Results of the development of computer vision in one year
Part one. Classification / localization, object detection and object tracking
Computer vision is usually called the scientific discipline that gives cars the ability to see, or more colorfully, allowing machines to visually analyze their environment and stimuli in it. This process usually involves evaluating one or more images or videos. The British Association of Machine Vision (BMVA) defines computer vision as "automatic extraction, analysis and understanding of useful information from an image or its sequence . "
The term understanding is interestingly distinguished from the mechanical definition of vision — and at the same time it demonstrates the significance and complexity of the field of computer vision. A true understanding of our environment is not only achieved through a visual presentation. In fact, the visual signals pass through the optic nerve into the primary visual cortex and are interpreted by the brain in a highly stylized sense. The interpretation of this sensory information encompasses almost the entire totality of our natural embedded programs and subjective experience, that is, how evolution has programmed us to survive and what we learned about the world throughout life.
In this regard, vision refers only to the transmission of images for interpretation; and computing indicates that the images are more like thoughts or consciousness, relying on the many abilities of the brain. Therefore, many believe that computer vision, a true understanding of the visual environment and its context, paves the way for future variations of Strong Artificial Intelligence thanks to a perfect mastery of work in cross-domain areas.
')
But don’t grab hold of a weapon, because we haven’t practically reached the embryonic stage of development of this amazing area. This article should just shed some light on the most significant achievements of computer vision in 2016. And it is possible to try to inscribe some of these achievements in a sound mixture of expected short-term social interactions and, where applicable, hypothetical predictions of the completion of our life as we know it.
Although our works are always written in the most accessible way, the sections in this particular article may seem a bit unclear due to the subject matter. We everywhere offer definitions at a primitive level, but they only provide a superficial understanding of key concepts. Concentrating on the works of 2016, we often make gaps for the sake of brevity.
One of these obvious omissions relates to the functionality of convolutional neural networks (CNN), which are commonly used in computer vision. AlexNet's success in 2012, the architecture of CNN, which stunned competitors in the ImageNet competition, was a testament to a revolution that de facto took place in this area. Subsequently, numerous researchers began using CNN-based systems, and convolutional neural networks have become a traditional technology in computer vision.
More than four years have passed, and the CNN variants still make up the bulk of the new neural network architectures for computer vision tasks. Researchers remake them as designer cubes. This is real proof of the power of both open source scientific publications and in-depth training. However, the explanation of convolutional neural networks will easily stretch into several articles, so it is better to leave it for those who are more deeply versed in the subject and have a desire to explain complex things in a clear language.
For ordinary readers who wish to quickly understand the topic before continuing with this article, we recommend the first two sources listed below. If you want to dive even more into the subject, then for this we also cite other sources:
For a more complete understanding of neural networks and deep learning in general, we recommend:
In general, this article is scattered and spasmodic, reflecting the authors' admiration and the spirit of how it is supposed to be used, section by section. The information is divided into parts in accordance with our own heuristics and judgments, a necessary compromise due to the cross-domain influence of so many scientific papers.
We hope that readers will benefit from our generalization of information, and it will allow them to improve their knowledge, regardless of the previous baggage.
On behalf of all participants
The m tank
The task of classification with respect to images is usually to assign a label to a whole image, for example, “cat”. With this in mind, localization can mean determining where the object is in this image. Usually, it is indicated by a certain bounding box around the object. The current classification methods on ImageNet are already superior to groups of specially trained people in the accuracy of object classification.
