Mobile devices from the inside. The image structure of partitions containing the file system. Part 1
Table of contents
Part 1
1. Introduction.
2. Cutting into pieces (chunks).
3. Compression of images.
3.1.Sparse files.
1. Introduction.
2. Cutting into pieces (chunks).
3. Compression of images.
3.1.Sparse files.
Part 2
3.2._sparsechunk files.
4. Creating dat files.
5. Sources of information.
The image structure of partitions containing the file system.
1. Introduction
Images of sections of mobile devices (MU) containing ext4 file system (FS) are large, for example, the size of the image of the system partition can reach several GB, and the size of the image of the userdata partition is already several dozen GB.
These features require from the developer of firmware the use of "tricks" when performing operations of the initial download of firmware MU or installing updates, because the dimensions of the partition images become not only commensurate with the volume of the RAM of the ME, but also significantly exceed them.
')
The developers of stock (factory) firmware to reduce the size of images of partitions currently use the following methods:
- dividing (cutting) the image into parts (chunks);
- compressing the whole image;
- use dat files.
The first method is based on reducing the size of an image by dividing it into several parts, called chunks , and the size of each piece should not exceed the pre-selected acceptable value. This allows you to reduce the size of the piece of information transmitted to the MU in one session.
In the second method, the property of the FS image is used, which is a sparse file [1]. This allows you to apply coding without data loss, which leads to a reduction in the size of the entire partition image by reducing the amount of “empty” blocks containing either zero or duplicate data.
The peculiarity of the third method is that after encoding all “empty” blocks are deleted from the image (when installing the firmware) or only changes of images are transferred (when updating is performed).
I think that, as an upgrade, the developers of custom firmware will be interested in becoming familiar with the internal structure of images of this type and clarifying some aspects of working with them ...
2. Cutting into pieces (chunks)
This method implies that the source image, which has ext4-format, is divided into parts no larger than a predetermined value, called the boundary . Most often, the border is set to 128 or 256 MB. At the same time, for the reverse recovery, an additional so-called allocation file is created, describing the location of these parts in the original image.
The process of cutting an image of a section into parts can be described by the following algorithm:
- the boundary value is selected, which must satisfy the following criteria:
- multiple of FS block size;
- Do not exceed the allowable size of files for transfer during OTA-update or boot in fastboot mode;
- the image of the section is viewed in the RAW format and is divided into parts with a size not exceeding the border ;
- from each part an output piece (chunk) is formed according to special rules:
- if the piece in question contains non-zero data, they are completely copied to the output piece (type 1 chunk);
- if the piece in question contains only zero data, then the output piece will have a size of one block, consisting of zeros (type 2 chunk);
- if the piece in question contains some information and a lot of null data, then the output piece will contain only the information part (type 3 chunk);
- the size of a piece of any type is always a multiple of the size of the block.
- the entire cutting process is recorded in the location file. The name of the piece, the offset in the firmware, and the size of the original input piece corresponding to the created piece are saved in the form of attributes.
After such a partitioning of the partition image and due to the truncation of the zero data, there is a significant decrease in the sum of the lengths of the pieces, i.e. total output file size.
The recovery process is very simple and is performed according to the following algorithm:
- creates a new blank image that has the size of the original;
- then chunks are sequentially read and arranged in it according to the information from the allocation file.
For example, let's consider the process of restoring the original partition image using the firmware for the Lenovo s90 MU based on the Qualcomm MSM8916 processor [2], which contains the rawprogram0.xml placement file. And for the "border" part of Qualcomm accepted the value of 128 MB.
The placement file rawprogram0.xml is an xml file, a quote from which is shown below:
<?xml version="1.0" ?> <data> <!--NOTE: This is an ** Autogenerated file **--> <!--NOTE: Sector size is 512bytes--> ... <program ... filename="cache_1.img" label="cache" ... start_sector="6193152" /> <program ... filename="cache_2.img" label="cache" ... start_sector="6455296" /> <program ... filename="cache_3.img" label="cache" ... start_sector="6455496" /> <program ... filename="cache_4.img" label="cache" ... start_sector="6717440" /> ... </data> Strictly speaking, this is a MU memory markup description file based on Qualcomm chips. I will not describe all the parameters of this file, because we only need the following:
- filename - the name of the file;
- label - section label;
- start_sector - file offset in memory, expressed in 512 byte sectors.
The filename parameter indicates the name of the file containing the image or its part, the label of which is represented by the label parameter.
The start_sector parameter contains the ABSOLUTE offset of the beginning of the file in the MU memory.
Since Since we are not going to flash part files into memory, we’ll only collect a whole file-image of a partition from them, then we need to use relative offset to place each part in this image file. The basis is the beginning of the image of a specific section, i.e. image offset in the memory MU. The calculation is made according to the following formula:
Relative displacement = abs. Offset of part_part - abs. Offset_start_of_part
There are several files in the firmware body containing ext4 filesystems:
- cache.img , consisting of 4 parts (cache_1.img - cache_4.img);
- preload.img , consisting of 6 parts (preload_1.img - preload_6.img);
- system.img , consisting of 29 parts (system_1.img - system_29.img).
Let's try to build an image of the cache partition, i.e. from parts cache_1.img - cache_4.img we will collect one file cache.img. Specifically, for it, we will select the following values from the rawprogram0.xml above file:
- the absolute offset of the beginning of the cache section is 6193152;
- the beginning of the first part of the cache image has an absolute offset of 6193152, respectively, the relative offset is zero;
- the beginning of the second part 6455296, respectively, the relative offset 262144.
- the beginning of the third part 6455496, respectively, the relative offset 262344;
- the beginning of the fourth part of 6717440, respectively, the relative offset 524288;
To recover, do the following:
- open the first part with any hex editor, i.e. cache_1.img file and read the value of the uint32 type at the address 0x0404, which is the size of the FS image of the type ext4 of the cache section, expressed in blocks. In Figure 1 it is marked in red:

