What is Hashing? Under the hood of the blockchain
Many of you have probably already heard about blockchain technology, but it is important to know about how hashing works in this system. The Blockchain technology is one of the most innovative discoveries of the last century. We can say so without exaggeration, as we observe the influence it has had over the past few years and the influence it will have in the future. In order to understand the structure and purpose of the blockchain technology itself, we first need to understand one of the basic principles of blockchain creation.
In simple words, hashing means entering information of any length and size in the source line and returning the result of a fixed length given by the algorithm of the hashing function. In the context of cryptocurrency, such as Bitcoin, transactions after hashing at the output look like a set of characters defined by the length algorithm (Bitcoin uses SHA-256).

Input- input data, hash- hash
Let's see how the hashing process works. We are going to enter certain data. For this, we will use SHA-256 (a secure hash algorithm from the SHA-2 family, 256 bits in size).
')
As you can see, in the case of SHA-256, no matter how large your input data (input), the output will always have a fixed 256-bit length. This is extremely necessary when you are dealing with a huge amount of data and transactions. Thus, instead of remembering the input data, which can be huge, you can simply remember the hash and track it. Before proceeding, it is necessary to get acquainted with the various properties of the hashing functions and how they are implemented in the blockchain.
A cryptographic hash function is a special class of hash functions that has various properties necessary for cryptography. There are certain properties that a cryptographic hash function must have in order to be considered secure. Let's deal with them in turn.
Property 1: Deterministic
This means that no matter how many times you analyze a particular input through a hash function, you always get the same result. This is important because if you receive different hashes every time, it will be impossible to track input.
Property 2: Fast Calculation
The hash function must be able to quickly return the hash input. If the process is not fast enough, the system simply will not be effective.
Property 3: The complexity of the inverse calculation
The complexity of the inverse calculation means that given H (A), it is impossible to determine A, where A is the input data and H (A) is the hash. Note the use of the word “impossible” instead of the word “impracticable.” We already know that it is possible to determine the source data by their hash value. Take an example.
Suppose you are playing dice, and the final number is a hash of a number that appears from the dice. How can you determine what the source number is? Simply, all you have to do is find the hashes of all the numbers from 1 to 6 and compare. Since the hash functions are deterministic, the hash of a particular number will always be the same, so you can simply compare the hashes and find out the source number.
But this only works when this amount of data is very small. What happens when you have a huge amount of data? Suppose you are dealing with a 128-bit hash. The only method by which you must find the source data is the “brute force” method. The “brute force” method means that you need to select a random entry, hash it, then compare the result with the test hash and repeat until you find a match.
So what happens if you use this method?
Thus, it is possible to break through the function of the inverse calculation using the “brute force” method, but it will take a lot of time and computational resources, so it is useless.
Property 4: Small changes in input change the hash
Even if you make small changes to the source data, the changes that will be reflected in the hash will be huge. Let's check with SHA-256:

Do you see? Even if you just changed the case of the first letter, notice how much this affected the output hash. This is a necessary function, since the hashing property leads to one of the main qualities of the blockchain - its immutability (more on this later).
Property 5: collision stability
Given the two different types of source data A and B, where H (A) and H (B) are their corresponding hashes, for H (A) it cannot be equal to H (B). This means that, for the most part, each entry will have its own unique hash. Why did we say “for the most part”? Let's talk about an interesting concept called “The Paradox of Birthday”.
What is the birthday paradox?
If you accidentally meet a stranger on the street, the chance that your dates of birthdays will match is very small. In fact, if you assume that all days of the year have the same probability of a birthday, the chances of another person sharing your birthday are 1/365 or 0.27%. In other words, it is really low.
However, for example, if you gather 20-30 people in the same room, the chances of two people sharing the same day increase dramatically. In fact, the chance for 2 people is 50-50, sharing the same birthday in this situation.
How does this apply to hashing?