Fig. 1 : Computer vision tasks
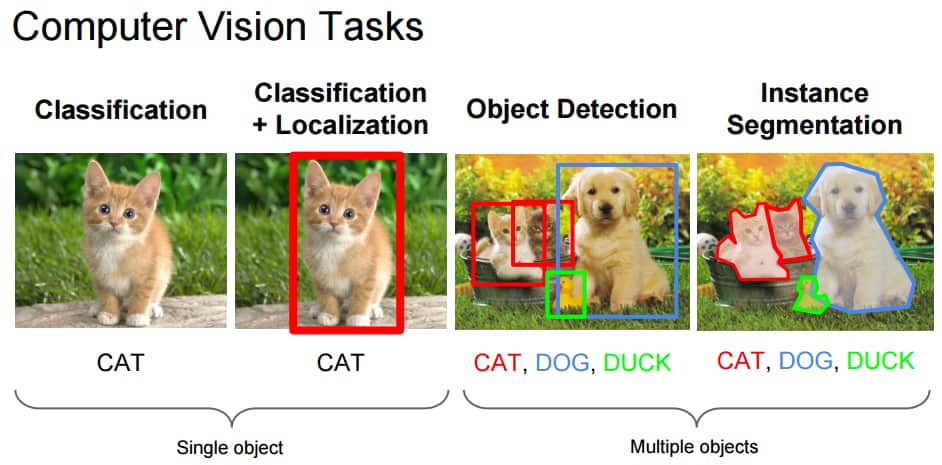
Source : Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, lecture 8 - slide 8, spatial localization and detection (01/02/2016), pdf
However, increasing the number of classes is likely to provide new metrics for measuring progress in the near future. In particular, Francois Chollet, the creator of Keras , has applied new techniques , including the popular Xception architecture, to Google’s internal data set with more than 350 million images with multiple tags containing 17,000 classes.
Fig. 2 : Classification / localization results from the ILSVRC competition (2010–2016)
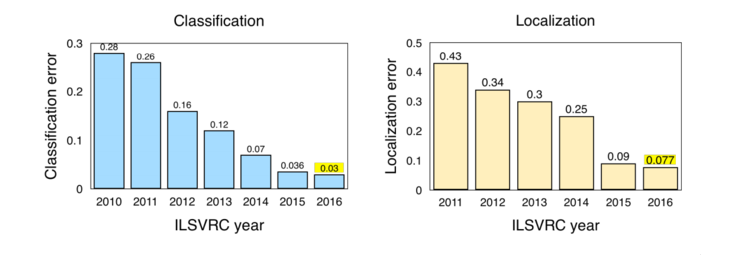
Note : ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The improvement in results after 2011–2012 is due to the advent of AlexNet. See a review of competition requirements regarding classification and localization.
Source : Jia Deng (2016). Localization of objects ILSVRC2016: introduction, results. Slide 2, pdf
Interesting excerpts from ImageNet LSVRC (2016):
As you might guess, the object detection process does exactly what it needs to do — it detects objects in images. The definition of object detection from ILSVRC 2016 includes the issuance of bounding boxes and labels for individual objects. This differs from the classification / localization task, since here classification and localization are applied to many objects, and not to one dominant object.
Fig. 3 : Object detection where face is the only class

Note : The picture is an example of face detection as the detection of objects of the same class. The authors call one of the constant problems in this area the detection of small objects. Using small faces as a test class, they explored the role of invariance in size, image resolution, and contextual reasoning.
Source : Hu, Ramanan (2016, p. 1)
One of the main trends in object detection in 2016 was the transition to faster and more effective detection systems. This can be seen in approaches such as YOLO, SSD and R-FCN as a step to joint calculations on the entire image as a whole. In this way, they differ from resource-intensive subnets associated with R / CNN Fast / Faster techniques. This technique is commonly called end-to-end training / learning.
In essence, the idea is to avoid using separate algorithms for each of the sub-problems in isolation from each other, since this usually increases the learning time and reduces the accuracy of the neural network. It is said that such an adaptation of neural networks to work from start to finish usually occurs after the operation of the initial subnets and, thus, is a retrospective optimization. However, the Fast / Faster R-CNN techniques remain highly efficient and are still widely used for object detection.
This excerpt is from a recent publication that was compiled by our research team in the field of computer vision. In the coming months, we will publish papers on various research topics in the field of Artificial Intelligence — about its economic, technological, and social applications — with the goal of providing educational resources for those who want to learn more about this amazing technology and its current state. Our project hopes to contribute to the growing mass of work that provides all researchers with information on the latest AI developments.
