Data Modeling Zone EU 2017
At the very beginning of the new working year - a few words about one of the events of the past year.
Data Modeling Zone is a franchise that brings together conferences on the construction of a logical database architecture. The past few years have been held in the USA and Europe, and this year it will be held in Australia for the first time. In 2017, two forums were organized under the DMZ brand, both were held in the fall: October 16–18 in Hartford, USA, and on October 23–25 in Düsseldorf, Germany. I happened to take part in the role of a listener in the last of them. This article presents a brief overview of the presentations that I saw at the conference, and my impressions of it in general.
The name of the conference unambiguously hints that the key issue is the different aspects of building a data model. Most of the announced topics are related to data warehouses, but were also relevant to any information system. My expectations were contradictory: on the one hand, among the speakers were recognized community leaders, on the other - an abundance of hourly presentations that did not involve in-depth consideration of issues.
')
The main program was represented by five tracks:
Along with the badge, the participants were given a set of stickers. With their help, the owner of the badge could indicate the languages in which he speaks and choose one or more professional roles. The idea is original and entertaining, but useless.

The first day began with a three-hour lecture on various aspects of versioned data storage. The construction of historicity is a topic around which there have been many lively disputes within our team. Therefore, I could not get past the keywords merging timelines, Data Vault Satellites, historization in the announcement of the speech.
The speaker is Dirk Lerner, one of the missionaries of Data Vault in Germany, the founder of TEDAMOH (The Data Modeling Hub), the author of a good professional blog .
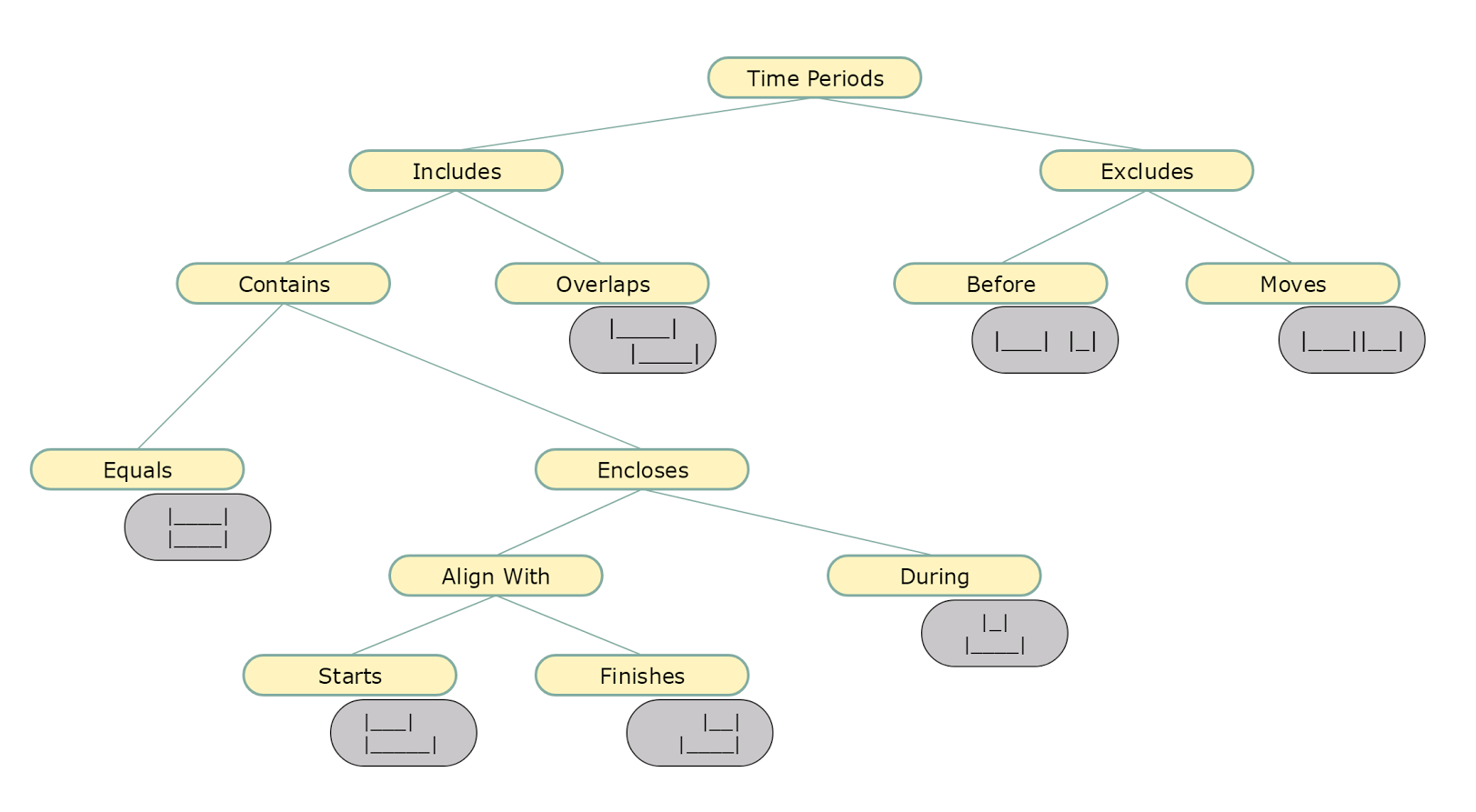
The presentation began with a review of the formats for recording time intervals. We considered 4 formats that differed in the way of recording the beginning and end of the interval: open or closed. In the first example, a sequence of two intervals was chosen: T1 = 2016, T2 = 2017. From the explanations, I realized that the open format of the recording of the boundary of the interval (open) implies the exclusion of the boundary, and the closed (closed) - inclusion. Like how numeric intervals are written in algebra.
But the following example baffled me. It was one interval - the period of the conference. The first item of the task (closed / closed) did not cause any difficulties for anyone. But over the other three discussions arose, during which the definitions of all formats finally clarified.

The bottom line is that the period limit in the open format is denoted by the first defined value from the adjacent period. That is, the “open” end of the period is designated as the first beat of the next period, and the beginning - as the last beat of the previous one. The periods from the first example had "neighbors" in fact of their belonging to the Gregorian calendar. The second example was more specific and local, so it was impossible to determine the boundaries of the proposed interval through the “open” format.
In conclusion, they talked about the preference of the close / open format, since it is precisely this that makes it possible not to depend on the clock ticks of the surveillance system. Indeed, if we build a continuous history of changes in the state of an object, then the end of the current period occurs at the time of the change of state, that is, from the beginning of the next period. To calculate the end of the closing interval when using the close / close format, it is necessary from the time when the new state is fixed, to take 1 clock tick. While the use of the close / open format allows you to specify the time of the status change as the beginning of the new period, and as the end of the old one. It does not matter in which units time is measured - the format of close / open is independent of the size of the clock clock of the storage. This is one of the reasons why it is most popular and introduced in ISO 9075: 2011.
The next topic was the classification of time interval intersections. Dirk clearly demonstrated how not to get confused in questions that seem obvious. In essence, nothing new, but the systematic consideration of the issue makes a pleasant impression.
But all this was a warm-up before the main topic of the presentation, namely, the preservation of data in the context of two chronologies: business and technical. The unusual word bitemporal in the title of the topic - just about that. Dirk began with a fairly simple abstract example, in which we have at the entrance an array of data with a key, a pair of business attributes, a date from which the recording began from a business point of view, and a date for loading data into staging.
