Docker self-organizing service infrastructure
My name is Danila Shtan, I am a technical manager, architect and CTO at Point. Below, I will tell you how in one particular company, and then in a few more, they solved one rather simple task - building the infrastructure for production, and in such a way that developers do not strain, and everyone was comfortable.

The material was prepared specifically for the blog @ Conference Oleg Bunin (Ontiko) based on my report at RootConf 2017 .
It all started with the fact that I came to work in one company, worked there for a couple of months ... And suddenly a number of factors coincided:
')
And then suddenly came the end of the 14th year. Everyone knows what happened at the end of the 14th year - Amazon has become very expensive. Not this way. He became very, very expensive. And at the same time, the only administrator resigned.
And we are such - 25 people, Amazon, Ansible (as it turned out later, not fully written), a huge online store - turnover of millions of rubles every day - you can’t fall, you can’t break, you can’t regret too.
In general, the situation is like in the picture.

We realized that we need to change something. And since the situation is such that, in general, already do not care, we decided to change absolutely everything: to reject legacy and everything.
First of all, everything there was always sawed by a large monolith, we wanted to drank a monolith into separate services (but not microservices, but just services), in one big team to make food teams more specialized of 25 people.
But at the same time, we wanted everyone to not interfere with each other. We wanted devOps, because the admin left us, and we guys are smart, we read books: “infrastructure as code” and so on, and so on, and so on.
Plus, again, if everything is automated, then everything will be easier, faster, everything will work fine, less shit of all.
Of course, since we had one admin and he quit, we decided that we would not hire new admins until we secured them at all.
These are the introductory:

Of course, in Docker, because, firstly, tender love, secondly, as I said, we wanted to do everything from scratch and cool - we are fashionable, stylish, youth guys, Docker, HYIP - everything.

Interesting questions for 2017:
At the professional festival “Russian Internet Technologies RIT ++ 2017” there were enough fingers of one hand to count those who did not hear about Docker - the trend is positive, so we were not mistaken.
I remind you that it was the end of 2014, and then Docker was like a lonely whale.

The fact is that at that time Docker - it was a great Proof Of Concept-system - containers, DSL, Docker-files and so on. He had one problem - he had never dealt with the issue of work on more than one machine.
On one machine, the internal mesh - everything is fine. More than one machine - there was nothing at all. More precisely, there were different add-ons - wrappers around Docker, which made a network between machines, threw containers to each other, and so on.
But we all had one car, of course, did not fit. We started to look at different options, we played with the one, the other, the third, the fifth, the tenth. And then we looked closely at Docker and realized that when he does the internal network, he lifts up the containers and collects all the network interfaces in one bridge so that they are in the same local area network.
But the Docker guys are trendy too, they allow you to configure everything. Therefore, there is such a cool topic: Docker can tell which bridge he is using - not his own Docker 0, as usual, but some separate one, and we can tell from which subnet IP addresses to issue to containers.
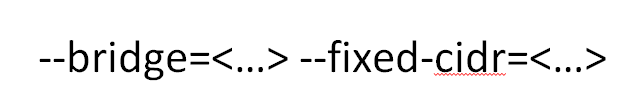
The trick is that if you take a bridge, attach it to some internal interface, to a physical machine, and then hang containers there, then all these containers will automatically see your locale. And if you say from which subnet, and make the subnet from the same larger network, from which you have all the local language, then when you pick up the container, it will have an IP from the locale, and it will see the containers on other machines on the local network .
Such a cheap way to organize an internal network for all containers.
I have already said that at that time we were moving down from Amazon, so we went to one very famous hoster in our country, took a bunch of rented hardware from him - 10-15 servers, all of them - to LAN, that's all. Predictably IP laid out pens on machines, allocated subnets for each machine.
One such big happy local network.
Cool, you can already do something - pack the application into a container, pick it up, go to each other, API, RPC, REST - whatever!
Then the question arises - how will we determine who has risen and where? Moreover, if we raise and lower containers and there are different IPs every time, there is nothing predictable.
And we took Consul. This is such a software from the guys who made Vagrant in their time, then they very tightly rested on creating all kinds of tools for infrastructure. This is a distributed repository of all information. The point is that we lift several copies, we set them against each other, and they all keep the same information inside themselves - that is, the distributed repository.
Over this, an absolutely beautiful thing was done there. There is a small agreement, how do you transmit information there, and then this Consul can answer DNS. That is, it is possible, relatively speaking, to register your service, and then from any machine that can go to this DNS, ask the service with the name of such and such, and you will be given IP - that's all.