Introduction
Computer vision is usually called the scientific discipline that gives cars the ability to see, or more colorfully, allowing machines to visually analyze their environment and stimuli in it. This process usually involves evaluating one or more images or videos. The British Association of Machine Vision (BMVA) defines computer vision as "automatic extraction, analysis and understanding of useful information from an image or its sequence . "
The term understanding is interestingly distinguished from the mechanical definition of vision — and at the same time it demonstrates the significance and complexity of the field of computer vision. A true understanding of our environment is not only achieved through a visual presentation. In fact, the visual signals pass through the optic nerve into the primary visual cortex and are interpreted by the brain in a highly stylized sense. The interpretation of this sensory information encompasses almost the entire totality of our natural embedded programs and subjective experience, that is, how evolution has programmed us to survive and what we learned about the world throughout life.
In this regard, vision refers only to the transmission of images for interpretation; and computing indicates that the images are more like thoughts or consciousness, relying on the many abilities of the brain. Therefore, many believe that computer vision, a true understanding of the visual environment and its context, paves the way for future variations of Strong Artificial Intelligence thanks to a perfect mastery of work in cross-domain areas.
')
But don’t grab hold of a weapon, because we haven’t practically reached the embryonic stage of development of this amazing area. This article should just shed some light on the most significant achievements of computer vision in 2016. And it is possible to try to inscribe some of these achievements in a sound mixture of expected short-term social interactions and, where applicable, hypothetical predictions of the completion of our life as we know it.
Although our works are always written in the most accessible way, the sections in this particular article may seem a bit unclear due to the subject matter. We everywhere offer definitions at a primitive level, but they only provide a superficial understanding of key concepts. Concentrating on the works of 2016, we often make gaps for the sake of brevity.
One of these obvious omissions relates to the functionality of convolutional neural networks (CNN), which are commonly used in computer vision. AlexNet's success in 2012, the architecture of CNN, which stunned competitors in the ImageNet competition, was a testament to a revolution that de facto took place in this area. Subsequently, numerous researchers began using CNN-based systems, and convolutional neural networks have become a traditional technology in computer vision.
More than four years have passed, and the CNN variants still make up the bulk of the new neural network architectures for computer vision tasks. Researchers remake them as designer cubes. This is real proof of the power of both open source scientific publications and in-depth training. However, the explanation of convolutional neural networks will easily stretch into several articles, so it is better to leave it for those who are more deeply versed in the subject and have a desire to explain complex things in a clear language.
For ordinary readers who wish to quickly understand the topic before continuing with this article, we recommend the first two sources listed below. If you want to dive even more into the subject, then for this we also cite other sources:
- “ What a deep neural network thinks about your selfie ” by Andrey Karpaty is one of the best articles that helps people understand the use and functionality of convolutional neural networks.
- Quora: “What is a convolutional neural network?” Is full of excellent references and explanations. Especially suitable for those who have not had prior understanding in this area .
- CS231n: Convolutional Neural Networks for Visual Recognition from Stanford University is an excellent resource for more in-depth study of the topic.
- “ Deep Learning ” (Goodfellow, Bengio & Courville, 2016) gives a detailed explanation of the functions of convolutional neural networks and functionality in Chapter 9 . The authors have kindly published this tutorial for free in HTML format.
For a more complete understanding of neural networks and deep learning in general, we recommend:
- “ Neural networks and deep learning ” (Nielsen, 2017) is a free online tutorial that provides a truly intuitive understanding of all the complexities of neural networks and deep learning. Even reading the first part should, in many ways, highlight for beginners the subject of this article.
In general, this article is scattered and spasmodic, reflecting the authors' admiration and the spirit of how it is supposed to be used, section by section. The information is divided into parts in accordance with our own heuristics and judgments, a necessary compromise due to the cross-domain influence of so many scientific papers.
We hope that readers will benefit from our generalization of information, and it will allow them to improve their knowledge, regardless of the previous baggage.