Stagingtable
Satellite
The idea is to keep a history of history changes. Consider processing the first two entries from staging. There are no problems with the first recording - at the time of its loading there is no question of processing changes. An entry is added to the satellite stating that the attribute key (10.10) for a given key is “for centuries”. The second entry from staging contains an update for one of the attributes, with the result that the vector took on the value (11,10). To handle this event, you need to do three things:
The next example, the students decided on their own. It dealt with the student schedule.
A curious visualization was used to demonstrate the solution. Double historicity was presented in the form of a coordinate plane. On the x-axis - business time, on the y-axis - technical. Each entry corresponds to one of the areas of the plane. Cutting goes diagonally - right and up.
The final example was the most difficult. Baseline - a plan for price changes in relation to the day of the Black Friday marketing campaign.
Staging table
The difficulty was that the plan was revised not only in terms of changing the price itself, but also in terms of breaking down the time continuum of the solution. I note that the key to the success of the assignment was to understand that for any moment of “technical” time in the repository there must be data that fully covers the entire “business” chronology. Not without effort, the task was solved “on a piece of paper”, but the question of automating this not very trivial algorithm remained open.
The next item on the program was a description of how to merge information from two satellites with dual historicity into one dimension. For the demonstration, we chose an example with a student with a specific class schedule. He has a history of degree change. The essence of the proposed method: cross join with the collapse of consecutive intervals.
The last considered aspect of this topic was the variability in the interpretation of information obtained at the output. There is a fact that the student has passed the exam. Information about the schedule and degree of the student for this fact we can determine in three different ways:
Perhaps this presentation was the most informative and informative for me personally. After it was followed by a block of performances in the genre of key notes.
The organizers uttered a set of on-duty phrases, of which the mention of gender distribution among the participants was remembered: 165 men to 17 women. After that, the “rock star” of data modeling appeared on the scene, the author of numerous books on the topic is Steve Hoberman. Steve told that today the most popular IT issues in this area are nosql databases and the cultivation of new modelers. At the second, he stopped in more detail, saying that the growth in the volume of metadata greatly exceeds the growth in the number of modelers. In this regard, he identified the 5 most popular skills in the coming years:
The next speaker was the architect of the data from the Central Bank of the Netherlands - Ronald Damkhov. Ronald told how he and his colleagues managed to build a repository on the principle of "multireality". It was about the methodology, which:
The idea is to present all the repository in the form of a quadrant, built in the coordinate system "flexibility-systematization" + "sources-business" and divided into 4 sectors:
At the same time, it was emphasized that the division of data into “master data”, “big data”, “metadata” and others is inefficient.
In the resulting coordinate system, there was an order of solving each of the 7 main tasks in designing the CD:
For the solution of the issue of construction, for example, suggested options (green - ok, red - not ok):
After Ronald, Steve Hoberman took the floor again. He told how the main determining factor in the development of IT in the next decade, the blockchain technology, affects data modeling issues. Since Steve is a guru of modeling everything and everything, the blockchain was immediately defined as a logical data model.

According to Steve, the blockchain will be most strongly influenced in data management, data standardization and storage architecture design. Blockchain is unlikely to touch the vector of relational database development. But how it will affect the Agile methodology is not yet clear.
Curiously, as an example of the spread of this technology, Steve spoke about the Ukrainian project, in which it is proposed to switch to the use of cryptocurrency for the calculation of state property sales transactions. This should help in the fight against corruption.
Everyone was invited to practice in the delivery of the most famous in the field of data management certification DAMA DMBOK2. The training version of the exam included 20 questions. For example:
And so on.
Curious theory. Rather abstract, at the same time consistent and logical.
Initially, a demonstration of a system providing a complex of services for building a storage architecture was planned in a seminar format. But the notebooks turned out to be much smaller than the participants, so the format was changed to a presentation.
As a preamble, a number of statements of the “Volga flows into the Caspian Sea” class were declared. For example, that the main thing is to listen to business, and automation is part of the process, not a technical solution. For example, a failed project was cited with a customer represented by a Russian company, whose representatives "believed that they were buying a magic wand by buying a system." After the presentation, I went to ask more details about this project. But all that he heard was a request not to perceive these words as a blasphemy of the Russian people - “this error is peculiar to all.” At the end of the introductory section, the Power Designer was thoroughly criticized - old, ugly, complicated, there is no point in storing a version.
The system itself during the demonstration looked really impressive. In the case, we saw only a part of the capabilities, but it was stated that WhereScape Red provides a complete set of options for managing metadata and ETL. As a confirmation, a scheme was presented in which the standard elements of the storage architecture covered by the functionality of the system were marked in red:
We started with the fact that the models of source systems are described, their changes are tracked. The modeling process itself consists in the construction of a logical model of custom storefronts and the definition of the mapping of their fields with sources. After that, pressing the magic button starts the process of automatically building a model of the staging layer and data vault in accordance with the pre-configured rules. The final step was to generate the ETL code and define the schedule. In the examples of the tutorial class, everything worked, of course, smoothly and elegantly. Among the features, I would single out the line by column. There are no verification and validation changes yet, but they should appear in the nearest release. More about the capabilities of the system can be found on the vendor page .
The first day ended with an amateur humorous show. Scenes of two adult men, the leitmotiv of which was self-irony about the rush around the Data Vault, bored after the first 15 minutes, although the whole presentation lasted more than an hour. Looking at the number of phone screens burning in the dark, it was hard not to feel sympathy for the speakers of the uncles.
The three-hour seminar of the Australian John Gillz was essentially a summary of his 2012 book The Nimble Elephant. The topic is useful and does not lose its relevance. It is about using industrial templates when designing a model. Currently, large vendors (for example, IBM and TeraData) offer ready-made high-level model templates for different subject areas - “Industry Reference Model”. The most common classification of entities in many templates is the same. The concept that John talked about is no exception. It involves the use of types:
At the seminar, participants had to build a data model describing this business process based on the description of the company's production activities. It was suggested to do this with:
In addition, John presented an exact schedule for building a data model using this approach:
The resulting conceptual model can be used not only to build a logical model of HD, but also as a single formalized enterprise business model, in accordance with which you should create logical data models of operating business systems.
The second seminar I was able to attend was conducted by Steve Hoberman. Steve is known not only for his books and the patented Data Model Scorecard quality system. He is also popular as a teacher in seminars and courses on the topic. In general, he confirmed his reputation: telling is available, interesting and with humor. True, the name of the seminar did not correspond to reality: it was about important and useful, but still basic principles for building a model.
First, he spoke about the concept of super-entities and their extensions, which overlapped with the content of the previous seminar. Then the task followed: it was necessary to study a small set of data presented in a flat denormalized shop window and describing the assortment of a bookstore, and build a 3NF model. According to Steve, performing this task, we had to feel like archaeologists of the data.
The next assignment was more entertaining. The initial data was the schedule of suburban trains in one of the directions in the vicinity of New York.
The task was to design a data model, on the basis of which it is possible to build an analyst on the quality of work of electric trains, namely, how precisely the schedule is fulfilled. The target model had to provide for the preservation of data on the schedule and on the actual train schedule. The models represented by the three teams did not practically differ in the set of entities, except for differences in names. What we call “branch” or “line” in different models was called: line, journey, route, trip, and “haul” - link or leg. From this, one of the obvious, but extremely important rules of modeling was derived - the need to provide a clear, most comprehensive definition of the entities represented in the model. The fundamental difference between the models was the way of saving actual data on train traffic: in some models, the granularity of these data was defined as the fact of the train arrival from the initial station to the given one. An alternative approach was to keep the train moving between two neighboring stations. In the course of comparing the two methods, we came to the conclusion that it is important when building a model to remember which process we want to measure with its help.
