Difficult about the simple: how to measure the opening time of the page and not make enemies
You are a developer and want to see that your page has become faster to open after all optimizations. Or you need to prove to the authorities that you are not a camel and everything really sped up. And maybe you want to make sure that your users will not suffer from slowly opening pages. Or, as in our case, you are a tester, who is now responsible for customer performance, and the leaked brakes on production keep me awake at night.
Measuring client productivity is not a trivial task. Especially if you have hundreds of pages in a project on a variety of stands. Each one is filled with js code, and hundreds of developers every day optimize, change, re-create them. It is necessary to design a system for collecting, processing and storing data. Which storage to choose? How to design a database, and in which DBMS? A lot of interesting tasks that fade into laconic “how long has a page opened?”. For us, the search for an answer to this question resulted in a quest with detective investigations, heated arguments and the search for truth. His most interesting moments are in this article.

In ancient times, before web 2.0, determining the end of the page load was relatively simple: a document arrived from the server ± a few ms, and we believe that the page was loaded. Then the number of requests for images, styles and other resources increased. It became a bit more difficult to determine the end of the page loading: now it was necessary to wait for the download of all resources, everyone started to tie into various js events, eg window.onload. The Internet was developing, the pages were heavy and the old approaches stopped working. Now loading the page after receiving all the resources did not stop. There were requests that are executed from js directly, appeared reloading and other mechanisms that have greatly blurred the very point that can be considered the end of the page loading. And now you can find different options to determine the end of the page loading. Let's go briefly on each of them.
')
Network activity. From the definition itself (the end of the page load), we see that we need to wait for the moment when the page has stopped performing requests, i.e. we have no requests in the “pending” state, and for some time new requests were not executed. Determining this, it seems, is not difficult, and the wording is clear. But that's just not workable for most sites. After loading the document a lot of time can go on initializing js, which will increase the time to build the page. And that notorious "page loaded" will take place for the user much later than the end of the download. Also, an unpleasant surprise can be a reloading, which works after the page loads and can last for a few seconds. In addition, it is not uncommon for various mechanisms on a page to exchange information with the server without interruption. Therefore, network activity may never end.
Developments. Now it’s right to say not “the page has loaded”, but “the page has been built”. Since the window.onload already mentioned, new events have been added to which not only the response of the js code can be attached, but also the full opening of our page. As a logical continuation, in 2012, work begins on a standard . There is already a whole series of events related to the page loading process. But in practice, it turns out that these events are triggered before the full construction of the page. This can be seen both on synthetic tests and on the test of the knee. Yes, in theory, you can create some kind of artificial event, which would show that the page has finally loaded. But then we would need to do this for all pages separately. Plus, with any changes to recheck the correctness of the new approach. All this again leads to the original task - how to understand that the page has loaded.
Visual changes. Client performance, one way or another, revolves around the user. Those. what matters to us is what a person feels when working with our product. And then you can, without thinking, rush forward, put a living person and instruct him to determine "by eye" the page load time. The idea is doomed to failure, because it is hardly possible to determine whether the page is slowing down or not slowing down the page, but a person can say how much it slows down on a 10-point scale. However, here we understand that visual changes are perhaps one of the best indicators that a page has loaded. We can constantly monitor the display of the page and, as soon as the visual changes stop, we assume that the page has loaded. But are all page changes equally important?
Here, for the first time, the page was rendered, a border appeared, text appeared, pictures were loaded, counters, social buttons, comments, etc. were loaded. Different situations are important different stages of loading the page. Somewhere the first rendering is important, and it is important for someone to know when the user has seen the comments. But, as a rule, in most cases loading the main content is important for us. It is the visual appearance of the main content that is considered the “page loaded”. Therefore, all other things being equal, we can build on this event, evaluating the page loading speed. In order to work with the page in a complex, there is a wonderful approach called “speed index”, which is described here .
The idea is as follows: we are trying to understand how evenly the page loads. Two versions of one page could open in 2 seconds, but in the first 90% of visual changes occurred a second after opening, and in the second, 1.7 seconds later. With equal opening time, the first page will seem to the user much faster than the second.
Performance So, we now understand exactly what the "page opened." Can we stop at this? And no. The page is loaded, we click on the add new comment button and ... pants do not turn into anything - the page ignores our clicks. What to do? Add another metric. We need to select a target element. And then find out when it will be available for interaction. As will be explained later, this is the most difficult task.