All this is called the buzzword Service Discovery. We started using Consul from a very old version, I think, even before 0.6.
What do we end up with?
In Docker, however, you can separately register the DNS, which is transmitted to the inside of the container, we prescribe it, and on each iron machine we raise Consul in server mode.
That is, we have this cluster of Consul's on each site on each host: each host has one node, information, distributor, fault-tolerant - in general, cool!
Good software, please use!
But Consul is not only about registration. A separate Consul-server on each host machine - we have there they exchange with each other all kinds of information.
And then the question arises - that we raise the container and what? How to tell where he will be? Where and what service lives there and so on. That is, you must somehow go to Consul - either through the API, or through the same Consul, but in a slightly different mode - in the running client mode.
And here we had the first religious war. We called it inside the war of the blunt with the point.

Now it is not so acute, and then, in 2014-15, when the HYIP around Docker was just beginning to rise, there was a lot of controversy: Docker is to isolate one process? Yes, there is PID 1, when the whole environment rises, the binary starts, in the Docker file you register the entry point - this is it. Or you can cram more than one process into a container, but then, respectively, you must first pick up some kind of supervisor or something else.
We argued for a very long time, it was almost really a religious war. As a result, I won, I don’t remember who is one of the endmen.
In general, we agreed that Docker is just a piece of our system, not necessarily a single process. There, inside we raise some kind of supervisor, for example:

That is, first the supervisor rises into the container, it starts up all the other processes that are needed. This may be an application that is used only for this node. This may be Cron, for example, that is, there is an application here, and next to Cron it works - this is also a process.
Accordingly, since we have agreed before, then the Consul agent can be run in the same container. This is the same Consul, only launched in a different mode, which does not participate in the general cluster, but puts information there.
When we lift the container, the Consul agent starts there. The config is already registered in it - we collect containers once in advance, everything is sewn right away. It rises, registers - in general, normally it turns out.
But only if you stupid won.
Another point about which it is very important to say is that Consul is not only Service Discovery. In general, in principle, Service Discovery in itself is a rather useless thing, because - well, ok, you have to start, and then put the containers. That is, there must be some kind of unDiscovery service.
If he falls well, that's understandable. He goes down, some software that is responsible for this, sends a signal to the cluster: “I’ve gone, goodbye!”, Removes this economy there, IP from DNS responses disappear.
But sometimes it is not, sometimes it breaks, sometimes it explodes, sometimes it goes out with an error, and so on.
Consul has a very useful tool called Health Checks. This is when you register your service, you tell the whole cluster how to check that you are alive. Usually they start everything - let's go down to the port with the URL and check that it returns via HTTP 200 ok, or something else.
But, generally, they can be made of any complexity. This is very, very important, because you can also say: "We register these, but if there is something dead, some nginx or any other service, it can always retry to the next IP in the DNS response."
This, of course, is the case. But sooner or later, some programmer Vasily will write such software that will take one IP from the answer, because he simply does not realize that there can be 10 IP in the answer in the DNS. Comes on it, everything will break with him, and you will debug it for a long time and unhappily, because no one except Basil will ever think that you can write code this way.
Therefore, service unDiscovery and Health Checks, which will be tied to Service Discovery directly, are very, very important.
We have succeeded: machines are physical, locale, containers are rising, they can see each other. Since within each container where it is needed (after all, the container is not always provided by some service to others, they can simply be launched like this), an agent is started, which registers the service in general Service Discovery and registers Health Checks. They all go back and forth - in general, everything is fine, as long as everything is beautiful.
But all this lives solely within your local language, does not solve the question of how to go outside.
In the event we were an online store, we had a service called an online storefront. This is a public website. Some services were supposed to give the API out to partners, for example. Some services raised admin panels for individual departments and divisions inside the online store, had to respond to publicly available URLs.
In all fashionable systems now it is called Ingress, when it comes to the cluster outside, it is balanced there, and so on. We started simply: we said: we will have another service, which we will launch the same way as usual, but only to tell him that he should listen to the public port on 80 - Docker port forwarding, and so on.

Inside it will be nginx, and in parallel with nginx there will be a wonderful software called Consul Template. He is from the same guys who made Consul. This software has one simple purpose - it looks in the Consul, and when something changes there, it can locally generate a new config and run some shell command, for example, nginx reload. Therefore, we can always get the actual nginx config and the actual routing of requests inward to specific services outside.