In addition, the paradigms of building logical models differed: one team chose Multi-Dimensional, the rest 3NF. On the basis of this, we formulated a thesis on the priority of creating a qualitative conceptual model, which can easily be converted into Multi-Dimensional, 3NF, Data Vault, and so on.
Extensive philosophical presentation of the role of architects in the modern world. The key idea is best expressed by the quote by architect Norman Foster:
“ As an architect you design for the present,
with an awareness of the past
for a future which is essentially unknown . ”
Of the great ones, Aristotle was still quoted with his words that architecture rests on three pillars: durability, beauty and functionality.
It was something about everything and about an hour-long in keynote format. Among other things, it is worth highlighting the extremely important observation: the architect of the building differs from the architect of the industrial system in that it is not built into the object of his creation.
Not the most exciting presentation on how to properly save the history of the entity. Key thoughts:
To demonstrate these good and important thoughts, a primitive example was chosen with the wildebeest life cycle model:
And to consolidate the information received, we were offered to build a data model that would automate the process of clearing bank checks. Either the task was formulated too abstractly, or the participants were tired by the end of the second day, but in the end there were no ready-made solutions.
The author is Gabor Golnhofer, an architect with 20 years of experience in HD projects in finance, insurance, telecom, retail and education. The project presented was to transfer the repository of indefinitely mixed architecture to the Data Vault. The name of the company-customer was not called, they said only that it is the market leader in its field in Hungary and is part of an international holding. According to the "tactical and technical characteristics" their storage is comparable to our Tinkoff DWH:
From a technical point of view, the main prerequisite for rebuilding the repository was the high cost of the process of improvements and performance problems. In addition, 20 years of evolution, including the transition from 3NF to Dimensional and the introduction of versioning, led to architectural chaos. From the business side, there were requirements: high speed of changes, completeness of history preservation, opportunities for self-service BI. In short, as usual - more, faster and cheaper.
I am sure that the main problems encountered by my colleagues are familiar to many. This is the absence of suitable business keys in the source data, only surrogate, and the poor quality of the source data, and integrity breaches in the sources. Also, a lot of effort had to be spent on automating the construction of Dimensional - windows based on DV - and the development of ETL-procedure templates for loading large data arrays. Perhaps the key feature of the project was the emphasis on automating model changes and ETL, resulting in:
In addition, it was rightly argued that Data Vault is useful in data quality control, because it allows you to save "facts" rather than "truth."
The report was interesting and informative. In a personal conversation after the presentation, Gabor agreed that the Data Vault should not be perceived as a dogma, but adapted to the needs of a specific project.
Summarizing the content of the conference, I note:
There were not enough presentations of real projects telling about ways of solving real, rather than hypothetical problems that project teams face when using beautiful and slim [on paper] methodologies, about adapting such approaches to the harsh prose of life.
If we talk about the general impression, the main effect is motivating. Motivating to read more about the approaches presented. Motivating to do this rather popular business. Perhaps DWH analysts with experience of up to three years would be primarily interested in the presentations themselves, and their older fellow architects would find more pleasure in communicating with colleagues on the margins. Personally, I managed to get acquainted with several colleagues from Europe, America, and, oddly enough, Russia. Lucky to talk with some gurus. By the way, Hans Haltgren in a personal conversation said that the two Russian guys with whom he works in the Valley are simply “amazing”. And left an autograph on his, perhaps, the most popular book about Data Vault.

Introduction
Data Modeling Zone is a franchise that brings together conferences on the construction of a logical database architecture. The past few years have been held in the USA and Europe, and this year it will be held in Australia for the first time. In 2017, two forums were organized under the DMZ brand, both were held in the fall: October 16–18 in Hartford, USA, and on October 23–25 in Düsseldorf, Germany. I happened to take part in the role of a listener in the last of them. This article presents a brief overview of the presentations that I saw at the conference, and my impressions of it in general.
The name of the conference unambiguously hints that the key issue is the different aspects of building a data model. Most of the announced topics are related to data warehouses, but were also relevant to any information system. My expectations were contradictory: on the one hand, among the speakers were recognized community leaders, on the other - an abundance of hourly presentations that did not involve in-depth consideration of issues.
')
The main program was represented by five tracks:
- Foundational Data Modeling
- Agile and Requirements
- Big Data and Architecture
- Hands-On and Case Studies
- Advanced data modeling
1st day
check in
Along with the badge, the participants were given a set of stickers. With their help, the owner of the badge could indicate the languages in which he speaks and choose one or more professional roles. The idea is original and entertaining, but useless.
Send Bitemporal data from the Ground to the Stars
The first day began with a three-hour lecture on various aspects of versioned data storage. The construction of historicity is a topic around which there have been many lively disputes within our team. Therefore, I could not get past the keywords merging timelines, Data Vault Satellites, historization in the announcement of the speech.
The speaker is Dirk Lerner, one of the missionaries of Data Vault in Germany, the founder of TEDAMOH (The Data Modeling Hub), the author of a good professional blog .
The presentation began with a review of the formats for recording time intervals. We considered 4 formats that differed in the way of recording the beginning and end of the interval: open or closed. In the first example, a sequence of two intervals was chosen: T1 = 2016, T2 = 2017. From the explanations, I realized that the open format of the recording of the boundary of the interval (open) implies the exclusion of the boundary, and the closed (closed) - inclusion. Like how numeric intervals are written in algebra.
| Format | T1 | T1 |
|---|---|---|
| Closed / Closed | Jan16 - Dec16 | Jan17 - Dec17 |
| Closed / Open | Jan16 - Jan17 | Jan17 - Jan18 |
| Open / Closed | Dec15 - Dec16 | Dec16 - Dec17 |
| Open / Open | Dec15 - Jan17 | Dec16 - Jan18 |
But the following example baffled me. It was one interval - the period of the conference. The first item of the task (closed / closed) did not cause any difficulties for anyone. But over the other three discussions arose, during which the definitions of all formats finally clarified.
The bottom line is that the period limit in the open format is denoted by the first defined value from the adjacent period. That is, the “open” end of the period is designated as the first beat of the next period, and the beginning - as the last beat of the previous one. The periods from the first example had "neighbors" in fact of their belonging to the Gregorian calendar. The second example was more specific and local, so it was impossible to determine the boundaries of the proposed interval through the “open” format.
In conclusion, they talked about the preference of the close / open format, since it is precisely this that makes it possible not to depend on the clock ticks of the surveillance system. Indeed, if we build a continuous history of changes in the state of an object, then the end of the current period occurs at the time of the change of state, that is, from the beginning of the next period. To calculate the end of the closing interval when using the close / close format, it is necessary from the time when the new state is fixed, to take 1 clock tick. While the use of the close / open format allows you to specify the time of the status change as the beginning of the new period, and as the end of the old one. It does not matter in which units time is measured - the format of close / open is independent of the size of the clock clock of the storage. This is one of the reasons why it is most popular and introduced in ISO 9075: 2011.
The next topic was the classification of time interval intersections. Dirk clearly demonstrated how not to get confused in questions that seem obvious. In essence, nothing new, but the systematic consideration of the issue makes a pleasant impression.