On behalf of all participants
The m tank
Classification / localization
The task of classification with respect to images is usually to assign a label to a whole image, for example, “cat”. With this in mind, localization can mean determining where the object is in this image. Usually, it is indicated by a certain bounding box around the object. The current classification methods on ImageNet are already superior to groups of specially trained people in the accuracy of object classification.
Fig. 1 : Computer vision tasks
Source : Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, lecture 8 - slide 8, spatial localization and detection (01/02/2016), pdf
However, increasing the number of classes is likely to provide new metrics for measuring progress in the near future. In particular, Francois Chollet, the creator of Keras , has applied new techniques , including the popular Xception architecture, to Google’s internal data set with more than 350 million images with multiple tags containing 17,000 classes.
Fig. 2 : Classification / localization results from the ILSVRC competition (2010–2016)
Note : ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The improvement in results after 2011–2012 is due to the advent of AlexNet. See a review of competition requirements regarding classification and localization.
Source : Jia Deng (2016). Localization of objects ILSVRC2016: introduction, results. Slide 2, pdf
Interesting excerpts from ImageNet LSVRC (2016):
- Scene classification refers to the task of assigning labels to an image with a specific class of a scene, such as a greenhouse, stadium, cathedral, etc. As part of ImageNet, last year a competition was held to classify scenes in a sample from the Places2 data set : 8 million images for training with 365 categories of scenes.
Won Hikvision with a score of 9% of the top 5 errors. The system is constructed from a set of deep neural networks in the style of Inception and non-such-deep residual networks. - Trimps-Soushen won the ImageNet classification problem with a classification error of 2.99% top 5 and a localization error of 7.71%. The developers made a system of several models (by averaging the results of the Inception, Inception-Resnet, ResNet and Wide Residual Networks models), and Faster R-CNN won the localization by tags. The data set was distributed between 1000 image classes with 1.2 million images for training. The data set for testing contained another 100 thousand images that neural networks had not seen before.
- Facebook's ResNeXt neural network finished in second place with a classification error of 3.03% of the top 5. It used a new architecture that extends the original ResNet architecture.
Object detection
As you might guess, the object detection process does exactly what it needs to do — it detects objects in images. The definition of object detection from ILSVRC 2016 includes the issuance of bounding boxes and labels for individual objects. This differs from the classification / localization task, since here classification and localization are applied to many objects, and not to one dominant object.
Fig. 3 : Object detection where face is the only class
Note : The picture is an example of face detection as the detection of objects of the same class. The authors call one of the constant problems in this area the detection of small objects. Using small faces as a test class, they explored the role of invariance in size, image resolution, and contextual reasoning.
Source : Hu, Ramanan (2016, p. 1)
One of the main trends in object detection in 2016 was the transition to faster and more effective detection systems. This can be seen in approaches such as YOLO, SSD and R-FCN as a step to joint calculations on the entire image as a whole. In this way, they differ from resource-intensive subnets associated with R / CNN Fast / Faster techniques. This technique is commonly called end-to-end training / learning.
In essence, the idea is to avoid using separate algorithms for each of the sub-problems in isolation from each other, since this usually increases the learning time and reduces the accuracy of the neural network. It is said that such an adaptation of neural networks to work from start to finish usually occurs after the operation of the initial subnets and, thus, is a retrospective optimization. However, the Fast / Faster R-CNN techniques remain highly efficient and are still widely used for object detection.
- SSD: Single Shot MultiBox Detector uses a single neural network that performs all the necessary calculations and eliminates the need for resource-intensive methods of the previous generation. It demonstrates "75.1% mAP, surpassing the comparable state-of-the-art Faster R-CNN model."
- One of the most impressive developments of 2016 is the system aptly named YOLO9000: Better, Faster, Stronger , which uses the YOLOv2 and YOLO9000 detection systems (YOLO means You Only Look Once). YOLOv2 is a greatly improved YOLO model from mid-2015 , and it is able to show the best results in videos with very high frame rates (up to 90 FPS in low-resolution images using the regular GTX Titan X). In addition to increasing the speed, the system surpasses the Faster RCNN with ResNet and SSD on certain data sets to identify objects.
