How it works: Merkle trees in the bitcoin network
Nodes in the blockchain network are anonymous and operate in the absence of trust. In this situation, the problem of data verification arises: how to verify that the correct transactions are recorded in the block? It will take a lot of time and computing resources to evaluate each unit. To solve the problem and simplify the process help trees Mercle.
What it is, how it is used, what alternatives exist - we will tell further

/ image Allison Harger CC
')
Blocks in a bitcoin blockchain are permanently written files that contain information about transactions performed by users. Additionally, each block contains a Generation Transaction (or Coinbase Transaction ) - this is a transaction with address information with a reward for solving a block, which is always first on the list.
All transactions in the block are represented as strings in hexadecimal format (raw transaction format), which is hashed to obtain transaction identifiers (txid). On their basis, a hash of the block is built, which is taken into account by the subsequent block, ensuring the immutability and coherence of the registry. The unit hash value is collected using the Merkle tree, the concept of which was patented by Ralph Charles Merkle in 1979.
A Merkle tree , or hash tree, is a binary tree whose leaf nodes are transaction hashes, and internal vertices are the results of the addition of the values of the associated vertices. Here is an example of a hash tree with three leaf transactions:
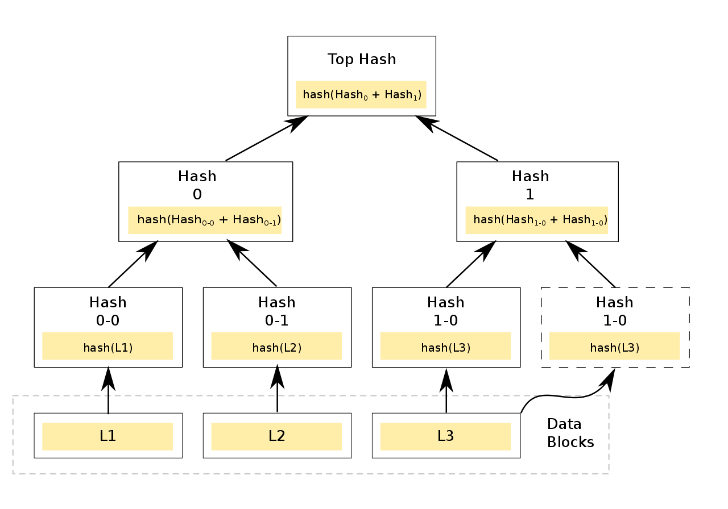
/ image MrTsepa CC
The construction of the tree is as follows:
In the bitcoin blockchain, Mercle trees are constructed using SHA-256 double hashing. Here is an example of hashing the string hello:
First round SHA-256:
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
Round two:
9595c9df90075148eb06860365df33584b75bff782a510c6cd4883a419833d50
And here is an example of the implementation of the Merkle trees used by Bitcoin in Python (you can find the results of the function in the repository on GitHub by the link ):
File systems use Merkle trees to check information for errors, and distributed databases use data synchronization. In blockchains, hash trees allow for a simplified payment verification (SPV).
SPV clients, called light (because they store only block headers, not their contents), do not recalculate all the hashes to verify the transaction information, but ask for Merkle’s proof. It consists of a root and a branch, including hashes from the requested transaction to the root, since the client does not need information about other operations. By adding the requested hashes and comparing them with the root, the client makes sure that the transaction is in its place.
This approach allows you to work with arbitrarily large amounts of data, since it significantly reduces the load on the network, since only the necessary hashes are downloaded. For example, the weight of a block with five maximum size transactions is more than 500 kilobytes. The weight of the proof of Merkle in the same case will not exceed 140 bytes.
Binary trees of Merkle are well suited for verifying the sequence of elements, so they cope with the task of storing the transaction structure. However, they limit the ability of light clients who do not receive information about the state of the system. For example, it is not possible to find out how many coins there are at the specified address.
To circumvent the constraints, researchers and developers are upgrading existing algorithms and developing new ones. For example, the Ethereum blockchain platform uses the so-called Merkle prefix tree (Trie). This is a data structure that stores an associative array with keys.
Unlike binary Merkle trees, the key that identifies a particular tree node is “dynamic”. Its value is determined by the location on the tree and is formed by connecting the characters assigned to the edges of the graph, passing from the root to the specified node.
In Ethereum, the block header contains three Merkle prefix trees at once: for transactions, information on their execution and status. This approach allowed easy customers to receive answers from the system to the questions: “Is there a transaction in the specified block?”, “How many coins are in the account?” And “What will the system state be after the completion of this transaction?”.
