Happy semi-final stories about the automation of test schemes

You can recall the beginning of the story in the first article , but let me briefly remind you what is happening.
It all started with the transfer of monolithic applications to microservices, when the streamlined process of rolling new releases on the test environment began to fail due to the sharply increased “detail”. So that the developers did not quarrel over common test benches and everything worked quickly and smoothly, we launched an automation project.
Due to managerial difficulties, the project did not show results immediately, therefore I offer you the continuation of the story.
What are the bad schemes with manual control?
Until recently, the company had several old monolithic test environments, each of which contains frontend / backend / billing components, and they are needed for application development and integration tests. A test bench is a group of hosts with a specific set of applications. Inside we call them test circuits. There were a few general test patterns: integration, load, etc., which did not correspond to their production architecture.
That is, each application was not always in its own container; it was impossible to test the nginx configuration on the test circuit.
It was necessary to install and configure a future release for tests, and after that, in a separate table, specify which hosts and what are you using, so that there are no conflicts. In all of this was the following number of problems:
- The file with busy hosts was conducted manually and was largely dependent on the human factor.
- On the same test circuit, the same application was often tested, but with different functions. And each of them imposed its own restrictions on the configuration and dependent applications. Of course, the configuration and deployment of such configurations was done manually and also depended on the human factor - the point automation was, but was rather a personal initiative of certain people.
- The configuration of the test environment and the permissible interactions of the components in it did not correspond to production. That is, it was impossible to fully verify the performance of the new application build in real conditions.
- The biggest problem was the transfer of settings from the old scheme to the new one. Each application has its own settings and bindings to the database, so with manual transfer something could be lost.
About a year ago, the company began a rapid growth of teams, and the number of test circuits did not change - only the amount of resources required to support them increased. That is, the volume of manual operations and related problems grew exponentially and at some point began to seriously slow down the testing process, and therefore development.
Automation pitfalls
First of all, it was decided to eliminate conflicts of application versions within one scheme, and also to guarantee the correct delivery of callbacks, so that the response of one component came to a specific server, and not to the one that was previously chosen by another developer. The best solution would be to provide each developer with their own isolated environment.
The operation supports only one reference scheme, repeating production as much as possible. As for the other problems to be solved, the following list of requirements for new test circuits appeared for them:
- the scheme contains a set of pre-configured applications, some of which are customized by the developer or excluded from the scheme;
- synchronization of versions of applications with the "combat";
- the ability to update or prohibit the update application on the scheme. This is for situations where application versions other than “combat” are required in the test environment;
- data synchronization of some databases with the "combat";
- cloning a database with data in the process of creating a scheme;
- collection of logs, metrics from each scheme. In addition, you need to ensure the delivery of service e-mail, SMS and Push-notifications to mobile in each scheme;
- the ability to gain access to certain schemes from external partners for mutual debugging;
- within the schema, components on Windows / IIS / Microsoft SQL (BI) should be supported. Here it is necessary to clarify that for various reasons (including historical), we have analytical tools on the .Net stack, and the rest is in Java.
When choosing a solution, the main limitation was the lack of automatic deployment of applications - the package with the application was simply transferred via a network folder to the test environment. That is, before the test schemes, it was necessary to build an automatic deployment system or accept the fact that the first time when creating new schemes, applications are cloned from the reference scheme (mainly Windows components).
Alternatively, the deployment of the production version of the application by operating scripts. The main disadvantage of this solution is that in order to get new versions of the components in the scheme, it needs to be recreated or to think over the update mechanism and constant support of such scripts in isolation from the applications.
By the way, about a long way to automate assemblies and deployments, we have a separate article , but there it’s mostly about assembly.
You can minimize the change in settings when creating a scheme in the case of invariance of host names to which calls are made. Thus, if the reference scheme is configured to interact, for example, by short names, then when it is cloned into a new scheme, the settings need not be changed. You only need to raise a separate DNS server for the new scheme.
Thus, if we omit a long and painful choice, the fastest solution for us was a bunch of Openstack with private networks for each scheme and Ansible as a deployment tool.
Final solution
The final solution is based on Openstack + CEPH , in which each application has its own VM. For each test circuit, a separate project is created in Openstack and its own private network is allocated, to which machines with applications related to the circuit are connected. And above all this is a set of Jenkins builds, which performs all service operations via Pipeline and Ansible: creating and deleting diagrams, subcircuits, deployments of applications, periodic tasks for database synchronization.