fig.1. Cache partition image size - create a new empty file containing filesystems of type ext4, size 0x010600 blocks, i.e. 0x010600 * 0x1000 = 0x010600000 (274,726,912 bytes or 262MB), calling it cache.img;
- copy the entire contents of the first part and paste it into a new file, starting with the relative offset calculated above, i.e. 0x0000;
- open the file containing the next part of the file is cache_2.img.
- copy the entire contents of this part and paste it into the created file, starting also with the relative offset of the second part (262144), calculated above;
- repeat the previous two steps for all other parts of the cache.img file, taking into account their order.
After completing all the steps, you will receive a file, cache.img , 262MB in size, containing an image of a cache partition in the form of an ext4 file system.
3. Image compression
Cutting into parts partially solves the problems of the developers, reducing the size of one part transmitted during the transfer session during the firmware update. However, the total file size does not change.
The problem of reducing the size of the image can be solved by its compression (coding). To do this, use the following methods:
- converting a raw format file to a sparse file;
- Converting a raw format file to _sparsechunk files.
Sparse files are actively used, for example, in a Lenovo Moto G device, and _sparsechunk files are used in Moto Z.
3.1.Sparse files
To remove “empty” values, the number of which in partition images can reach 90%, the images themselves convert (compress) into Sparse files, the structure of which is described in [3]. In this case, the source file is considered as an array of elements representing four-byte numbers, and the array is scanned block by block, i.e. 4096 bytes each or 1024 elements each.
Depending on the content, the blocks are divided into the following types:
- blocks with repeating elements, i.e. containing zeros or the same (duplicate) elements, i.e. Fill blocks;
- blocks with information elements, i.e. containing different data within the whole block, i.e. Raw blocks.
3.1.1.The structure of sparse files
The sparse image of the partition with the FS after converting it into a sparse file is a sequence (list) of Raw and Fill pieces, interleaved. To identify and provide a reverse transformation (image restoration), all this is supplemented with a header.
So, the Sparse file consists of:
- file header;
- data areas, i.e. list of pieces.
Despite the fact that when converting the image of the Raw format in sparse , only two types of pieces are used, there are 4 types of pieces of sparse files, which will be discussed below.
Sparse file header
The header has the following structure:
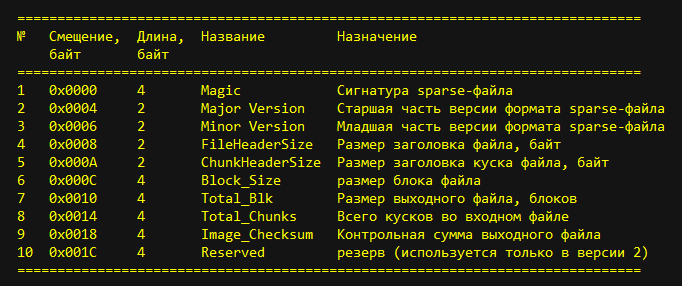
fig.2. Sparse file header
Briefly consider all the header fields.
The Magic field is 4 bytes long and contains a signature (the number 0xed26ff3a) and is used to identify the sparse file as a file type.
The Major Version and Minor Version fields are 2 bytes long and contain the version number of the sparse file format. Now it is version 1.0.
The FileHeaderSize field is 2 bytes long and contains the size of the sparse file header in bytes. Currently, there are two versions of the header, differing only in its size: 0x1C (28) bytes and 0x20 (32) bytes. Accordingly, this field contains the number or 0x1C, or 0x20.
The ChunkHeaderSize field is 2 bytes long and contains the size of the header of the sparse file. Regardless of the type of pieces, it contains the number 0x0C (12).
The Block_Size field is 4 bytes long and contains the block size of the sparse file. For compression into a sparse FS image file of type ext2-ext4, the value of this field is 0x1000 (4096).
The Total_Blk field is 4 bytes long and contains the size of the source file (img) in blocks.
The Total_Chunks field is 4 bytes long and contains the number of parts into which the source (input) file was divided. The same number of pieces is contained in the output file ( sparse ).
The Image_Checksum field contains the checksum of the output file data (sparse) calculated by the Crc32 algorithm for the entire file (header + data).
The structure of the data area of the sparse file pieces
Following the header is the data area, consisting of a list of pieces of a sparse file.
Each piece has a piece header and piece data.
The header has a length of 0x0C (12) bytes, as indicated in the ChunkHeaderSize field of the sparse file header and contains the following fields:

Fig.3. Piece Header Structure
The Chunk_Type field is 2 bytes long and contains a chunk identifier and can have the following values:
- 0xCAC1 is a piece of Raw type intended for storing non-repeating data. The size of the piece is equal to the amount of data in bytes + the size of the piece header;
- 0xCAC2 - a piece of type Fill describes the repeating part of the input data, contains zero or duplicate data in coded form. The size of the piece is equal to the size of the header + 4 bytes per placeholder element;
- 0xCAC3 - a piece of type DontCare contains no data at all. The size of the piece is equal to the size of the piece header, i.e. 12 bytes;
- 0xCAC4 - a piece of type Crc contains the checksum of the file, calculated by the algorithm Crc32. The chunk size is equal to the header size + 4 bytes per checksum value.
The Reserved field is 2 bytes long, is not used and is always zero.
The Chunk_Size field is 4 bytes long and contains the size of the original piece in the input file (img), expressed in blocks.
The Total_Size field is 4 bytes long and contains the size of the resulting piece in the output sparse file, expressed in bytes. The calculation takes into account both the length of the header and the length of the piece data.
Following the header are data that differs depending on the type of piece.
Since a piece of type Raw is intended to store non-repeating data, then the data of the piece completely coincides with the data of the corresponding part of the input file. It has the largest size, because the amount of data can reach the value of the selected boundary .
A piece of the Fill type contains only one four-byte number (4-byte placeholder) as data, repeated in the corresponding part of the input file. It replaces the entire area occupied by these repetitive data without enumerating them, which leads to their compression.
A piece of type Crc as data contains a checksum of a piece, calculated using the Crc32 algorithm for all the piece data .
The exception is a piece of the DontCare type, which contains no data at all, but the Chunk_Size field is still filled. It represents a pointer (offset) at the beginning of the next piece of data in the input file.
3.1.2. Algorithms for working with sparse files
When working with sparse files, the operations are performed to encode the raw ( Raw ) img file into a sparse file and decode the sparse file into the original file.
The coding of the input Raw image of the sparse section of the format is performed according to the following algorithm:
- Block by block the input image of the section is viewed and the type of each block is determined.
- Contracting blocks of the same type are combined into groups. The current group ends when a block type changes, and a new one begins.
Contracting Fill blocks are combined into Fill groups. This takes into account the repeated value, which must be the same within the same group. If the next going Fill block has another repeated value, a new Fill group is created.
Raw raw blocks are combined into Raw groups. - All resulting groups are converted into chunks of the sparse format file. At the same time, the Raw group containing non-repeating data is completely, unchanged, copied into the data area of the Raw . And the entire Fill group is replaced with one piece of the Fill type, containing one repeating element in the data area of this piece.
- The sparse file header is filled.
Decoding of the sparse file into the original image is performed according to the following algorithm:
- A new empty file is created, the size of which in blocks is taken from the Total_Blk field of the sparse file header.
- Each piece of the list from the data field of the sparse file is sequentially decoded, filling the output file sequentially, starting at address 0x0000. At the same time for the piece read the title, and then:
- These pieces of type Raw are completely copied from the input file to the output.
In this case, the read pointer for the input file and the write pointer for the output file are moved by the number of bytes to be copied. - For a piece of type Fill in the output file, the filler element is copied Total_Size , divided by 4, times.
In this case, the read pointer of the input file is moved to 4 bytes of a placeholder. The record pointer of the output file is moved by the number of bytes occupied by the placeholders. - For pieces of type DontCare, the input file read pointer does not move, and in the output file the write pointer is moved to the number of byte blocks specified in the chunk_Size field of the piece.
- These pieces of type Raw are completely copied from the input file to the output.
3.1.3. Examples of working with sparse files
When working with sparse files, two questions most often arise:
- How to restore the original image from a sparse file?
- How to convert source image to sparse file?
Consider them according to the receipt ...
How to restore the original image from a sparse file?
For example, consider the process of restoring an image of an oem partition from a sparse file of MU Moto Z from Lenovo [4]. All actions are performed using a hex editor, for example, WinHex.
The original oem.img file containing the compressed image of the oem partition has a size of 69MB. Let's see his title:

Fig.4. Heading moto z
From the address 0x0000 there is a file signature indicating that the file is of type sparse file and consists of pieces. The signature is marked in blue.
Then the fields with the version of the sparse file (1.0) are highlighted in green.
Then the fields FileHeaderSize and ChunkHeaderSize are highlighted in red, containing the size of the file header (0x001C) and the size of the piece header (0x000C), respectively.
At offset 0x000C there is a Block_Size field indicating the block size of the sparse file. The size of the block is 0x00001000.
At offset 0x0010 is the Total_Blk field, which contains the size of the source file in blocks. It is highlighted in yellow and has the value 0x0000C021.
At offset 0x0014 is the Total_Chunks field, which contains the number of pieces contained in the sparse file. It is highlighted in purple and has the value 0x0000001F.
At offset 0x0018, the Image_Checksum field is located , containing the checksum of the sparse file. This field contains 0, which means that the CS was not calculated and is not taken into account when loading this file into the memory of the ME.
Starting at address 0x001C, the header of the first piece of the sparse file is located:

fig.5. CAC1 piece header
You can see that the Chunk_Type field contains the value 0xCAC1, highlighted in blue. The next 2 bytes are empty, and then the Chunk_Size field is marked in red, containing the number of blocks of the input file (0x00000001) encoded in the piece.
Next is the Total_Size field, which contains the length of the piece along with the header, expressed in bytes (0x0000100C). It is highlighted in green. We always need the size without a header, so the length of the data only: 0x100C - 0x000C = 0x1000.
Immediately after the heading, starting at address 0x0028, there is an array of chunk data.
So, to restore the original image, perform the following steps:
- open the original sparse oem.img file in a hex editor;
- choose field values from the file header, create a new empty size file
and save under the name, for example, oem_ext4.img;Total_Blk * Block_Size = 0x000C021 * 0x1000 = 00C021000 (192) - go to the processing of the first piece;
- its type is CAC1, so we copy the data array (starting at offset 0x0028, 0x1000 in size) and paste it into the created output file;
- move on to the next piece. Its type is CAC2, respectively, the placeholder is 0xFFFFFFFF, and the number of placeholders is 0x1D blocks:

Fig.6. The second piece of CAC2
Insert the number of placeholders in the created file0x001D * 0x1000 = 0x01D000 118784 - Etc. We will perform the described steps to decode the pieces to the end of the source file.
The result will be a file containing filesystems of type ext4, 192MB in size.
How to convert source image to sparse file?
For simplicity, take the oem_ext4.img image you just received and try to turn it into a sparse file. In this case, you need to create a new file of size 0x001C (28) bytes, place the header of the sparse file into it and then sequentially review the source file, dividing it into pieces and encoding them, place all the created sparse files in the new file. And, of course, save the new file under the name, for example, oem_sparse.img .
To fill in the file header, enter the signature of the sparse file in the first 4 bytes:

fig.7. Sparse file header
Next, write the values in succession:
- version numbers of the sparse file (takes 4 bytes):