YOLO9000 implements a combined learning method for detecting and classifying objects, extending its ability to predict beyond the limits of available markup detection data. In other words, it is able to detect objects that have never been encountered in the marked data. The YOLO9000 model provides the detection of objects in real time among more than 9000 categories, which eliminates the difference in the size of data sets for classification and detection. Additional details, pre-trained models and video demonstrations are available here .
Object Detection YOLOv2 works on frames of the film with James Bond - The Feature Pyramid Networks for Object Detection system was developed by the FAIR (Facebook Artificial Intelligence Research) research unit. It uses the “innate multiscale pyramidal hierarchy of deep convolutional neural networks to construct features pyramids with minimal additional costs” . This means maintaining powerful representations without losing speed and additional memory costs. The developers achieved record numbers on the COCO (Common Objects in Context) dataset. In combination with the Faster R-CNN base system, it surpasses the results of the 2016 winners.
- R-FCN: Object Detection via Region-based Fully Convolutional Networks . Another method in which developers abandoned the use of resource-intensive subnets for individual regions of the image hundreds of times in each picture. Here the detector by region is completely convolutional and performs joint calculations on the entire image as a whole. “When testing, the speed of work was 170 ms per image, which is 2.5–20 times faster than that of Faster R-CNN,” the authors write.
Fig. 4 : The trade-off between accuracy and size of objects when objects are detected on different architectures
Note : The mAP (mean Average Precision) indicator is plotted on the vertical axis, and the variety of meta-architectures for each feature extraction unit (VGG, MobileNet ... Inception ResNet V2) is shown on the horizontal axis. In addition, small, medium, and large mAP show average accuracy for small, medium, and large objects, respectively. Essentially, the accuracy depends on the size of the object, the meta-architecture and the feature extraction block. At the same time, "the image size is fixed at 300 pixels." Although the Faster R-CNN model has performed relatively well in this example, it is important to note that this meta-architecture is much slower than more modern approaches, such as R-FCN.
Source : Huang et al. (2016, p. 9)
The aforementioned scientific article provides a detailed comparison of the performance of the R-FCN, SSD and Faster R-CNN. Due to the difficulty of comparing machine learning techniques, we would like to point out the merits of creating a standardized approach described by the authors. They view these architectures as “meta-architectures,” because they can be combined with different feature extraction blocks, such as ResNet or Inception.
The authors study the trade-offs between accuracy and speed in various meta-architectures, feature extraction blocks and resolutions. For example, the choice of a feature extraction block greatly changes the results of work on various meta-architectures.
In scientific articles describing SqueezeDet and PVANet , the necessity of a compromise between the tendency to increase application speed with a decrease in consumed computing resources is emphasized again and the accuracy that is required for real-time commercial applications, especially in unmanned vehicle applications. Although the Chinese company DeepGlint showed a good example of detecting objects in real time in the stream from a video surveillance camera.
Object Detection, Object Tracking and Face Recognition in DeepGlint
ILSVRC and COCO Detection Challenge Results
COCO (Common Objects in Context) is another popular image data set. However, it is relatively smaller in size and more closely supervised than alternatives like ImageNet. It aims to recognize objects with a broader context of understanding the scene. The organizers hold an annual competition for the detection of objects, segmentation and key points. Here are the results from the ILSVRC and COCO competitions for object detection:- ImageNet LSVRC, Object Detection (DET) : CUImage system showed 66% meanAP. Won in 109 out of 200 object categories.
- ImageNet LSVRC, object detection on video (VID) : NUIST 80.8% meanAP
- ImageNet LSVRC, object detection on video with tracking : CUvideo 55.8% meanAP
- COCO 2016, object detection (bounding box) : G-RMI (Google) 41.5% AP (absolute increase of 4.2 pp compared to the winner of 2015 - MSRAVC)
In a review of the results shown by object detection systems of 2016, ImageNet writes that MSRAVC 2015 set a very high level of performance (the first appearance of ResNet networks at this competition). System performance has improved in all grades. In both competitions, localization has greatly improved. A significant improvement has been achieved on small objects.