Another alternative to classic Mercle trees is the HashFusion hash value combination method proposed by Hewlett Packard Labs. As noted in the company, the new approach allows calculating hash values in stages. The components of the hash are calculated as soon as the data becomes available, and then merged with each other if necessary.
HashFusion involves building parts of a hash using a binary merge function. It is associative and non-commutative, so it can be used to combine hashes at the time of formation. This allows you to reduce the amount of memory needed to store them.
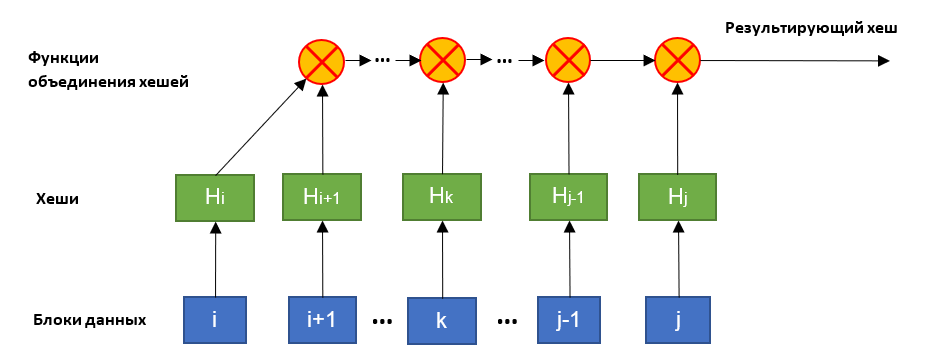
The operation of a binary function is constructed as follows: it accepts hash values (generated by classical hashing functions) as input and converts them into matrices of integers. Then the matrices are multiplied, and the result is turned back into a byte array of fixed length.
HPE representatives say that HashFusion implements more flexible structures than Merkle trees, which allow you to update existing hashes and selectively delete / insert new values. The authors hope that in the future the technology will find application in file systems, cloud solutions and distributed registries.
There are other algorithms that the IT community is developing to optimize metadata processing and build Merkle trees. Among them is the iSHAKE solution, the author of which proposes to replace the process of building hash trees with the introduction of a reversible operation. It will allow to restore / add and delete new values from the structure. You can also note the modified algorithm for digital signature organization eXtended Merkle Signature Scheme (XMSS) and the SPHINCS algorithm.
Most of these proposals are at the testing stage and have not yet found wide application - however, some of them are predicting a great future in the world of post-quantum cryptography .
PS On January 25, Bitfury in Kiev will hold a free workshop, during which practical features of development using Exonum will be disassembled.
Our experts will tell and show how to deploy your own blockchain and how to write a service. The meeting will be useful to developers on Rust, C ++ and JavaScript, making the first steps in blockchain development, as well as those who have already tried to create blockchain solutions.
You can find out more information about the event and speakers, as well as register for the event here .
What it is, how it is used, what alternatives exist - we will tell further
/ image Allison Harger CC
')
The Merkle Tree - What It Looks Like
Blocks in a bitcoin blockchain are permanently written files that contain information about transactions performed by users. Additionally, each block contains a Generation Transaction (or Coinbase Transaction ) - this is a transaction with address information with a reward for solving a block, which is always first on the list.
All transactions in the block are represented as strings in hexadecimal format (raw transaction format), which is hashed to obtain transaction identifiers (txid). On their basis, a hash of the block is built, which is taken into account by the subsequent block, ensuring the immutability and coherence of the registry. The unit hash value is collected using the Merkle tree, the concept of which was patented by Ralph Charles Merkle in 1979.
A Merkle tree , or hash tree, is a binary tree whose leaf nodes are transaction hashes, and internal vertices are the results of the addition of the values of the associated vertices. Here is an example of a hash tree with three leaf transactions:
/ image MrTsepa CC
The construction of the tree is as follows:
- The hashes of transactions placed in the block are calculated: hash (L1), hash (L2), hash (L3), and so on.
- Hashes are calculated from the sum of transaction hashes, for example hash (hash (L1) + hash (L2)). Since the Merkle tree is binary, the number of elements at each iteration must be even. Therefore, if a block contains an odd number of transactions, then the latter is duplicated and added to itself: hash (hash (L3) + hash (L3)).
- Further, hashes are calculated from the sum of hashes again. The process is repeated until a single hash is obtained - the root of the Merkle tree (merkle root). It is a cryptographic proof of the integrity of the block (that is, that all transactions are in the stated order). The root value is fixed in the block header.