It seems to figure out what is considered the end of the page load. And what about the beginning of the opening? Here, it seems, everything is clear - we count from the moment when we gave the browser a command to open the page, but again the damn details. There are such events as beforeunload. The code that is triggered when they occur, can significantly affect the opening time of the page. We can, of course, always pre-switch to about: blank, but in this case we can skip a similar problem. And with excellent performance of our tests, users will complain about the brakes. Again, we choose based on our specifics. For comparative measurements, we always start with a blank page. And problems with transitions from page to page are caught within the framework of measuring the time of work of critical business scenarios.
Is it important to measure one to one like a customer? Maybe. But will there be any direct benefit from this for development and acceleration? Far from a fact. Here's a great article that says that it’s important to just select at least one metric and build on it to estimate page opening times. It will be much easier to work with one selected indicator, track optimization, build trends. And then, with the availability of resources, supplement with auxiliary metrics.

Great, now everyone in the company speaks the same language. Developers, testers, managers by the time of opening the page understand the time of displaying the main content on the page. We even created a tool that performs these measurements with high accuracy. We have fairly stable results, the measure of variation is minimal. We publish our first report and ... get a lot of disgruntled comments. The most popular of them - "and I died here, and I have everything differently!". Even if we assume that the measurement methodology was observed and the same tool was used, it turns out that everyone has completely different results. We begin to dig and find out that someone was taking measurements via Wi-Fi, someone had a computer with 32 cores, and someone was opening the site from the phone. It turns out that the measurement problem is no longer multifaceted, but multidimensional. Under different conditions, we get different results.
Then the question arose: what factors affect the opening time of the page? In haste was made such an associative map .
Some 60-70 different factors turned out. And a series of experiments began, which sometimes gave us very interesting results.
Cache or not cache - that is the question. The first anomaly we encountered was discovered in the very first reports. We performed measurements with an empty cache and with a full one. Part of the pages with the filled cache was given no faster than with an empty one. And some pages are also longer. At the same time, the volume of traffic at the first opening was measured in megabytes, and at the second one it was less than 100 KB. Open DevTools (by the way, DevTools itself can have a strong influence on measurements, but for comparative research it is what you need), start the data collection and open the page. And we get this picture:
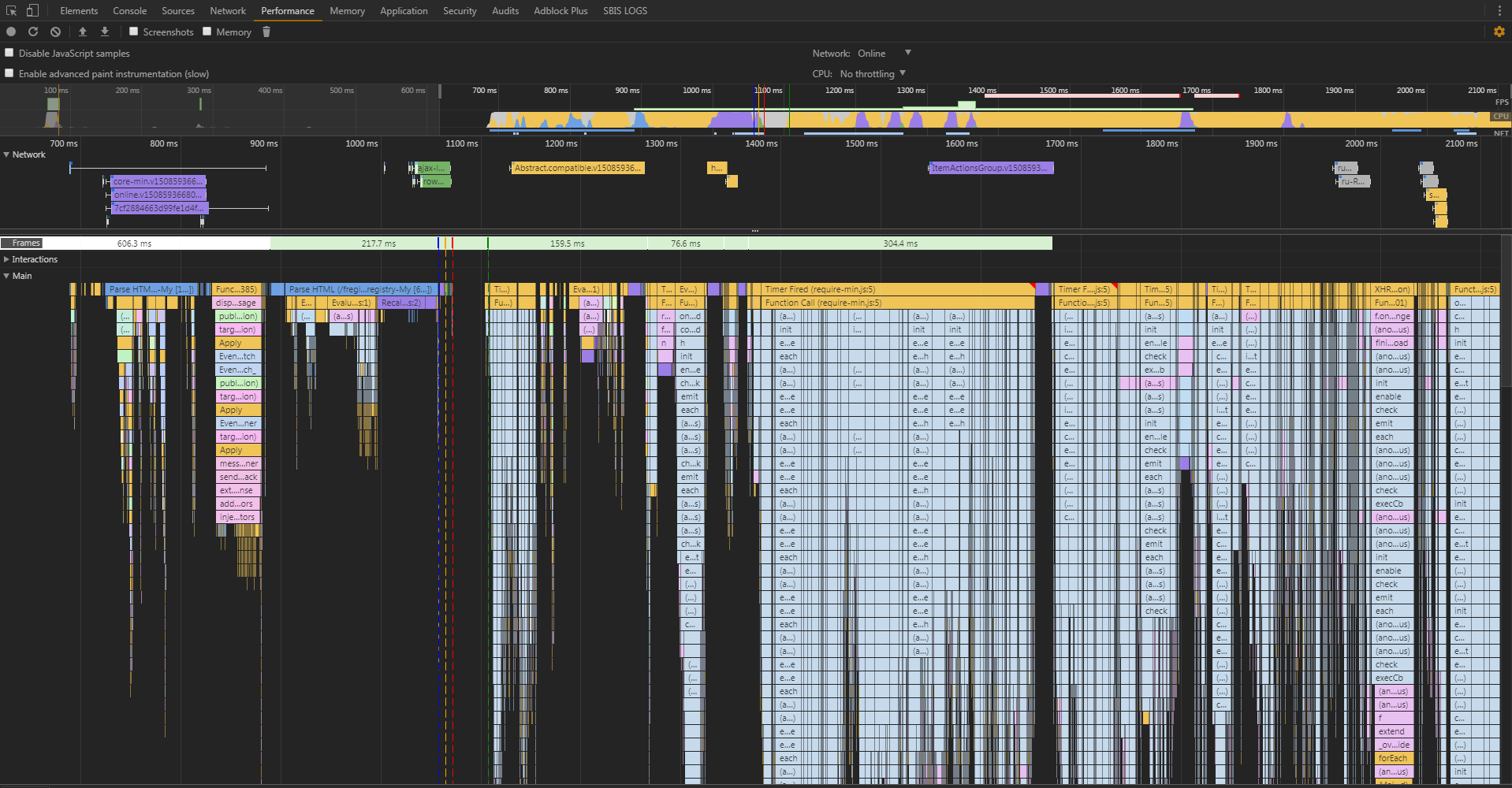