But all this was a warm-up before the main topic of the presentation, namely, the preservation of data in the context of two chronologies: business and technical. The unusual word bitemporal in the title of the topic - just about that. Dirk began with a fairly simple abstract example, in which we have at the entrance an array of data with a key, a pair of business attributes, a date from which the recording began from a business point of view, and a date for loading data into staging.
Stagingtable
| Somebk | Attr_1 | Attr_2 | Validfrom | STGLoadDTS |
|---|---|---|---|---|
| % 662HK! ..? | ten | ten | 2014-12-01 | 2015-01-01 |
| % 662HK! ..? | eleven | ten | 2015-01-03 | 2015-02-10 |
| % 662HK! ..? | eleven | 100 | 2015-03-30 | 2015-02-23 |
Satellite
| H_ID | Attr_1 | Attr_2 | Tech_from | Tech_to | Bsns_from | Bsns_to |
|---|---|---|---|---|---|---|
| one | ten | ten | 2015-01-01 | 2015-02-10 | 2014-12-01 | 2999-12-31 |
| one | ten | ten | 2015-02-10 | 2999-12-31 | 2014-12-01 | 2015-01-03 |
| one | eleven | ten | 2015-02-10 | 2015-02-23 | 2015-01-03 | 2999-12-31 |
| one | eleven | ten | 2015-02-23 | 2999-12-31 | 2015-01-03 | 2015-03-30 |
| one | eleven | 100 | 2015-02-23 | 2999-12-31 | 2015-03-30 | 2999-12-31 |
The idea is to keep a history of history changes. Consider processing the first two entries from staging. There are no problems with the first recording - at the time of its loading there is no question of processing changes. An entry is added to the satellite stating that the attribute key (10.10) for a given key is “for centuries”. The second entry from staging contains an update for one of the attributes, with the result that the vector took on the value (11,10). To handle this event, you need to do three things:
- Save information that in the period from the moment of receiving data on the first value (10.10) until receiving data on the second (11.10) we thought that the value (10.10) is “for centuries”. To do this, we update the first record by closing the interval of "technical" relevance, leaving the "business" open.
- From the moment of receiving the data (11.10) we know that the value (10.10) was relevant only in a certain period of time, and this knowledge of ours is no longer subject to revision. To save this information, we inserted a second entry with (10.10) with an open interval of “technical” relevance, but with a closed “business” one.
- In order to preserve our current view that the value (11.10) is really now and will be so for an indefinite future, the third entry is inserted with this value of the attribute vector and the open intervals of “technical” and “business” relevance (on the slide at this the "technical" interval is closed, because the satellite contains the results of processing subsequent updates).
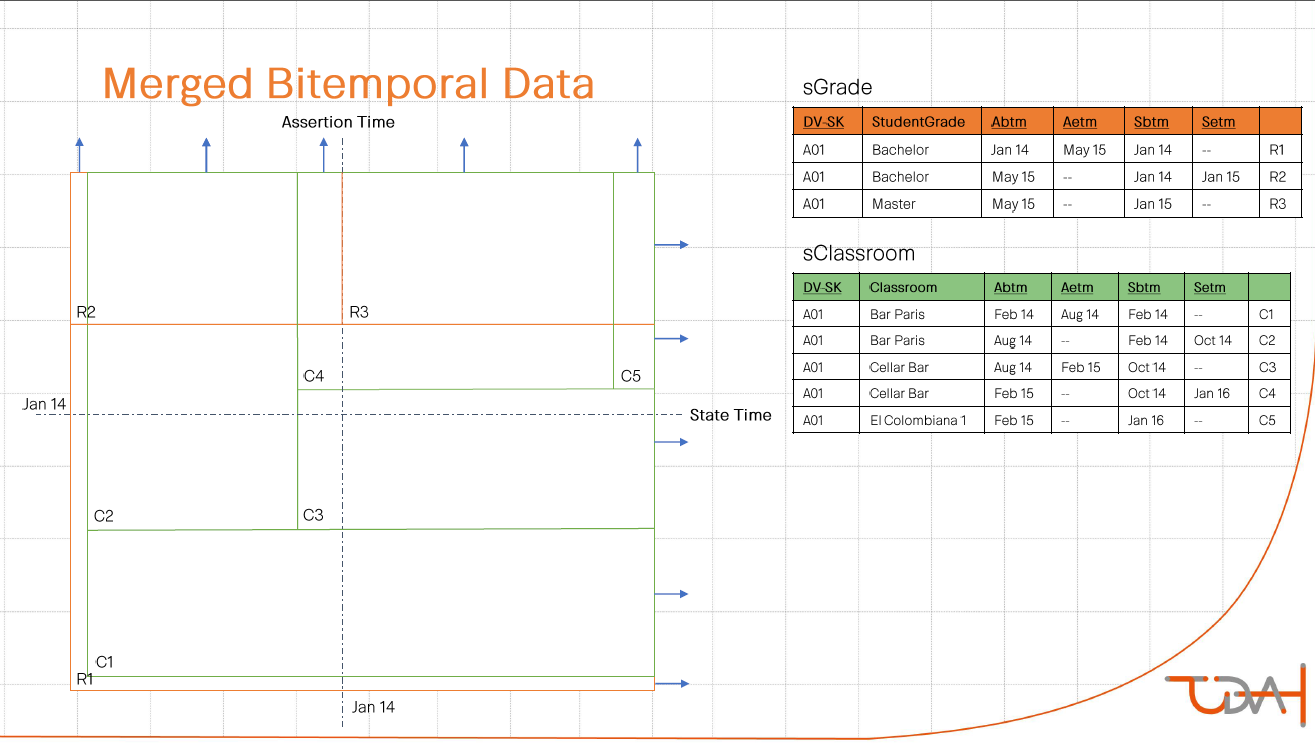
The next example, the students decided on their own. It dealt with the student schedule.
A curious visualization was used to demonstrate the solution. Double historicity was presented in the form of a coordinate plane. On the x-axis - business time, on the y-axis - technical. Each entry corresponds to one of the areas of the plane. Cutting goes diagonally - right and up.
The final example was the most difficult. Baseline - a plan for price changes in relation to the day of the Black Friday marketing campaign.
Staging table
| Product | Price | Daystart | Dayand | STG Load DTS |
|---|---|---|---|---|
| Jeans | 100 | D1 | Bf | D1 |
| Jeans | 80 | Bf | Bf + w | D1 |
| Jeans | 110 | Bf + w | 9999 | D1 |
| Jeans | 95 | D1 | Bf | D10 |
| Jeans | 82 | Bf | Bf + 2w | D10 |
The difficulty was that the plan was revised not only in terms of changing the price itself, but also in terms of breaking down the time continuum of the solution. I note that the key to the success of the assignment was to understand that for any moment of “technical” time in the repository there must be data that fully covers the entire “business” chronology. Not without effort, the task was solved “on a piece of paper”, but the question of automating this not very trivial algorithm remained open.
