How I Parsil Habr, Part 1: Trends
When the New Year's Eve was finished, I had nothing to do, and I decided to download all articles from Habrahabr (and adjacent platforms) to my computer and search.
It turned out a few interesting stories. The first of these is the development of the format and theme of articles over the 12 years of the site’s existence. For example, the dynamics of some topics are quite indicative. Continued - under the cut.

Parsing process
To understand how Habr developed, it was necessary to bypass all his articles and select meta-information from them (for example, dates). The walk was easy because the links to all the articles look like "habrahabr.ru/post/337722/", and the numbers are strictly in order. Knowing that the last post has a number slightly less than 350 thousand, I simply went through all possible id documents with a loop (Python code):
import numpy as np from multiprocessing import Pool with Pool(100) as p: docs = p.map(download_document, np.arange(350000)) The download_document function tries to load the page with the corresponding id and tries to pull out the content information from the html structure.
import requests from bs4 import BeautifulSoup def get_doc_by_id(pid): """ Download and process a Habr document and its comments """ # r = requests.get('https://habrahabr.ru/post/' +str(pid) + '/') # soup = BeautifulSoup(r.text, 'html5lib') # instead of html.parser doc = {} doc['id'] = pid if not soup.find("span", {"class": "post__title-text"}): # , doc['status'] = 'title_not_found' else: doc['status'] = 'ok' doc['title'] = soup.find("span", {"class": "post__title-text"}).text doc['text'] = soup.find("div", {"class": "post__text"}).text doc['time'] = soup.find("span", {"class": "post__time"}).text # create other fields: hubs, tags, views, comments, votes, etc. # ... # fname = r'files/' + str(pid) + '.pkl' with open(fname, 'wb') as f: pickle.dump(doc, f) In the process of parsing discovered a few new moments.
First, they say that creating more processes than cores in a processor is useless. But in my case it turned out that the limiting resource is not a processor, but a network, and 100 processes work faster than 4 or, say, 20.
Secondly, in some posts there were combinations of special characters - for example, euphemisms like "% & # @". It turned out that html.parser , which I used first, reacts to the &# painful combination, considering it to be the beginning of an html entity. I was going to create black magic, but the forum suggested that you can just change the parser.
Thirdly, I managed to unload all publications, except for three. Documents numbered 65927, 162075, and 275987 instantly deleted my antivirus. These are, respectively, articles about a chain of javascripts, downloading a malicious pdf, an SMS ransomware in the form of a set of browser plug-ins, and the website CrashSafari.com, which sends iPhones to reload. I found another antivirus article later, during a system scan: post 338586 about scripts on the pet store website that use the user's processor for mining cryptocurrency. So you can consider the work of the antivirus is quite adequate.
“Live” articles were only half of the potential maximum - 166307 pieces. About the others Habr gives options "the page became outdated, was removed or did not exist at all". Well, anything can happen.
The unloading of the articles was followed by technical work: for example, the publication date had to be transferred from the format "December 21, 2006 at 10:47" to the standard datetime , and "12.8k" views - to 12800. At this stage, several other incidents got out. The most fun is related to the counting of votes and data types: in some old posts an overflow occurred, and they received 65535 votes each.

As a result, the texts of the articles (without pictures) occupied me 1.5 gigabytes, comments with meta-information - another 3, and about a hundred megabytes - meta-information about articles. This can be fully kept in RAM, which was a pleasant surprise for me.
I began analyzing articles not from the texts themselves, but from meta-information: dates, tags, hubs, views and likes. It turned out that she can tell a lot.
Development Trends Habrahabra
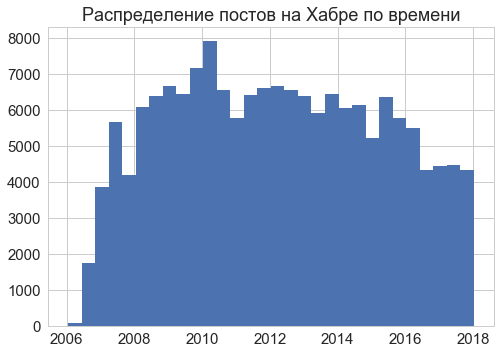
Articles on the site have been published since 2006; the most intense - in 2008-2016.
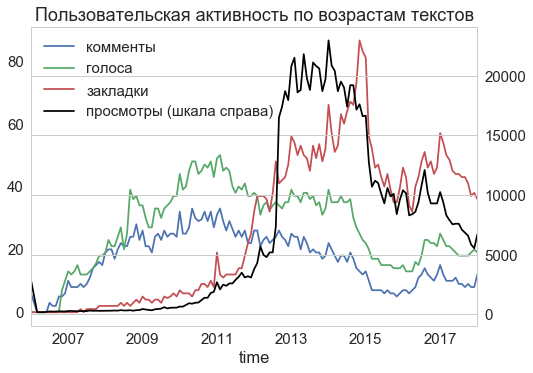
How actively these articles were read at different times is not so easy to evaluate. Texts of 2012 and younger commented and rated more actively, but newer texts have more views and bookmarks. These metrics only behaved (halved) only once, in 2015. Perhaps in a situation of economic and political crisis, the attention of readers shifted from IT blogs to more painful issues.
In addition to the articles themselves, I deflated more comments to them. There were 6 million comments, however, 240 thousand of them were banned ("the UFO flew in and posted this inscription here"). A useful feature of comments is that time is indicated for them. Studying the time of comments, you can roughly understand and when all the articles are read.
It turned out that most of the articles were both written and commented from 10 to 20 hours, i.e. in a typical Moscow working day. This may mean that Habr is read for professional purposes, and that this is a good way to procrastinate at work. By the way, this distribution of time of day is stable from the very foundation of Habr to the present day.