Here you can clearly see that most of the time the browser was engaged in parsing / initializing js-files. Those. we have so many js-code, and the browser so optimally uses the time to receive files over the network, which for the most part we depend on the speed of initialization of js-modules than on the speed of receiving them. Network traffic is very important, but in view of the ideal connection (we measure from the inside of the network), we get exactly this picture. This problem has already been covered, for example, by Eddie Osmani .
So, OK, with the pages that in our report practically did not accelerate with filling the cache, everything is clear. And why did some of the pages start opening even longer? Then I had to look very carefully at the Network tab, on which the problem was discovered. Trying to reduce the number of requests, we combined almost all js modules with extra dependencies into one big file. And on one page this file began to weigh as much as 3 MB. The disk was not an SSD, but a channel with zero ping. Everything else Chrome is very curly works with disk cache, creating brakes sometimes out of the blue. Therefore, the file got out of the cache longer than flying through the network. Which, ultimately, led to an increase in total time.
Yes, page size is critical and should be reduced. But now it is equally important to optimize the data structure. What is the benefit of reducing the size of a small file by 10% through a new compression algorithm, if the user spends the extra 50 ms to decompress? And if you look at the statistics from the site httparchive.org, you will see that further this situation can only get worse:
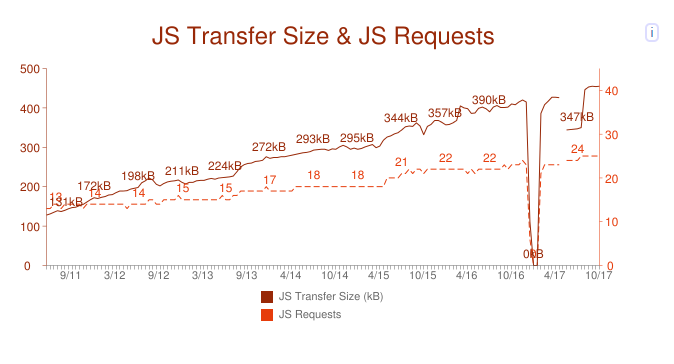
The bottom scale is months and years, the left scale is the volume of js code per page on average, and the right scale is the number of requests per page on average.
About network conditions. Although it was said above about what we measure mainly on the ideal channel, sometimes there is a need to study what happens to the user when opening our pages via Wi-Fi or 3G. Or maybe there is a dial-up somewhere, and you want to understand if woman Frosi’s page from the village of Kukuyevo will open in principle. And here, of course, we can put one of the nodes to measure in that very village, or we can emulate a bad channel. The latter draws on a separate article or even an entire book, so we confine ourselves to a stack of tools that we use successfully.
First, there are various http proxies: BrowserMobProxy (in light mode), Fiddler, mitm, etc. They, of course, do not emulate a bad channel in any way, but simply create delays every n KB. But as practice shows, for applications running on http as a whole, this is enough. When we want to really emulate, netem and clumsy come to the rescue .
With this testing, it is desirable to understand how the network affects the performance of web applications. If it’s not so important for getting results, then it’s really worth figuring it out to interpret them, so as not to give out in the bug report “it’s slowing down”. One of the best books on this topic is “High Performance Browser Networking” by Ilya Grigorik .
