What to look at the weekend? Review of the best reports in the public domain. Part Two, JBreak 2017
What can be seen in the evening or this weekend? You can watch some movies, or you can - our incessant series called “Java Conferences”. The only series, after watching which you can dramatically increase salary.
Yesterday's article about the JPoint 2017 was surprisingly successful. She had almost no comments, but at the moment - 88 bookmarks. That is, the article hit the mark: people bookmark and watch - hooray. Literally in the first hour, Satan himself came to read it.
Today we will act according to the old scheme: I look at 10 reports in a row for you, I make a short description of the content so that you can throw out the uninteresting. In addition, from sites I collect links to slides and descriptions. The resulting sort and give in order to increase the rating - that is, at the bottom will be the coolest report. Ratings are not likes on YouTube, but our own evaluation system, it is cooler than likes.

10. Glitter and poverty of distributed streams
Speaker : Victor Gamov; rating : 4.24 ± 0.11. Link to the presentation .
First slide:

It is clear that since this is Victor, then it will be a question of Hazelcast, although it is not clear from the first slide. This is a good introductory report on how to make streams distributed so that they finally stop slowing down (really, and not as always).
With the first example, Victor chooses word counting — the classic task of the programming world. There will be a map < -> > , you need to count the number of words and display the top. Will consider files with lyrics Disturbed and Lady Gaga.
You can do it on Spark, as does Zhenya Borisov. It is clear that the man-hazelkast can not descend to such a simple level.
The first example - with the help of streams from the eight, we subtract lines and set on the result of compute - we get a typical word count. A classification of operations on streams is given: intermediate, terminal, and stateful-blocking, is illustrated by the example of a picture with a burger (which he stole unhindered from a book about lambdas).

There is a certain amount of code on the stream with detailed explanations (the algorithms are simple, but they allow you to demonstrate everything well):
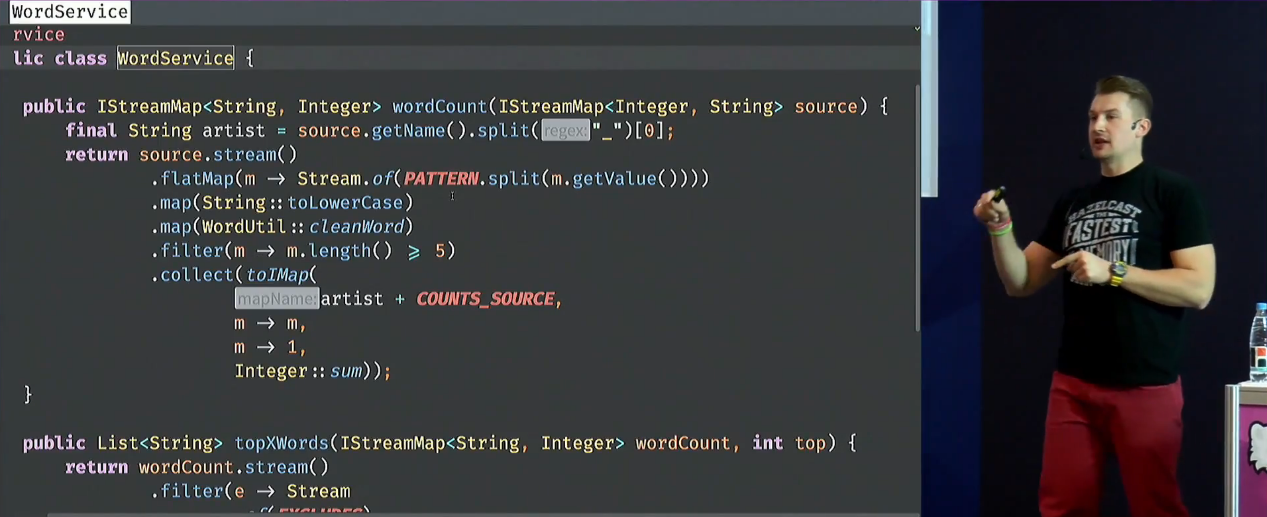
The question is not to write it at least somehow, but to make it distributed. But the interface of the streams of distribution does not imply, you can’t just take and convert the ready-made code (the maximum can be done within a single process using parallelStream , which is not a fact that will speed up anything at all). Lambdas are also non-serializable - you can’t just send them to other nodes. The results of the execution - too.
In 2014, at JavaOne, a team of people from Oracle (Goetz, Oliver, Sandoz, ...) told how to use this paradigm for distributed data: they made the engine for Hadoop, Coherence , etc.
In the original design of the stream library, the usual Stream could be inherited from the DistributedStream, but this was not done, because it would require fighting the Java language, dragging the overhead projector, and so on. Therefore, you need to distributeStream from just Stream. In Hazle this is done.
In Coherence there is, for example, RemoteStreams. There are ready-made collectors for streams, for assembling data in a serialized form. Infinispan also has a bunch of interesting pieces.
Except, in fact, the engine, the system should have good usability: we are zhaboprogrammers, we want everything to be just going, figak-figak, DevOps is not about us — they were immediately shoved into the cooker and sizzled for the prod. Hazelcast promises to solve all these things. Distributed caches, distributed computing, distributed everything, and this is also convenient to use. Horizontal scaling, vertical scaling, backups directly on neighboring nodes, etc.
But there are all sorts of problems like OOM.