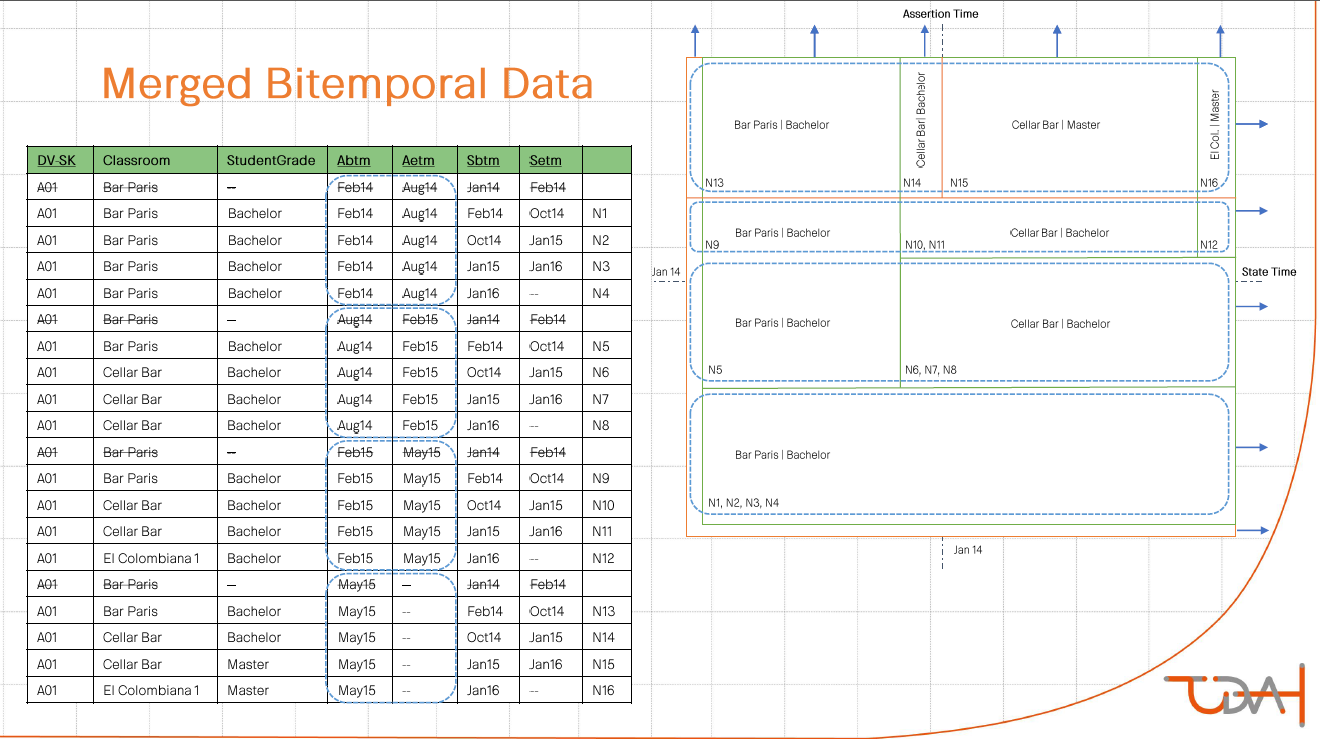
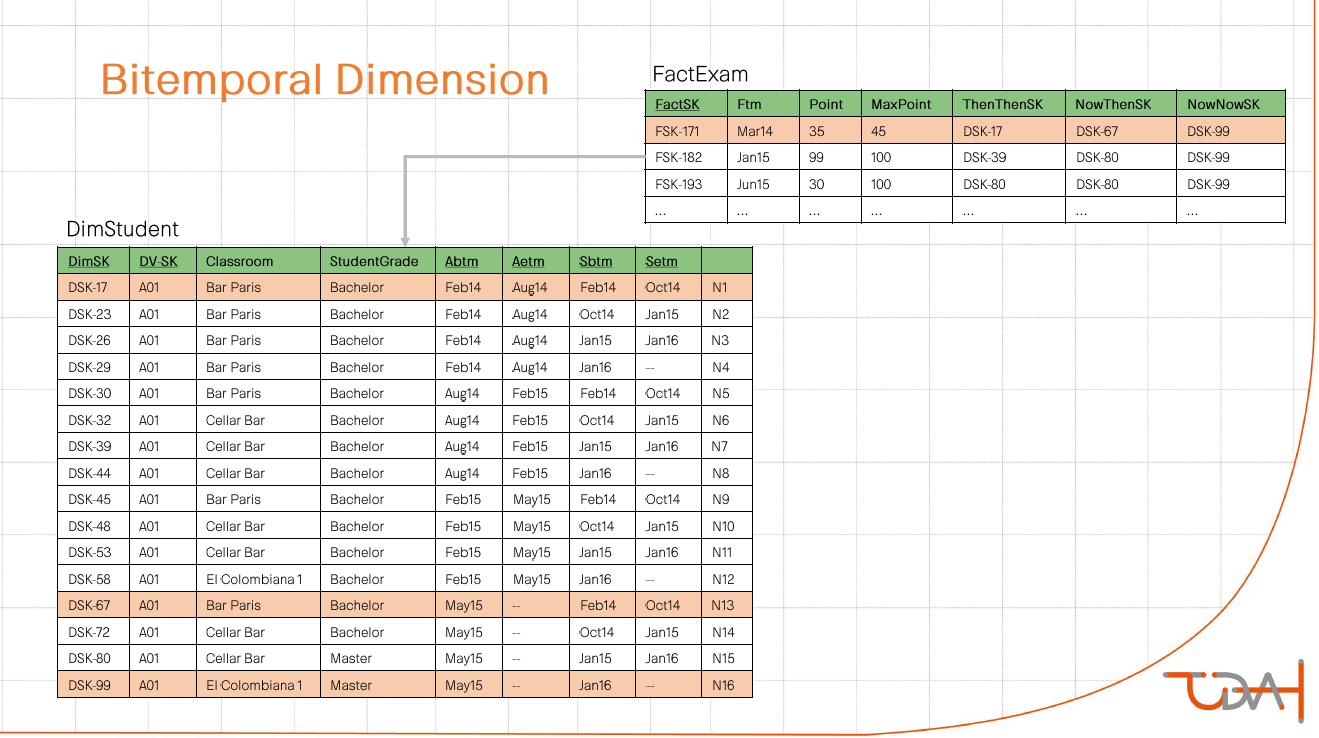
The next item on the program was a description of how to merge information from two satellites with dual historicity into one dimension. For the demonstration, we chose an example with a student with a specific class schedule. He has a history of degree change. The essence of the proposed method: cross join with the collapse of consecutive intervals.
The last considered aspect of this topic was the variability in the interpretation of information obtained at the output. There is a fact that the student has passed the exam. Information about the schedule and degree of the student for this fact we can determine in three different ways:
- What we know now about the schedule and degree, relevant today.
- What we know now about the schedule and degree, relevant at the time of the exam.
- What we knew at the time of the exam about the schedule and extent relevant at the time of the exam.
Perhaps this presentation was the most informative and informative for me personally. After it was followed by a block of performances in the genre of key notes.
Official opening
The organizers uttered a set of on-duty phrases, of which the mention of gender distribution among the participants was remembered: 165 men to 17 women. After that, the “rock star” of data modeling appeared on the scene, the author of numerous books on the topic is Steve Hoberman. Steve told that today the most popular IT issues in this area are nosql databases and the cultivation of new modelers. At the second, he stopped in more detail, saying that the growth in the volume of metadata greatly exceeds the growth in the number of modelers. In this regard, he identified the 5 most popular skills in the coming years:
- Communication
- Modeling
- Data Management in the Agile Paradigm
- Knowledge of various types of DBMS
- Knowledge of business processes
Data, a Managerial Perspective
The next speaker was the architect of the data from the Central Bank of the Netherlands - Ronald Damkhov. Ronald told how he and his colleagues managed to build a repository on the principle of "multireality". It was about the methodology, which:
- provides for both the completeness of reflection of sources, and an adequate representation of the business context;
- allows you to use the advantages of a flexible approach to development, together with a clear regulation of the processes of change.