Also, when you register services in Consul, you can put all the accompanying information there in the form of tags, and all these tags will also be available in the context of this template engine, which will collect the config from the template. Therefore, there you can, for example, write a public domain - you stuff it into the service, you say - it has the public http tag, another tag - IP is such and such, this name, and from this side you generate your config.
Appetite comes with eating, so then we wanted it to not only automatically draw all services, but also, for example, draw some kind of authentication when we don’t want to let the service just like that, but only want people who logged into our central OAuth, but we don’t want to do the implementation in the application.
For example, we put and hid Grafana. Sometimes Grafana wants to look outside, not from the locale, but at the same time there is either its own authentication, or some kind of LDAP to raise - in general, there are many hemorrhoids, it is easier to log it out.
Then Let's Encrypt appeared, and it was required to automatically raise https-certificates, something else was added there.
As a result, we wrote a huge application inside. In the list of references it is in the last line. This application in public is not at all what works for us inside, but, in principle, you can ask me how it works, I will tell.

In fact, this is a fairly large application that adds 10% of the functionality, which spent 80% of the resources. Compared to the Consul Template, which works out of the box, it is stable, reliable, and 80% of your questions can be resolved.

Sometimes containers fall, explode, cars break, the network disappears on one machine, on several machines, sometimes hard drives fail, sometimes just unknown garbage happens.
And here we also had an easy religious war about what we consider containers.
Is the container closer to the virtual machine? Especially lyutical pointed ones, who shouted that “we already crammed in there a bunch of processes, a bunch of services, they work there. This is a virtual machine, just very easy! Let's treat them that way. ”
Or containers are consumables, which you threw here, lifted here, threw here, raised here - no state is stored inside, and we don’t want to leave anything.
In general, we treat containers as a consumable. No state is ever stored inside. This, of course, imposes certain restrictions on developers. For example, they cannot save anything to the local file system. Never. If the user loads a picture, it must be given to some external service.
In an amicable way, this is always and in any case necessary to be done, and not to store pictures just like that.
Or, for example, a separate question arises - what to do in this case with databases, which, by definition, should all be stored - is the state stored, is the data stored?
First, if we go back a little bit and remember about the network - it’s a peer-to-peer regular network - next to this Docker cluster we can raise the same machines from the hoster and put the bases there, as usual - like any normal DBA installs, replicates, backs up and so on. Moreover, all containers can even be registered in Service Discovery, if necessary.
And you can be the same brave guys like us, and shout that we fully live in the Docker, we committed ourselves, and so on. Then we will have to work a little, but there are no insoluble problems.
For example, in our case, we very actively used MySql and RabbitMQ. Both that, and that demands sometimes to write something on a disk and to save this data. If the container suddenly explodes, it must be lifted, set up replication, and so on.
In general, not the biggest problem is to collect such containers that will work exactly like that. You pick up the container, tell him where the other guys are, as it happens in all fashionable systems like Consul. It rises, rolls in state, takes away data, joins in a cluster and starts working.
In the case of MySql, this is done on top of Galera. Galera is such a synchronous multimaster replication. It works fine, I seriously say I love.
In the case of the "rabbit" the same garbage. It is not very difficult to write a small script that, when lifting a container, connects to the cluster and enters it.
I recommend everyone to do this - do not be retrogrades, do not put the bases on separate servers - push everything into containers, it's fun!
When we experimented with all this - we put the containers, picked up the applications - how did we roll in the new version? Of course, we didn’t do any git pull in the container. We, like the right guys, collected everything in a new container. There was a new version of the code, a new Consul'a config, some other things. Then we went to the cluster, we started it. More precisely, at first we launched the old one, then raised the new one, drove the migration.
Then marketing came and said: “Once again, downtime, arrange for your update!” ...
Clearly, we stopped, thought and said: “Well, wait - we also have Service Discovery, which automatically tells everyone who lives here; we have Health Checks that allow us to determine if a node is alive or not. And living is not necessarily not dead and not functioning! After all, this may already be raised, but not yet ready to work!
If you know how to raise and stop containers, and in the case of Docker, this is a fairly cheap operation, then all the nishtyaks like Blue / Green Deployment, Rolling Update and so on - you have them out of the box. The only thing you need is to convince all of your programmers that you need to write migrations to databases that do not stop anything.
That is, version compatibility, backward compatibility of database schemas, when you write a new version, it can work with the old version of the schema, and with the new version of the schema, then you extinguish the old, and then you clean the old one, and so on. , in fact, fairly simple things.
It is only necessary to convince programmers - it's good when you have a good stick or programmers are intelligent. But after that, everything works fine.