Fig.8 Version number of the sparse file - sparse file header size (2 bytes):

Fig.9 Sparse file header size - size of chunk header (2 bytes):

fig.10 Size of the piece header - block size in bytes (4 bytes):

fig.11 block size
The remaining fields are left free, because their values will appear with us only after the final creation of the output file.
Let's now look at how to encode, i.e. create, different types of pieces.
Any type of piece has a header. Therefore, we create it first: create a 12-byte file in a hex editor:

fig.12 Empty piece header
Next, consider how and what to fill in the pieces.
Raw type slice
In the first 2 bytes of the header, we write its type (CAC1):

fig.13 Type of piece CAC1
Then in the field we insert the size of the data (0x00000001), expressed in blocks:

fig.14 Size in blocks
And finally, the size of the piece in bytes (0x0000100C), i.e. header length + data length:

fig.15 CAC1 piece size
After the header we insert the data, i.e. 0x1000 (4096) bytes from the source file:

Fig.16 Data piece SAS1
Let's proceed to the creation of the next piece.
Fill Piece
In the first 2 bytes of the header, write its type (CAC2):

Figure 17. Type of piece CAC2
Insert the data size of the piece (0x001D), expressed in blocks:

Fig.18 Size in CAC2 blocks
Insert the size of the piece in bytes (0x0010), i.e. header length + data length:

Fig.19 Size of piece SAS2
Add the piece data. For CAC2, this is a placeholder element (0xFFFFFFFF):

fig.20 Data piece SAS2
Let's proceed to the creation of the next piece.
DontCare Piece
In the first 2 bytes of the header, write its type (CAC3):

fig.21 Type of piece CAC3
Insert the offset value to the next piece (0xxxxxx), expressed in blocks, at the address 0x0004 header.
Insert the size of the piece in bytes (0x000C), i.e. just the length of the title, because A piece of this data type does not have at the address 0x0008 header:

fig.22 Size of piece SAS3
Let's proceed to the creation of the next piece.
Crc Piece
In the first 2 bytes of the header, write its type (CAC4):

Figure 23 Piece Type CAC4
Insert the data size of the piece (0x001D), expressed in blocks:

Fig.24 Size in CAC4 blocks
Insert the size of the piece in bytes (0x0010), i.e. header length + data length:

fig.25 CAC4 piece size
Add the piece data. For CAC4, this is a check sum of a piece calculated using the CRC32 algorithm:

fig.26 Data piece CAC4
Actually, we have already sorted out everything by bone: we create a sparse header — a slice; and immediately after him add the data he needs.
Now the process of encoding the source file in a sparse file is as follows:
- create an output file of 0x001C bytes in the hex editor, and fill in the header fields of the sparse file in it as described above;
- open the source file in a hex editor;
- scan 4096 bytes (one block) and determine the type of the piece.
- create a piece of type CAC1 in the output file;
- we scan the following 4096 bytes (one block) and determine the type of the piece.
- create a piece of type CAC2 in the output file;
- perform block-by-block viewing of the source file to the end. All blocks are encoded into pieces and put them in the output file.
- view the output file and merge pieces of one type, arranged in series, into one group, and pieces of another type into another group. In the group there is one header from the first piece, in which the values of two fields are corrected:
- Chunk_Size is the total size of the group of source pieces of the input file (img), expressed in blocks;
- Total_Size - the size of the resulting group in the output sparse file, expressed in bytes.
- we add the size of the source file in blocks in the Total_Blk header field, and the number of pieces in the Total_Chunks file header field;
To be continued...
3.2._sparsechunk files
4. Creating dat files
5. Sources of information
1. "Sparse_file" .
2. "s90-a_row_s125_141114_pc_qpst - firmware" .
3. system / core / libsparse / sparse_format.h
4. "Firmware device Lenovo Moto Z" .
5. Victara_Retail_China_XT1085_5.1_LPE23.32-53_CFC.xml.zip - firmware of the Lenovo Moto X device.
Source: https://habr.com/ru/post/345726/
All Articles