Kubernetes success stories in production. Part 6: BlaBlaCar

Founded in 2006, BlaBlaCar is considered the world's largest online search service for car travel companions (ridesharing). Appearing in France, the service underwent an active expansion in Europe, from 2014 it became available in Russia and Ukraine, and later reached the countries of Latin America and Asia. The rise in popularity of online services is inevitably associated with the development of the IT infrastructure behind them, and, as is easy to guess from the title of the article, today's needs of BlaBlaCar are realized thanks to Kubernetes. What did the company's IT engineers come to?
Prehistory
In February 2016, BlaBlaCar blog published a note with a story about their way to the containers. The entire infrastructure of the company was initially built on its servers (bare metal), which over time (as computing resources grew) were reduced to several typical configurations.
')
To manage all the software services on these servers, Chef has been used for a long time with a streamlined workflow, including code review, testing, etc. To isolate services that are not particularly demanding of performance (for testing, pre-production, and others), a VMware-based cluster. Problems with it were described as automation complexity, insufficient performance (compared to bare metal) and high cost (when it comes to a large number of nodes). It was then at BlaBlaCar that they decided, without considering the other “classic” virtualization options, to immediately switch to containers . As an additional factor in favor of containers, the possibility of rapid allocation of resources is given.
2015—2016: transition to containers
As a container solution, BlaBlaCar chose ... no, not Docker, but rkt . The reason for this was "the awareness of the existing limitations of the product, which were very important for use in production." And it just so happened that during their experiments with containers, the CoreOS project announced its development - an executable environment for rkt containers (then known as Rocket).
Shortly before, the BlaBlaCar engineers managed to fall in love with the CoreOS operating system (it was later that they stopped as the main container infrastructure), so they decided to try a new product of the same project. And they liked the result: "We were surprised at the stability of rkt even in its earliest versions, and all the important functions we needed were promptly added by the CoreOS team."
Note : BlaBlaCar and today remains among the not so numerous eminent rkt users in production. Their official list can be found on the CoreOS website .
Continuing to use Chef for containers, the company's engineers faced a number of inconveniences that can be summarized as unnecessary difficulties where they should not be (for example, there was no easy way to customize the config when the container was started, when you need to change the node ID in the cluster). Began the search for a new solution, the requirements for which were formulated as follows:
- quick build;
- ease of understanding for new employees;
- minimum possible code replication;
- templates used when starting the container;
- good integration with rkt.
It was not possible to find a suitable tool, so the authors created their own - dgr . It was originally written in Bash, but then the authors rewrote Go. In GitHub, the product is called “a console utility created for assembly and configuration during the launch of App Containers Images ( ACI ) and App Container Pods ( POD ), based on the concept of configuration agreement (convention over configuration)”.
The general scheme of work dgr is as follows:

A direct use of the utility is demonstrated as follows:

Orchestration required the simplest solution (there was no time to experiment with large systems), so the choice fell on the standard tool of the same CoreOS- fleet . To help him, for the automated creation of all systemd units (based on the description of environments and services in them in the file system), the GGN utility (green-garden) was developed.
The result of the stage in BlaBlaCar is the transition from the idea of using containers to launching more than 90% of production-services in them in 7 months . A great desire to continue to use Chef - a reliable tool, in which the engineers invested a lot of time - had to be corrected with the understanding that "the classic configuration management tools are not suitable for assembling and managing containers".
2016—2017: current infrastructure and transition to Kubernetes
Updated information on the company's infrastructure appeared quite recently - at the end of last month - in the publication “ The Expendables - Backends High Availability at BlaBlaCar ” from engineer BlaBlaCar. Over the past almost 2 years, the company has come to the concept of " expendables" in infrastructure, which is similar to the well-known story about cattle and pets (cattle vs. pets) .
The general essence is that each infrastructure component must be ready for restart at any time and not affect the operation of applications. Obviously, the special difficulty in implementing such an approach appears with the DBMS administrators, so it is doubly noteworthy that the corresponding specialist Maxime Fouilleul, who is in the position of Database Engineer, tells about the BlaBlaCar experience.
So, the current infrastructure of the company is as follows:

All ACIs (Application Container Images) and PODs are created and assembled using the already mentioned development of the company - dgr. Once assembled in a continuous integration system, PODs are placed in the central registry and are ready for use. To run them on the servers, a special stack called the Distributed Units System is used , based on fleet and etcd. Its purpose is the distributed launch of the usual systemd units throughout the data center, as if it happens on a local machine. To specify the target host, special metadata is added to the unit-file — for example, this is relevant for MySQL, the installation of which is tied to a specific server.
Note : The BlaBlaCar DBMS started with asynchronous replication in MySQL, however, because of the difficulties of recovery when the wizard crashes (since it’s a single point of failure) and the need to track replication latency in applications (otherwise non-consistent data) replication based on the galera cluster . Today in production use MariaDB and Galera: this option allows you to consider all the nodes with MySQL with the same "consumables", which is important for an ecosystem built on containers.
Finally, in order to generate and deploy systemd units in the company, they use another (already mentioned) their development - ggn. And now, engineers are working to standardize the orchestration of their Kubernetes-based PODs.
Service discovery
The task of service discovery in BlaBlaCar is rightly considered one of the keys for building a fault-tolerant and scalable infrastructure. To achieve this, the company rewrote a specialized Airbnb framework, SmartStack, into Go . It is based on two components:
- go-nerve is a utility for tracking the state of services, which launches various checks (via TCP and HTTP protocols, system calls, execution of SQL commands, etc.) and reports their results to the corresponding systems; runs on each instance of the service (more than 2000 in BlaBlaCar) and transfers the status to the Apache ZooKeeper storage;
- go-synapse is a direct service discovery mechanism that monitors services (tracks key values stored in ZooKeeper) and updates their state in the router (based on HAProxy).
Both utilities are not just rewritten versions of the Airbnb development of the same name ( Nerve , Synapse ), but also expand their capabilities according to the needs of BlaBlaCar (for more details, see their GitHub repositories in the links above) . The general algorithm of interaction between service discovery components is depicted in this diagram:

An example of configuration (configs) of service discovery for MySQL is hidden here for enthusiasts.
Nerve for MySQL (
ZooKeeper result:
And the settings in Synapse (
env/prod-dc1/services/mysql-main/attributes/nerve.yml ): override: nerve: services: - name: "main-read" port: 3306 reporters: - {type: zookeeper, path: /services/mysql/main_read} checks: - type: sql driver: mysql datasource: "local_mon:local_mon@tcp(127.0.0.1:3306)/" - name: "main-write" port: 3306 reporters: - {type: zookeeper, path: /services/mysql/main_write} checks: - type: sql driver: mysql datasource: "local_mon:local_mon@tcp(127.0.0.1:3306)/" haproxyServerOptions: "backup" ZooKeeper result:
# zookeepercli -c lsr /services/mysql/main_read mysql-main_read1_192.168.1.2_ba0f1f8b3 mysql-main_read2_192.168.1.3_734d63da mysql-main_read3_192.168.1.4_dde45787 # zookeepercli -c get /services/mysql/mysql-main_read1_192.168.1.2_ba0f1f8b3 { "available":true, "host":"192.168.1.2", "port":3306, "name":"mysql-main1", "weight":255, "labels":{ "host":"r10-srv4" } } # zookeepercli -c get /services/mysql/mysql-main_write1_192.168.1.2_ba0f1f8b3 { "available":true, "host":"192.168.1.2", "port":3306, "name":"mysql-main1", "haproxy_server_options":"backup", "weight":255, "labels":{ "host":"r10-srv4" } } And the settings in Synapse (
env/prod-dc1/services/tripsearch/attributes/synapse.yml ): override: synapse: services: - name: mysql-main_read path: /services/mysql/main_read port: 3307 serverCorrelation: type: excludeServer otherServiceName: mysql-main_write scope: first - name: mysql-main_write path: /services/mysql/main_write port: 3308 serverSort: date Kubernetes at BlaBlaCar. Enjoliver
According to an interview in April 2017, the introduction of Kubernetes into BlaBlaCar occurred gradually, and the first components in production were launched “3 months ago.” However, despite the repeated references to Kubernetes in the infrastructure, there are not so many details about its structure in the existing articles. Another BlaBlaCar project on GitHub, Enjoliver, helps shed light on this question.
Enjoliver (from the French word “embellish”) is described as a tool for “deploying and supporting a usable Kubernetes cluster”. He has been conducting his public history since October 2016, and his main source code (including his Engine and API) has been written in Python. As an executable environment for containers, Enjoliver is used, as everyone guessed, rkt from CoreOS, as well as CoreOS Container Linux, Fleet, CNI and Vault are involved in the cluster. The overall architecture is as follows:
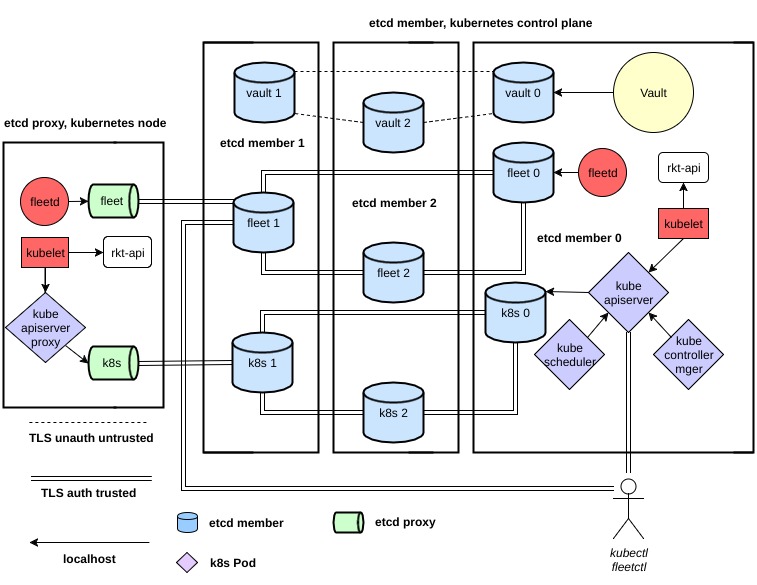
The authors identify four main areas of work / development of Enjoliver:
- Kubernetes cluster role configuration (control plane and nodes);
- service discovery topology, Kubernetes role planning and cluster life cycle support — the Enjoliver Engine is responsible for this;
- e2e testing Enjoliver;
- Kubernetes application for development purposes, including ready-made examples of using Helm / Tiller, Heapster, Kubernetes Dashboard, Prometheus, Vault UI, CronJobs for etcd backups.
Description Enjoliver will draw on a separate material ... You can begin to get acquainted with it with a sufficiently detailed README , including a brief instruction for test deployment (see chapter “Development - Local KVM”), the authors of which, however, promise to improve it soon.
Finally, additional information on the use of Kubernetes in BlaBlaCar became available from a case study written according to the company's infrastructure engineer (Simon Lallemand) and published on the Kubernetes website. In particular, it reports the following:
- The BlaBlaCar engineers sought to provide developers with greater autonomy in deploying services (using rkt containers), and Kubernetes responded to their requests in the summer of 2016, when support for this executable environment began to appear in the system. The first launch of K8s in production took place by the end of 2016.
- The entire infrastructure (about 100 developers use it) is serviced by a team of 25 people.
- To date, BlaBlaCar has about 3,000 pods, 1,200 of which work for Kubernetes.
- Prometheus is used for monitoring.
Other articles from the cycle
- “ Kubernetes success stories in production. Part 1: 4,200 pods and TessMaster on eBay . ”
- “ Kubernetes success stories in production. Part 2: Concur and SAP . ”
- “ Kubernetes success stories in production. Part 3: GitHub .
- “ Kubernetes success stories in production. Part 4: SoundCloud (by Prometheus) . ”
- “ Kubernetes success stories in production. Part 5: Monzo Digital Bank .
- “ Kubernetes success stories in production. Part 7: BlackRock .
- “ Kubernetes success stories in production. Part 8: Huawei .
- “ Kubernetes success stories in production. Part 9: CERN and 210 K8s clusters. ”
- “ Kubernetes success stories in production. Part 10: Reddit .
Source: https://habr.com/ru/post/345780/
All Articles