Suppose you have a 128-bit hash that has 2 ^ 128 different probabilities. Using the birthday paradox, you have a 50% chance to break the conflict resistance sqrt (2 ^ 128) = 2 ^ 64.
As you have noticed, it is much easier to break the collision resistance than to find the inverse calculation of the hash. This usually takes a long time. So, if you use a function such as SHA-256, you can safely assume that if H (A) = H (B), then A = B.
Property 6: Puzzle
Properties The puzzle has the strongest effect on cryptocurrency topics (more on this later when we dive into crypto schemes). First, let's define a property, after which we will look at each term in detail.
For each “Y” output, if k is chosen from a distribution with high min-entropy, it is impossible to find input data x such that H (k | x) = Y.
This is probably beyond your comprehension! But it's all right, now let's deal with this definition.
What is the meaning of "high mine entropy"?
This means that the distribution from which the value is chosen is scattered so that we choose a random value that has a negligible probability. In principle, if you are told to choose a number from 1 to 5, this is a low distribution of min-entropy. However, if you chose a number from 1 to infinity, this is a high distribution of min-entropy.
What does "k | x" mean?
"|" Denotes concatenation. Concatenation means the union of two strings. For example. If I combined the "blue" and "sky", then the result would be "blue sky".
So let's go back to the definition.
Suppose you have an output value "Y". If you choose a random “K” value, it is impossible to find the value of X, such that a concatenation hash from K and X will yield Y as a result.
Once again pay attention to the word "impossible", but it is possible, because people do it all the time. In fact, the whole process of mining works on this (more later).
Examples of cryptographic hash functions:
Hashing and data structures.
The data structure is a specialized way to store data. If you want to understand how the blockchain system works, then there are two basic properties of the data structure that can help you with this:
1. Pointers
2. Related listings
Pointers
In programming, pointers are variables that store the address of another variable, regardless of the programming language used.
For example, the record int a = 10 means that there is a certain variable “a”, which stores an integer value equal to 10. This is how a standard variable looks.
However, instead of storing values, pointers store the addresses of other variables. That is why they got their name, because they literally indicate the location of other variables.
Related Lists
The linked list is one of the most important elements in data structures. The structure of the linked list is as follows:

* Head - heading; Data - data; Pointer - pointer; Record - record; Null - zero
This is a sequence of blocks, each of which contains data associated with the next using a pointer. The pointer variable in this case contains the address of the next node, thereby making the connection. As shown in the diagram, the last node is marked with a null pointer, which means that it does not matter.
It is important to note that the pointer inside each block contains the address of the previous one. So the chain is formed. The question arises, what does this mean for the first block in the list and where is its pointer located?
The first block is called the “genesis block”, and its index is in the system itself. It looks like this:

* H () - Hash pointers are rendered this way.
If you are interested in what “hash pointer” means, then we will be happy to explain.
As you already understood, the blockchain structure is based on this. A chain of blocks is a linked list. Consider the structure of the blockchain:
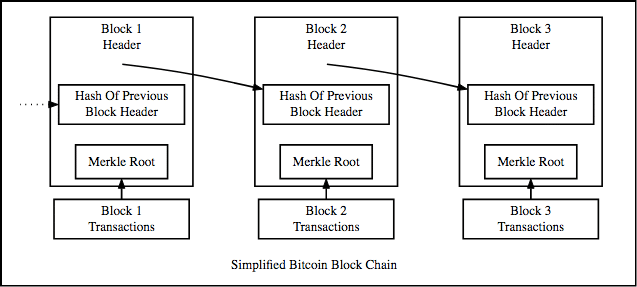
* Hash of previous block header - hash of the previous block header; Merkle Root - Merkle Root; Transactions - transactions; Simplified Bitcoin Blockchain - Simplified Bitcoin blockchain.
