Non convolutional networks
The advantages, problems and limitations of convolutional neural networks (CNN) are currently quite well studied. About 5 years have passed since their recognition by the community of engineers, and the first impression “now we will solve all the problems”, I want to believe, has already passed. So, it's time to look for ideas that will make the next step in the field of AI. Hinton, for example, suggested CapsuleNet .
Together with Alexey Redozubov, relying on his ideas about the structure of the brain, we also decided to retreat from the mainstream. And now I have something to show: architecture (goes with the title picture to attract attention) and the source code for Tensorflow for MNIST.
More formally, the result is described in an article on arxiv .
What for?
Always and in everything we deal with ambiguity. The further information leaves the senses, the more options for its interpretation becomes. It seems, sight does not bring us. But no, there are a number of illusions that demonstrate that this is not so: the illusion of a concave mask (you need to try very hard to realize its concave depth), the famous white-blue-brown dress. Hearing is the same story that amazes even more than visual illusions: I want to congratulate you on this . And when the question of perception of information concerns abstract concepts, it is impossible not to recall the endless debate about politics.
')
This principle of changing the meaning of the observable depending on the context is universal, implemented in one way or another for any information we are dealing with. And, at the same time, it is poorly or not explicitly reflected in most approaches to machine learning. Often, the formulation of machine learning tasks eliminates the very possibility of various interpretations. Although, if you look at the idea of convolutional networks from a different angle, it turns out that the statement of the problem for one convolutional layer is formulated as follows: you must select K features with the size of MxM, regardless of what position (spatial context) they are in. If at the same time it is assumed that the transfer operation on X, Y is not programmed in advance, then the task becomes very nontrivial. Similarly with recurrent networks: it is necessary to distinguish sequences in time, regardless of at what point in time T (context of time) it appeared.
In addition, after learning, we can use ideas about how data changes due to a change in context. Show a person a new car model from 4 sides, he will easily recognize it later in perspective from a random angle. A child will see a cartoon where a certain social model of interaction is demonstrated by beasts, it is not difficult for him to recognize the same situation in his relationship with people. This is such a powerful and universal principle that I personally wonder why it receives so little attention.
I am convinced that Strong Artificial Intelligence will differ precisely in the ability to present any information at any level of processing in various contexts, choose the most appropriate context of the observed situation and experience gained as a result of training.
The inspiration for the convolutional networks (or rather the neocognitron) was the research of Hubel and Wiesel, who at one time conducted very effective studies of the visual cortex V1 and the function of minicolumns in it, for which they were awarded the Nobel Prize. But the results of their experiments can be interpreted differently. Read more here .
Hinton's capsule nets are also a way of rethinking the function of minicolumns.
Suppose the minicolumn function
The cerebral cortex is structurally composed of zones with different functions, but at the same time, regardless of the zone, minicolumns are structurally distinguished - columns of neurons, the vertical connections between which are denser than the horizontal ones.
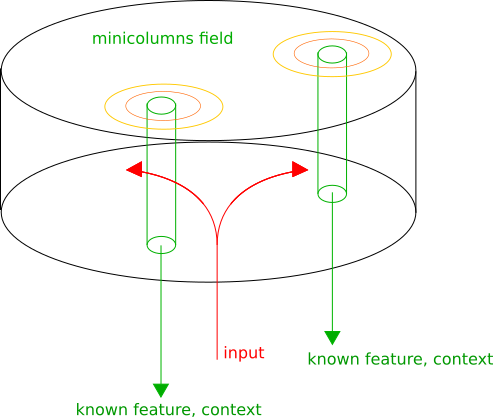
We assume that the minicarrier presents the input information in its own context. Then, in each minicolumn, known patterns are recognized, its activity is proportional to the degree of reliability of recognition. Neighboring minicolumns represent similar transformations, due to this we can choose local maxima of activity on the cortex, which will correspond to the best contexts in which the input information is treated. The output of the cortical area will be the list: (recognized patterns, context).
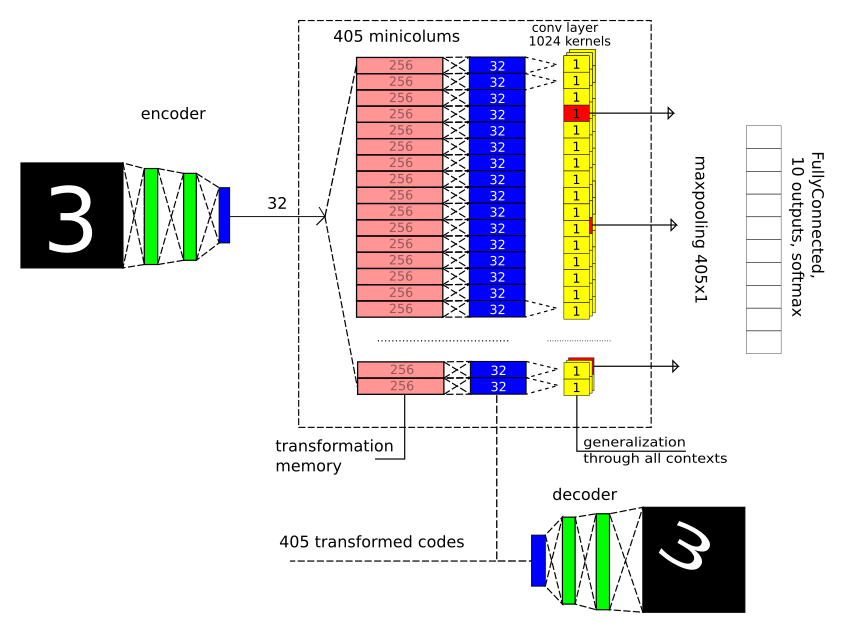
Model for MNIST
Only one level of information analysis was modeled (one zone), several zones will be the next stage.
It is fundamentally important that here we have abandoned spatial convolutions in the image (Conv2D) and max-pooling 2x2, which forgive small geometric distortions, due to which the accuracy on MNIST is noticeably improved.
I will repeat the picture so that I don’t have to wind off far when reading the text:
There are 3 important parts:
1) Only a vector of length 32 enters the zone — the result of compression by the classical autoencoder with 2 fully connected layers for decoding and encoding.
2) We set 405 geometric context-transformations: 5 turns X 9 displacements X 9 scales. We look at how the code changes (32 components) after the input images are transformed, we train for each context transformation 2 fully connected layers (32-> 256-> 32), i.e. one hidden and one day off. In fact, of course, just remember.
3) We are looking for stable patterns, regardless of the context in which they appeared, for each pattern we choose the best context (max-pooling layer).
Then we exit the zone to a small fully meshed network, which decides what the figure is in front of us.
Training
Yes, the principle of reverse propagation of errors was used everywhere. The only thing that his "long-range" was very limited. Those. studied in stages, there was hardly any real “deep learning”. There is a feeling that everything should work on different approaches, but until the algorithms are written we will use proven tools.
First, we train the autoencoder separately:

And we fix the weights of the layers of the encoder and decoder.
Actually, this is a completely optional step. Moreover, due to the non-ideal data presentation, the accuracy will deteriorate a little. But at stage 3, this reduces the number of calculations.
Then we train all 405 transformations. Those. how the image code changes after these transformations. Test what happened. Restore the original images from the converted codes:

It seems that it is trite (and it is)! But here are a couple of very important points:
1) From the point of view of the model, the transformation is not programmed, but obtained by training. Those. absolutely no restrictions on what data we are dealing with and what contextual transformations. And what's even cooler, you can even convert not to the same space. But more about that later.
2) You can take and submit to the input a sign that has never been shown before, and we will know how it changes depending on the context.
Let's give the inverted triangle to the entrance and get:

It looks, of course, not so impressive. But ideologically it is very cool! Due to previous experience, you know how an object that you have never seen before in your life will look in all possible contexts. And this opens up the possibility for one-shoot learning. Saw an object in one view, and then find out completely in another! This drastically reduces the required training sample. And if we talk about computer vision, then we are not only talking about geometric transformations, but also about color, brightness, etc.
And then we need detectors that are common to all contexts. It was implemented using a convolutional layer with a 1x1 core size and a max-pooling layer, which selected a winner for each core. The convolutional layer here is just a way to use the same weights for different contexts, it does not perform its usual function (like max-pooling with a kernel of an unusual size of 405x1).
results
First of all, it was important to check how things are going with reducing the size of the training sample. Take the first 1000 images and train only on them.
The learning curve is as follows:

Accuracy 96%.
It is necessary to compare with a convolutional network, for example, such an architecture:

Accuracy after CNN training was 95.3%.
An attentive reader will notice that the comparison is unfair, because I used implicit augmentation (geometric distortion of input images). So we introduce a similar augmentation for the convolution network. We already get 96.2%.
Not bad, the result is comparable with the convolutional network.
Training in the full base gave an accuracy of 99.1%. Which is much worse than the convolutional network, but also better than a fully connected network of several levels.
Failure to use convolutional layers, presumably, reduced accuracy. But, in any case, we managed to debug the architecture and get adequate accuracy.
Something it all reminds?
Yes, first, of course, unexpectedly it looks like Hinton's CapsuleNet. He also offers his own interpretation of the functionality of minicolumns. The main difference is that CapsuleNet does not contain the idea of presenting information in various contexts. But the fact that the architecture turned out to be similar, suggests a very interesting reflection. In its implementation, the activity of the minicolumn corresponds to the recognition of one of the numbers, and in our concept it turns out that the figure is the context. And what does this picture mean in the context of the fact that it is a seven? And in the context of what is the unit? And this question is really not devoid of meaning. The context may be a geometric transformation, and the context may be a type of recognizable object. About this next.
Another transformation idea is contained in Spartial Transformation Networks . The layer of geometric transformation is included in the gap of layers and another small grid that evaluates the most appropriate transformation using regression. At the same time, discontinuities in differentiability are not allowed, and all this can be trained using the method of back propagation of errors. There are 2 differences: it is not formulated what to do with discrete transformations (and, for example, in the grammar of speech, they are discrete), and it seems that a small regression network for assessing the optimal transformation is unnecessary. The best context is to choose on the basis of in which of the contexts the data form a known pattern, and there is no other optimal way, apart from analyzing each of the transformations.
And another thought that never lets go
There is a so-called “Two-stream hypothesis” in the visual tract (and in the auditory / speech). On one side of the brain (ventral stream), minicolumns respond mainly to the characteristics of objects and the types of objects themselves, and on the other side of the brain (dorsal stream) mainly to spatial characteristics.
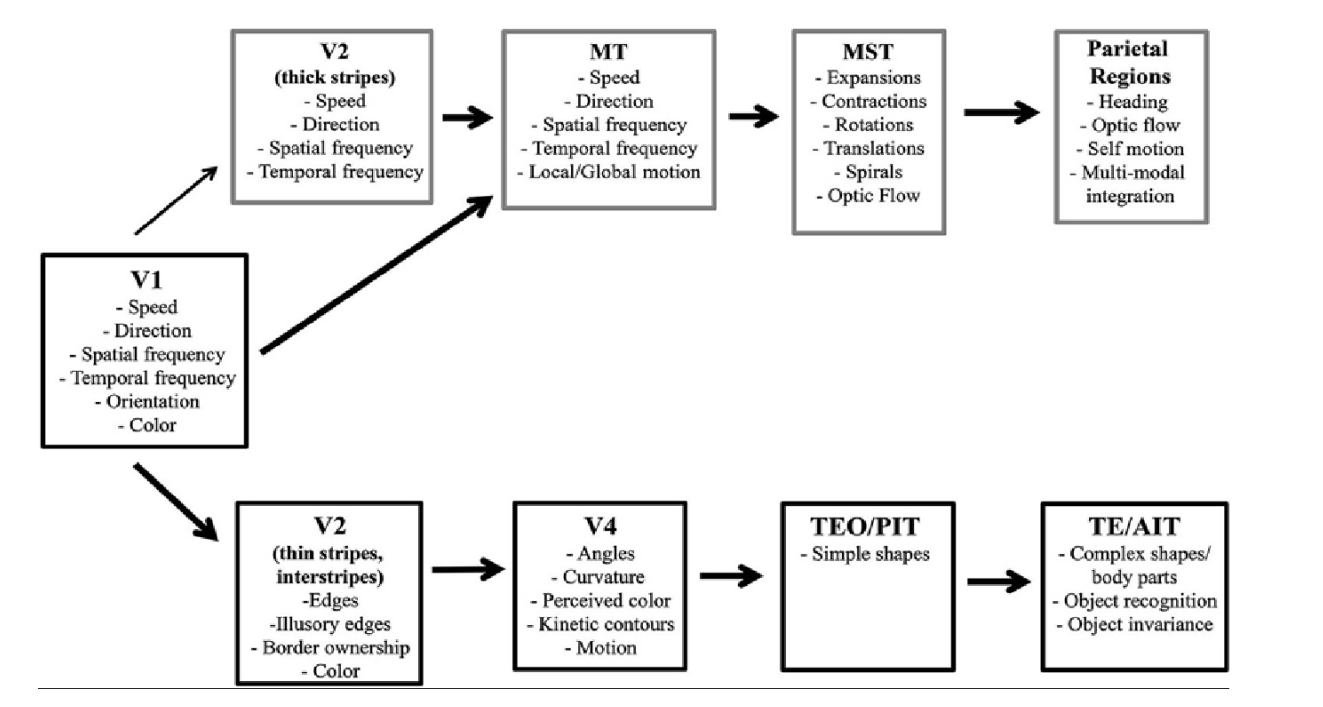
In our interpretation, dorsal stream is just about spatial and temporal transformations. Take a look at V2 and V3: Speed X Direction - transition to the reference system, moving at a given speed with a given direction, Spartical Frequency - just a scale conversion, Temporal Frequency - a change in scale over time.
But Ventral Stream looks completely counterintuitive. What does it mean to go into the context of “Simple shapes” (context of the form), or the context of curvature? In the context of color, by the way, is not a problem. Or in TE / AIT "in the context of the object"? This problem can be overcome by assuming that the minicolumn code characterizes the properties and characteristics of the object. For example, the curvature of the border in the image is characterized by contrast, blurring, color, etc. And these characteristics will be common to each of the minicolumns responsible for the curvature.
Very close to CapsuleNet, but the styles or features inside the mini columns should be common to some neighborhood. It remains an open question how to train this type of contextual transformations.
It is also remarkable here that the result of recognition obtained in one of the Streams can be used in the other. Knowing the shape in the context of a particular position in the dorsal stream, orientation and scale, you can increase the probability of activation of the corresponding mini speakers in the ventral stream. And vice versa.
findings
There is still plenty of work ahead.
PS: The name ContextNet, which I used in the source code, is in fact already taken , but it is painfully well suited.
Source: https://habr.com/ru/post/345492/
All Articles