AI teaches the language: why do you need a hackathon on machine translation

On December 18, a qualifying round for participation in the hackathon DeepHack.Babel from the Laboratory of Neural Systems and Deep Learning of MIPT started. The focus will be on neural network machine translation, which is gaining popularity in the research community and is already being used in commercial products. Moreover, it will be necessary to train a machine translation system, in contrast to common practice, on non-parallel data — that is, in terms of machine learning, without the involvement of a teacher. If you are still thinking about registration, tell us why.
What was before
Until recently (before neural networks became popular), machine translation systems were essentially tables of translation options: for each word or phrase in the source language, a number of possible translations were made into the target language. These translations were distinguished from a large number of parallel texts (texts in two languages that are exact translations of each other) by analyzing the frequency of the joint occurrence of words and expressions. To translate a string, you had to combine translations for individual words and phrases into sentences and choose the most plausible option:
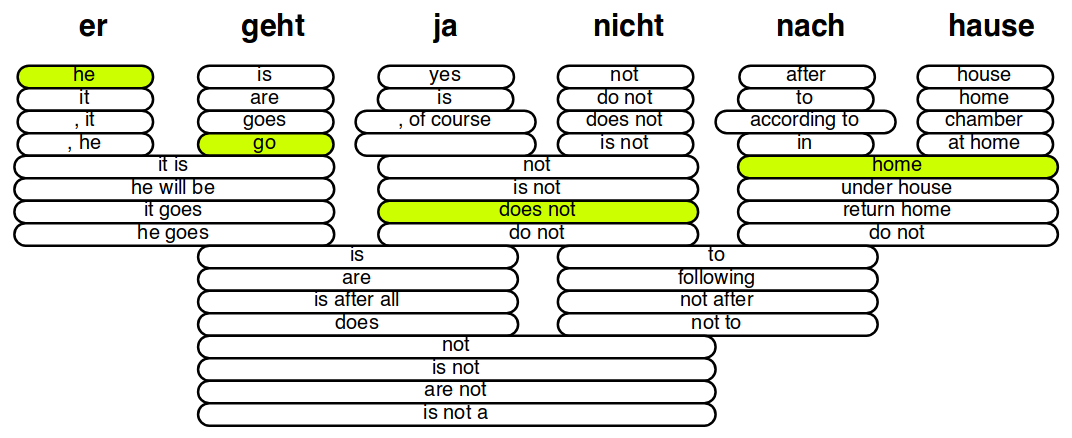
')
Options for the translation of individual words and phrases of the sentence “er geht ja nicht nach hause” (“he does not go home”) into English. The quality of variants is determined by the weighted sum of the values of the attributes, such as, for example, the probabilities p ( e | f ) and p ( f | e ), where e and f are the source and target phrases. In addition to suitable translations, you must also select the order of phrases. The illustration is taken from the Philipp Koehn presentation .
Here the second component of the machine translation system, the probabilistic model of language, came into play. Its classic version - a language model on n- grams - as well as a translation table, is based on the joint occurrence of words, but this time it is about the probability of meeting a word after a certain prefix ( n previous words). The more such a probability for each of the words of the generated sentence (that is, the less we “surprise” the language model with a choice of words), the more natural it sounds and the more likely it is the correct translation. Such a technique, despite its seemingly limited, allowed achieving a very high quality of translation - not least because the probabilistic model of the language is trained only in a monolingual (and not in a parallel) package, so it can be taught on a very large amount of data and she will be well informed about how you can talk, and how not.
What has changed with the advent of neural networks
Neural networks have changed the approach to machine translation. Now translation is made by “coding” the entire sentence into a vector representation (containing the general meaning of this sentence in a form independent of the language) and then “decoding” this representation into words in the target language. These transformations are often performed using recurrent neural networks, which are designed specifically for processing sequences of objects (in our case, sequences of words).
