Search under the hood Chapter 1. Network spider
The ability to search for information on the Internet is vital. When we click on the “search” button in our favorite search engine, we receive an answer in a split second.
Most do not think at all about what is happening “under the hood”, and meanwhile the search engine is not only a useful tool, but also a complex technological product. Modern search engine for its work uses almost all the advanced achievements of the computer industry: big data, graph and network theory, analysis of natural language texts, machine learning, personalization and ranking. Understanding how the search engine works gives an idea of the level of technology development, and therefore any engineer will be able to understand this.

In several articles, I will talk step by step about how the search engine works, and, in addition, for the purposes of illustration, I will build my own small search engine so as not to be unfounded. This search engine will, of course, be “educational”, with a very strong simplification of what is happening inside Google or Yandex, but, on the other hand, I will not simplify it too much.
The first step is to collect data (or, as it is also called, crawling).
Web is a graph
That part of the Internet that we are interested in consists of web pages. In order for the search engine to be able to find a particular web page at the user's request, it must know in advance that such a page exists and contains information relevant to the request. The user usually finds out about the existence of a web page from a search engine. How does the search engine itself know about the existence of a web page? After all, no one is obliged to tell her explicitly about this.
Fortunately, web pages do not exist by themselves, they contain links to each other. The search robot can follow these links and discover all new web pages.
In fact, the structure of the pages and the links between them describes the data structure called "graph". A graph, by definition, consists of vertices (web pages in our case) and edges (links between vertices, in our case, hyperlinks).
Other examples of graphs are social network (people - peaks, edges - friendship), a road map (cities - peaks, edges - roads between cities) and even all possible combinations in chess (a chess combination - top, edge between peaks exists, if one position to another can move in one move).
Graphs are oriented and unoriented - depending on whether the direction is indicated on the edges. The Internet is a directed graph, since it is possible to go only in one direction by hyperlinks.
For further description, we will assume that the Internet is a strongly connected graph, that is, starting at any point on the Internet, you can get to any other point. This assumption is obviously wrong (I can easily create a new web page that will not be available from anywhere and therefore cannot be reached), but for the task of designing a search engine it can be accepted: as a rule, web pages that are not links are not of great interest to search.
A small part of the web graph:

Graph traversal algorithms: search in width and depth
Depth search
There are two classic graph traversal algorithms. The first one, simple and powerful, is called Depth-first Search (DFS). It is based on recursion, and it represents the following sequence of actions:
- Mark the current vertex processed.
- We process the current vertex (in the case of a search robot, processing will simply save a copy).
- For all vertices to which you can go from the current one: if the vertex has not yet been processed, we recursively process it too.
Python code that implements this approach literally:
seen_links = set() def dfs(url): seen_links.add(url) print('processing url ' + url) html = get(url) save_html(url, html) for link in get_filtered_links(url, html): if link not in seen_links: dfs(link) dfs(START_URL) For example, the standard Linux utility wget works in the same way with the -r parameter, which indicates that the site needs to be pumped out recursively:
wget -r habrahabr.ru It is advisable to use the depth-first search method to bypass web pages on a small site, however, it is not very convenient to crawl the entire Internet:
- The recursive call it contains does not parallel well.
- With this implementation, the algorithm will get deeper and deeper through the links, and in the end it will most likely not have enough space in the recursive call stack and we will get the error stack overflow.
In general, both of these problems can be solved, but we will use another classical algorithm instead - a search in width.
Search wide
A wide search (breadth-first search, BFS) works in a manner similar to depth-first search, but it goes around the top of the graph in order of distance from the start page. For this, the algorithm uses the “queue” data structure — you can add elements to the end of the queue and pick it up from the beginning.
- The algorithm can be described as follows:
- We add to the queue the first vertex and to the set of "seen".
- If the queue is not empty, retrieve the next vertex from the queue for processing.
- We process top.
- For all edges emanating from the vertex being processed that are not included in the "seen":
- Add to "seen";
- Add to queue.