To demonstrate all of these pieces, Victor has an application that was loaded on Spring Boot, and an impressive demonstration of how to load data (locally, not on a cluster — but on the clouds, too, he says, all this is tested, for example, on Heroku). Victor does live coding further, and it doesn't make much sense to describe it.
Then Victor moves on to Hazelcast Jet and Jet Streams - what it is and how it works. (By the way, don't you think that this is some kind of hell - are there so many products called Jet-something there?) This is for distributed computing, it works on a graph model and is based on the Hazelcast IMDG. Can be compared with Spark and Flink.

All this, of course, is described in detail. Execution of the graph, tasklets, etc. Shows demos and benchmarks and draws conclusions based on this. And then more than 10 minutes of questions and answers.
In this description, enough information is missing so that the report makes sense to look, and Victor did not crucify me for total spoiling :-)
For me personally, the report is valuable in that it’s the thing that you should definitely use in your applications instantly, as distributed streams will be needed.
9. The life cycle of the JIT code
Speaker : Ivan Krylov; rating : 4.29 ± 0.07. Link to the presentation .
Krylov is a companion from Azul, and in theory he could have burst into a nightingale about the peculiarities of his cool VM, but he does not do that. For which he special thanks a lot.
The talking epigraph to this report is Crazy House :

This is about how HotSpot works. From my perverted point of view, sometimes it is even good - otherwise life would be much more boring. From trusted sources, after the death of all the JVM developers, instead of hell, they are sent to develop the JVM.
The report will be about the transformation of the presentation of code, code profiles, de-optimizations, and the more practical part - 4 APIs for tuning compilation. Two-thirds of the report is about problems, the rest is practical.
First, it tells about the pipeline: static verification, non-optimizing compilation, the resulting bytecode, runtime verification, linking, executable code.

But it can be otherwise: bytecode can come from some ByteBuddy, the virtual machine can be without an interpreter, as in JRockit, the virtual machine can only be with an interpreter and that's it, or it can be a hybrid virtual machine with AOT, as in Excelsior JET.
Ivan says that the profile is, in fact, counters. Inaccurate counters for calculating ratios (not absolute values). Sometimes these counters have additional properties - this allows you to make additional optimizations.
In addition to the profile, we still need all sorts of small interesting things. It is illustrated on the features of the compiled Enum (in the compiled form it weighs more than its text - as if it hints that nontrivial logic is sewn inside. This logic can be viewed by bytecode).
Ivan shows how inlining works in general terms, and tells how once he accidentally broke this inlining (24% regression). There are standard reasons for breakdowns like: very large methods, too much nesting, special settings flags for virtuals, uninitialized classes, unbalanced monitors, jsr bytecode, etc.
But inlining can not only help, but also hurt. For example, when some methods are too often deoptimized. Virtualka can prohibit inlining in such situations.
Then we talk about the compilation levels from 1 to 4. It describes the transition scheme, conditions, thresholds (such as one and a half thousand executions for C1) and other interesting things. If you suddenly think that you understand all this well, then ... most likely, it is not :-)
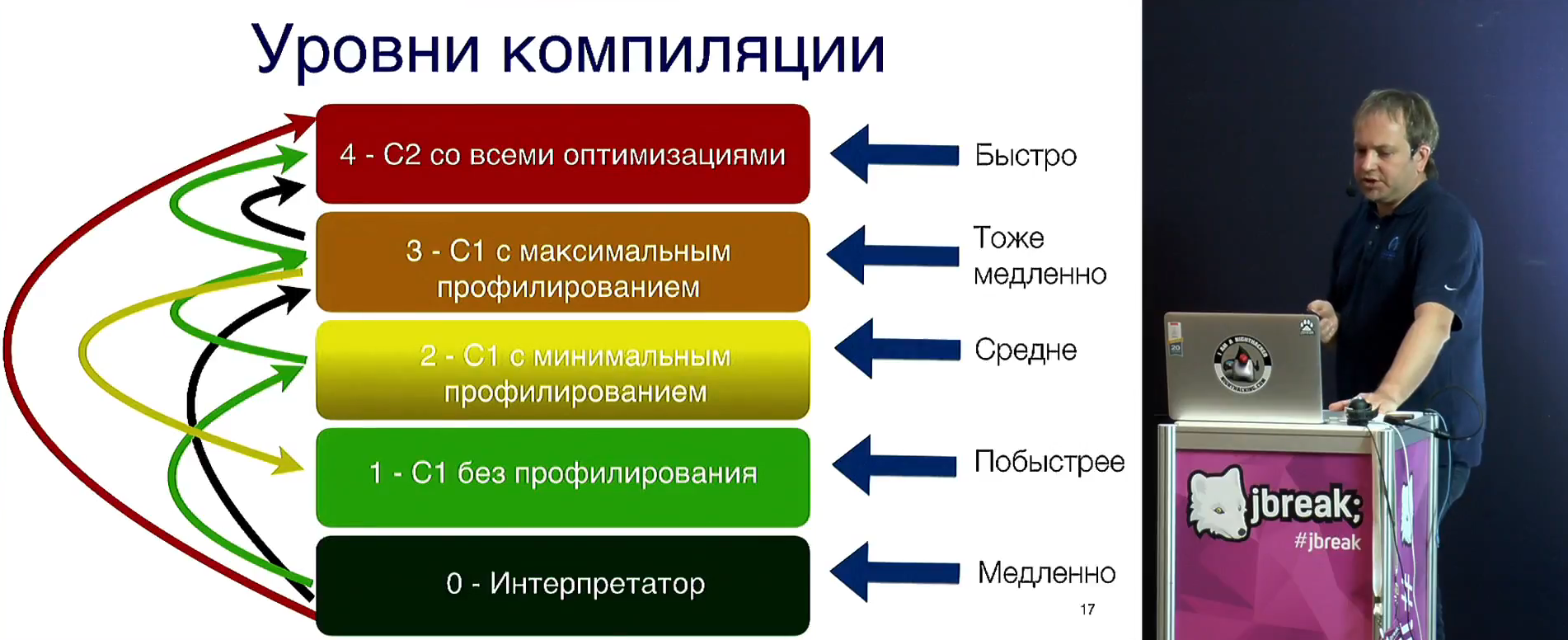
From this, a transition is made to de-optimizations, how they work, how they are divided into classes: deterministic (constant propagation, rollback (bias locking, tsx), speculative with instantaneous stopping (CHA invalidation).
A lot of code should be performed according to JVMS requirements: checks for zeroing, going beyond the limits of arrays, dividing by zero, checking types, etc. So that the code does not slow them down, JIT struggles to prove that these checks are not needed and throw them away. When the code changes, these optimizations will have to be thrown away. A long list of reasons for de-optimization is given.
And the report ends with a detailed description of the API for compiler settings that are related to the issues described above. Even if you (like me) are more interested in digging into the intestines of the JVM and experimenting, than to really turn the settings on the sale of a bloody enterprise, this section is still worth listening to, because there is also a lot of "meat" on the topic. Keys just can not explain, any attempt to explain reveals additional details. Including, there are explanations about how it works in Azul.