A blockchain is a linked list containing data, as well as a hash pointer pointing to the previous block, thus creating a connected chain. What is a hash pointer? It looks like a regular pointer, but instead of simply containing the address of the previous block, it also contains the hash of the data inside the previous block. It is this small setting that makes the blockchain so reliable. Imagine for a second that a hacker attacks block 3 and is trying to change the data. Because of the properties of the hash functions, even a small change in the data will greatly change the hash. This means that any minor changes made in block 3 will change the hash stored in block 2, which in turn will change the data and hash of block 2, and this will lead to changes in block 1 and so on. The chain will be completely changed, and this is impossible. But what does the block header look like?

* Prev_Hash - previous hash; Tx - transaction; Tx_Root - transaction root; Timestamp - time stamp; Nonce is a unique symbol.
The block header consists of the following components:
· Version: block version number
· Time: current timestamp
· Current challenging goal (See below)
· Hash previous block
· Unique symbol (See below)
· Merkle root hash
Right now, let's focus on what the Merkle root hash is. But before that, we need to understand the concept of the Merkle Tree.

Source: Wikipedia
The diagram above shows what a Merkle tree looks like. In the Merkle tree, each non-leaf node is a hash of the values of their child nodes.
Leaf knot: Leaf knots are nodes in the lowest tier of the tree. Therefore, following the above scheme, the nodes L1, L2, L3 and L4 will be considered leaf.
Child nodes: For a node, all nodes that are below its level and that are part of it are its child nodes. In the diagram, nodes with the words “Hash 0-0” and “Hash 0-1” are child nodes of the node with the words “Hash 0”.
Root node: the only node at the highest level, labeled "Top Hash" is the root.
So what does the Merkle Tree have to do with blockchain?
Each block contains a large number of transactions. It will be very inefficient to store all the data inside each block as a series. This will make the search for any particular operation extremely cumbersome and take a long time. But the time required to ascertain whether a particular transaction belongs to this block or not is significantly reduced if you use the Merkle tree.
Let's look at an example in the following Hash tree:

Image courtesy of the project: Coursera
Now suppose I want to know if this data belongs to a block or not:

Instead of going through the complex process of looking through each individual hash process, and also to see if it belongs to the data or not, I just can track the trace of the hash leading to the data:
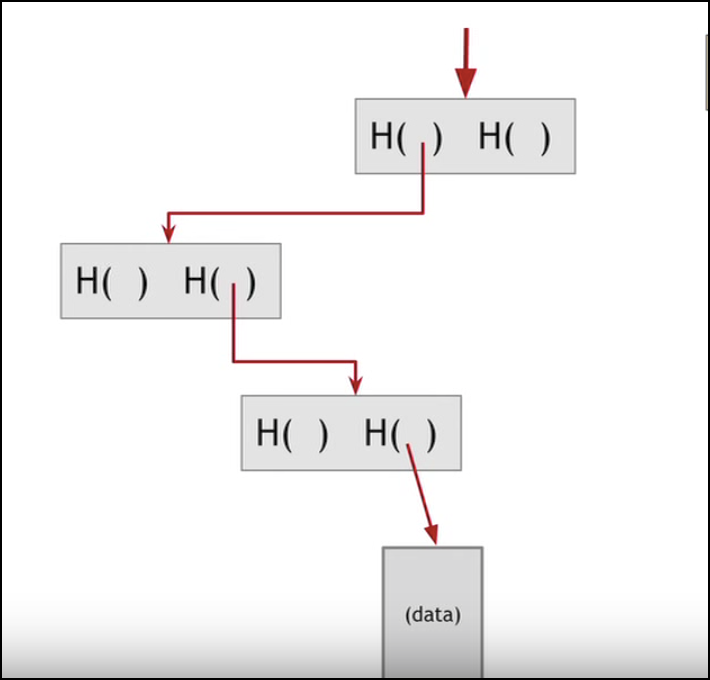
This significantly reduces the time.
Hashing in mining: crypto puzzles.
