Modify Python in 6 minutes
All good and inexorably coming!
This extremely intense year is coming to an end and we have the last course that we launch this year - " Python full-stack developer ", which, in fact, we dedicate to the article, which, although it has slipped past the main program, but seemed interesting generally.
This week I did my first pull-request to the main CPython project. He was rejected :-( But in order not to waste my time, I’ll share my conclusions on how CPython works and show you how easy it is to change the syntax of Python.
')
I'm going to show you how to add a new feature to the Python syntax. This feature is an increment / decrement operator, the standard operator for most languages. To be sure - open the REPL and try:
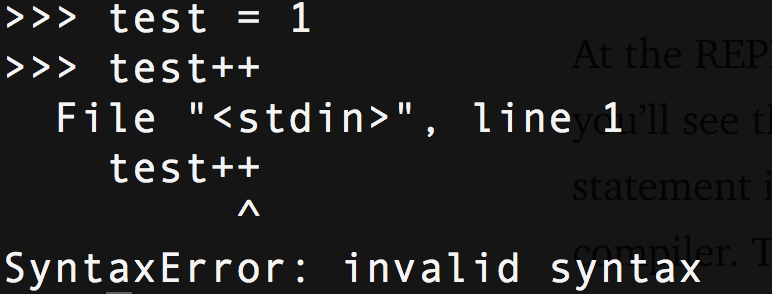
A change in the Python syntax is preceded by an application describing the reasons for the design and behavior of the changes made. All language changes are discussed by the main Python team and approved by the BDFL. Increment operators are not approved (and probably never will be), which gives us a good opportunity to practice.
The Grammar file is a simple text file that describes all the elements of the Python language. It is used not only by CPython, but also by other implementations, such as PyPy, to preserve consistency and harmonize types of language semantics.
Inside these keys form tokens that are understood by the lexer. When you type
Thus,
Let's add increment and decrement expressions: something that does not exist in the language. This would be another variant of the structure of the expression, along with the yield, extended and standard assignment operators, i.e. foo = 1.
We add it to the list of possible small expressions (this will become apparent in AST).
If you run Python with the -d option and try it, you should get:
What is a token? Let's find out ...
There are four steps that Python takes when you call return: lexical analysis, parsing, compilation, and interpretation. Lexical analysis breaks the line of code you just entered into tokens. The CPython lexer is called
For example, the code that allows you to use
Let's add two things to Parser / tokenizer.c: the new
Then we add a check to return the
They are defined in
Now, when we start Python with -d and try to execute our statement, we see:

The parser accepts these tokens and generates a structure that shows their relationship with each other. For Python and many other languages, this is an abstract syntax tree (or AST). The compiler then takes an AST and turns it into one (or more) code object. Finally, the interpreter accepts each code object that executes the code represented by it.
Submit your code as a tree. The top level is the root, the function can be a branch, the class is also a branch and the methods of the class are branched off from it. Expressions are leaves on a branch.
AST is defined in
This is the code we need to add for increment and decrement.
This returns an extended assignment — instead of a new type of expression with a constant value of 1. The operator is either Add or Sub (tract), depending on the type of token
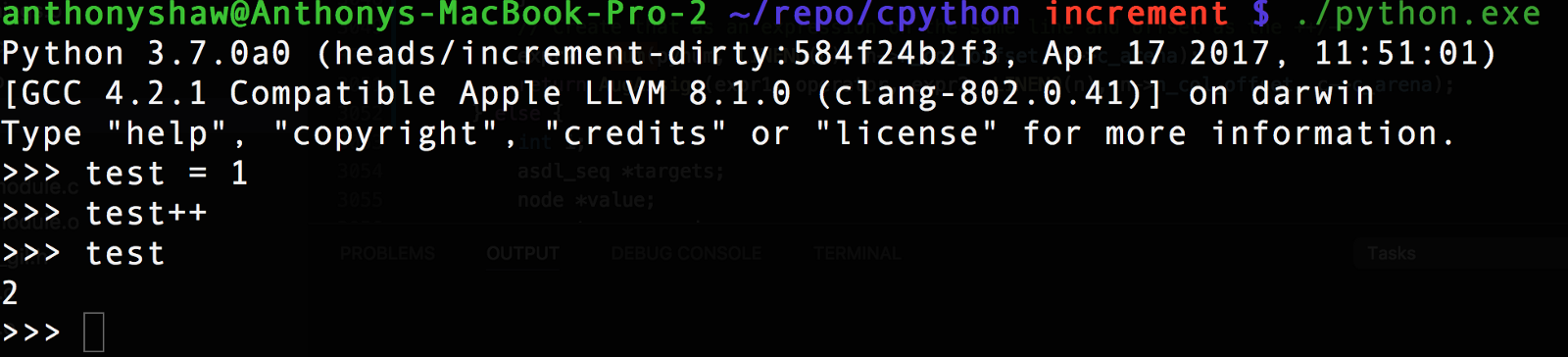
In the REPL you can try
Then the compiler takes the syntax tree and “visits” each branch. The CPython compiler has a method for visiting a statement called
The result will be VISIT (load value - for us 1), ADDOP (add a binary operation code operation depending on the operator (subtract, add)) and STORE_NAME (save the result ADDOP for the name). These methods respond with more specific bytecodes.