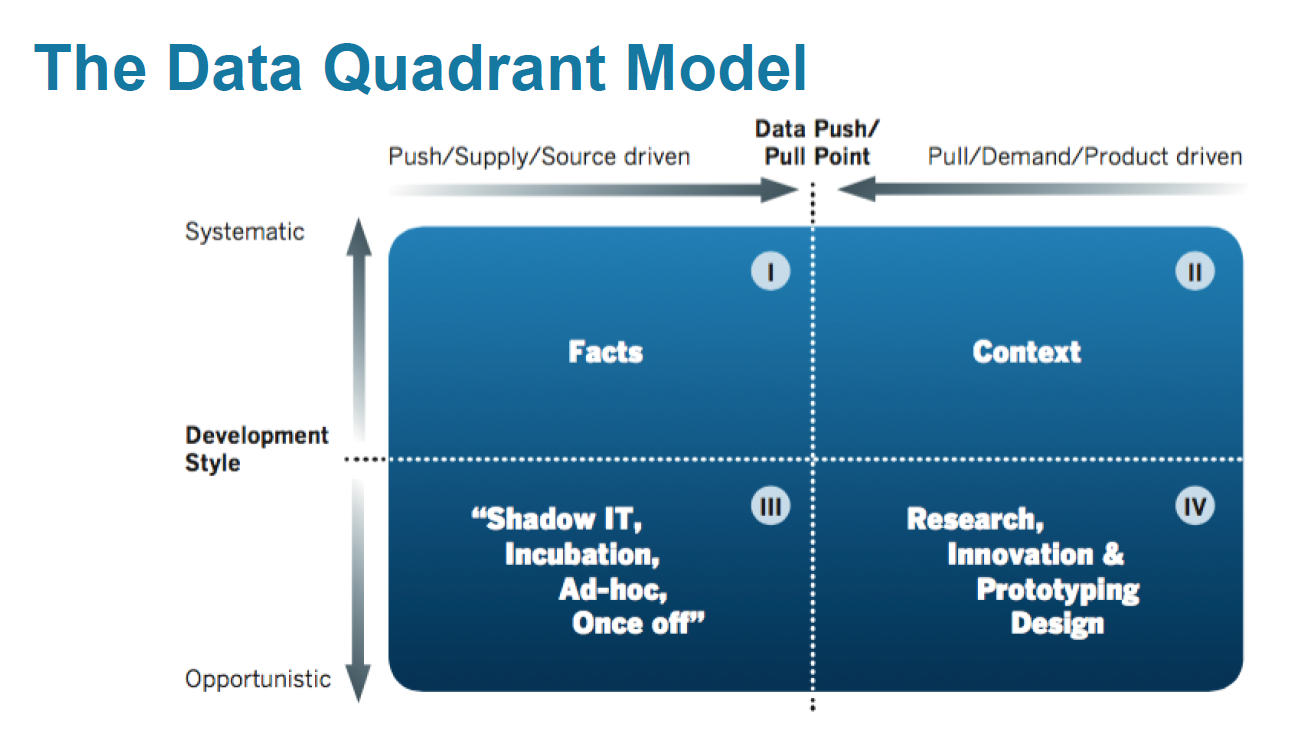
The idea is to present all the repository in the form of a quadrant, built in the coordinate system "flexibility-systematization" + "sources-business" and divided into 4 sectors:
At the same time, it was emphasized that the division of data into “master data”, “big data”, “metadata” and others is inefficient.
In the resulting coordinate system, there was an order of solving each of the 7 main tasks in designing the CD:
- Building
- Automation
- Systematization
- Control
- User Access
- Manufacturability
- Modeling
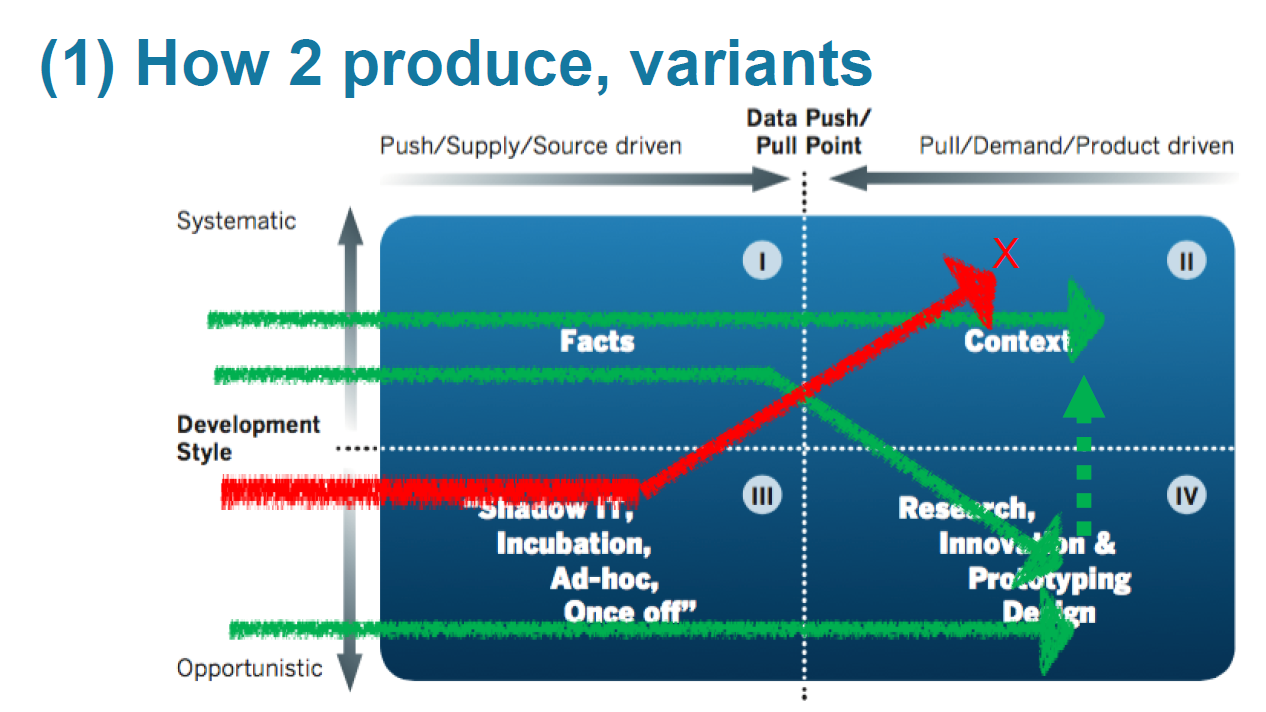
For the solution of the issue of construction, for example, suggested options (green - ok, red - not ok):
The blockchain billionaire
After Ronald, Steve Hoberman took the floor again. He told how the main determining factor in the development of IT in the next decade, the blockchain technology, affects data modeling issues. Since Steve is a guru of modeling everything and everything, the blockchain was immediately defined as a logical data model.
According to Steve, the blockchain will be most strongly influenced in data management, data standardization and storage architecture design. Blockchain is unlikely to touch the vector of relational database development. But how it will affect the Agile methodology is not yet clear.