When we say “mining”, basically, it means finding a new block that will be added to the blockchain. Miners around the world are constantly working to make sure that the chain continues to grow. Previously, people found it easier to work using only their laptops for mining, but over time they began to form "pools", combining the power of computers and miners, which could be a problem. There are restrictions for each cryptocurrency, for example, for Bitcoin, they are 21 million. Between the creation of each block there must be a specific time interval specified by the protocol. For bitcoin, the time between creating a block takes only 10 minutes. If blocks were allowed to be created faster, this would result in:
Thus, to limit the creation of blocks, a certain level of complexity is established. Mining is a bit like a game: you solve a problem and you get a reward. Increasing complexity makes solving a problem much more difficult and, consequently, it takes more time to complete. WRT, which starts with a set of zeros. As the level of difficulty increases, the number of zeros increases. The level of difficulty changes after every 2016 block.
Note: in this section we will talk about the development of bitcoins.
When the Bitcoin protocol wants to add a new block to the chain, mining is the procedure it follows. Whenever a new block appears, all its contents are first hashed. If the selected hash is greater than or equal to the complexity level set by the protocol, it is added to the blockchain, and everyone in the community recognizes the new block.
However, it is not so simple. You must be very lucky to get a new unit in this way. Since, it is here that a unique symbol is assigned. A unique character (nonce) is a one-time code that is combined with a block hash. Then this line is again changed and compared with the level of complexity. If it corresponds to the level of complexity, then the random code changes. This is repeated a million times until the requirements are finally met. When this happens, the block is added to the block chain.
Summing up:
• A hash of the contents of the new block is being executed.
• A nonce (special character) is added to the hash.
• The new line is hashed again.
• The final hash is compared with the level of complexity to check whether it is less or not.
• If not, the nonce changes, and the process repeats again.
• If so, the block is added to the chain, and the publicly accessible book (blockchain) is updated and informs the nodes that a new block has been attached.
• Miners responsible for this process are awarded Bitcoins.
Remember the property number 6 hash functions? Ease of use of the task?
For each output "Y", if k is chosen from a distribution with high min-entropy, it is impossible to find the input x in this way, H (k | x) = Y.
So, when it comes to bitcoin mining:
• K = Unique character
• x = block hash
• Y = problem target
The whole process is completely random, based on the generation of random numbers, following the Proof Of Work protocol and meaning:
What is hash rate?
Hashing speed basically means how quickly these hashing operations occur during mining. A high level of hashing means that more and more people and miners are involved in the mining process, and as a result, the system is functioning normally. If the hash rate is too high, the level of complexity increases proportionally. If the hash speed is too slow, then the complexity level decreases accordingly.
Hashing is indeed fundamental to the creation of blockchain technology. If someone wants to understand what a blockchain is, he should start by understanding what hashing means.
So what is hashing?
In simple words, hashing means entering information of any length and size in the source line and returning the result of a fixed length given by the algorithm of the hashing function. In the context of cryptocurrency, such as Bitcoin, transactions after hashing at the output look like a set of characters defined by the length algorithm (Bitcoin uses SHA-256).
Input- input data, hash- hash
Let's see how the hashing process works. We are going to enter certain data. For this, we will use SHA-256 (a secure hash algorithm from the SHA-2 family, 256 bits in size).
')
As you can see, in the case of SHA-256, no matter how large your input data (input), the output will always have a fixed 256-bit length. This is extremely necessary when you are dealing with a huge amount of data and transactions. Thus, instead of remembering the input data, which can be huge, you can simply remember the hash and track it. Before proceeding, it is necessary to get acquainted with the various properties of the hashing functions and how they are implemented in the blockchain.
Cryptographic Hash Functions
A cryptographic hash function is a special class of hash functions that has various properties necessary for cryptography. There are certain properties that a cryptographic hash function must have in order to be considered secure. Let's deal with them in turn.
Property 1: Deterministic
This means that no matter how many times you analyze a particular input through a hash function, you always get the same result. This is important because if you receive different hashes every time, it will be impossible to track input.
Property 2: Fast Calculation
The hash function must be able to quickly return the hash input. If the process is not fast enough, the system simply will not be effective.