Browsers Undoubtedly, the browsers themselves play a very important role in the opening time of the page. And now it is not even about those benchmark tests that each browser creator designs for himself, in order to show that their horse is the brightest on the planet. Now we are talking about various features of the engines or the browsers themselves, which ultimately affect the opening time of the page. For example, Chrome will initialize large js files as they are received in a separate stream. But what the authors mean by "large files" is not specified anywhere. But if you look at the sources of Chromium , it turns out that we are talking about 30 KB.
And so it turns out that sometimes, by slightly increasing the js module, we can speed up page load time. True, not so much of course, so now just to increase all the js modules in a row.
This is a small detail. And if you look wider, then we have different browser settings, open tabs, various plugins, different state of storage and cache. And all this, one way or another, is involved in the browser and can affect how quickly one or another page opens for a particular user.
We found that there are many factors that have a significant or small influence on our measurements. What to do with it? Enumerate all combinations? Then we will get a combinatorial explosion and will not have time to really measure even one page per release. The correct solution is to choose one configuration for the main permanent measurements, since reproducibility of test results is paramount.
As for the rest of the situations, here we decided to conduct separate isolated experiments. In addition, all our assumptions about users may not be true, and it is desirable to learn how to collect indicators directly ( RUM ).
There are many tools dedicated to measuring and web performance in general (gmetrix, pingdom, webpagetest, etc.). If we arm ourselves with Google and try a dozen of them, then we can draw the following conclusions:
Next, about the most practical.
WebPageTest. Of all the variety of tools, WebPageTest stands out positively . This is a hefty multi-combine, constantly evolving and producing an excellent result.
One of the most important advantages of this tool:
About the last plus should be said separately. Here, perhaps, almost all methods are really collected. The most interesting are Speed Index and First Interactive. About the first mentioned before. And the second tells us how long after the appearance of the page will begin to respond to our actions. What if the cunning developer began to generate pictures on the server and send them to us (I hope not).
If you deploy such a solution locally, then you will cover almost all of your performance testing needs. But, alas, not all. If you still want to get the exact time of the appearance of the main content, add the ability to execute entire scripts using convenient frameworks, you have to make your own tool. What we once did.
Selenium. More out of habit than consciously, Selenium was chosen for the first pancake. Disregarding small details, the whole essence of the decision looked like this:
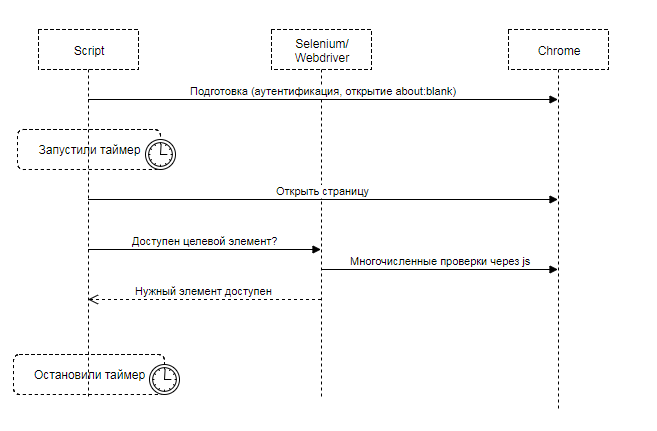
We translate the browser into the desired state, open the page, and begin to wait for Selenium to find the target element accessible and visible to the user. The target element is what the user expects to see: message text, article text, image, etc.
All these measurements were performed 10 times, and averaged results were calculated (eg median, arithmetic mean, ...). In general, from time to time a more or less stable result was obtained. It seems that here it is happiness, but our long-suffering forehead again faces the universal rake. It turned out that although the time was stable with one page unchanged, it began to jump unreasonably when changing this page. The video helped us figure it out. We compared two versions of the same page. The video page opened almost simultaneously (± 100 ms). And measurements through Selenium stubbornly told us that the page began to open for a second and a half longer. And stably longer.
The investigation led to the implementation of is_displayed in Selenium. The calculation of this property consisted of checking several js of the properties of the element, eg that it is in the DOM tree, that it is visible, is not of zero size, and so on. At the same time, all these checks are also carried out recursively for all parent elements. Not only do we have a very large DOM tree, but the checks themselves, being implemented on js, can be performed for a very long time at the time of opening the page due to the initialization processes of the js modules and the execution of other js code.
As a result, we decided to replace Selenium with something else. At first it was WebPageTest, but after a series of experiments, we implemented our simple and working solution.