Fig. 5 : Results of detection systems on images in the ILSVRC competition (2013–2016)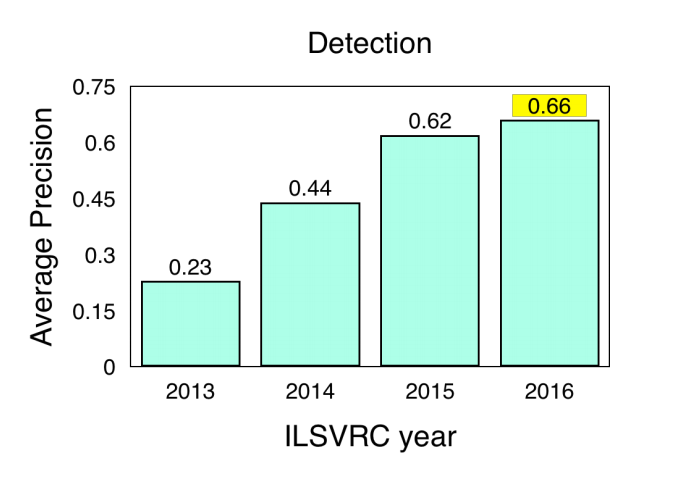
Note : Results of detection systems on images in the ILSVRC competition (2013–2016). Source : ImageNet 2016, online presentation, slide 2, pdfObject tracking
It refers to the process of tracking a specific object of interest or several objects in a given scene. Traditionally, this process is used in video applications and systems of interaction with the real world, where observations are made after the detection of the original object. For example, the process is crucial for unmanned vehicle systems.- “ Fully convolutional Siamese tracking networks ” combines a basic tracking algorithm with a Siamese network trained from start to finish that reaches record levels in its field and runs frame by frame at a rate that is greater than what is needed for real-time applications. This paper attempts to overcome the lack of functional richness available to tracking models from traditional online learning methods.
- “ Teaching deep regression networks to track objects at 100 FPS ” is another article whose authors are trying to overcome existing problems with the help of online teaching methods. The authors have developed a tracker that uses a network with a mechanism for predicting events (feed-forward network) to assimilate common relationships in connection with the movement of an object, its appearance and orientation. This allows you to effectively track new objects without online learning . Shows a record result in a standard benchmark tracking, while at the same time allowing “to track common objects at 100 FPS”.
GOTURN (Generic Object Tracking Using Regression Networks) video - The work “ Deep motion signs for visual tracking ” combines hand-written signs, deep RGB / appearance signs (from CNN), as well as deep signs of movement (trained on an optical image stream) to achieve record numbers. Although deep signs of movement are commonplace in action recognition and video classification systems, the authors state that they are first used for visual tracking. The article received the award as the best article at the ICPR 2016 conference, in the section “Computer vision and vision of robots”.
“This article is a study of the influence of deep signs of movement in a tracking framework through detection. Further, we show that additional information contains handwritten signs, deep RGB signs, and deep signs of movement. As far as we know, we are the first to propose to combine information on appearance with deep signs of movement for visual tracking. Comprehensive experiments clearly assume that our mixed approach with deep signs of movement is superior to standard methods that rely only on appearance information. ” - The article “ Virtual Worlds as an Intermediate for Analyzing the Tracking of Multiple Objects ” is devoted to the problem of the absence of inherent real world variability in existing benchmarks and data sets for video tracking. The article proposes a new method of cloning the real world by generating from scratch saturated, virtual, synthetic, photorealistic environments with full label coverage. This approach solves some of the problems of sterility that are present in existing data sets. The generated images are automatically tagged with exact labels, which allows them to be used for a variety of applications, in addition to detecting and tracking objects.
- " Global optimal tracking of objects with fully convolutional networks . " Object diversity and interference are discussed here as the two root causes of constraints in object tracking systems. "The proposed method solves the problem of the diversity of the appearance of objects with the help of a fully convolutional network, and also works with the problem of interference by dynamic programming . "
Source: https://habr.com/ru/post/346140/
All Articles