- Go to step 2.
Python code:
def bfs(start_url): queue = Queue() queue.put(start_url) seen_links = {start_url} while not (queue.empty()): url = queue.get() print('processing url ' + url) html = get(url) save_html(url, html) for link in get_filtered_links(url, html): if link not in seen_links: queue.put(link) seen_links.add(link) bfs(START_URL) 
It is clear that in the queue there will first be vertices located at a distance of one link from the initial one, then two links, then three links, etc., that is, the search algorithm will always reach the vertex by the shortest path.
Another important point: the queue and the set of “seen” vertices in this case use only simple interfaces (add, take, check for entries) and can easily be transferred to a separate server that communicates with the client through these interfaces. This feature allows us to implement a multi-threaded graph traversal - we can run several simultaneous handlers using the same queue.
Robots.txt
Before describing the actual implementation, I would like to note that a well-behaved crawler takes into account the restrictions imposed by the owner of the website in the robots.txt file. Here, for example, the contents of robots.txt for the site lenta.ru:
User-agent: YandexBot Allow: /rss/yandexfull/turbo User-agent: Yandex Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Host: https://lenta.ru User-agent: GoogleBot Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my User-agent: * Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Sitemap: https://lenta.ru/sitemap.xml.gz It can be seen that there are certain sections of the site that are forbidden to visit the robots of Yandex, Google and everyone else. In order to take into account the contents of robots.txt in python, you can use the filter implementation included in the standard library:
In [1]: from urllib.robotparser import RobotFileParser ...: rp = RobotFileParser() ...: rp.set_url('https://lenta.ru/robots.txt') ...: rp.read() ...: In [3]: rp.can_fetch('*', 'https://lenta.ru/news/2017/12/17/vivalarevolucion/') Out[3]: True In [4]: rp.can_fetch('*', 'https://lenta.ru/search?query=big%20data#size=10|sort=2|domain=1 ...: |modified,format=yyyy-MM-dd') Out[4]: False Implementation
So, we want to bypass the Internet and save it for further processing.
Of course, for demonstration purposes, it will not be possible to bypass and save the entire Internet - it would be VERY expensive, but we will develop the code with an eye to the fact that it could potentially be scaled to the size of the entire Internet.
This means that we must work on a large number of servers at the same time and save the result to some kind of storage from which it can be easily processed.
I chose Amazon Web Services as the basis for my solution, because there you can easily pick up a certain number of machines, process the result and save it to the distributed storage of Amazon S3 . Similar solutions have, for example, google , microsoft and Yandex .
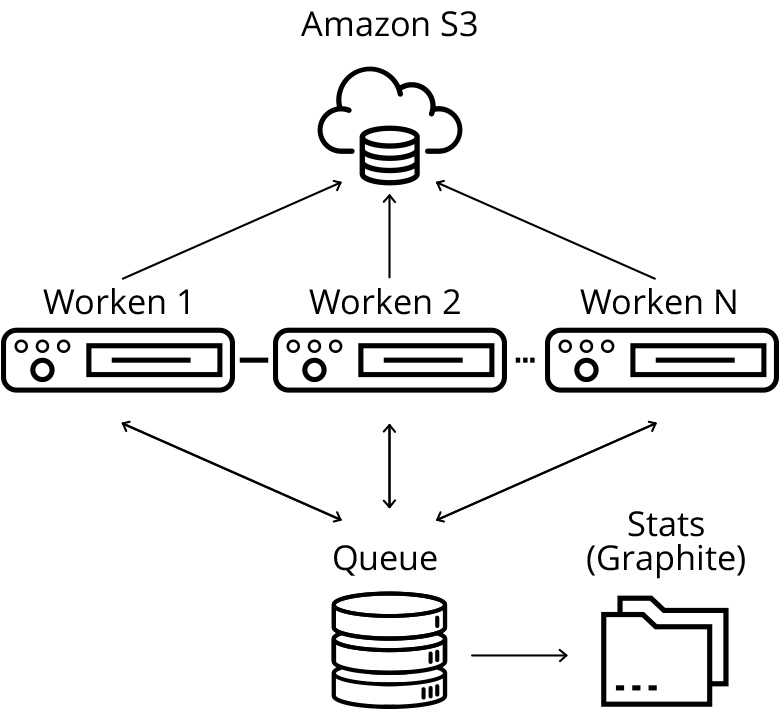
Architecture of the developed solution
The central element in my data collection scheme is the queue server, which holds the queue URLs to be downloaded and processed, as well as many URLs that our handlers have already “seen”. In my implementation, they are based on the simplest data structures Queue and set of the python language.