Since we mainly wanted to measure the time of the visual appearance of the main content on the page, we also chose measurements for the tool by taking screenshots with a frequency of 60 fps. The mechanism of the measurement itself is as follows:

Through the debug-mode, we connect to the Chrome browser, add the necessary cookies, check the environment, and launch the screenshots via the PIL in parallel on the same machine. Open the page we need in the application under test (UAT). Then we wait for the termination of significant network and visual activity with a duration of 10 seconds. After that, we save the results and artifacts: screenshots, HAR-files, Navigation Timing API and so on.
As a result, we get several hundred screenshots and process them.

Usually, after removing all duplicates from hundreds of screenshots, no more than 8 pieces remain. Now we need to calculate some diff between adjacent screenshots. Diff in the simplest case is, for example, the number of modified pixels. For greater reliability, we consider the difference not all screenshots, but only some . After that, summing all the diffs, we get the total number of changes (100%). Now we can only find a screenshot, after which> 90% of page changes occurred. The time to receive this screenshot will be the time to open the page.
Instead of connecting to Chrome via a debug protocol, you can equally well use Selenium. Since from the 63rd version, Chrome supports multiple remote debugging, we still have access to the entire set of data, and not only to those that Selenium gives us.
As soon as we had the first version of this solution, we started a series of tedious, painstaking, but very necessary tests. Yes, yes, testing tools for your products also need to be tested.
For testing, we used two main approaches:
We conduct tests regularly, because the tool itself is changing, the applications being tested are changing. When writing this article, I took one of the stable pages (the server part runs almost instantly) and conducted a series of 100 tests through 3 different approaches. Through the video measured 10 times and calculated the median.
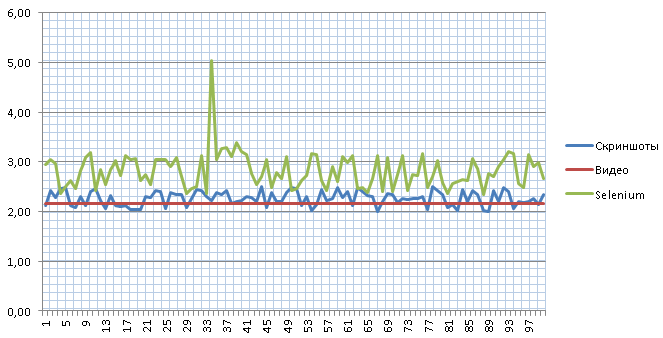
As you can see, through the screenshots, we get a close to reality result within 10 ms of the error. But through Selenium we have a fairly strong variation with an incomprehensible release of up to 5 seconds.
Yes, again about the spherical horse in a vacuum, this is not a universal way. Such an algorithm works for us, with our products, but may not easily work for other sites. Moreover, as with many previous approaches, it is not devoid of the paradox of the observer , as in quantum physics. We can not see the result, guaranteed to not affect it. You can only reduce the degree of error.
At a minimum, the PIL also recycles some resources. But, nevertheless, this solution has been successfully used in the company for the last year. It is regularly updated, but the basic idea remains the same.
Author Sergey Dokuchaev
Measuring client productivity is not a trivial task. Especially if you have hundreds of pages in a project on a variety of stands. Each one is filled with js code, and hundreds of developers every day optimize, change, re-create them. It is necessary to design a system for collecting, processing and storing data. Which storage to choose? How to design a database, and in which DBMS? A lot of interesting tasks that fade into laconic “how long has a page opened?”. For us, the search for an answer to this question resulted in a quest with detective investigations, heated arguments and the search for truth. His most interesting moments are in this article.
What is the "page opened"?
In ancient times, before web 2.0, determining the end of the page load was relatively simple: a document arrived from the server ± a few ms, and we believe that the page was loaded. Then the number of requests for images, styles and other resources increased. It became a bit more difficult to determine the end of the page loading: now it was necessary to wait for the download of all resources, everyone started to tie into various js events, eg window.onload. The Internet was developing, the pages were heavy and the old approaches stopped working. Now loading the page after receiving all the resources did not stop. There were requests that are executed from js directly, appeared reloading and other mechanisms that have greatly blurred the very point that can be considered the end of the page loading. And now you can find different options to determine the end of the page loading. Let's go briefly on each of them.
')
Network activity. From the definition itself (the end of the page load), we see that we need to wait for the moment when the page has stopped performing requests, i.e. we have no requests in the “pending” state, and for some time new requests were not executed. Determining this, it seems, is not difficult, and the wording is clear. But that's just not workable for most sites. After loading the document a lot of time can go on initializing js, which will increase the time to build the page. And that notorious "page loaded" will take place for the user much later than the end of the download. Also, an unpleasant surprise can be a reloading, which works after the page loads and can last for a few seconds. In addition, it is not uncommon for various mechanisms on a page to exchange information with the server without interruption. Therefore, network activity may never end.