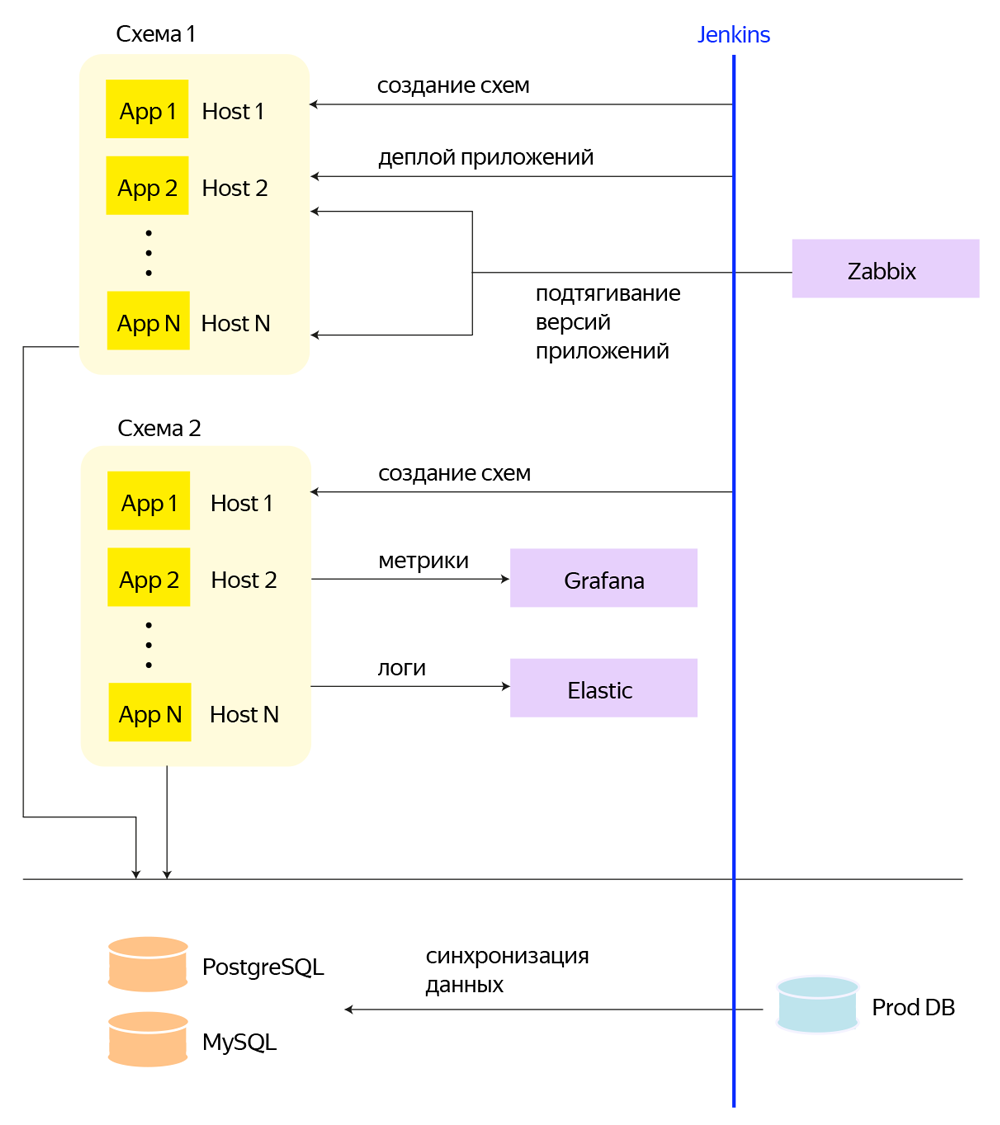
The vertical axis is Jenkins, through which the creation of schemes, deployment of applications, the creation of databases and other processes take place.
To visualize all the processes with test circuits, we use Jenkins Pipeline and Blue Ocean, we get a clear picture of all the steps, and it is easy to see the broken stage. Most of the processes we have done are idempotent, and in case of an error it is enough just to restart the build.