For example, I am very proud of how we updated what we called Internet storefronts. Several containers were launched into clusters with a new version of the code. They were getting up, and they were ready: 2 of 3 Health Checks were working. The third one didn’t work yet because the showcase was dragging the necessary data into itself, pre-cached it, warmed up the caches and so on. Then Health Checks turned on green, and that meant that there was already possible to send live traffic.
And everything has risen here, it has descended there. If something is wrong here, it has dropped here, it has risen there - it works quite simply.
The most important thing is that there is no magic in it, because you have all the tools. The trick is to be able to do it quickly. Most of the problems with update'mi are that you can't do something quickly. If you have the tools to speed up this procedure, everything works well.
The second bun was when we did the monitoring for all this: we raised the influx, Grafana, drew dashboards. In our paradigm, each team was responsible for its services - in fact, where did this whole idea come from with containers that wrap everything up inside themselves and so on. Each team sawed their service and did it as they saw fit: they made the right amount of containers with different software that they needed, they took something centralized, something did not. Grafana and influx raise each separately - stupid, so it was centralized. But in Grafana alerting'a then was not. He is now not very good, but then there was no.
We didn’t want other tools, because we need to be hipster!
But influx has an excellent software called Kapacitor. This is such a thing that you can put in your own container, write your own config there, describe the alerting that you need, pull it all into a cluster, and it will work there.
Each team writes its own software, registers it in the general Service Discovery, writes itself the environment what they need, and alerting, to which they also respond, also writes itself as they need, inside this container. You want to change something, you collect a new version of the container, send it to the cluster, and everything works.
What have we got? Yes, almost everything we needed was: containers, a network, iron cars, Service Discovery, Health Checks - all inside the container, each container inside it.
That is, all that the team needs is to assemble a container according to a predetermined agreement (not very large), because what is needed there? You need to write the config correctly in order to register your service in the internal network and, by and large, nothing else is needed. The main thing is that it works.
Then the question arises - how to run all this on several dozen cars?
We took Swarm simply because it is convenient to look at it. This is one hole for the API, where you can send a command, it’s there itself will somehow decompose these containers. In later versions of Swarm, restart condition type chips still appeared, when you can monitor the necessary number of instances of your container in a cluster to live.
In general, this is all that is needed.
Therefore, we took Swarm simply because it was already there. But I had to write my own for the small-small subset'a, which we needed: that is, 10-15-20 machines with a Docker daemon, into which you need to somehow stuff containers, make sure that they have the right amount, sometimes raise and lower - in general, nothing more is needed.
Since we are not real admins, and we all have admin prejudices - to the point of a bulb, we in the same production cluster were chasing both production, and staging, and tests, and all CI also lived there with all the new nodes that were raised there.
All this lives in one cluster because it is easier to follow one cluster than two. There is no fundamental difference - just service in a different way obzovite and everything works fine. To do this, you need to have a little reserve for iron just in case.
You can say - if everything was as easy as you say! But, everything is really quite easy: these are simple components, simple tools, there is practically no excess software.

Why is this all about?
Why do guys hundreds of man-years injected and do it all?
In fact, the answer is quite simple. Most of the problems that these guys solve through complex code, complex configs, complex concepts, and so on, in our case, are solved at the level of agreements within the team.
I sincerely believe that for the vast majority of all teams in general this is enough. You do not need sophisticated software, no need to dive into Kubernetes. This software is really quite complicated, and when the question arises - what to spend time on: trying to figure out Kubernetes or pee on some food features immediately begin picking your sock: “Well, maybe you shouldn’t ? Maybe, in the old fashioned way, git push will be thrown onto machines ”and so on.
But, dudes, Docker is a shame not to know. No one knows how to work with him. You simply add another little bit of paper there and continue to shove it into our cluster.
I sincerely believe that in most cases fairly simple technical solutions and fairly simple agreements within the team. And if this combination provides a simple service for developers who probably don’t want to deal with complex concepts, then why not?
Ontiko: friends, at the moment there is free access to videos of all reports from RootConf 2017 . We hope you find there many useful and interesting things.
Also, our program committee has already begun to accept applications from speakers. If you have a lot of experience or interesting cases, you can become the speaker of RootConf 2018. Applications can be left here .
The material was prepared specifically for the blog @ Conference Oleg Bunin (Ontiko) based on my report at RootConf 2017 .
How did it all start?