Personally, I will use this report to quickly introduce newcomers to the topic. This is a good (and most importantly - fast) overview of the topic of optimization and de-optimization that the brain cannot tolerate by excessive immersion.
8. CRDT. Solve conflicts better than Cassandra
Speaker : Andrey Ershov; rating : 4.32 ± 0.20. Link to the presentation .
A report on the ALPS-system (Available, Low Latency, Partition Tolerant, Scalable). Unfortunately, competitive modifications are inevitable in them, and we have to understand which changes are correct. Most systems, such as Cassandra, use the LWW (last write wins) policy — it will be shown why it does not always work. As an alternative, LWW came up with CRDT, to which the main part is dedicated. In the end - a lot of links for homework, self-study.
All this is demonstrated not on the bare theory (which you can read in the paper), but by the example of the task to synchronize data in the webmord, which is dear to the heart of any web-based coder. All demos are not just drawn on slides, but are shown live (Andrei has 4 applications running on the laptop).

That is, this application is opened in two browser tabs, but these tabs do not communicate with each other directly, but through a database ( Riak KV ).
Problems such as network segmentation are also demonstrated - despite the fact that all applications are running on the same computer. Iptables is used for this:
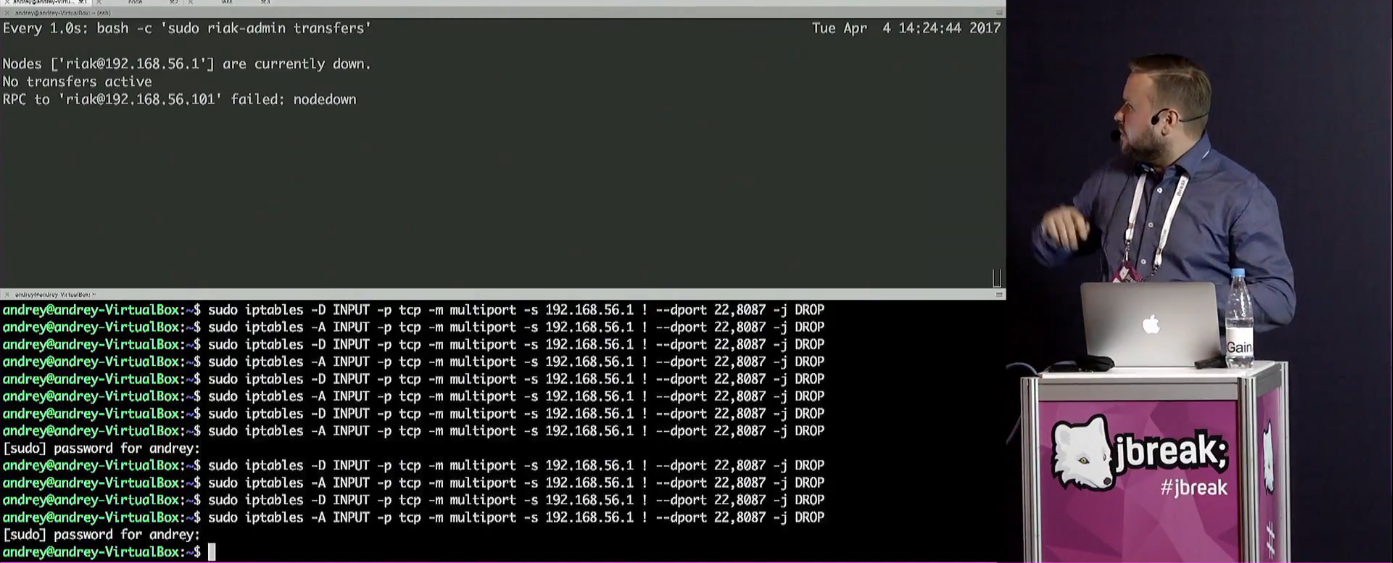
It seems that we will be haunted by references to documents that are worth studying. In this case, the way data is organized in a key-value database is covered by this must have document:

