Akumuli - time series database
Hello! In this article I want to talk about the project Akumuli, a specialized database for collecting and storing time series. I have been working on the project for more than four years and have achieved high stability, reliability, and may have invented something new in this area.
A time series is an ordered sequence of measurements in time; if to speak as simply as possible, this is something that can be drawn on the graph. Time series naturally occur in many applications, from finance to DNA analysis. The most widely used databases of time series are found in infrastructure monitoring. In the same place the most serious loadings are often observed.
“I don't need TSDB, I already have X”
X can be anything from SQL databases to flat files. In fact, all this can really be used to store time series, with one reservation - you have little data. If you make 10,000 inserts into your SQL database, everything will be fine for a while, then the table will grow in size so that the execution time of insert operations will increase.
You will begin to group them before inserting, this will help, but now you have a new problem - you have to accumulate data somewhere, which means you can lose everything that did not have time to register in the database. The next step is to try to use some clever scheme, for example, to store not one dimension in one line (id + timestamp + value) but several (id + timestamp + value + value in 10 seconds + value in 20sec + ...). This will increase the recording capacity, but will create new problems. The place quickly ends because compression is not very good, you need to store time series with different steps, you need to store time series with variable steps, you need to consider aggregation (maximum value for the interval), you need to make a time series with a step of 10 seconds with a step of 1 hour .
All these problems are surmountable; you just need to write your TSDB on top of the SQL server or flat files or Cassandra or even Pandas . In fact, many people have already gone this way, you can guess by the number of already existing TSDBs working on top of some other DB. Akumui differs from them in that it uses specialized storage based on original algorithms.
Design
The problem that TSDB solves can be reduced to the fact that the data is written in one order and read in another. Imagine that we have a million time series, once a second in each of them you need to write one value with the current timestamp. To record them quickly, you need to write them in the order in which they come. Unfortunately, if we want to read one hour of data from one time series, we will have to read all 3600 * 1000000 points, filter out most of the data and leave only 3600. This is called read amplification and this is bad.
Unfortunately, a lot of TSDBs do this. The only difference is that the data a) is compressed b) is divided into small blocks, each of which has a column format (the so-called PAX) which allows you not to parse all the contents and go directly to the necessary data.
I decided to follow a different path (however, I first tried PAX) and implemented a columned storage in each column of which a separate time series is stored. This allows you to read only the data needed by the request. Modern SSD and NVMe do not need the data accessed by the database to lie strictly sequentially, but their bandwidth is limited, so it is very important for the database to read only what is really needed, and not save disk seeks. Previously, it was the other way around, we changed the bandwidth to disk seeks, many data structures are built around this compromise (hi LSM-tree). Akumuli does the opposite.
Compression
This is the most important aspect for TSDB, since Compression has a profound effect on trade-offs, the balance of which underlies the design of any database. For Akumuli, I developed, it seems to me, a pretty good algorithm. It compresses time stamps and values using essentially two different algorithms. I do not want to go into details too much, for this there is a whitepaper , but I will try to give a good introductory.
Points (time + value) are combined into groups of 16 and compressed together. This allows you to write the algorithm in the form of simple cycles processing fixed-length arrays, which the compiler can optimize and vectorize well. In the hot path there are no branches, which the branch predictor cannot predict in most cases.
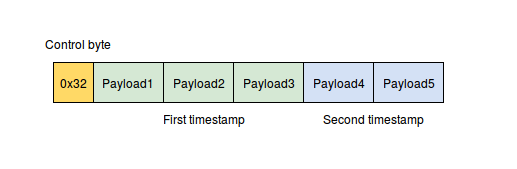
The time stamps are compressed as follows: first, the delta-delta encoding is applied (first, deltas are counted, then the minimum element is subtracted from each delta), then this is all compressed using VByte encoding. VByte encoding is similar to that used in protocol buffers with the only difference that bitwise operations are not required here, it works faster. This is achieved due to the fact that time stamps are combined in pairs and the metadata of each pair (control byte) is stored in one byte.
To compress values, a predictive algorithm is used that attempts to predict the next value using a differential finite context method (DFCM) predictor.
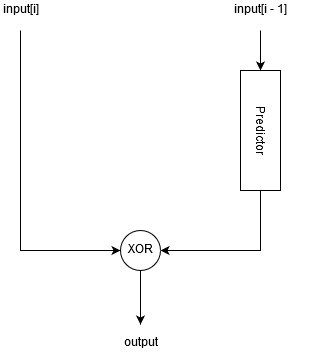
Further, the XOR-it algorithm predicted and actual values among themselves, resulting in a string of bits with a large number of zeros at the end or at the beginning. This string of bits is encoded as follows:
- We count the number of zeros at the beginning and end of the line, if there are more zeros at the beginning of the line, set a special flag.
- We count how many bytes (N) are needed in order to write a given bit string (taking into account the flag).