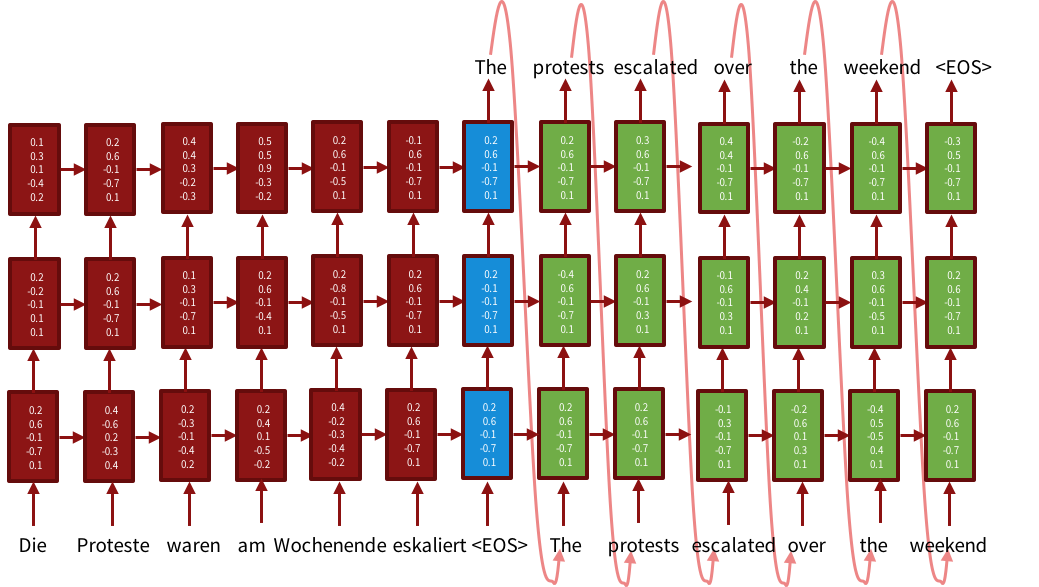
The scheme of the three-layer model encoder-decoder. The encoder (red part) generates a sentence representation: at each step, combines a new input word with a representation for the words read earlier. The blue part is the presentation of the entire sentence. The decoder (green part) outputs the word in the target language based on the representation of the original sentence and the previous generated word. The illustration is taken from the tutorial on neural network machine translation for ACL-2016.
At each step, such a neural network combines a new input word (more precisely, its vector representation) with information about the previous words. The parameters of the neural network determine how much you need to “forget”, and how much you need to “remember” at each step, so the presentation of the entire sentence contains the most important information from it. The architecture of encoder-decoder has already become classical, you can read its description, for example, in [1].
In fact, the standard version of this system does not work exactly as expected, therefore additional tricks are needed for good translation quality. For example, a recurrent network with normal cells is subject to exploding or decaying gradients (i.e., the gradients converge to zero or very large values and do not change anymore, which makes network training impossible) —the neurons of a different structure — LSTM [2] and GRU [ 3], at each step deciding what information you need to "forget" and which one to pass on. When reading long sentences, the system forgets how they started - in this case, the use of bidirectional networks helps to read the sentence from the beginning and the end at the same time, as was done in [4]. In addition, it turned out to be useful, by analogy with statistical systems, to clearly make correspondences between individual words in the original sentence and its translation — the attention mechanism already used in other tasks was used for this purpose (application of attention to machine translation is described, for example, in [4] and [5], a short and simple description of attention - in this post ). It consists in the fact that when decoding (generating a translation) the system receives information about which word of the original sentence it should translate at this step.