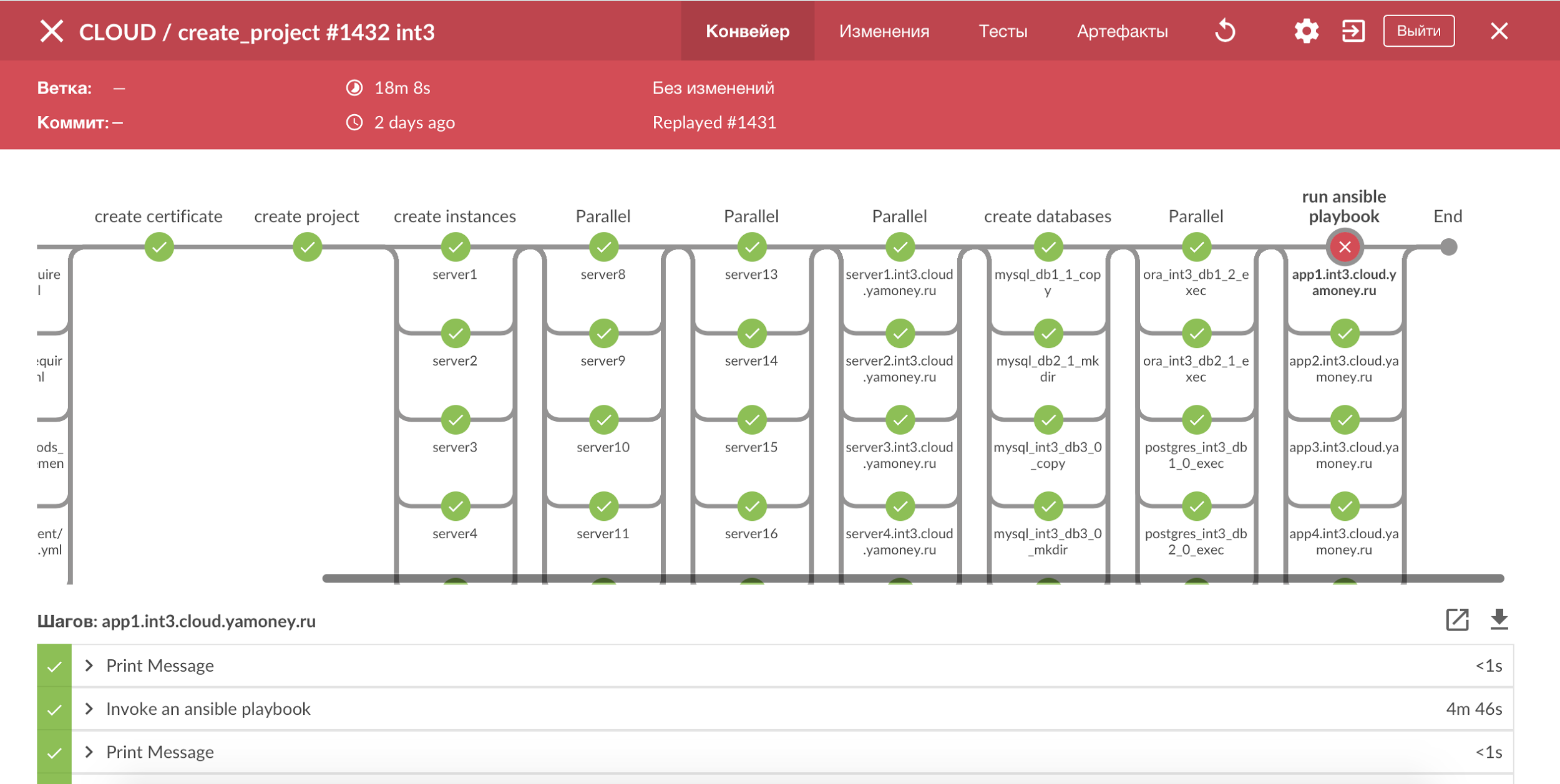
Process visualization with Jenkins Pipeline.
We tried to put all the databases on separate physical machines in order not to create an extra disk load, leaving the application server in test schemes, and we clone all instances that are not yet able to automatically deploy. Instances with applications that are a database and are not transferred to separate physical machines, we create CEPH on a separate ssd pool.
Speaking of numbers: closer to the end of the project, one medium scheme included more than 60 instances that use about 180 GB of memory and 600 GB of disk space.
