Welcome to the era of deep neuroevolution

On behalf of the Uber AI Labs team, which also includes Joel Lehman, Jay Chen, Edoardo Conti, Vashisht Madhavan, Felipe Petroski Such and Xingwen Zhang.
In the field of deep neural networks (DNN) with a large number of layers and millions of connections, for training, as a rule, stochastic gradient descent (SGD) is used. Many believe that the ability of SGD to efficiently calculate gradients is an exceptional feature. However, we publish a set of five articles in support of neuroevolution , when neural networks are optimized using evolutionary algorithms. This method is also effective in learning deep neural networks for reinforced learning (RL) tasks. Uber has many areas where machine learning can improve its performance, and developing a wide range of powerful learning approaches (including neuroevolution) will help develop safer and more reliable transport solutions.
From translator
It seemed to me more organic to keep abbreviations in the English version, as more recognizable to specialists in this subject area. In addition, for some I did not manage to quickly find well-established Russian-language equivalents. Therefore, I give a decryption of the abbreviations used:
')
')
- A3C (Asynchronous Advantage Actor-Critic) - well-established Russian-language name I do not know.
- DNN (Deep Neural Network) is a deep neural network.
- DQN (Q-learning) - Q-learning.
- ES (Evolution Strategies) - evolutionary strategies.
- GA (Genetic Algorithm) is a genetic algorithm.
- MNIST (Modified National Institute for Standards and Technology database) is a voluminous database of handwritten number samples.
- NS (Novelty Search algorithms) - novelty search algorithms.
- QD (Quality Diversity algorithms) - qualitative diversity algorithms.
- RL (Reinforcement Learning) - reinforcement learning.
- SGD (Stochastic Gradient Descent) - stochastic gradient descent.
- SM-G (Safe Mutations through Gradients) - safe mutations through gradients.
- TRPO (Trust Region Policy Optimization) - well-established Russian-language name I do not know.
Genetic algorithms as a competitive alternative for training deep neural networks
Using the new technique that we have invented for the efficient development of DNN, we were surprised to find that an extremely simple genetic algorithm (GA) can train deep convolutional networks with more than 4 million parameters for playing Atari from pixels, and in many games surpasses modern algorithms deep reinforcement learning (RL) (for example, DQN and A3C) or evolutionary strategies (ES), and is also faster due to better parallelization. This result is unexpected, both because it was not expected that a GA, not based on a gradient, would scale well in such large parameter spaces, and also because it was not considered possible to achieve or exceed advanced RL algorithms using GA. Further, we show that modern GA enhancements that improve GA capabilities, such as novelty search , also work on DNN scales and can contribute to finding solutions to deceptive tasks (with complex local extremes), ahead of reward maximization algorithms, such as Q-learning (DQN ), policy gradients (A3C), ES and GA.
This GA strategy scores 10,500 points in Frostbite. DQN, AC3 and ES gain less than 1000 on this game.
GA plays well in the Asteroids. It is on average superior to DQN and ES, but not A3C.
Safe mutations using gradient calculations
In a separate article, we show how gradients can be combined with neuroevolution, improving the ability to learn recurrent and very deep neural networks, making possible the evolution of DNN with more than a hundred layers - a level far exceeding what was previously possible due to neuroevolution. We do this by computing the gradient of the network outputs relative to the weights (that is, not the error gradient, as in traditional deep learning), allowing the calibration of random mutations to more accurately handle the most sensitive parameters, thereby solving the main problem of random mutation in large networks.
Both animations show a set of mutations of the same network, which should bypass the maze (start in the lower left corner and exit in the upper left). Normal mutations generally lose their ability to reach the finish line, while safe mutations generally retain it, while maintaining diversity, illustrating the significant advantage of safe mutation.
How ES relates to SGD
Our articles complement the previously formed understanding , which was first noted by a team from OpenAI (Russian translation: habrahabr.ru/post/330342 ), that various evolutionary neuroevolution strategies can compete well in optimizing deep neural networks on deep RL problems. However, today the broader implications of this result remain the subject of discussion. Creating the prerequisites for further innovations in ES, we examine their relationship with SGD in detail in a comprehensive study that examines how close the gradient approximation using ES actually achieves the optimal gradient for each minibatch calculated by MNIST SGD, and how well it can be done . We show that ES can achieve 99% accuracy in MNIST if sufficient computational power is provided to improve the gradient approximation, indicating why ES will be an increasingly serious contender in deep RL where no method has privileged access. to the ideal gradient information, as the degree of parallelization of computations increases.