It all started with the fact that I came to work in one company, worked there for a couple of months ... And suddenly a number of factors coincided:
')
- This company was a rather large online store. At that time, it ranked among the top 15 online stores in the country according to different ratings;
- in this company there was a group of 25 developers who all sawed in-house, there generally historically everything was written inside - from warehouse management and logistics to web muzzles, all baskets, and so on;
- there was one admin who drove all the production, deployed code, the developers wrote, he did git pull, poured various nodes, Ansible he had ... He was fine, and it all lived in Amazon, on AWS, on EC2.
And then suddenly came the end of the 14th year. Everyone knows what happened at the end of the 14th year - Amazon has become very expensive. Not this way. He became very, very expensive. And at the same time, the only administrator resigned.
And we are such - 25 people, Amazon, Ansible (as it turned out later, not fully written), a huge online store - turnover of millions of rubles every day - you can’t fall, you can’t break, you can’t regret too.
In general, the situation is like in the picture.
We realized that we need to change something. And since the situation is such that, in general, already do not care, we decided to change absolutely everything: to reject legacy and everything.
What did we want to do?
First of all, everything there was always sawed by a large monolith, we wanted to drank a monolith into separate services (but not microservices, but just services), in one big team to make food teams more specialized of 25 people.
But at the same time, we wanted everyone to not interfere with each other. We wanted devOps, because the admin left us, and we guys are smart, we read books: “infrastructure as code” and so on, and so on, and so on.
Plus, again, if everything is automated, then everything will be easier, faster, everything will work fine, less shit of all.
Of course, since we had one admin and he quit, we decided that we would not hire new admins until we secured them at all.
These are the introductory:
Where did we go?
Of course, in Docker, because, firstly, tender love, secondly, as I said, we wanted to do everything from scratch and cool - we are fashionable, stylish, youth guys, Docker, HYIP - everything.
Interesting questions for 2017:
- Who about Docker did not hear at all?
- And who worked with Docker at least on a local machine?
- And who is the Docker in the production for at least some insignificant service running?
- And who in Docker in production lives entirely, in general there is nothing else, only Docker-containers?
At the professional festival “Russian Internet Technologies RIT ++ 2017” there were enough fingers of one hand to count those who did not hear about Docker - the trend is positive, so we were not mistaken.
I remind you that it was the end of 2014, and then Docker was like a lonely whale.
The fact is that at that time Docker - it was a great Proof Of Concept-system - containers, DSL, Docker-files and so on. He had one problem - he had never dealt with the issue of work on more than one machine.
On one machine, the internal mesh - everything is fine. More than one machine - there was nothing at all. More precisely, there were different add-ons - wrappers around Docker, which made a network between machines, threw containers to each other, and so on.
But we all had one car, of course, did not fit. We started to look at different options, we played with the one, the other, the third, the fifth, the tenth. And then we looked closely at Docker and realized that when he does the internal network, he lifts up the containers and collects all the network interfaces in one bridge so that they are in the same local area network.
But the Docker guys are trendy too, they allow you to configure everything. Therefore, there is such a cool topic: Docker can tell which bridge he is using - not his own Docker 0, as usual, but some separate one, and we can tell from which subnet IP addresses to issue to containers.
The trick is that if you take a bridge, attach it to some internal interface, to a physical machine, and then hang containers there, then all these containers will automatically see your locale. And if you say from which subnet, and make the subnet from the same larger network, from which you have all the local language, then when you pick up the container, it will have an IP from the locale, and it will see the containers on other machines on the local network .
Such a cheap way to organize an internal network for all containers.
I have already said that at that time we were moving down from Amazon, so we went to one very famous hoster in our country, took a bunch of rented hardware from him - 10-15 servers, all of them - to LAN, that's all. Predictably IP laid out pens on machines, allocated subnets for each machine.
What have we got?
- We wanted containers - we made them.
- We have cars - we lift containers on them.
- All containers see each other.
One such big happy local network.
Cool, you can already do something - pack the application into a container, pick it up, go to each other, API, RPC, REST - whatever!
Then the question arises - how will we determine who has risen and where? Moreover, if we raise and lower containers and there are different IPs every time, there is nothing predictable.
And we took Consul. This is such a software from the guys who made Vagrant in their time, then they very tightly rested on creating all kinds of tools for infrastructure. This is a distributed repository of all information. The point is that we lift several copies, we set them against each other, and they all keep the same information inside themselves - that is, the distributed repository.
Over this, an absolutely beautiful thing was done there. There is a small agreement, how do you transmit information there, and then this Consul can answer DNS. That is, it is possible, relatively speaking, to register your service, and then from any machine that can go to this DNS, ask the service with the name of such and such, and you will be given IP - that's all.