However, the main advantage of the comment timestamp is not the time of day, but the term of the “active life” of the article. I calculated how time is allocated from the publication of the article to its comment. It turned out that now the median comment (green line) comes in about 20 hours, i.e. on the first day after publication, on average, slightly more than half of all comments on the article are left. And for two days leave 75% of all comments. At the same time, the articles were read even faster - in 2010, half of the comments came in the first 6 hours.

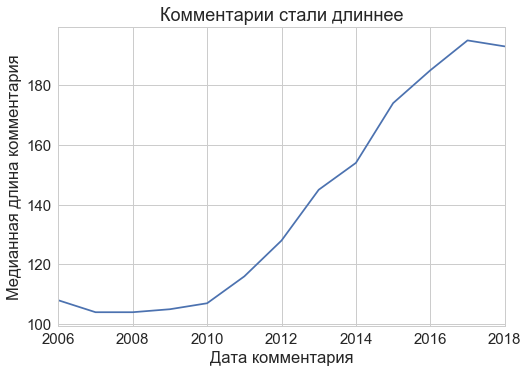
It came as a surprise to me that the comments were lengthened: the average number of characters in the comments during the existence of Habr almost doubled!
Easier feedback than comments are votes. Unlike many other resources, on Habré you can put not only pluses, but also minuses. However, readers use the last opportunity not so often: the current share of dislikes is about 15% of all the votes cast. It used to be more, but over time, readers have become more willing.

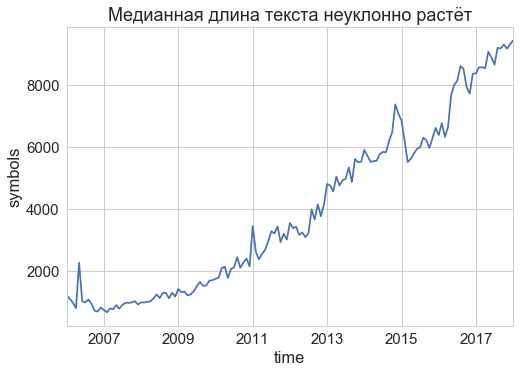
The texts themselves have changed over time. For example, the typical length of the text does not stop steadily growing from the very launch of the site, despite crises. Over the decade, the texts have become almost ten times longer!
The style of the texts (as a first approximation) also changed. For the first years of Habr's existence, for example, the share of code and numbers in texts increased:

Having dealt with the overall dynamics of the site, I decided to measure how the popularity of various topics changed. Topics can be extracted from texts automatically, but for a start, you can not reinvent the wheel, but use ready-made tags put down by the authors of each article. I have drawn four typical trends on the chart. The “Google” theme initially dominated (perhaps mainly due to SEO optimization), but lost weight every year. Javascript has been a popular topic and continues gradually, but machine learning has begun to rapidly gain popularity only in recent years. Linux, however, remains equally relevant throughout the decade.

Of course, I wondered which topics attracted more reader activity. I calculated the median number of views, votes and comments in each topic. Here's what happened:
- The most viewed topics: arduino, web design, web development, digest, links, css, html, html5, nginx, algorithms.
- The most "likeable" themes: VKontakte, humor, jquery, opera, c, html, web development, html5, css, web design.
- The most discussed topics: opera, skype, freelance, VKontakte, ubuntu, work, nokia, nginx, arduino, firefox.
By the way, since I am comparing topics, you can make their rating by frequency (and compare the results with a similar article from 2013 ).
- For all the years of Habr's existence, google, android, javascript, microsoft, linux, php, apple, java, python, programming, startups, development, ios, startup, social networks have become the most popular tags (in descending order).
- In 2017, the most popular were javascript, python, java, android, development, linux, c ++, programming, php, c #, ios, machine learning, information security, microsoft, react
When comparing these ratings, one can pay attention, for example, to the victorious procession of Python and the extinction of php, or to the "sunset" of the startup theme and the rise of machine learning.
Not all tags on Habré have such an obvious thematic coloring. Here, for example, a dozen tags that met only once, but just seemed funny to me. So: "the idea of the progress mover", "boot from the image of a floppy disk", "state of Iowa", "drama", "superalesha", "steam engine", "what to do on Saturday", "I have a fox in a meat grinder", "a It turned out as always "," it was not possible to come up with funny tags. " To determine the subject of such articles, tags are not enough - you will have to carry out thematic modeling on the texts of articles.
A more detailed analysis of the content of the articles will be in the next post. First, I am going to build a model that predicts the number of article views, depending on its content. Secondly, I want to teach the neural network to generate texts in the same style as the authors of Habr. So subscribe :)
')
Source: https://habr.com/ru/post/346198/
All Articles