Property 3: The complexity of the inverse calculation
The complexity of the inverse calculation means that given H (A), it is impossible to determine A, where A is the input data and H (A) is the hash. Note the use of the word “impossible” instead of the word “impracticable.” We already know that it is possible to determine the source data by their hash value. Take an example.
Suppose you are playing dice, and the final number is a hash of a number that appears from the dice. How can you determine what the source number is? Simply, all you have to do is find the hashes of all the numbers from 1 to 6 and compare. Since the hash functions are deterministic, the hash of a particular number will always be the same, so you can simply compare the hashes and find out the source number.
But this only works when this amount of data is very small. What happens when you have a huge amount of data? Suppose you are dealing with a 128-bit hash. The only method by which you must find the source data is the “brute force” method. The “brute force” method means that you need to select a random entry, hash it, then compare the result with the test hash and repeat until you find a match.
So what happens if you use this method?
- The best scenario: you get your answer at the first attempt. You really have to be the happiest person in the world for this to happen. The probability of such an event is negligible.
- Worst scenario: you get an answer after 2 ^ 128 - 1 time. This means that you will find your answer at the end of all data calculations (one chance out of 340282366920938463463374607431768211456)
- The average scenario: you will find it somewhere in the middle, so basically after 2 ^ 128/2 = 2 ^ 127 attempts. In other words, this is a huge amount.
Thus, it is possible to break through the function of the inverse calculation using the “brute force” method, but it will take a lot of time and computational resources, so it is useless.
Property 4: Small changes in input change the hash
Even if you make small changes to the source data, the changes that will be reflected in the hash will be huge. Let's check with SHA-256:
Do you see? Even if you just changed the case of the first letter, notice how much this affected the output hash. This is a necessary function, since the hashing property leads to one of the main qualities of the blockchain - its immutability (more on this later).
Property 5: collision stability
Given the two different types of source data A and B, where H (A) and H (B) are their corresponding hashes, for H (A) it cannot be equal to H (B). This means that, for the most part, each entry will have its own unique hash. Why did we say “for the most part”? Let's talk about an interesting concept called “The Paradox of Birthday”.
What is the birthday paradox?
If you accidentally meet a stranger on the street, the chance that your dates of birthdays will match is very small. In fact, if you assume that all days of the year have the same probability of a birthday, the chances of another person sharing your birthday are 1/365 or 0.27%. In other words, it is really low.
However, for example, if you gather 20-30 people in the same room, the chances of two people sharing the same day increase dramatically. In fact, the chance for 2 people is 50-50, sharing the same birthday in this situation.
How does this apply to hashing?
Suppose you have a 128-bit hash that has 2 ^ 128 different probabilities. Using the birthday paradox, you have a 50% chance to break the conflict resistance sqrt (2 ^ 128) = 2 ^ 64.
As you have noticed, it is much easier to break the collision resistance than to find the inverse calculation of the hash. This usually takes a long time. So, if you use a function such as SHA-256, you can safely assume that if H (A) = H (B), then A = B.
Property 6: Puzzle
Properties The puzzle has the strongest effect on cryptocurrency topics (more on this later when we dive into crypto schemes). First, let's define a property, after which we will look at each term in detail.
For each “Y” output, if k is chosen from a distribution with high min-entropy, it is impossible to find input data x such that H (k | x) = Y.
This is probably beyond your comprehension! But it's all right, now let's deal with this definition.
What is the meaning of "high mine entropy"?
This means that the distribution from which the value is chosen is scattered so that we choose a random value that has a negligible probability. In principle, if you are told to choose a number from 1 to 5, this is a low distribution of min-entropy. However, if you chose a number from 1 to infinity, this is a high distribution of min-entropy.
What does "k | x" mean?
"|" Denotes concatenation. Concatenation means the union of two strings. For example. If I combined the "blue" and "sky", then the result would be "blue sky".
So let's go back to the definition.