Developments. Now it’s right to say not “the page has loaded”, but “the page has been built”. Since the window.onload already mentioned, new events have been added to which not only the response of the js code can be attached, but also the full opening of our page. As a logical continuation, in 2012, work begins on a standard . There is already a whole series of events related to the page loading process. But in practice, it turns out that these events are triggered before the full construction of the page. This can be seen both on synthetic tests and on the test of the knee. Yes, in theory, you can create some kind of artificial event, which would show that the page has finally loaded. But then we would need to do this for all pages separately. Plus, with any changes to recheck the correctness of the new approach. All this again leads to the original task - how to understand that the page has loaded.
Visual changes. Client performance, one way or another, revolves around the user. Those. what matters to us is what a person feels when working with our product. And then you can, without thinking, rush forward, put a living person and instruct him to determine "by eye" the page load time. The idea is doomed to failure, because it is hardly possible to determine whether the page is slowing down or not slowing down the page, but a person can say how much it slows down on a 10-point scale. However, here we understand that visual changes are perhaps one of the best indicators that a page has loaded. We can constantly monitor the display of the page and, as soon as the visual changes stop, we assume that the page has loaded. But are all page changes equally important?
Here, for the first time, the page was rendered, a border appeared, text appeared, pictures were loaded, counters, social buttons, comments, etc. were loaded. Different situations are important different stages of loading the page. Somewhere the first rendering is important, and it is important for someone to know when the user has seen the comments. But, as a rule, in most cases loading the main content is important for us. It is the visual appearance of the main content that is considered the “page loaded”. Therefore, all other things being equal, we can build on this event, evaluating the page loading speed. In order to work with the page in a complex, there is a wonderful approach called “speed index”, which is described here .
The idea is as follows: we are trying to understand how evenly the page loads. Two versions of one page could open in 2 seconds, but in the first 90% of visual changes occurred a second after opening, and in the second, 1.7 seconds later. With equal opening time, the first page will seem to the user much faster than the second.
Performance So, we now understand exactly what the "page opened." Can we stop at this? And no. The page is loaded, we click on the add new comment button and ... pants do not turn into anything - the page ignores our clicks. What to do? Add another metric. We need to select a target element. And then find out when it will be available for interaction. As will be explained later, this is the most difficult task.
It seems to figure out what is considered the end of the page load. And what about the beginning of the opening? Here, it seems, everything is clear - we count from the moment when we gave the browser a command to open the page, but again the damn details. There are such events as beforeunload. The code that is triggered when they occur, can significantly affect the opening time of the page. We can, of course, always pre-switch to about: blank, but in this case we can skip a similar problem. And with excellent performance of our tests, users will complain about the brakes. Again, we choose based on our specifics. For comparative measurements, we always start with a blank page. And problems with transitions from page to page are caught within the framework of measuring the time of work of critical business scenarios.
Is it important to measure one to one like a customer? Maybe. But will there be any direct benefit from this for development and acceleration? Far from a fact. Here's a great article that says that it’s important to just select at least one metric and build on it to estimate page opening times. It will be much easier to work with one selected indicator, track optimization, build trends. And then, with the availability of resources, supplement with auxiliary metrics.
Why do I have a different result?
Great, now everyone in the company speaks the same language. Developers, testers, managers by the time of opening the page understand the time of displaying the main content on the page. We even created a tool that performs these measurements with high accuracy. We have fairly stable results, the measure of variation is minimal. We publish our first report and ... get a lot of disgruntled comments. The most popular of them - "and I died here, and I have everything differently!". Even if we assume that the measurement methodology was observed and the same tool was used, it turns out that everyone has completely different results. We begin to dig and find out that someone was taking measurements via Wi-Fi, someone had a computer with 32 cores, and someone was opening the site from the phone. It turns out that the measurement problem is no longer multifaceted, but multidimensional. Under different conditions, we get different results.
Then the question arose: what factors affect the opening time of the page? In haste was made such an associative map .
Some 60-70 different factors turned out. And a series of experiments began, which sometimes gave us very interesting results.