Curiously, as an example of the spread of this technology, Steve spoke about the Ukrainian project, in which it is proposed to switch to the use of cryptocurrency for the calculation of state property sales transactions. This should help in the fight against corruption.
Introducing the DAMA DMBOK2 certification
Everyone was invited to practice in the delivery of the most famous in the field of data management certification DAMA DMBOK2. The training version of the exam included 20 questions. For example:
- Who is the “provider” in the context of the data management process?
- What activities are included in the data development process?
- What support actions are basic to building a reliable data storage system?
- Who is most interested in a well-implemented data management process?
And so on.
Curious theory. Rather abstract, at the same time consistent and logical.
Wherescape test drive
Initially, a demonstration of a system providing a complex of services for building a storage architecture was planned in a seminar format. But the notebooks turned out to be much smaller than the participants, so the format was changed to a presentation.
As a preamble, a number of statements of the “Volga flows into the Caspian Sea” class were declared. For example, that the main thing is to listen to business, and automation is part of the process, not a technical solution. For example, a failed project was cited with a customer represented by a Russian company, whose representatives "believed that they were buying a magic wand by buying a system." After the presentation, I went to ask more details about this project. But all that he heard was a request not to perceive these words as a blasphemy of the Russian people - “this error is peculiar to all.” At the end of the introductory section, the Power Designer was thoroughly criticized - old, ugly, complicated, there is no point in storing a version.
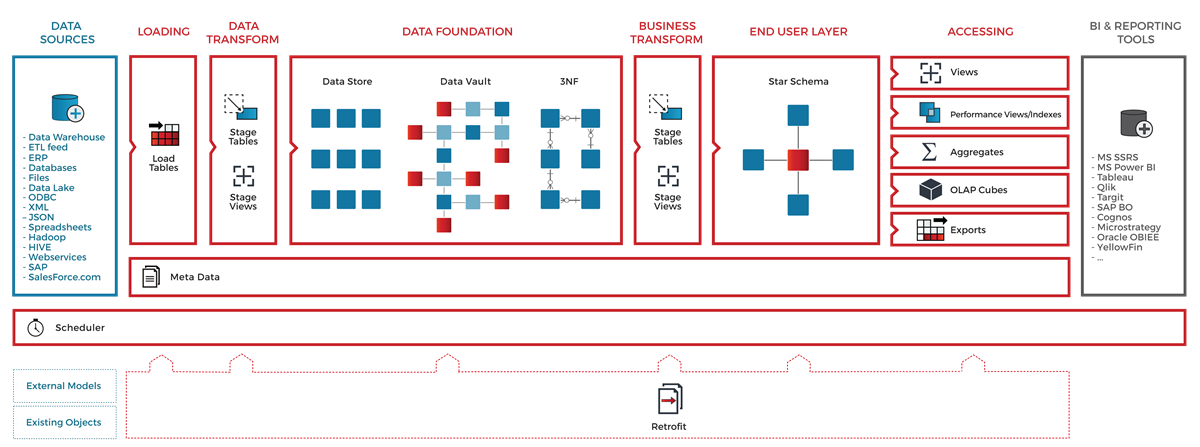
The system itself during the demonstration looked really impressive. In the case, we saw only a part of the capabilities, but it was stated that WhereScape Red provides a complete set of options for managing metadata and ETL. As a confirmation, a scheme was presented in which the standard elements of the storage architecture covered by the functionality of the system were marked in red:
We started with the fact that the models of source systems are described, their changes are tracked. The modeling process itself consists in the construction of a logical model of custom storefronts and the definition of the mapping of their fields with sources. After that, pressing the magic button starts the process of automatically building a model of the staging layer and data vault in accordance with the pre-configured rules. The final step was to generate the ETL code and define the schedule. In the examples of the tutorial class, everything worked, of course, smoothly and elegantly. Among the features, I would single out the line by column. There are no verification and validation changes yet, but they should appear in the nearest release. More about the capabilities of the system can be found on the vendor page .
How to sell Data Vault to non-technical people
The first day ended with an amateur humorous show. Scenes of two adult men, the leitmotiv of which was self-irony about the rush around the Data Vault, bored after the first 15 minutes, although the whole presentation lasted more than an hour. Looking at the number of phone screens burning in the dark, it was hard not to feel sympathy for the speakers of the uncles.
2nd day
Developing Corporate Model Using Patterns
The three-hour seminar of the Australian John Gillz was essentially a summary of his 2012 book The Nimble Elephant. The topic is useful and does not lose its relevance. It is about using industrial templates when designing a model. Currently, large vendors (for example, IBM and TeraData) offer ready-made high-level model templates for different subject areas - “Industry Reference Model”. The most common classification of entities in many templates is the same. The concept that John talked about is no exception. It involves the use of types:
- Participant and role
- Product
- Resource
- The task
- Score
- Agreement
- Document
- Event
- Location
At the seminar, participants had to build a data model describing this business process based on the description of the company's production activities. It was suggested to do this with:
- creating subtypes of different levels of nesting in relation to the listed initial types;
- identifying links between them.
In addition, John presented an exact schedule for building a data model using this approach:
- 1 week: introduction, draft conceptual model.
- 2–4 weeks: seminars on problem areas, iterative development of the conceptual model through refinement, creation of extensions of basic entities.
- Week 5: Business prioritizes, IT begins development.
- 6-8 weeks: building a prototype, launching the process of agile development.
The resulting conceptual model can be used not only to build a logical model of HD, but also as a single formalized enterprise business model, in accordance with which you should create logical data models of operating business systems.
Advanced Data Modeling Challenges
The second seminar I was able to attend was conducted by Steve Hoberman. Steve is known not only for his books and the patented Data Model Scorecard quality system. He is also popular as a teacher in seminars and courses on the topic. In general, he confirmed his reputation: telling is available, interesting and with humor. True, the name of the seminar did not correspond to reality: it was about important and useful, but still basic principles for building a model.
First, he spoke about the concept of super-entities and their extensions, which overlapped with the content of the previous seminar. Then the task followed: it was necessary to study a small set of data presented in a flat denormalized shop window and describing the assortment of a bookstore, and build a 3NF model. According to Steve, performing this task, we had to feel like archaeologists of the data.
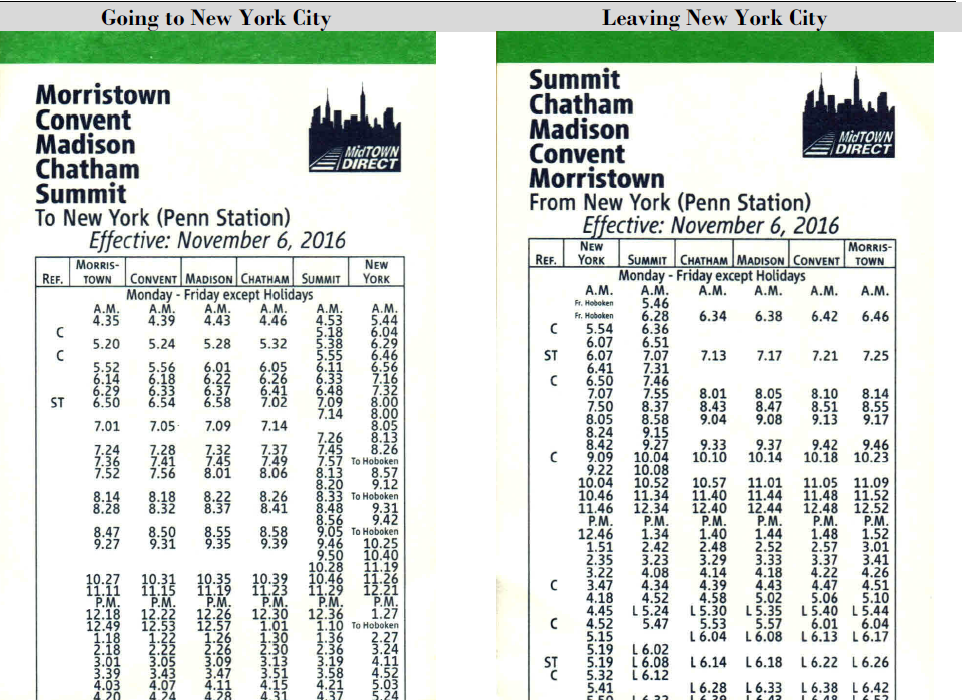
The next assignment was more entertaining. The initial data was the schedule of suburban trains in one of the directions in the vicinity of New York.