ES is not just traditional finite differences.
A companion study empirically confirms the understanding that ES (with a sufficiently large value of the perturbation parameter) acts differently than SGD because it optimizes the expected reward from the set of strategies described by the probability distribution (cloud in the search space), while SGD optimizes the reward for one strategy (point in the search space). This change forces ES to visit different areas of the search space, fortunately or unfortunately (both cases are illustrated). An additional consequence of the optimization of the perturbation parameter population is that ES acquires robustness that is not achievable through SGD. Noting that ES optimizes a population of parameters, it also highlights the intriguing connection between ES and Bayesian methods .
The random perturbations of the weights of the pedometer, studied by the TRPO, lead to significantly less steady gaits than the random perturbations of the pedometer of equivalent quality found with ES. The original trained walkers are located in the center of each nine-frame combined image.
Traditional finite differences (gradient descent) cannot cross the narrow gap where the fitness function has a low value, and the ES easily crosses it, reaching an area with a high value on the other side.
ES stalls in a narrow “ravine” with a high value of fitness function, while traditional finite differences (gradient descent) go the same way without any problems, illustrating, along with the previous video, the differences and trade-offs between these two different approaches.
Improve ES Search Capability
The exciting consequence of deep neuroevolution is that the toolkit, previously developed for neuroevolution, is now becoming a candidate for improving the learning of deep neural networks. We are exploring this possibility by introducing new algorithms that combine the optimization power and scalability of ES with methods unique to neuroevolution, which facilitate the search for RL domains through agent populations, stimulate each other to act in different ways. Such population-based research differs from the single-agent tradition in RL, including recent work on research in deep RL. Our experiments show that adding this new research style improves ES performance in many areas that require testing to avoid deceptive local optima, including some Atari games and the humanoid movement control task in the Mujoco simulator.
ES
ES with sounding
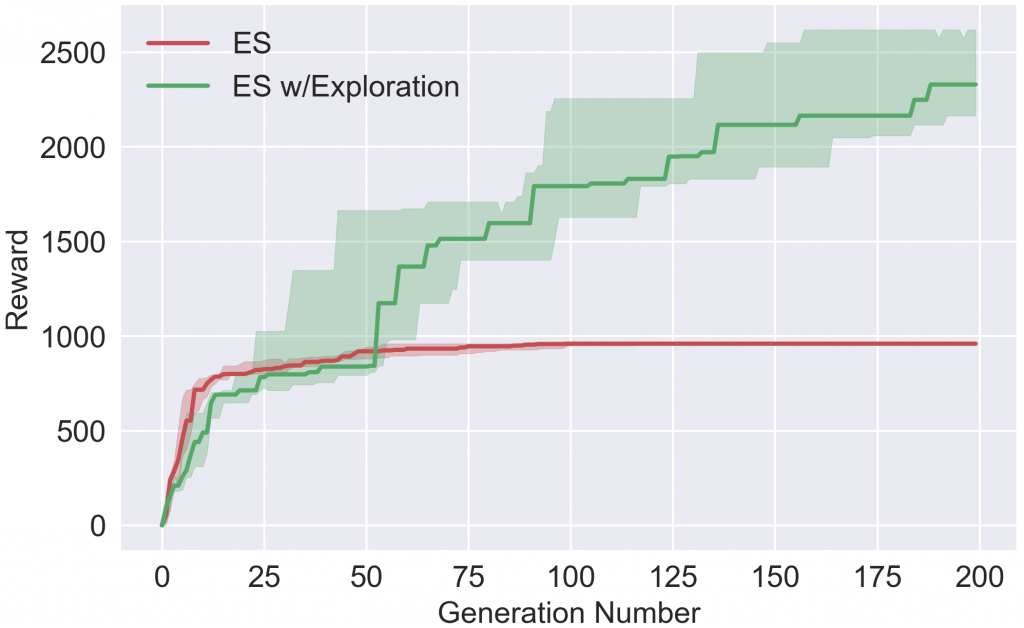
Award for the duration of the training
With our hyperparameters, the ES quickly converges to a local optimum, which does not include a rise to replenish oxygen, because it temporarily cancels the reward. However, when probing, the agent learns to climb for oxygen and, thus, receives a much higher reward in the future. Please note that Salimans et al. 2017 does not report that their ES variant encounters these specific local optima, but note that ES without probing can be blocked indefinitely in some local optima (and that probing helps unlock it) in the same way as shown in our article.