- Shift the bit string to the left by 64 - N * 8 bits if the flag is set.
- Write the first N bytes of the bit string to the output buffer.
As a result, we have N bytes of data, but in addition to this we must save the metadata - the value of N and the flag, these are four bits. To save space, I combine the values in pairs and first write the bytes with the metadata for both values (control byte), and then the values themselves.
In addition, another trick is used. If we are dealing with “convenient” data, this algorithm can predict the next value with 100% accuracy. In monitoring this happens quite often, sometimes there the values do not change for a long time, or they grow at a constant rate. In this case, after the XOR, we will always get zero values. In order not to encode each of them with a full half of byte, the algorithm has a special case - if all 16 values can be predicted, it writes a special control byte and nothing else. It turns out that in this case we spend less than a bit on the value. A similar shortcut is also implemented for time stamps, for the case if measurements have a fixed step.
This algorithm has no branches and works on byte boundary. Compression speed, according to my measurements, is about 1 Gb / s.
Storage engine
Each time series is represented on disk as a separate data structure. I call it Numeric B + tree, because it is intended for storing numerical data, but in fact, it is an LSM tree whose segments are B + trees. Usually (but not necessarily) segments (SSTables) are implemented as sorted arrays.

The role of the MemTable in this LSM tree is performed by a single B + leaf of the tree. When it is filled with data, it is sent to the second level, where it simply joins another B + tree, consisting of two levels. When this tree is filled, it is sent to the third level, joining the B + tree consisting of three levels and so on. I have a whitepaper detailing the process.
This data structure allows you to:
- Merge the segments without reading them from the disk entirely (as a regular LSM-tree does). Akumuli does not read data from disk to write. Due to this, readers can not slow down the recording process by spending the disk bandwidth to read.
- Have a lot of independent trees in one file. The nodes of different trees are simply interspersed on the disk with each other. Because of this, writing to the disk is still going on consistently. Reading one series selects data from the disk in random order, but for modern SSDs this is not a problem.
- Optimization for SSD and NVMe drives. All read and write operations are aligned at the block boundary (which reduces write amplification). Both writing and reading can be performed in parallel (without which it is difficult to saturate a modern SSD). The database is ready for the appearance of byte addressable devices (like Intel Optane SSDs), since able to display data in memory and read / write with even greater granularity.
- Perform disaster recovery without using WAL. This is a complex problem, the details of the solution of which are disclosed in the article. In short, Akumuli does not use WAL and additional links between tree nodes are used for disaster recovery.
- Multiversion concurrency control allows you to eradicate synchronization errors as a class. Both writing and reading can be performed in parallel, readers / writers are independent of each other, etc. and etc.
There are disadvantages to this approach:
- Data must be recorded in order of increasing timestamps.
- If you fall, you can lose the data that was recorded last, say, the last 5 minutes of monitoring data.
Sooner or later, these problems will be solved, but until they are solved they should be taken into account.
Query Processing
I wanted to get something similar in features to Pandas data frames. First of all, be able to read the data in any order and group them as you please - in order of increasing time stamps or vice versa, first the data of one series, then the data of the next (the query can return many time series), or first the data of all the series with one label time, then the data of all series in the same order with the following timestamp and so on. My experience shows that it is necessary to be able to, because the size of the requested data may exceed the amount of RAM from the client and he simply cannot reorder them locally, but if the data comes in the correct order, he will be able to process them in parts.
In addition, I wanted to be able to merge several rows into one, simply by combining points, or join several time series by timestamps, aggregate the data of the series (min, max, avg, etc), aggregate in increments (resample), calculate all sorts of functions (rate, abs, etc).
The request handler, in its current form, has a hierarchical structure. Operators work at the lower level, the operator always works with the data of one column corresponding to one time series and stored in one tree. Operators are something like iterators. They are implemented at the storage level and are able to use its features. Unlike iterators, database operators are not only able to read data, they can aggregate and filter, and these operations can be performed on compressed data (not always).
Operators can skip (search pruning) parts of the tree without even reading them from disk. For example, if a query reads data without a downsample conversion, then the scan statement will be used, which simply returns the data as is, but if the query performs the group aggregate with any step, another operator will be used who can do downsampling without reading everything from the disk.
The next stage is the materialization of the query results (Akumuli performs only the early materialization). From the data that operators return, tuples are formed, the basic operations of the plan (for example, join) are already performed on the materialized data. All sorts of functions are also performed here (for example, rate).
All processing is done in a lazy way. First, the request handler forms a pipeline of operators, and then data is run through it. The speed of reading and processing data depends on how fast the client reads them, i.e. If you have read part of the query results and stopped, the query will stop executing on the server. In practice, this means that the client application can process data in streaming mode, and this data does not have to be placed in the client’s RAM or even the server.