And I probably will answer:
- First, because we do not have it in the infrastructure - that is, we would have to deploy it specifically for this project, including production. With OpenStack, you can almost completely repeat the combat environment in the test segment.
- Secondly, each application has its own binding from Heka, Zabbix, HAproxy, Pgbouncer, which are necessary for monitoring and logging, balancing traffic and switching the database. That is, the Docker scheme would require significantly more refactoring of the existing architecture.
- Thirdly, Yandex.Money has high requirements for service uptime, and assessing the aggregate level of accessibility of Docker (taking into account the need for its implementation in the combat environment) and all services built around it would require separate study and a lot of time.
- But we are looking in the direction of containerization to isolate services on combat systems and the lightweight replacement of heavy virtual machines on test environments. Initially, the simplest solution “one component - one virtual machine” was built, with an eye to further transfer into containers. Implementing parallel containers seemed too risky.
To ensure the applicability of existing ansible roles and playbooks for test schemes without any changes, a dynamic inventory generation script is used that, by the name of the scheme that matches the project name in OpenStack, creates an Inventrory of the same type as in production. All the necessary information for dynamic inventory is contained in the metadata of the instances in OpenStack.
As for applications, we translated a significant part of our components on the deployment via ansible: the application is packaged in a deb package together with configs templates and variable values for different environments, and the universal Ansible playbook can template configs, switch symlinks between different versions and check the elevation of the application. Thus, the number of components that we must first clone from the reference scheme when creating a new one has drastically decreased.
In fact, not all components have been transferred to a new deployment - the project is at the “translate what is left” stage just at the time of writing this article.
Another important feature was the process of maintaining all test circuits up to date, for this we implemented a pull-up of production versions from our monitoring and launching an update at night or on demand. Moreover, if the diagram is not a production version of the application, but an assembly from a feature branch, then such a component is automatically excluded from the nightly update.
What about processing
Since the majority of applications in test schemes are somehow involved in the payment process, a pool of test bank cards is automatically generated for it. Creation of cards, authorization on them and clearing are performed in the processing module, which stands separately from the test schemes and is common to all payment components. Despite the fact that the processing is special test, it can only send a response to a specific server.
That is, we have a lot of schemes and a processing server that does not want to know anything about this set. In addition, in test patterns, new map ranges are added dynamically. As a logical solution to the problem, one could simply clone the processing for each scheme, but this would entail an excessive increase in resources, as well as automation of the processing settings in each scheme. In general, it does not seem to be the best way.
In order not to substantially finish the existing processing, we decided to correct the component creating the maps in the test scheme and install the nginx server with the lua module to proxying the authorization requests from the processing. After adding a range of maps to the scheme, the process of creating maps is started in processing, as a result of which for each map the name of the scheme that issued it is added to the service field.
All reverse requests from processing to test schemes are sent to the server with nginx, where the lua script searches the name of the scheme in the request body and proxies the request correctly.
And almost a year has passed since the last article about this story ...
As Dima wrote in the first part of our novel about test environments, when several divisions work with the system, projects tend to drag out.
But nevertheless a certain finish line is already visible, and we can summarize what we managed to solve:
- To update the applications that are deployed by cloning instances, it was necessary to recreate the entire schema. According to the results of the project, the problem still remains, since it can be solved when all our components are transferred to the standard deployment process - in the process.
- High disk load from some applications and local logging has decreased to acceptable values due to the transition to SSD drives and separate pools in CEPH for such instances.
- It is difficult to effectively use the RAM when working with virtual machines, since the memory is consumed including the operating system inside the machine.
- With the introduction of the OpenStack / CEPH infrastructure, additional labor was required to test new versions, find and fix bugs, etc. In general, everything that accompanies any new product in the infrastructure.
- As a result of the project, recording application logs on several thousand instances creates a noticeable load on CEPH, so we are thinking in the direction of rejecting local logging.
At the moment, we have already done auto-update of most of the components on all test circuits before their production versions and started a project to create test circuits with a selective set of components to save resources. Now plans to use LXC containers in OpenStack.
In general, this whole technique is just the tip of the iceberg. The most pain is to persuade the development and testers to move to new schemes (to establish new processes). Just went the second quarter, as we continue to slowly, step by step to migrate from the old schemes to new ones.
')
Source: https://habr.com/ru/post/345654/
All Articles