ES
ES with sounding
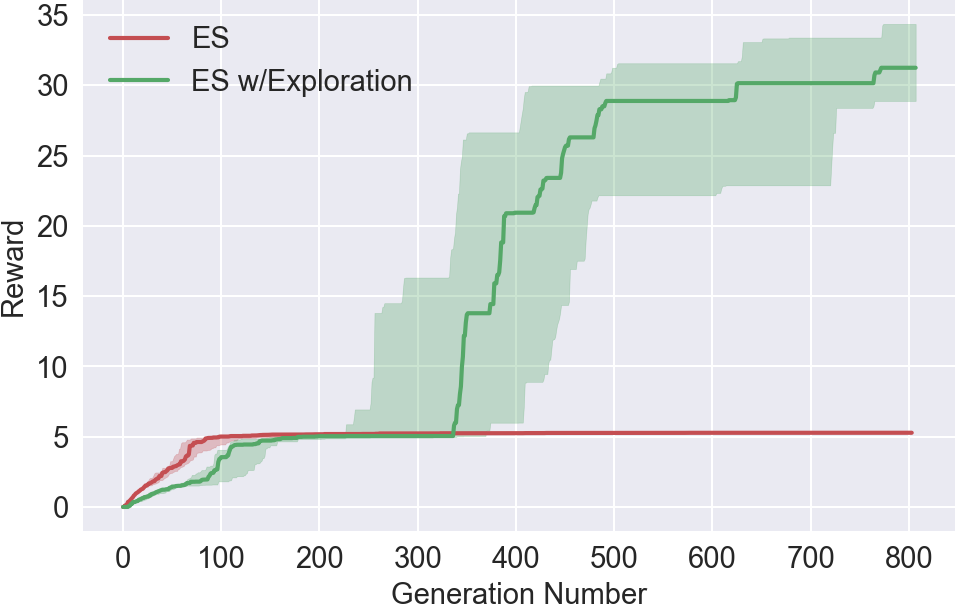
Award for the duration of the training
The task of the agent is to run as far as possible. ES is never trained to avoid the trap. However, having acquired the possibility of probing, one of the agents is trained to bypass the trap.
Conclusion
For researchers of neuroevolution interested in moving to deep networks, there are several important thoughts: first of all, such experiments require more computational power than in the past; for the experiments described in these new articles, we often used hundreds or even thousands of processors at a time. However, such computational voracity should not be seen as a hindrance; after all, the simplicity of scaling evolution in massive parallel computing centers means that neuroevolution is perhaps best suited for use in the world that comes to us.
The new results are so different from what was previously observed in low dimension neuroevolution that they effectively refute the years of assumptions, in particular, on the consequences of a search in spaces with high dimension. As it was discovered in deep learning , above a certain threshold of complexity, it seems that the search actually becomes simpler in high dimensions in the sense that it is less susceptible to local optima. Although the direction of deep learning is familiar with this way of thinking, its consequences are only beginning to be absorbed in neuroevolution.
The reappearance of neuroevolution is another example of the fact that old algorithms in combination with modern computational volumes can work surprisingly well. The viability of neuroevolution is interesting because many methods developed in the neuroevolution community immediately become available on DNN-scales, each of which offers different tools for solving complex problems. Moreover, as our works show, neuroevolution is not looking the way SGD does, therefore, offers an interesting alternative approach to machine learning tools. We ask ourselves whether deep neuroevolution will experience a renaissance just like deep learning. If so, 2017 may mark the beginning of an era, and we will be happy to see what will develop in the coming years!