Suppose you have an output value "Y". If you choose a random “K” value, it is impossible to find the value of X, such that a concatenation hash from K and X will yield Y as a result.
Once again pay attention to the word "impossible", but it is possible, because people do it all the time. In fact, the whole process of mining works on this (more later).
Examples of cryptographic hash functions:
- MD 5: It produces a 128-bit hash. The collision resistance was cracked after ~ 2 ^ 21 hash.
- SHA 1: creates a 160-bit hash. The collision resistance was cracked after ~ 2 ^ 61 hash.
- SHA 256: creates a 256-bit hash. Currently used in Bitcoin.
- Keccak-256: Creates a 256-bit hash and is currently used by Ethereum.
Hashing and data structures.
The data structure is a specialized way to store data. If you want to understand how the blockchain system works, then there are two basic properties of the data structure that can help you with this:
1. Pointers
2. Related listings
Pointers
In programming, pointers are variables that store the address of another variable, regardless of the programming language used.
For example, the record int a = 10 means that there is a certain variable “a”, which stores an integer value equal to 10. This is how a standard variable looks.
However, instead of storing values, pointers store the addresses of other variables. That is why they got their name, because they literally indicate the location of other variables.
Related Lists
The linked list is one of the most important elements in data structures. The structure of the linked list is as follows:
* Head - heading; Data - data; Pointer - pointer; Record - record; Null - zero
This is a sequence of blocks, each of which contains data associated with the next using a pointer. The pointer variable in this case contains the address of the next node, thereby making the connection. As shown in the diagram, the last node is marked with a null pointer, which means that it does not matter.
It is important to note that the pointer inside each block contains the address of the previous one. So the chain is formed. The question arises, what does this mean for the first block in the list and where is its pointer located?
The first block is called the “genesis block”, and its index is in the system itself. It looks like this:
* H () - Hash pointers are rendered this way.
If you are interested in what “hash pointer” means, then we will be happy to explain.
As you already understood, the blockchain structure is based on this. A chain of blocks is a linked list. Consider the structure of the blockchain:
* Hash of previous block header - hash of the previous block header; Merkle Root - Merkle Root; Transactions - transactions; Simplified Bitcoin Blockchain - Simplified Bitcoin blockchain.
A blockchain is a linked list containing data, as well as a hash pointer pointing to the previous block, thus creating a connected chain. What is a hash pointer? It looks like a regular pointer, but instead of simply containing the address of the previous block, it also contains the hash of the data inside the previous block. It is this small setting that makes the blockchain so reliable. Imagine for a second that a hacker attacks block 3 and is trying to change the data. Because of the properties of the hash functions, even a small change in the data will greatly change the hash. This means that any minor changes made in block 3 will change the hash stored in block 2, which in turn will change the data and hash of block 2, and this will lead to changes in block 1 and so on. The chain will be completely changed, and this is impossible. But what does the block header look like?
* Prev_Hash - previous hash; Tx - transaction; Tx_Root - transaction root; Timestamp - time stamp; Nonce is a unique symbol.
The block header consists of the following components:
· Version: block version number
· Time: current timestamp
· Current challenging goal (See below)
· Hash previous block
· Unique symbol (See below)
· Merkle root hash
Right now, let's focus on what the Merkle root hash is. But before that, we need to understand the concept of the Merkle Tree.
What is the Merkle Tree?
Source: Wikipedia
The diagram above shows what a Merkle tree looks like. In the Merkle tree, each non-leaf node is a hash of the values of their child nodes.
Leaf knot: Leaf knots are nodes in the lowest tier of the tree. Therefore, following the above scheme, the nodes L1, L2, L3 and L4 will be considered leaf.
Child nodes: For a node, all nodes that are below its level and that are part of it are its child nodes. In the diagram, nodes with the words “Hash 0-0” and “Hash 0-1” are child nodes of the node with the words “Hash 0”.
Root node: the only node at the highest level, labeled "Top Hash" is the root.