If you load the

The final level is the interpreter. It takes a sequence of bytecodes and converts it into machine operations. That's why Python.exe and Python for Mac and Linux are all separate executable files. Some byte codes need specific handling and verification of the OS. The stream processing API, for example, should work with the GNU / Linux API, which is very different from Windows threads.
For further reading.
If you are interested in interpreters, I talked about Pyjion, the plugin architecture for CPython, which has become PEP523
If you still want to play, I ran the code on GitHub along with my changes in the wait token.
THE END
As always, we are waiting for questions, comments, comments.
This extremely intense year is coming to an end and we have the last course that we launch this year - " Python full-stack developer ", which, in fact, we dedicate to the article, which, although it has slipped past the main program, but seemed interesting generally.
Go
This week I did my first pull-request to the main CPython project. He was rejected :-( But in order not to waste my time, I’ll share my conclusions on how CPython works and show you how easy it is to change the syntax of Python.
')
I'm going to show you how to add a new feature to the Python syntax. This feature is an increment / decrement operator, the standard operator for most languages. To be sure - open the REPL and try:
Level 1: PEP
A change in the Python syntax is preceded by an application describing the reasons for the design and behavior of the changes made. All language changes are discussed by the main Python team and approved by the BDFL. Increment operators are not approved (and probably never will be), which gives us a good opportunity to practice.
Level 2: Grammar
The Grammar file is a simple text file that describes all the elements of the Python language. It is used not only by CPython, but also by other implementations, such as PyPy, to preserve consistency and harmonize types of language semantics.
Inside these keys form tokens that are understood by the lexer. When you type
make -j , the command converts them into a set of enumerations and constants in C-headers. This allows you to refer to them in the future. stmt: simple_stmt | compound_stmt simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE # ... pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue' # .. import_as_name: NAME ['as' NAME] Thus,
simple_stmt is a simple expression, it may have a semicolon or not, for example, when you enter import pdb; pdb.set_trace() import pdb; pdb.set_trace() , and end on the new line NEWLINE. Pass_stmt - word skip, break_stmt - work interruption. Simple, isn't it?Let's add increment and decrement expressions: something that does not exist in the language. This would be another variant of the structure of the expression, along with the yield, extended and standard assignment operators, i.e. foo = 1.
# expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) | ('=' (yield_expr|testlist_star_expr))* | incr_stmt | decr_stmt) annassign: ':' test ['=' test] testlist_star_expr: (test|star_expr) (',' (test|star_expr))* [','] augassign: ('+=' | '-=' | '*=' | '@=' | '/=' | '%=' | '&=' | '|=' | '^=' | '<<=' | '>>=' | '**=' | '//=') # , del_stmt: 'del' exprlist # incr_stmt: '++' decr_stmt: '--' We add it to the list of possible small expressions (this will become apparent in AST).
Incr_stmt will be our increment method and decr_stmt will be decrement. Both follow NAME (variable name) and form a small autonomous expression. When we build a Python project, it will generate components for us (not now).If you run Python with the -d option and try it, you should get:
Token <ERRORTOKEN>/'++' … Illegal token What is a token? Let's find out ...
Level 3: Lexer
There are four steps that Python takes when you call return: lexical analysis, parsing, compilation, and interpretation. Lexical analysis breaks the line of code you just entered into tokens. The CPython lexer is called
tokenizer.c . It has functions that read from a file (for example, python file.py ) a string (for example, REPL). It also processes a special comment for the encoding at the top of the files and analyzes your file as UTF-8, etc. It processes nesting, the async and yield keywords, detects sets and tuples of assignments, but only grammatically. He does not know what these things are or what to do with them. He cares only text.For example, the code that allows you to use
o -notation for octal values is in the tokenizer . The code that actually creates octal values is in the compiler.Let's add two things to Parser / tokenizer.c: the new
INCREMENT and DECREMENT tokens are the keys that the DECREMENT returns for each part of the code. /* */ const char *_PyParser_TokenNames[] = { "ENDMARKER", "NAME", "NUMBER", ... "INCREMENT", "DECREMENT", ... Then we add a check to return the
INCREMENT or DECREMENT token each time we see ++ or -. There is already a function for two-character operators, so we are expanding it in accordance with our case. @@ -1175,11 +1177,13 @@ PyToken_TwoChars(int c1, int c2) break; case '+': switch (c2) { + case '+': return INCREMENT; case '=': return PLUSEQUAL; } break; case '-': switch (c2) { + case '-': return DECREMENT; case '=': return MINEQUAL; case '>': return RARROW; } They are defined in
token.h #define INCREMENT 58 #define DECREMENT 59 Now, when we start Python with -d and try to execute our statement, we see:
It's a token we know - ! Level 4: Parser
The parser accepts these tokens and generates a structure that shows their relationship with each other. For Python and many other languages, this is an abstract syntax tree (or AST). The compiler then takes an AST and turns it into one (or more) code object. Finally, the interpreter accepts each code object that executes the code represented by it.