Cache or not cache - that is the question. The first anomaly we encountered was discovered in the very first reports. We performed measurements with an empty cache and with a full one. Part of the pages with the filled cache was given no faster than with an empty one. And some pages are also longer. At the same time, the volume of traffic at the first opening was measured in megabytes, and at the second one it was less than 100 KB. Open DevTools (by the way, DevTools itself can have a strong influence on measurements, but for comparative research it is what you need), start the data collection and open the page. And we get this picture:
Here you can clearly see that most of the time the browser was engaged in parsing / initializing js-files. Those. we have so many js-code, and the browser so optimally uses the time to receive files over the network, which for the most part we depend on the speed of initialization of js-modules than on the speed of receiving them. Network traffic is very important, but in view of the ideal connection (we measure from the inside of the network), we get exactly this picture. This problem has already been covered, for example, by Eddie Osmani .
So, OK, with the pages that in our report practically did not accelerate with filling the cache, everything is clear. And why did some of the pages start opening even longer? Then I had to look very carefully at the Network tab, on which the problem was discovered. Trying to reduce the number of requests, we combined almost all js modules with extra dependencies into one big file. And on one page this file began to weigh as much as 3 MB. The disk was not an SSD, but a channel with zero ping. Everything else Chrome is very curly works with disk cache, creating brakes sometimes out of the blue. Therefore, the file got out of the cache longer than flying through the network. Which, ultimately, led to an increase in total time.
Yes, page size is critical and should be reduced. But now it is equally important to optimize the data structure. What is the benefit of reducing the size of a small file by 10% through a new compression algorithm, if the user spends the extra 50 ms to decompress? And if you look at the statistics from the site httparchive.org, you will see that further this situation can only get worse:
The bottom scale is months and years, the left scale is the volume of js code per page on average, and the right scale is the number of requests per page on average.
About network conditions. Although it was said above about what we measure mainly on the ideal channel, sometimes there is a need to study what happens to the user when opening our pages via Wi-Fi or 3G. Or maybe there is a dial-up somewhere, and you want to understand if woman Frosi’s page from the village of Kukuyevo will open in principle. And here, of course, we can put one of the nodes to measure in that very village, or we can emulate a bad channel. The latter draws on a separate article or even an entire book, so we confine ourselves to a stack of tools that we use successfully.
First, there are various http proxies: BrowserMobProxy (in light mode), Fiddler, mitm, etc. They, of course, do not emulate a bad channel in any way, but simply create delays every n KB. But as practice shows, for applications running on http as a whole, this is enough. When we want to really emulate, netem and clumsy come to the rescue .
With this testing, it is desirable to understand how the network affects the performance of web applications. If it’s not so important for getting results, then it’s really worth figuring it out to interpret them, so as not to give out in the bug report “it’s slowing down”. One of the best books on this topic is “High Performance Browser Networking” by Ilya Grigorik .
Browsers Undoubtedly, the browsers themselves play a very important role in the opening time of the page. And now it is not even about those benchmark tests that each browser creator designs for himself, in order to show that their horse is the brightest on the planet. Now we are talking about various features of the engines or the browsers themselves, which ultimately affect the opening time of the page. For example, Chrome will initialize large js files as they are received in a separate stream. But what the authors mean by "large files" is not specified anywhere. But if you look at the sources of Chromium , it turns out that we are talking about 30 KB.
And so it turns out that sometimes, by slightly increasing the js module, we can speed up page load time. True, not so much of course, so now just to increase all the js modules in a row.
This is a small detail. And if you look wider, then we have different browser settings, open tabs, various plugins, different state of storage and cache. And all this, one way or another, is involved in the browser and can affect how quickly one or another page opens for a particular user.
We found that there are many factors that have a significant or small influence on our measurements. What to do with it? Enumerate all combinations? Then we will get a combinatorial explosion and will not have time to really measure even one page per release. The correct solution is to choose one configuration for the main permanent measurements, since reproducibility of test results is paramount.
As for the rest of the situations, here we decided to conduct separate isolated experiments. In addition, all our assumptions about users may not be true, and it is desirable to learn how to collect indicators directly ( RUM ).
Instruments
There are many tools dedicated to measuring and web performance in general (gmetrix, pingdom, webpagetest, etc.). If we arm ourselves with Google and try a dozen of them, then we can draw the following conclusions:
- all tools have a different understanding of what “page open time” is
- there are not many hosts from which the page is opened. And for Russia - even less.
- authentication sites are very difficult to measure. There are few ways to overcome this problem.
- reports for the most part without details, everything is limited to the ladder of requests and the simplest statistics
- results are not always stable, and it is sometimes unclear why
Next, about the most practical.
WebPageTest. Of all the variety of tools, WebPageTest stands out positively . This is a hefty multi-combine, constantly evolving and producing an excellent result.