The task was to design a data model, on the basis of which it is possible to build an analyst on the quality of work of electric trains, namely, how precisely the schedule is fulfilled. The target model had to provide for the preservation of data on the schedule and on the actual train schedule. The models represented by the three teams did not practically differ in the set of entities, except for differences in names. What we call “branch” or “line” in different models was called: line, journey, route, trip, and “haul” - link or leg. From this, one of the obvious, but extremely important rules of modeling was derived - the need to provide a clear, most comprehensive definition of the entities represented in the model. The fundamental difference between the models was the way of saving actual data on train traffic: in some models, the granularity of these data was defined as the fact of the train arrival from the initial station to the given one. An alternative approach was to keep the train moving between two neighboring stations. In the course of comparing the two methods, we came to the conclusion that it is important when building a model to remember which process we want to measure with its help.
In addition, the paradigms of building logical models differed: one team chose Multi-Dimensional, the rest 3NF. On the basis of this, we formulated a thesis on the priority of creating a qualitative conceptual model, which can easily be converted into Multi-Dimensional, 3NF, Data Vault, and so on.
Designing the Dream - Why Enterprises Need Architects
Extensive philosophical presentation of the role of architects in the modern world. The key idea is best expressed by the quote by architect Norman Foster:
“ As an architect you design for the present,
with an awareness of the past
for a future which is essentially unknown . ”
Of the great ones, Aristotle was still quoted with his words that architecture rests on three pillars: durability, beauty and functionality.
It was something about everything and about an hour-long in keynote format. Among other things, it is worth highlighting the extremely important observation: the architect of the building differs from the architect of the industrial system in that it is not built into the object of his creation.
Business Milestones and Data Models
Not the most exciting presentation on how to properly save the history of the entity. Key thoughts:
- It is necessary to save history as much as possible, without any analysis.
- It is important to separate the state of the entity and the new entity (candidate - employee, attire - order).
- Not all entity statuses are equally useful for analytics - you need to collapse.
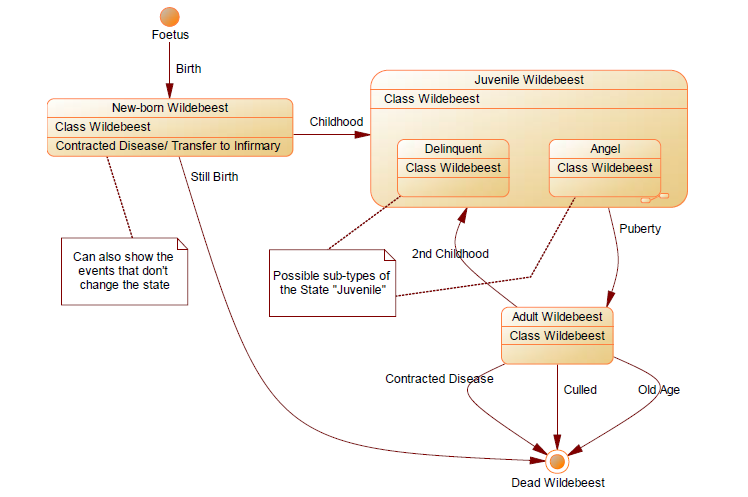
To demonstrate these good and important thoughts, a primitive example was chosen with the wildebeest life cycle model:
And to consolidate the information received, we were offered to build a data model that would automate the process of clearing bank checks. Either the task was formulated too abstractly, or the participants were tired by the end of the second day, but in the end there were no ready-made solutions.
Migrating an Enterprise DW from “traditional” to Data Vault based
The author is Gabor Golnhofer, an architect with 20 years of experience in HD projects in finance, insurance, telecom, retail and education. The project presented was to transfer the repository of indefinitely mixed architecture to the Data Vault. The name of the company-customer was not called, they said only that it is the market leader in its field in Hungary and is part of an international holding. According to the "tactical and technical characteristics" their storage is comparable to our Tinkoff DWH:
- 40+ source systems
- Milestones: 1998 - beginning, 2008 - SAS → Oracle, 2016 - Data Vault.
- 22 TB, 5000 target tables, 9000 ETL jobs.
From a technical point of view, the main prerequisite for rebuilding the repository was the high cost of the process of improvements and performance problems. In addition, 20 years of evolution, including the transition from 3NF to Dimensional and the introduction of versioning, led to architectural chaos. From the business side, there were requirements: high speed of changes, completeness of history preservation, opportunities for self-service BI. In short, as usual - more, faster and cheaper.
I am sure that the main problems encountered by my colleagues are familiar to many. This is the absence of suitable business keys in the source data, only surrogate, and the poor quality of the source data, and integrity breaches in the sources. Also, a lot of effort had to be spent on automating the construction of Dimensional - windows based on DV - and the development of ETL-procedure templates for loading large data arrays. Perhaps the key feature of the project was the emphasis on automating model changes and ETL, resulting in:
- significantly increased the rate of change,
- reduced the number of bugs
- the quality and completeness of the documentation has increased,
- the ratio of developers and analysts in the team has changed in favor of the latter.
In addition, it was rightly argued that Data Vault is useful in data quality control, because it allows you to save "facts" rather than "truth."
The report was interesting and informative. In a personal conversation after the presentation, Gabor agreed that the Data Vault should not be perceived as a dogma, but adapted to the needs of a specific project.
Total
Summarizing the content of the conference, I note:
- Using Data Vault (Anchor Modeling - as an option) - the gold standard of DWH.
- The trend of today is automation [of creating metadata, generating ETL code, QA].
- The trend of tomorrow is the vault in the cloud.
- Good business knowledge is a prerequisite for building a good model.
There were not enough presentations of real projects telling about ways of solving real, rather than hypothetical problems that project teams face when using beautiful and slim [on paper] methodologies, about adapting such approaches to the harsh prose of life.
If we talk about the general impression, the main effect is motivating. Motivating to read more about the approaches presented. Motivating to do this rather popular business. Perhaps DWH analysts with experience of up to three years would be primarily interested in the presentations themselves, and their older fellow architects would find more pleasure in communicating with colleagues on the margins. Personally, I managed to get acquainted with several colleagues from Europe, America, and, oddly enough, Russia. Lucky to talk with some gurus. By the way, Hans Haltgren in a personal conversation said that the two Russian guys with whom he works in the Valley are simply “amazing”. And left an autograph on his, perhaps, the most popular book about Data Vault.
Source: https://habr.com/ru/post/346446/
All Articles