All this is called the buzzword Service Discovery. We started using Consul from a very old version, I think, even before 0.6.
What do we end up with?
- We have hosts;
- we have containers on them;
- containers see each other;
- we have tools for working with containers.
In Docker, however, you can separately register the DNS, which is transmitted to the inside of the container, we prescribe it, and on each iron machine we raise Consul in server mode.
That is, we have this cluster of Consul's on each site on each host: each host has one node, information, distributor, fault-tolerant - in general, cool!
Good software, please use!
But Consul is not only about registration. A separate Consul-server on each host machine - we have there they exchange with each other all kinds of information.
And then the question arises - that we raise the container and what? How to tell where he will be? Where and what service lives there and so on. That is, you must somehow go to Consul - either through the API, or through the same Consul, but in a slightly different mode - in the running client mode.
And here we had the first religious war. We called it inside the war of the blunt with the point.
Now it is not so acute, and then, in 2014-15, when the HYIP around Docker was just beginning to rise, there was a lot of controversy: Docker is to isolate one process? Yes, there is PID 1, when the whole environment rises, the binary starts, in the Docker file you register the entry point - this is it. Or you can cram more than one process into a container, but then, respectively, you must first pick up some kind of supervisor or something else.
We argued for a very long time, it was almost really a religious war. As a result, I won, I don’t remember who is one of the endmen.
In general, we agreed that Docker is just a piece of our system, not necessarily a single process. There, inside we raise some kind of supervisor, for example:
That is, first the supervisor rises into the container, it starts up all the other processes that are needed. This may be an application that is used only for this node. This may be Cron, for example, that is, there is an application here, and next to Cron it works - this is also a process.
Accordingly, since we have agreed before, then the Consul agent can be run in the same container. This is the same Consul, only launched in a different mode, which does not participate in the general cluster, but puts information there.
When we lift the container, the Consul agent starts there. The config is already registered in it - we collect containers once in advance, everything is sewn right away. It rises, registers - in general, normally it turns out.
But only if you stupid won.
Another point about which it is very important to say is that Consul is not only Service Discovery. In general, in principle, Service Discovery in itself is a rather useless thing, because - well, ok, you have to start, and then put the containers. That is, there must be some kind of unDiscovery service.
If he falls well, that's understandable. He goes down, some software that is responsible for this, sends a signal to the cluster: “I’ve gone, goodbye!”, Removes this economy there, IP from DNS responses disappear.
But sometimes it is not, sometimes it breaks, sometimes it explodes, sometimes it goes out with an error, and so on.
Consul has a very useful tool called Health Checks. This is when you register your service, you tell the whole cluster how to check that you are alive. Usually they start everything - let's go down to the port with the URL and check that it returns via HTTP 200 ok, or something else.
But, generally, they can be made of any complexity. This is very, very important, because you can also say: "We register these, but if there is something dead, some nginx or any other service, it can always retry to the next IP in the DNS response."
This, of course, is the case. But sooner or later, some programmer Vasily will write such software that will take one IP from the answer, because he simply does not realize that there can be 10 IP in the answer in the DNS. Comes on it, everything will break with him, and you will debug it for a long time and unhappily, because no one except Basil will ever think that you can write code this way.
Therefore, service unDiscovery and Health Checks, which will be tied to Service Discovery directly, are very, very important.
So what we got?
We have succeeded: machines are physical, locale, containers are rising, they can see each other. Since within each container where it is needed (after all, the container is not always provided by some service to others, they can simply be launched like this), an agent is started, which registers the service in general Service Discovery and registers Health Checks. They all go back and forth - in general, everything is fine, as long as everything is beautiful.
But all this lives solely within your local language, does not solve the question of how to go outside.
In the event we were an online store, we had a service called an online storefront. This is a public website. Some services were supposed to give the API out to partners, for example. Some services raised admin panels for individual departments and divisions inside the online store, had to respond to publicly available URLs.
How to solve it?
In all fashionable systems now it is called Ingress, when it comes to the cluster outside, it is balanced there, and so on. We started simply: we said: we will have another service, which we will launch the same way as usual, but only to tell him that he should listen to the public port on 80 - Docker port forwarding, and so on.
Inside it will be nginx, and in parallel with nginx there will be a wonderful software called Consul Template. He is from the same guys who made Consul. This software has one simple purpose - it looks in the Consul, and when something changes there, it can locally generate a new config and run some shell command, for example, nginx reload. Therefore, we can always get the actual nginx config and the actual routing of requests inward to specific services outside.