But all such sacred things are instantly demonstrated on a real, understandable example of the type of a distributed basket.

If it is quite brief, the meaning is as follows: if the same field is being edited from two different tabs, then a conflict may arise. In the proposed system, in the web interface, not just the last value will be displayed, but directly it will be written: “Do you have a conflict here, what will we do?”.
Questions such as response acceleration (asynchronous replication, optimistic UI), network problem solving (network segmentation, offline work, to work in an airplane), etc. are considered. In short, there are some competitive changes, and the problem with them is solved with the help of CRDT - conflict-free replicated data types.
It describes what the Strong Eventual Consistency is and, in fact, CRDT (data structures with the SEC property, solving competitive change problems and automatically resolving conflicts). There are almost any data structures there — counters, registers, flags, lists, sets, maps, graphs, and so on — all this can be described as CRDT.
The state-based CRDT is considered (when the state of an object changes, the entire state is transmitted) and their problems. More precisely, one major problem is a huge amount of data. Specific implementations are Akka and Lasp .
Similarly, the operation-based CRDT, advantages and disadvantages.

It is proposed to read the book "Reliable and Secure Distributed Programming" , it is obligatory in English, because the Russian translation is fuzzy. After that, go to the basic description of different types of broadcast: Unreliable, Reliable, FIFO, Global Order. Discussed causal broadcast in different versions.
Evenuate , swiftcloud, and antidotedb are offered as an example of op-based CRDT.
Based on the discussion of previous types of CRDT, we turn to Delta-CRDT: the requirements are the same as those of state-based, and the size is the same as op-based. They are implemented by Akka and Riak KV.
All these types of CRDT are illustrated with a real-life example such as GCounter (grow-only counter) and PNCounter (positive-negative counter) = GCounter + GCounter. There are problems with counters, and, of course, here we will need Riak Counters. Next in line is the LWWRegister, Version Vector, MVRegister, GSet, 2PSet, OR-Set, AWMap. All this with a detailed description.
What does this mean for me? IMHO, CRDT - the future of distributed systems. The field of distributed systems is booming, and you need to maintain your knowledge in step with the times, in particular, read papers and walk on such reports. And of course, once in Akka we have written down delta CRDT , this issue should be studied first.
7. Java Inspection at IntelliJ IDEA: What Can Go Wrong?
Speaker : Tagir Valeev; rating : 4.33 ± 0.12. Link to the presentation .
First you need to understand that Tagir is @lany , and it is a living embodiment of the Java hub in Habre .

If you read his articles, it is easy to see how the average post of Tagir is different, for example, from my average post. They are not advertising and very high quality. His reports at conferences are better than posts, and they need to be watched. At this one could put an end, but being a graphomaniac, I can’t stop.
And also, for this report, Tagir was forced to donate my laptop. He worked best with the projector, or something. If you look at the lid of the laptop, you will see on it the only round sticker “This is Sbertech, baby!” - not the most obvious label for the employee of JetBrains!

Okay, to the point. Report - about writing inspections for ideas.
The epigraph picture to the report: a normal IDE would definitely help prevent such an error.

The idea is two thousand inspections, most of which are search and replace.
An example is given of the Wishlist user Idea to add a transformation from:
set.stream().collect(Collectors.toList()) in a more reasonable view:
new ArrayList<>(set) For those who are in the tank, Tagir explains why the regular season is not the best way to solve this problem. You can not represent the code as a set of characters, you need a more abstract model, for example, AST. However, it is also not enough in a normal situation. Enough PSI (Program Structure Interface), which is implemented in the Idea.
With the help of something like this, you can immediately cover a whole class of equivalent records:

Next Tagir tells about the replacement, what could go wrong at this stage. There are magic methods that allow you to make a fragment of a PSI tree from a line and replace it.