Submit your code as a tree. The top level is the root, the function can be a branch, the class is also a branch and the methods of the class are branched off from it. Expressions are leaves on a branch.
AST is defined in
ast.py and ast.c ast.c is the file we need to change. The AST code is broken into methods that handle token types, ast_for_stmt processes operators, ast_for_expr processes expressions. We put incr_stmt and decr_stmt as possible expressions. They are almost identical to extended expressions, for example, test + = 1, but there is no right expression (1), it is implicit.This is the code we need to add for increment and decrement.
static stmt_ty ast_for_expr_stmt(struct compiling *c, const node *n) { ... else if ((TYPE(CHILD(n, 1)) == incr_stmt) || (TYPE(CHILD(n, 1)) == decr_stmt)) { expr_ty expr1, expr2; node *ch = CHILD(n, 0); operator_ty operator; switch (TYPE(CHILD(n, 1))){ case incr_stmt: operator = Add; break; case decr_stmt: operator = Subtract; break; } expr1 = ast_for_testlist(c, ch); if (!expr1) { return NULL; } switch (expr1->kind) { case Name_kind: if (forbidden_name(c, expr1->v.Name.id, n, 0)) { return NULL; } expr1->v.Name.ctx = Store; break; default: ast_error(c, ch, "illegal target for increment/decrement"); return NULL; } // PyObject 1 PyObject *pynum = parsenumber(c, "1"); if (PyArena_AddPyObject(c->c_arena, pynum) < 0) { Py_DECREF(pynum); return NULL; } // ++/-- expr2 = Num(pynum, LINENO(n), n->n_col_offset, c->c_arena); return AugAssign(expr1, operator, expr2, LINENO(n), n->n_col_offset, c->c_arena); This returns an extended assignment — instead of a new type of expression with a constant value of 1. The operator is either Add or Sub (tract), depending on the type of token
incr_stmt or decr_stmt . Returning to the Python REPL after compilation, we can see our new statement!In the REPL you can try
ast.parse ("test=1; test++).body[1] , and you will see the return type of AugAssign . AST just converted the operator into an expression that can be processed by the compiler. The AugAssign function sets the Kind field, which used by the compiler.Level 5: Compiler
Then the compiler takes the syntax tree and “visits” each branch. The CPython compiler has a method for visiting a statement called
compile_visit_stmt . It's just a big switch statement that defines the type of statement. We had the AugAssign type, so it accesses the compiler_augassign for handling details. This function then converts our assertion into a set of bytecodes. This is an intermediate language between machine code (01010101) and the syntax tree. The byte code sequence is what is cached in .pyc files. static int compiler_augassign(struct compiler *c, stmt_ty s) { expr_ty e = s->v.AugAssign.target; expr_ty auge; assert(s->kind == AugAssign_kind); switch (e->kind) { ... case Name_kind: if (!compiler_nameop(c, e->v.Name.id, Load)) return 0; VISIT(c, expr, s->v.AugAssign.value); ADDOP(c, inplace_binop(c, s->v.AugAssign.op)); return compiler_nameop(c, e->v.Name.id, Store); The result will be VISIT (load value - for us 1), ADDOP (add a binary operation code operation depending on the operator (subtract, add)) and STORE_NAME (save the result ADDOP for the name). These methods respond with more specific bytecodes.
If you load the
dis module, you can see the bytecode:Level 6: Interpreter
The final level is the interpreter. It takes a sequence of bytecodes and converts it into machine operations. That's why Python.exe and Python for Mac and Linux are all separate executable files. Some byte codes need specific handling and verification of the OS. The stream processing API, for example, should work with the GNU / Linux API, which is very different from Windows threads.
! For further reading.
If you are interested in interpreters, I talked about Pyjion, the plugin architecture for CPython, which has become PEP523
If you still want to play, I ran the code on GitHub along with my changes in the wait token.
THE END
As always, we are waiting for questions, comments, comments.
Source: https://habr.com/ru/post/345526/
All Articles