In a real production system, most likely, instead of them, it would be worthwhile to use some existing solution for queues (for example, kafka ) and for distributed storage of sets (for example, solutions of the in-memory key-value class of aerospike databases would be appropriate ). This would allow to achieve full horizontal scalability, but in general the load on the queue server is not very large, so there is no sense in such a scale in my small demo project.
Working servers periodically pick up a new group of URLs for downloading (we take away immediately a lot so as not to create an extra load on the queue), download the web page, save it on s3 and add new found URLs to the download queue.
In order to reduce the load on adding URLs, adding is also done in groups (I immediately add all new URLs found on the web page). I also periodically synchronize many “seen” URLs with working servers in order to pre-filter already added pages on the side of the working node.
I save downloaded web pages to a distributed cloud storage (S3) - it will be convenient later for distributed processing.
The queue periodically sends statistics on the number of added and processed requests to the statistics server. Statistics are sent in total and separately for each work node - this is necessary in order to make it clear that the download is in normal mode. It is impossible to read the logs of each individual machine, so we will monitor the behavior on the charts. As a solution for monitoring downloads, I chose graphite .
Crawler launch
As I already wrote, in order to download the entire Internet, you need a huge amount of resources, so I limited myself to only a small part of it - namely, the sites habrahabr.ru and geektimes.ru. However, the restriction is rather conditional, and its extension to other sites is simply a matter of the amount of available iron. To launch, I implemented simple scripts that raise a new cluster in the amazon cloud, copy the source code there and start the corresponding service:
#deploy_queue.py from deploy import * def main(): master_node = run_master_node() deploy_code(master_node) configure_python(master_node) setup_graphite(master_node) start_urlqueue(master_node) if __name__ == main(): main() #deploy_workers.py #run as: http://<queue_ip>:88889 from deploy import * def main(): master_node = run_master_node() deploy_code(master_node) configure_python(master_node) setup_graphite(master_node) start_urlqueue(master_node) if __name__ == main(): main() The code of the deploy.py script containing all called functions
Using graphite statistics as a tool allows you to draw beautiful graphs:
Red graph - found URLs, green - downloaded, blue - URL in the queue. All time downloaded 5.5 million pages.