Also, when you register services in Consul, you can put all the accompanying information there in the form of tags, and all these tags will also be available in the context of this template engine, which will collect the config from the template. Therefore, there you can, for example, write a public domain - you stuff it into the service, you say - it has the public http tag, another tag - IP is such and such, this name, and from this side you generate your config.
Appetite comes with eating, so then we wanted it to not only automatically draw all services, but also, for example, draw some kind of authentication when we don’t want to let the service just like that, but only want people who logged into our central OAuth, but we don’t want to do the implementation in the application.
For example, we put and hid Grafana. Sometimes Grafana wants to look outside, not from the locale, but at the same time there is either its own authentication, or some kind of LDAP to raise - in general, there are many hemorrhoids, it is easier to log it out.
Then Let's Encrypt appeared, and it was required to automatically raise https-certificates, something else was added there.
As a result, we wrote a huge application inside. In the list of references it is in the last line. This application in public is not at all what works for us inside, but, in principle, you can ask me how it works, I will tell.
In fact, this is a fairly large application that adds 10% of the functionality, which spent 80% of the resources. Compared to the Consul Template, which works out of the box, it is stable, reliable, and 80% of your questions can be resolved.
Sometimes containers fall, explode, cars break, the network disappears on one machine, on several machines, sometimes hard drives fail, sometimes just unknown garbage happens.
And here we also had an easy religious war about what we consider containers.
Is the container closer to the virtual machine? Especially lyutical pointed ones, who shouted that “we already crammed in there a bunch of processes, a bunch of services, they work there. This is a virtual machine, just very easy! Let's treat them that way. ”
Or containers are consumables, which you threw here, lifted here, threw here, raised here - no state is stored inside, and we don’t want to leave anything.
In general, we treat containers as a consumable. No state is ever stored inside. This, of course, imposes certain restrictions on developers. For example, they cannot save anything to the local file system. Never. If the user loads a picture, it must be given to some external service.
In an amicable way, this is always and in any case necessary to be done, and not to store pictures just like that.
Or, for example, a separate question arises - what to do in this case with databases, which, by definition, should all be stored - is the state stored, is the data stored?
First, if we go back a little bit and remember about the network - it’s a peer-to-peer regular network - next to this Docker cluster we can raise the same machines from the hoster and put the bases there, as usual - like any normal DBA installs, replicates, backs up and so on. Moreover, all containers can even be registered in Service Discovery, if necessary.
And you can be the same brave guys like us, and shout that we fully live in the Docker, we committed ourselves, and so on. Then we will have to work a little, but there are no insoluble problems.
For example, in our case, we very actively used MySql and RabbitMQ. Both that, and that demands sometimes to write something on a disk and to save this data. If the container suddenly explodes, it must be lifted, set up replication, and so on.
In general, not the biggest problem is to collect such containers that will work exactly like that. You pick up the container, tell him where the other guys are, as it happens in all fashionable systems like Consul. It rises, rolls in state, takes away data, joins in a cluster and starts working.
In the case of MySql, this is done on top of Galera. Galera is such a synchronous multimaster replication. It works fine, I seriously say I love.
In the case of the "rabbit" the same garbage. It is not very difficult to write a small script that, when lifting a container, connects to the cluster and enters it.
I recommend everyone to do this - do not be retrogrades, do not put the bases on separate servers - push everything into containers, it's fun!
About nishtyaki, which we from this (almost) received for free
When we experimented with all this - we put the containers, picked up the applications - how did we roll in the new version? Of course, we didn’t do any git pull in the container. We, like the right guys, collected everything in a new container. There was a new version of the code, a new Consul'a config, some other things. Then we went to the cluster, we started it. More precisely, at first we launched the old one, then raised the new one, drove the migration.
Then marketing came and said: “Once again, downtime, arrange for your update!” ...
Clearly, we stopped, thought and said: “Well, wait - we also have Service Discovery, which automatically tells everyone who lives here; we have Health Checks that allow us to determine if a node is alive or not. And living is not necessarily not dead and not functioning! After all, this may already be raised, but not yet ready to work!
If you know how to raise and stop containers, and in the case of Docker, this is a fairly cheap operation, then all the nishtyaks like Blue / Green Deployment, Rolling Update and so on - you have them out of the box. The only thing you need is to convince all of your programmers that you need to write migrations to databases that do not stop anything.
That is, version compatibility, backward compatibility of database schemas, when you write a new version, it can work with the old version of the schema, and with the new version of the schema, then you extinguish the old, and then you clean the old one, and so on. , in fact, fairly simple things.