Below are five articles that we have published to date, along with an abstract of their key points:
- Deep Neuroevolution: A genetic algorithm is a competitive alternative for learning deep neural networks in reinforcement learning
- Develops DNN using a simple and traditional, population-based genetic algorithm that works well with complex RL problems. Atari, GA works as well as evolutionary reinforcement learning strategies and algorithms based on Q-learning (DQN) and gradient strategies.
- Deep GA successfully produces a network with more than 4 million free parameters, the largest neural network that was previously obtained using traditional evolutionary algorithms.
- It is intriguing that in some cases, following a gradient is not the best choice for optimizing performance.
- DNN combining novelty search is a probe algorithm designed for problems with deceptive and sparse reinforcement functions to solve complex problems in large spaces where reinforcement maximization strategies (GA and ES) fail.
- Shows that Deep GA will parallel better and run faster than ES, A3C and DQN, and also allow the use of modern compact encoding techniques that represent DNN with millions of parameters in thousands of bytes.
- Includes random Atari search results. Surprisingly, in some games the random search steadily outpaces DQN, A3C and ES, although it never exceeds GA.
Amazingly, however, the DNN, found using random searching, plays well in Frostbite, surpassing DQN, A3C and ES, but not GA. - Safe mutations for deep and recurrent neural networks through output gradients
- Safe mutations through gradients (SM-G), significantly improve the effectiveness of mutations in large, deep and recurrent networks by measuring the sensitivity of the network to changes in certain weights of connections.
- Calculates output gradients relative to weights instead of error or loss gradients, as in the usual deep learning, allowing random but safe probing steps.
- Both types of safe mutations do not require additional attempts or rollbacks in the definition area.
- Result: deep networks (over 100 layers) and large recurrent networks can currently be generated efficiently only with the help of SM-G variants.
- About the relationship between OpenAI evolutionary strategy and stochastic gradient descent
- Opens the relationship between ES and SGD by comparing the approximate gradient calculated by ES with the exact gradient calculated by SGD in the MNIST set under different conditions.
- Develops fast proxies that predict the expected performance from ES for different population sizes.
- Represents and demonstrates various ways to accelerate and improve ES performance.
- Limited ES disturbances significantly speed up execution in parallel infrastructure.
- An ES without a mini-batch improves gradient estimation by replacing the mini-batch approach developed by SGD with another approach tuned to ES: a random subset of the complete training sequence is assigned to each member of the ES population at each iteration of the algorithm. This ES-specialized approach provides better accuracy for ES compared to the first approach, and the learning curve is much smoother than even for SGD.
- The ES version without a minibat achieves 99 percent accuracy on a test run, which is the best declared performance of the evolutionary approach in this learning task with the teacher.
- In general, it helps to show why ES is able to compete with RL, where the gradient information obtained during tests in the domain is less informative than that obtained when training with a teacher.
- ES is more than just a traditional finite difference approximator.
- The important differences between ES and traditional finite difference methods are emphasized, namely that ES optimizes the optimal distribution of solutions (as opposed to one optimal solution).
- One interesting consequence: the solutions found by ES tend to be resistant to parameter perturbations. For example, we show that models of a humanoid pedometer are much more resistant to perturbation of parameters than those found using the GA or TRPO.
- Another important consequence: it is expected that ES will solve some problems in which traditional methods fall into the trap and vice versa. Simple examples illustrate these differences in dynamics between ES and traditional gradient following.
- Improving research in Evolutionary Deep Learning Strategies with reinforcement through a population of agents seeking novelty
- Adds the ability to promote in-depth research in ES
- Indicates that algorithms that were invented to facilitate surveys in small evolutionary neural networks through a population of research agents — in particular, novelty search (NS) and quality (QD) algorithms — can be hybridized with ES to improve performance on sparse or fraudulent RL tasks while maintaining scalability.
- Confirms that the resulting new algorithms, NS-ES and the QD-ES version, called NSR-ES, avoid the local optima faced by the ES, achieving higher performance on tasks ranging from simulated robots that learn to bypass the trap to high-dimensional Atari pixel game tasks.
- Adds this new family of search algorithms in the population to the toolkit for deep RL.
Source: https://habr.com/ru/post/345950/
All Articles