In the bitcoin blockchain, Mercle trees are constructed using SHA-256 double hashing. Here is an example of hashing the string hello:
First round SHA-256:
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
Round two:
9595c9df90075148eb06860365df33584b75bff782a510c6cd4883a419833d50
And here is an example of the implementation of the Merkle trees used by Bitcoin in Python (you can find the results of the function in the repository on GitHub by the link ):
import hashlib def merkle_root(lst): sha256d = lambda x: hashlib.sha256(hashlib.sha256(x).digest()).digest() hash_pair = lambda x, y: sha256d(x[::-1] + y[::-1])[::-1] if len(lst) == 1: return lst[0] if len(lst) % 2 == 1: lst.append(lst[-1]) return merkle_root([ hash_pair(x, y) for x, y in zip(*[iter(lst)] * 2) ]) What are the hash trees for
File systems use Merkle trees to check information for errors, and distributed databases use data synchronization. In blockchains, hash trees allow for a simplified payment verification (SPV).
SPV clients, called light (because they store only block headers, not their contents), do not recalculate all the hashes to verify the transaction information, but ask for Merkle’s proof. It consists of a root and a branch, including hashes from the requested transaction to the root, since the client does not need information about other operations. By adding the requested hashes and comparing them with the root, the client makes sure that the transaction is in its place.
This approach allows you to work with arbitrarily large amounts of data, since it significantly reduces the load on the network, since only the necessary hashes are downloaded. For example, the weight of a block with five maximum size transactions is more than 500 kilobytes. The weight of the proof of Merkle in the same case will not exceed 140 bytes.
Analogs of Merkle Trees
Binary trees of Merkle are well suited for verifying the sequence of elements, so they cope with the task of storing the transaction structure. However, they limit the ability of light clients who do not receive information about the state of the system. For example, it is not possible to find out how many coins there are at the specified address.
To circumvent the constraints, researchers and developers are upgrading existing algorithms and developing new ones. For example, the Ethereum blockchain platform uses the so-called Merkle prefix tree (Trie). This is a data structure that stores an associative array with keys.
Unlike binary Merkle trees, the key that identifies a particular tree node is “dynamic”. Its value is determined by the location on the tree and is formed by connecting the characters assigned to the edges of the graph, passing from the root to the specified node.
In Ethereum, the block header contains three Merkle prefix trees at once: for transactions, information on their execution and status. This approach allowed easy customers to receive answers from the system to the questions: “Is there a transaction in the specified block?”, “How many coins are in the account?” And “What will the system state be after the completion of this transaction?”.
Another alternative to classic Mercle trees is the HashFusion hash value combination method proposed by Hewlett Packard Labs. As noted in the company, the new approach allows calculating hash values in stages. The components of the hash are calculated as soon as the data becomes available, and then merged with each other if necessary.
HashFusion involves building parts of a hash using a binary merge function. It is associative and non-commutative, so it can be used to combine hashes at the time of formation. This allows you to reduce the amount of memory needed to store them.
The operation of a binary function is constructed as follows: it accepts hash values (generated by classical hashing functions) as input and converts them into matrices of integers. Then the matrices are multiplied, and the result is turned back into a byte array of fixed length.
HPE representatives say that HashFusion implements more flexible structures than Merkle trees, which allow you to update existing hashes and selectively delete / insert new values. The authors hope that in the future the technology will find application in file systems, cloud solutions and distributed registries.
There are other algorithms that the IT community is developing to optimize metadata processing and build Merkle trees. Among them is the iSHAKE solution, the author of which proposes to replace the process of building hash trees with the introduction of a reversible operation. It will allow to restore / add and delete new values from the structure. You can also note the modified algorithm for digital signature organization eXtended Merkle Signature Scheme (XMSS) and the SPHINCS algorithm.
Most of these proposals are at the testing stage and have not yet found wide application - however, some of them are predicting a great future in the world of post-quantum cryptography .
PS On January 25, Bitfury in Kiev will hold a free workshop, during which practical features of development using Exonum will be disassembled.
Our experts will tell and show how to deploy your own blockchain and how to write a service. The meeting will be useful to developers on Rust, C ++ and JavaScript, making the first steps in blockchain development, as well as those who have already tried to create blockchain solutions.
You can find out more information about the event and speakers, as well as register for the event here .
Source: https://habr.com/ru/post/346398/
All Articles