One of the most important advantages of this tool:
- the ability to deploy a local node and test their sites from the corporate network
- amazing detailed reports (including screenshots and video)
- good api
- many ways to determine the opening time of the page
About the last plus should be said separately. Here, perhaps, almost all methods are really collected. The most interesting are Speed Index and First Interactive. About the first mentioned before. And the second tells us how long after the appearance of the page will begin to respond to our actions. What if the cunning developer began to generate pictures on the server and send them to us (I hope not).
If you deploy such a solution locally, then you will cover almost all of your performance testing needs. But, alas, not all. If you still want to get the exact time of the appearance of the main content, add the ability to execute entire scripts using convenient frameworks, you have to make your own tool. What we once did.
Selenium. More out of habit than consciously, Selenium was chosen for the first pancake. Disregarding small details, the whole essence of the decision looked like this:
We translate the browser into the desired state, open the page, and begin to wait for Selenium to find the target element accessible and visible to the user. The target element is what the user expects to see: message text, article text, image, etc.
All these measurements were performed 10 times, and averaged results were calculated (eg median, arithmetic mean, ...). In general, from time to time a more or less stable result was obtained. It seems that here it is happiness, but our long-suffering forehead again faces the universal rake. It turned out that although the time was stable with one page unchanged, it began to jump unreasonably when changing this page. The video helped us figure it out. We compared two versions of the same page. The video page opened almost simultaneously (± 100 ms). And measurements through Selenium stubbornly told us that the page began to open for a second and a half longer. And stably longer.
The investigation led to the implementation of is_displayed in Selenium. The calculation of this property consisted of checking several js of the properties of the element, eg that it is in the DOM tree, that it is visible, is not of zero size, and so on. At the same time, all these checks are also carried out recursively for all parent elements. Not only do we have a very large DOM tree, but the checks themselves, being implemented on js, can be performed for a very long time at the time of opening the page due to the initialization processes of the js modules and the execution of other js code.
As a result, we decided to replace Selenium with something else. At first it was WebPageTest, but after a series of experiments, we implemented our simple and working solution.
Your bike
Since we mainly wanted to measure the time of the visual appearance of the main content on the page, we also chose measurements for the tool by taking screenshots with a frequency of 60 fps. The mechanism of the measurement itself is as follows:
Through the debug-mode, we connect to the Chrome browser, add the necessary cookies, check the environment, and launch the screenshots via the PIL in parallel on the same machine. Open the page we need in the application under test (UAT). Then we wait for the termination of significant network and visual activity with a duration of 10 seconds. After that, we save the results and artifacts: screenshots, HAR-files, Navigation Timing API and so on.
As a result, we get several hundred screenshots and process them.
Usually, after removing all duplicates from hundreds of screenshots, no more than 8 pieces remain. Now we need to calculate some diff between adjacent screenshots. Diff in the simplest case is, for example, the number of modified pixels. For greater reliability, we consider the difference not all screenshots, but only some . After that, summing all the diffs, we get the total number of changes (100%). Now we can only find a screenshot, after which> 90% of page changes occurred. The time to receive this screenshot will be the time to open the page.
Instead of connecting to Chrome via a debug protocol, you can equally well use Selenium. Since from the 63rd version, Chrome supports multiple remote debugging, we still have access to the entire set of data, and not only to those that Selenium gives us.
As soon as we had the first version of this solution, we started a series of tedious, painstaking, but very necessary tests. Yes, yes, testing tools for your products also need to be tested.
For testing, we used two main approaches:
- Creating a master page whose download time is known in advance.
- Use alternatives to determine the opening time of pages and perform a large number (> 100 for each page) measurements. Most of all there was a video of the screen.
We conduct tests regularly, because the tool itself is changing, the applications being tested are changing. When writing this article, I took one of the stable pages (the server part runs almost instantly) and conducted a series of 100 tests through 3 different approaches. Through the video measured 10 times and calculated the median.
As you can see, through the screenshots, we get a close to reality result within 10 ms of the error. But through Selenium we have a fairly strong variation with an incomprehensible release of up to 5 seconds.
Yes, again about the spherical horse in a vacuum, this is not a universal way. Such an algorithm works for us, with our products, but may not easily work for other sites. Moreover, as with many previous approaches, it is not devoid of the paradox of the observer , as in quantum physics. We can not see the result, guaranteed to not affect it. You can only reduce the degree of error.
At a minimum, the PIL also recycles some resources. But, nevertheless, this solution has been successfully used in the company for the last year. It is regularly updated, but the basic idea remains the same.
Author Sergey Dokuchaev
Source: https://habr.com/ru/post/345434/
All Articles