Tests
The most interesting thing about this project is testing. Testing takes place automatically on the CI server (I use Travis-CI). The project uses the following types of tests:
- The first stage is unit testing. Unit tests work in about a minute or two, they don’t touch the disk, so they work pretty quickly. They rarely find regressions, but when they do, they give the most information about where the problem lies.
- Integration tests. This application uses libakumuli - a library that implements the storage system. It contains many simple tests with a small amount of data. The task of the test is to make sure that the contracts are not broken, i.e. in that the behavior of the library API functions has not changed.
- Functional tests. These tests (there are more than 20 of them) are written in python and they work at the highest level. Each test is a separate script that creates a new database, starts the database server and does something. For example, I have a test that simply writes data and checks that everything has been recorded, there is a test that checks all possible query options, a test that kills the database server through kill -9, to check crash recovery, etc. These are the most important tests that find the most problems. Usually I add regressions here — tests that check problems that have already been fixed.
- Roundtrip test. This is a seemingly simple test written entirely in bash. It downloads several hundred MB of test data from S2 in a ready-to-write form, creates a database, starts the database server, writes test data to it, then it forms a join request that must output all the recorded data in exactly the same format as the test data. If everything went well, both files are identical and the test is successful. This is done twice for the two input data formats (RESP and OpenTSDB).
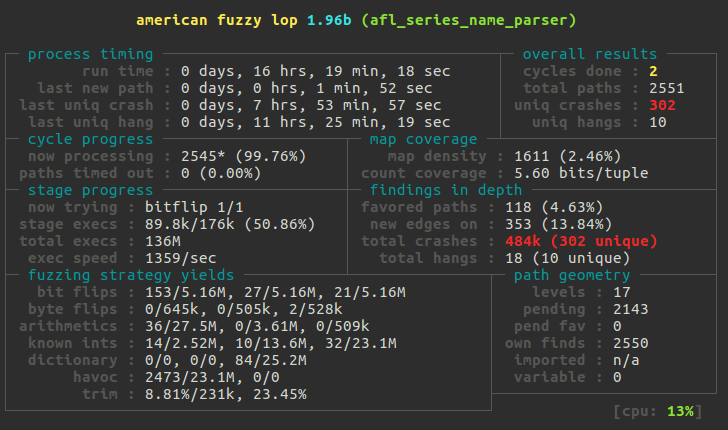
- Fuzz tests. These tests are run manually. They check the compression algorithm and the code that parses the input data, for example, the code that parses timestamps and the names of time series. When a pull request affects one of these code points, I run the AFL with the appropriate test for several days on a specially created EC2 instance in AWS. Eye opening experience!
- Randomized tests. The most strange kind of tests. In some cases, I add a special code that does something with a very low probability. For example, it generates an error when trying to read data from a disk in order not to wait until it actually happens. From the recent - I worked on changing data in the past using shadow pages and in order to check that writing to the past will not break anything, I added code that does the same thing that the writing procedure to the past does without changing anything . This code was called in the process of working with a low probability and applied to a random point in the time series. Having collected the database with these changes, I spent many hours spinning integration tests on the AWS instance until something went down there, and then corrected the error and started all over again, until the errors stopped appearing. Naturally, this is not performed on the CI server, moreover, I always delete such code so that it does not accidentally get into the master.
Benchmarks
Typically, Akumuli can perform about 0.5 million write operations per second per core. Those. on a dual-core machine will be about 1M, on 4x - 2M, and so on. In this article, I described the testing process on a 32-core machine, there were about 16 million write operations per second. To create such a load it took four machines (m3.xlarge instance). The test data was prepared in advance (as close as possible to what the real collector produces, in the RESP format, 16GB in compressed form), since in order to generate them on the fly, more computational resources would be required. I ran the test through parallel-ssh simultaneously on all machines and in less than three minutes everything was recorded. During the test, the DB wrote to the disk at a speed of 64MB / s.
I also tested the read speed here . The data volumes there are quite small and everything fits into memory, but before testing, I restarted the database server and cleared the disk cache. I’m sure that Akumuli will behave very well on large amounts of data and with an active record in the database.
Future plans
At the moment I am working on solving the problem of writing to the past. This is also necessary in order to enable replication of data and HA. I already have one implementation based on shadow pages, now I'm working on an alternative using WAL. I think one of these two options will end up in the master, but this will not happen soon, because requires serious testing and iron, and from iron I only have an ultrabook, so hello AWS ES2.
Another direction of development is all sorts of integration and tools. I implemented support for the OpenTSDB protocol and now Akumuli can be used along with a large number of collectors, like collectd. I also have a plugin for Grafana, which is waiting for its turn to be included in their plugin store. I also glance at Redash, although I’m not sure yet that this may be necessary for someone.
Akumuli is an open source project published under the Apache 2.0 license. You can find the source code here . Here you can take a docker container with the latest stable build , and here - a plug-in for graphs. The project can be helped by sending a pull-request or bug report.
')
Source: https://habr.com/ru/post/345974/
All Articles