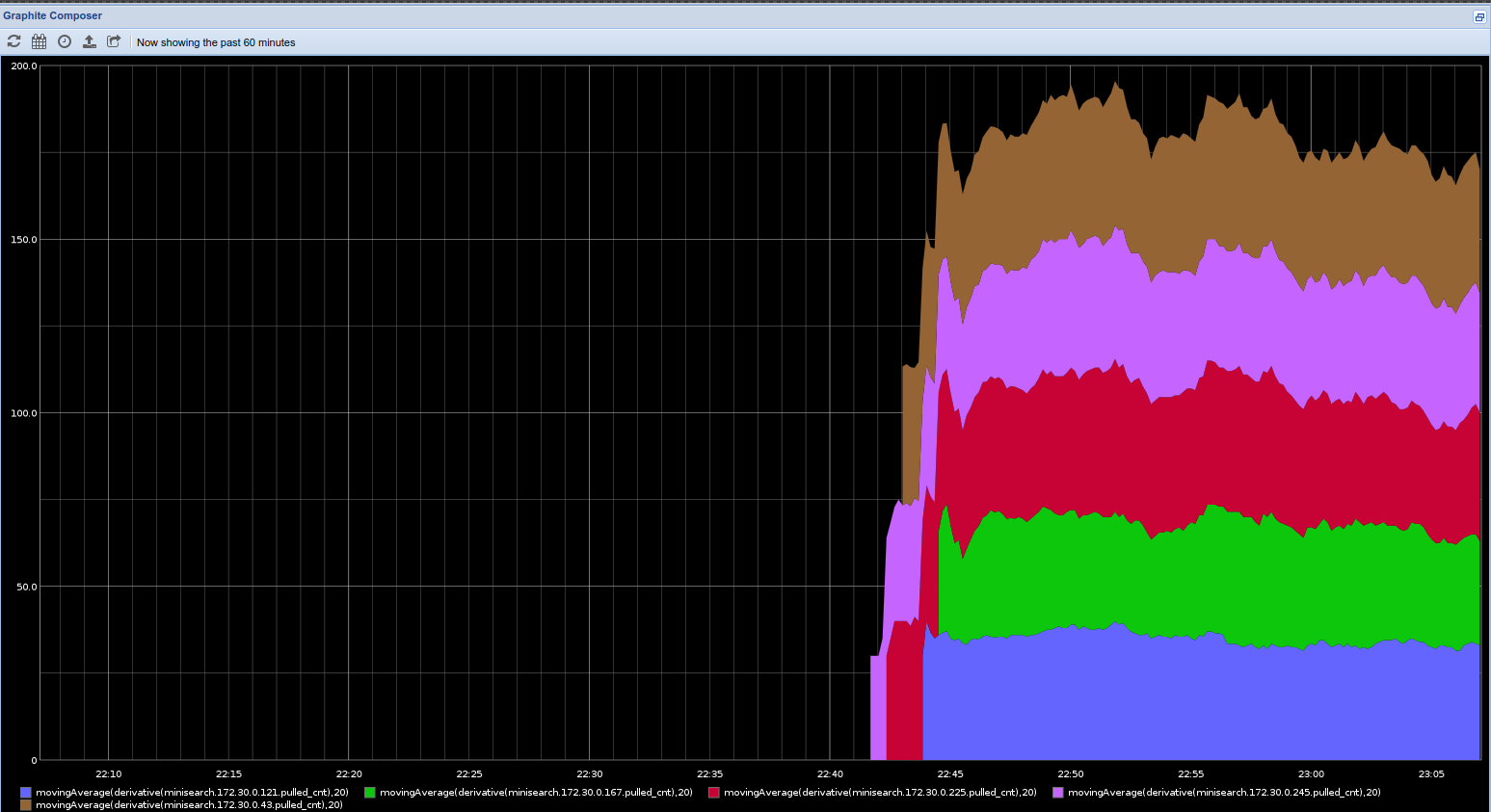
The number of pages scored per minute, broken down by working nodes. Charts are not interrupted, cracking is in normal mode.
results
Downloading habrahabr and geektimes took me three days.
It would be possible to download much faster, increasing the number of copies of workers on each working machine, as well as increasing the number of workers, but then the load on the Habr itself would be very large - why create problems for your favorite site?
In the process, I added a couple of filters to the crawler, starting to filter some obviously garbage pages that are irrelevant to the development of the search engine.
The developed crawler, although it is a demonstration, is generally scalable and can be used to collect large amounts of data from a large number of sites at the same time (although it is possible that production should focus on existing crawling solutions, such as heritrix . Real production crawler also should be run periodically, not once, and implement a lot of additional functionality, which I have so far neglected.
During the crawler, I spent about $ 60 on the amazon cloud. Total downloaded 5.5 million pages, a total of 668 gigabytes.
In the next article of the cycle, I will build an index on the downloaded web pages using big data technology and design the simplest search engine for the downloaded pages.
Project code is available on github
')
Source: https://habr.com/ru/post/345672/
All Articles