If you write correctly, then the Idea will automatically add the missing imports and other nishtyaki (see the call to shortenClassReferences ). In addition to imports, code can be normalized in many different ways, for example, by automatically removing unnecessary qualifiers or type conversions.
The next interesting example is the processing of comments. In the old inspections, after fixation, they were simply lost, in the new ones - they are trying to keep an eye on this. Where possible, comments remain in place, but this is not always the case. For example, if we close the loop with deletion to list.removeIf , and there were comments in the middle of the loop, then all of them will creep up and appear directly above the line calling list.removeIf .
Similar problems arise from the fact that inspections must take into account the fact that you can build as many round brackets as you like in different places. Inspections should fall inside the brackets. Another idea can cycle fold into a stream, and with this there is an additional set of difficulties.
How semantically are the original and refactored code equivalent? About this is a separate large block of the report. In short, changing semantics can sometimes be sacrificed, and some changing semantics inspections are better off by default.

The following blocks are about generics and type conversions. As you might guess, the problems are the car.
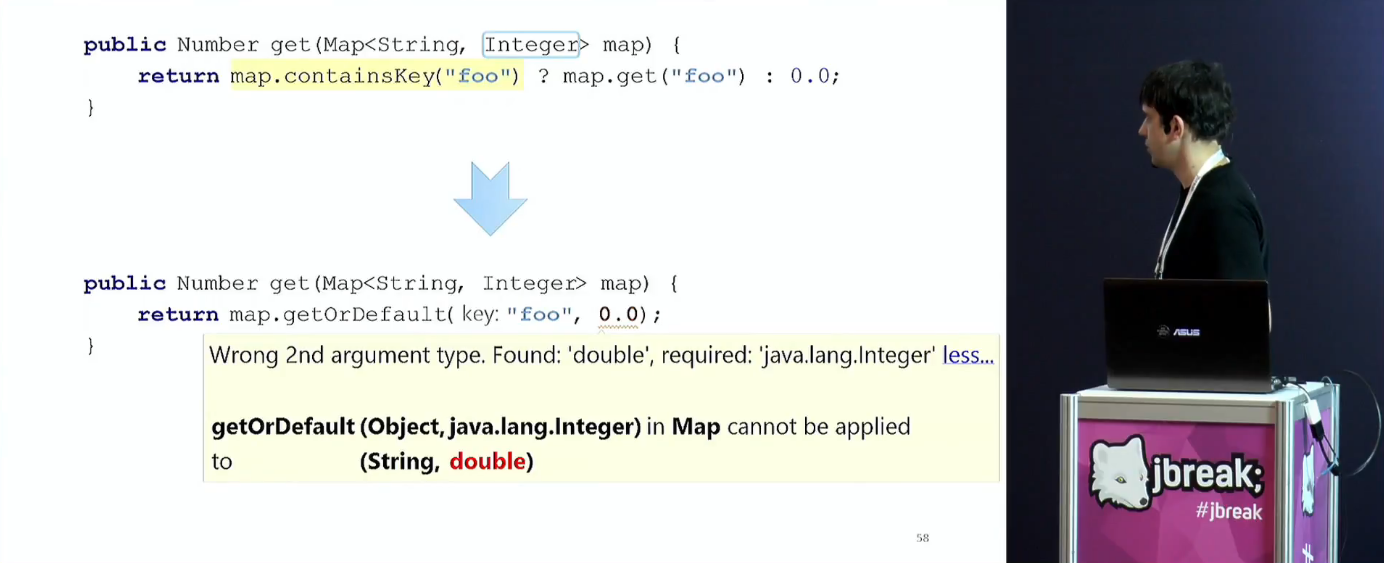
And at the end the tin itself is considered an incorrect code. Unlike the correct code, any can be incorrect, and here especially perverted and heaped tricks are used.
For me personally, this report is very useful, because writing inspectorates for an Idea is one of the things that I will do without fail. Why the marketer needs this - I will not explain now, there will be a separate article about it.
6. Analyzing HotSpot Crashes
Speaker : Volker Simonis; rating : 4.35 ± 0.14. Link to the presentation .
Volker is a companion from SAP who systematically tells all the tin about how to repair Java, if you intend to use it as cruelly as he does at work. Usually there occurs blood-gut-dismemberment, debugging of the falling JVM, traveling through the wilds of C ++ and assembler code, and so on.
This report is no exception:

The report begins with a review of the structure of HotSpot VM

Volker hints, as it were, that we will need to dig into this when repairing. In fact, this is such a full-stack task, where our “stack” is the guts of the JVM. The task is divided into two main parts: to understand in which part of the stack an error occurred, and then, using our knowledge of this part, to fix the error.
By the way, this is one of the few reports by Volker, where there is no real live coding. It seems that there is too much code to dial it manually: he typed it in advance and packed it into slides with screenshots.
But you have to understand that, in essence , this is still a debugging process, the purpose of the report is to observe this process, and describe everything step by step in a somewhat meaningless way, so I’ll just say a few words.
If anyone is interested in how to quickly brighten up the JVM:

It is important that Volker shows his examples very schematically. Often it is not enough just to copy the code, you need to think a little. For example, the real code from this crash (just checked) should look something like this:
import sun.misc.Unsafe; import java.lang.reflect.Field; public class Main { public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, ClassNotFoundException { Class<?> c = Class.forName("sun.misc.Unsafe", false, Main.class.getClassLoader()); Field theUnsafe = c.getDeclaredField("theUnsafe"); theUnsafe.setAccessible(true); Unsafe u = (Unsafe) theUnsafe.get(null); u.putInt(0x99, 0x42); } } Having thrust on a rake, we, following Volker, fiercely study the virtualka's fall logs:

We rummage in registers and a stack:

We discuss the generation of hs_err.log and the fact that everything is not easy with it:

Explore the places of the fall:

And so on.
For example, you can paint in the interpreter, but it is not necessary that it is somehow connected with the interpreter. Maybe we just broke hip. Or, for example, you can debug Out of Memory in this way (you need to dig, starting with the -XX:+CrashOnOutOfMemoryError flag -XX:+CrashOnOutOfMemoryError and the corresponding log).
For me, the value of this report is that it gives a specific set of pens that you can grasp. How specifically to look at the disassembler, what to write in the VM options, how to use the Serviceability Agent, how to use replay files, and so on. More importantly, you can look at Volker’s train of thought and try to learn how to think in a similar way.
Of course, it is not every day that your JVM falls, and there is even less chance that you will be able to fix such a bug (elementary, you may not have so much time to crawl through the logs for days on end). Usually such bugs will be reported and waited for professionals to fix them. On the other hand, knowing the things Volker is talking about, you can, without waiting for a fix, come up with some tricky workout (not at the level of fixing the JVM itself, but at the level of easily refactoring your Java code).
, JVM , , - , . , , , , , . , in open source no one can hear your scream. , , , — .
5. Kafka , Spark !
: ; : 4.38 ± 0.19. Link to the presentation .
.
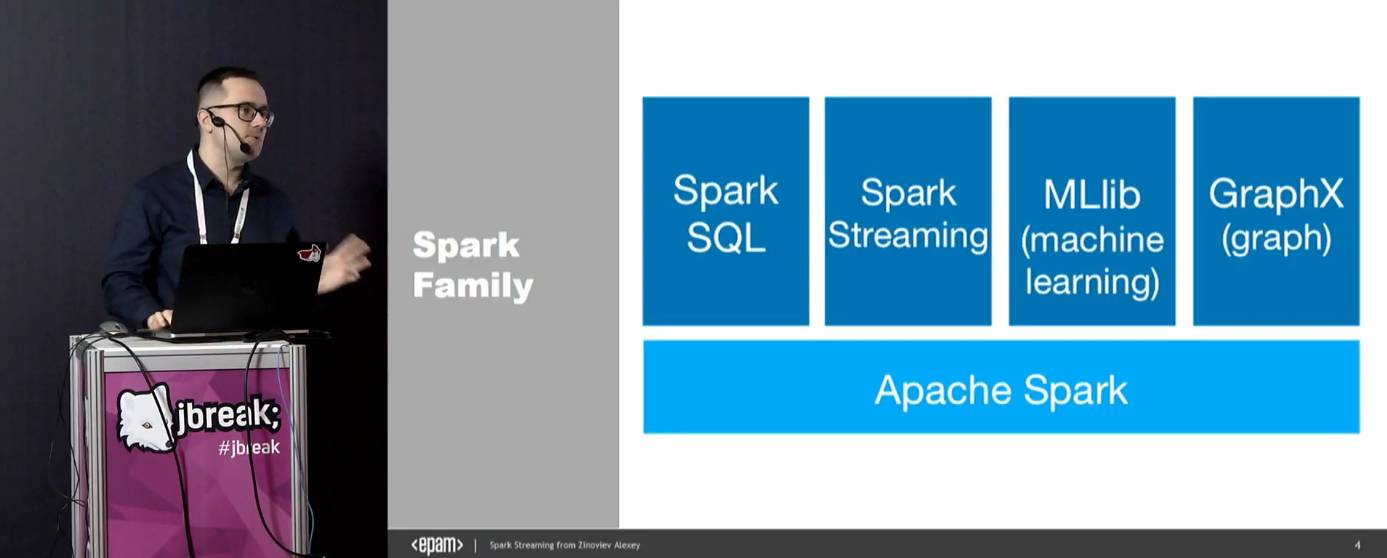
Spark Streaming Kafka. , , .
:

, Java, Scala. , Scala, .
, «real-time» , , -, .
, . , , . 5 50 .
2017 - . , , - . ( , .. — , ). data lake, :-)
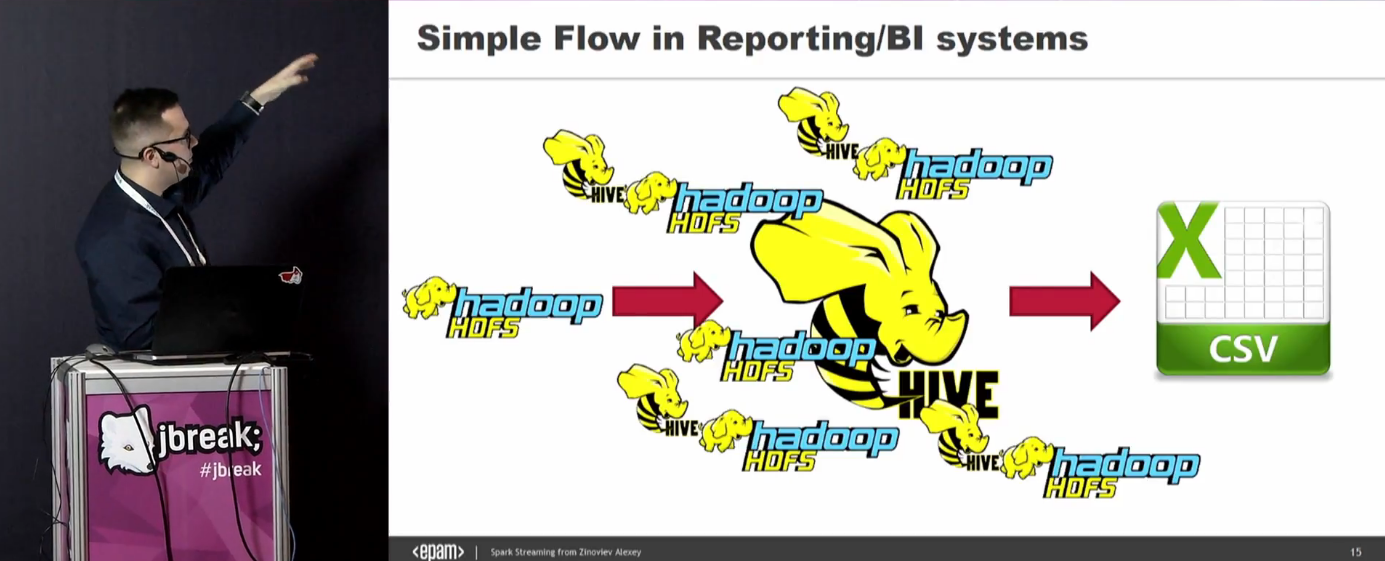
— Spark. , . , — . , - .
— . , .. , — , .

, cassandra to spark. , .
, . Publish-subscribe, .. , JMS , , — point to point, publish-subscribe, , fault tolerance ..
Kafka. : .
, Zookeeper.

. , , . producer, consumer, .
, , dstreams. , . .
API.

. -, . « » ©, . .
— , : filter, sort, aggregate, join, foreach, explain .. .
, Explain, :
:

, , , , . -.
, , . , — . , .
? , , «» . , — , , , . — .
4. JVM
: ; : 4.47 ± 0.11. Link to the presentation .
: « , ?»

, :-) , :
— OpenJDK, , , , — .
12 : . Throughput . , , . SIMD. , x86: , ..
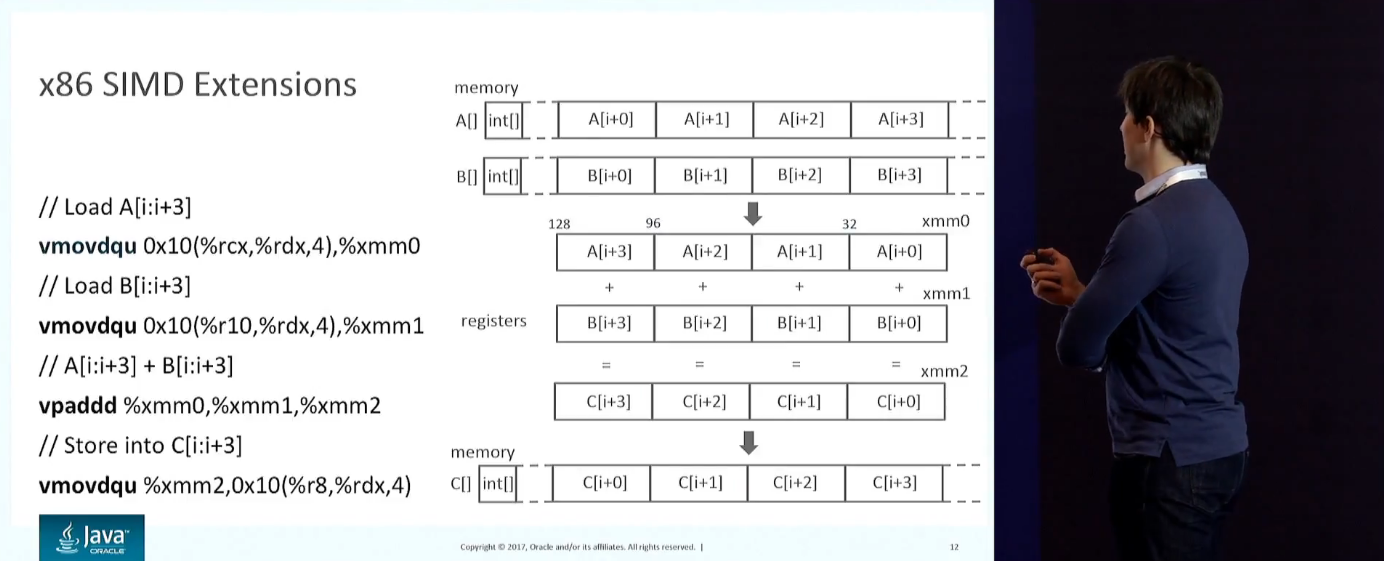
: , (low-level ).
. ( , ). Anger Fog , , . JVM , , JVM , .
SIMD-, , . -XX:+UseSuperWord .