It is only necessary to convince programmers - it's good when you have a good stick or programmers are intelligent. But after that, everything works fine.
For example, I am very proud of how we updated what we called Internet storefronts. Several containers were launched into clusters with a new version of the code. They were getting up, and they were ready: 2 of 3 Health Checks were working. The third one didn’t work yet because the showcase was dragging the necessary data into itself, pre-cached it, warmed up the caches and so on. Then Health Checks turned on green, and that meant that there was already possible to send live traffic.
And everything has risen here, it has descended there. If something is wrong here, it has dropped here, it has risen there - it works quite simply.
The most important thing is that there is no magic in it, because you have all the tools. The trick is to be able to do it quickly. Most of the problems with update'mi are that you can't do something quickly. If you have the tools to speed up this procedure, everything works well.
The second bun was when we did the monitoring for all this: we raised the influx, Grafana, drew dashboards. In our paradigm, each team was responsible for its services - in fact, where did this whole idea come from with containers that wrap everything up inside themselves and so on. Each team sawed their service and did it as they saw fit: they made the right amount of containers with different software that they needed, they took something centralized, something did not. Grafana and influx raise each separately - stupid, so it was centralized. But in Grafana alerting'a then was not. He is now not very good, but then there was no.
We didn’t want other tools, because we need to be hipster!
But influx has an excellent software called Kapacitor. This is such a thing that you can put in your own container, write your own config there, describe the alerting that you need, pull it all into a cluster, and it will work there.
Each team writes its own software, registers it in the general Service Discovery, writes itself the environment what they need, and alerting, to which they also respond, also writes itself as they need, inside this container. You want to change something, you collect a new version of the container, send it to the cluster, and everything works.
What have we got? Yes, almost everything we needed was: containers, a network, iron cars, Service Discovery, Health Checks - all inside the container, each container inside it.
That is, all that the team needs is to assemble a container according to a predetermined agreement (not very large), because what is needed there? You need to write the config correctly in order to register your service in the internal network and, by and large, nothing else is needed. The main thing is that it works.
Then the question arises - how to run all this on several dozen cars?
We took Swarm simply because it is convenient to look at it. This is one hole for the API, where you can send a command, it’s there itself will somehow decompose these containers. In later versions of Swarm, restart condition type chips still appeared, when you can monitor the necessary number of instances of your container in a cluster to live.
In general, this is all that is needed.
Therefore, we took Swarm simply because it was already there. But I had to write my own for the small-small subset'a, which we needed: that is, 10-15-20 machines with a Docker daemon, into which you need to somehow stuff containers, make sure that they have the right amount, sometimes raise and lower - in general, nothing more is needed.
Bravery and stupidity
Since we are not real admins, and we all have admin prejudices - to the point of a bulb, we in the same production cluster were chasing both production, and staging, and tests, and all CI also lived there with all the new nodes that were raised there.
All this lives in one cluster because it is easier to follow one cluster than two. There is no fundamental difference - just service in a different way obzovite and everything works fine. To do this, you need to have a little reserve for iron just in case.
You can say - if everything was as easy as you say! But, everything is really quite easy: these are simple components, simple tools, there is practically no excess software.
Why is this all about?
Why do guys hundreds of man-years injected and do it all?
In fact, the answer is quite simple. Most of the problems that these guys solve through complex code, complex configs, complex concepts, and so on, in our case, are solved at the level of agreements within the team.
I sincerely believe that for the vast majority of all teams in general this is enough. You do not need sophisticated software, no need to dive into Kubernetes. This software is really quite complicated, and when the question arises - what to spend time on: trying to figure out Kubernetes or pee on some food features immediately begin picking your sock: “Well, maybe you shouldn’t ? Maybe, in the old fashioned way, git push will be thrown onto machines ”and so on.
But, dudes, Docker is a shame not to know. No one knows how to work with him. You simply add another little bit of paper there and continue to shove it into our cluster.
I sincerely believe that in most cases fairly simple technical solutions and fairly simple agreements within the team. And if this combination provides a simple service for developers who probably don’t want to deal with complex concepts, then why not?
Ontiko: friends, at the moment there is free access to videos of all reports from RootConf 2017 . We hope you find there many useful and interesting things.
Also, our program committee has already begun to accept applications from speakers. If you have a lot of experience or interesting cases, you can become the speaker of RootConf 2018. Applications can be left here .
Source: https://habr.com/ru/post/345842/
All Articles