So what does the Merkle Tree have to do with blockchain?
Each block contains a large number of transactions. It will be very inefficient to store all the data inside each block as a series. This will make the search for any particular operation extremely cumbersome and take a long time. But the time required to ascertain whether a particular transaction belongs to this block or not is significantly reduced if you use the Merkle tree.
Let's look at an example in the following Hash tree:
Image courtesy of the project: Coursera
Now suppose I want to know if this data belongs to a block or not:
Instead of going through the complex process of looking through each individual hash process, and also to see if it belongs to the data or not, I just can track the trace of the hash leading to the data:
This significantly reduces the time.
Hashing in mining: crypto puzzles.
When we say “mining”, basically, it means finding a new block that will be added to the blockchain. Miners around the world are constantly working to make sure that the chain continues to grow. Previously, people found it easier to work using only their laptops for mining, but over time they began to form "pools", combining the power of computers and miners, which could be a problem. There are restrictions for each cryptocurrency, for example, for Bitcoin, they are 21 million. Between the creation of each block there must be a specific time interval specified by the protocol. For bitcoin, the time between creating a block takes only 10 minutes. If blocks were allowed to be created faster, this would result in:
- A lot of collisions: more hash functions will be created that will inevitably cause more collisions.
- To a large number of abandoned blocks: If many miners go ahead of the protocol, they will at the same time randomly create new blocks without preserving the integrity of the main chain, which will lead to “orphaned” blocks.
Thus, to limit the creation of blocks, a certain level of complexity is established. Mining is a bit like a game: you solve a problem and you get a reward. Increasing complexity makes solving a problem much more difficult and, consequently, it takes more time to complete. WRT, which starts with a set of zeros. As the level of difficulty increases, the number of zeros increases. The level of difficulty changes after every 2016 block.
Mining process
Note: in this section we will talk about the development of bitcoins.
When the Bitcoin protocol wants to add a new block to the chain, mining is the procedure it follows. Whenever a new block appears, all its contents are first hashed. If the selected hash is greater than or equal to the complexity level set by the protocol, it is added to the blockchain, and everyone in the community recognizes the new block.
However, it is not so simple. You must be very lucky to get a new unit in this way. Since, it is here that a unique symbol is assigned. A unique character (nonce) is a one-time code that is combined with a block hash. Then this line is again changed and compared with the level of complexity. If it corresponds to the level of complexity, then the random code changes. This is repeated a million times until the requirements are finally met. When this happens, the block is added to the block chain.
Summing up:
• A hash of the contents of the new block is being executed.
• A nonce (special character) is added to the hash.
• The new line is hashed again.
• The final hash is compared with the level of complexity to check whether it is less or not.
• If not, the nonce changes, and the process repeats again.
• If so, the block is added to the chain, and the publicly accessible book (blockchain) is updated and informs the nodes that a new block has been attached.
• Miners responsible for this process are awarded Bitcoins.
Remember the property number 6 hash functions? Ease of use of the task?
For each output "Y", if k is chosen from a distribution with high min-entropy, it is impossible to find the input x in this way, H (k | x) = Y.
So, when it comes to bitcoin mining:
• K = Unique character
• x = block hash
• Y = problem target
The whole process is completely random, based on the generation of random numbers, following the Proof Of Work protocol and meaning:
- Problem solving should be difficult.
- However, checking the answer should be easy for everyone. This is done to ensure that unauthorized methods are not used to solve the problem.
What is hash rate?
Hashing speed basically means how quickly these hashing operations occur during mining. A high level of hashing means that more and more people and miners are involved in the mining process, and as a result, the system is functioning normally. If the hash rate is too high, the level of complexity increases proportionally. If the hash speed is too slow, then the complexity level decreases accordingly.
Conclusion
Hashing is indeed fundamental to the creation of blockchain technology. If someone wants to understand what a blockchain is, he should start by understanding what hashing means.
Source: https://habr.com/ru/post/345740/
All Articles