( -XX:+PrintCompilation , -XX:+TraceLoopOpts ), -XX:+PrintAssembly . , — . , . , .
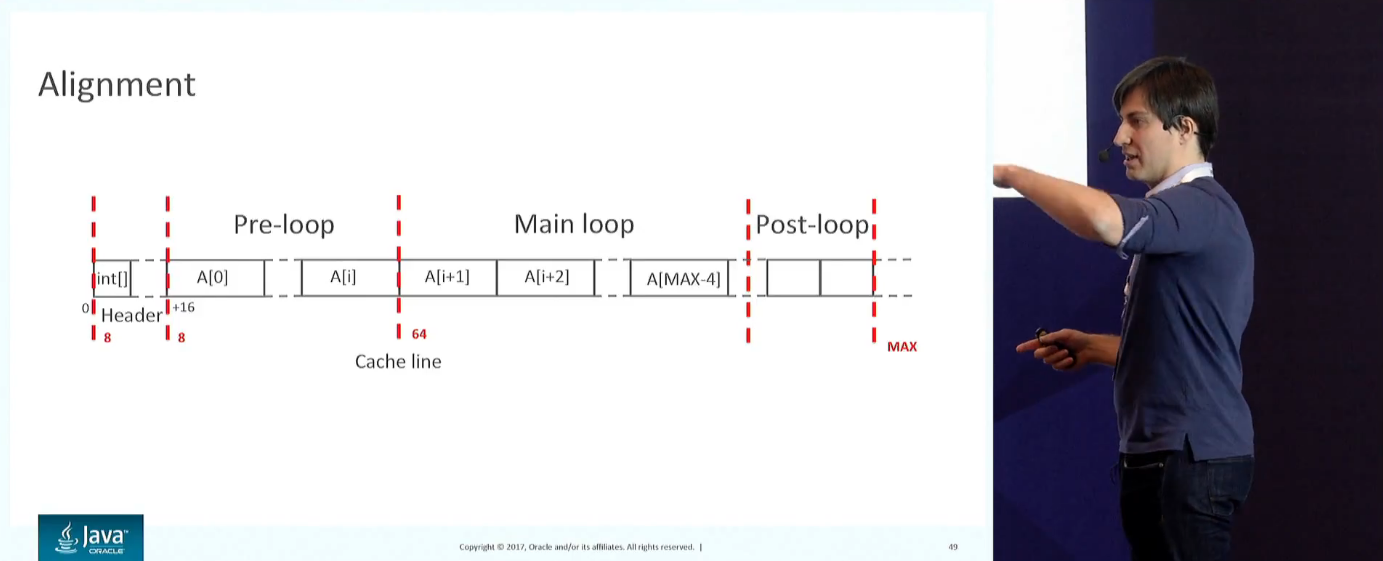
Fused Operations, JDK. AVX-512, 10 x86.

: System.arraycopy , Arrays.copyOf , : Arrays.mismatch , ArraysSupport.vectorizedMismatch .
, Java SIMD 2017 . Panama, API. : , , OpenJDK.

, JVM. - OpenJDK, , , ( Graal & Truffle, ).
3. : ?
: ; : 4.47 ± 0.06. Link to the presentation .
, , JPoint, JBreak. .
, JPoint 2017 . , .
2. Java 9 . OSGi?
: ; : 4.60 ± 0.06. Link to the presentation .
, OSGi. , (.. JUG.ru Group), — Java Excelsior JET , 17 ( Java ), . , - , . , , Mark Reinhold ( - OpenJDK, JET, ), .
Java 9 , , , . , , , . , - , .
: , Maven OSGi. Maven - (, , ), OSGi .
- :

: OpenJDK, , , . , -, — , OpenJDK , — ( ).
, OSGi, , .

OSGi. , :

, (, , classloader memory leaks, ). , OSGi loading constraints ( «LinkageError», ). , , — . , OSGi , , .
. JVM . JVM ( , ), ( ), ( ). OSGi ! , HotSpot . , — OpenJDK , . -, , (, Graal & Truffle!).
, ( , ) — . , @pjbooms , , - .
, Jigsaw , . « Jigsaw»: «reliable configruation + strong encapsulation» :

, .
? . , advanced JVM, must have . - : OSGi ( low level , — ), — ( , « » — ). — .
1. Shenandoah: ,
: ; : 4.62 ± 0.06. Link to the presentation .
, , JPoint, JBreak. . « , » #1 .
, JPoint 2017 . , .
Conclusion
JBreak 2017 . , .
. .
JBreak , , . , 4 2018, JBreak 2018 , , . .
')
Source: https://habr.com/ru/post/346490/
All Articles