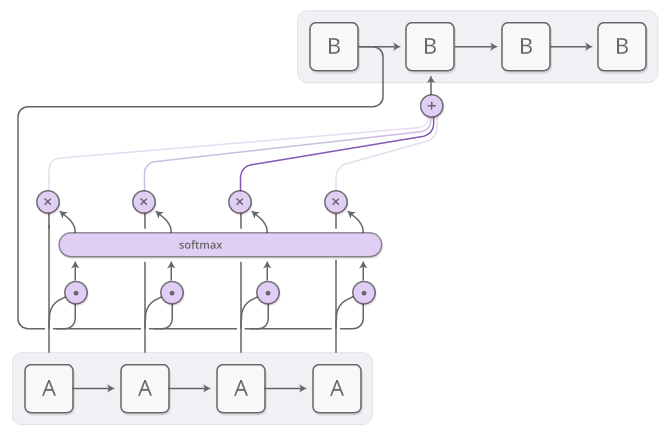
The attention mechanism in the encoder-decoder architecture. The current state of the decoder (B) is multiplied with each of the encoder states (A) - this is how we determine which of the input words is most relevant for the decoder at the moment (instead of multiplication, another operation can be used to determine the similarity). The result of this multiplication is then converted to a probability distribution by the softmax function — it returns the weight of each input word to the decoder. Combinations of the weighted states of the encoder are fed to the decoder. The illustration is taken from the post by Chris Olah.
Using all these additional techniques, machine translation on neural networks is confidently won by statistical systems: for example, at the last competition of machine translation systems, neural network models were the first in almost all pairs of languages. However, in the past statistical models there is a feature that has not yet been able to be transferred to neural networks - this is the ability to use a large amount of non-parallel data (that is, those for which there is no translation into another language).
Why use non-parallel data
One may ask, why use non-parallel data if neural network systems are good enough without them? The fact is that good quality requires a very large amount of data, which is not always available. It is known that neural networks are demanding on the amount of training data. It is easy to check that any classical method (for example, Support Vector Machines) will bypass a neural network on a very small data set. In machine translation for some of the most sought-after pairs of languages (English ⇔ main European languages, English Chinese, English ⇔ Russian) there is enough data, and neural network architectures for such pairs of languages show very good results. But where parallel data is less than a few million sentences, neural networks are useless. There are very few such richly parallel pairs of languages, but monolingual texts are available for very many languages, and in huge numbers: news, blogs, social networks, government works - new content is constantly generated. All these texts could be used to improve the quality of neural network machine translation just as they helped to improve statistical systems - but, unfortunately, such techniques have not yet been developed.
More precisely, there are several examples of teaching a neural network translation system on monolingual texts: in [6] the combination of the encoder-decoder architecture with a probabilistic language model is described, in [7] the missing translation for a monolingual corpus is generated by the model itself. All these methods improve the quality of translation, but the use of monolingual corpuses in neural network machine translation systems has not yet become common practice: it is not yet clear how to use non-parallel texts when learning, it is not clear which approach is better, or if there are differences in its use for different pairs of languages, different architectures, etc. And these are exactly the questions that we will try to solve on our DeepHack.Babel hackathon.
Non-parallel data and DeepHack.Babel
We will try to conduct controlled experiments: the participants will be given a very small set of parallel data, they will be asked to train a neural network machine translator on it, and then improve its quality using monolingual data. All participants will be on an equal footing: the same data, the same restrictions on the size and training time of the models - so we can find out which of the methods implemented by the participants work better and come closer to understanding how to improve the quality of translation for non-common pairs of languages. We will conduct experiments on several pairs of languages of different degrees of complexity in order to check how versatile different solutions are.
In addition, we will come close to an even more ambitious task that seemed impracticable by means of statistical translation: translation without parallel data. The technology of teaching translation in parallel texts is already known and perfected, although many issues related to it are not yet resolved. Comparable corpuses (pairs of texts with a common theme and similar content) are also actively used in machine translation [8] - this makes it possible to use such resources as Wikipedia (the corresponding articles in different languages do not match there literally, but describe the same objects) . But what if there is no information at all about whether the texts match each other or not? For example, when analyzing two corpuses of news for a certain year in different languages, we can be sure that the same events were discussed - this means that for most of the words of one corpus there will be a translation in the other corpus - but establish correspondences between sentences or at least between texts without additional information can not.
Is it possible to use such data? Although this seems fiction, there are already several examples in the scientific literature that this is possible - for example, a recent publication [9] describes such a system built on denoising autoencoders. Participants of the hackathon will be able to reproduce these methods and try to bypass systems trained in parallel texts.
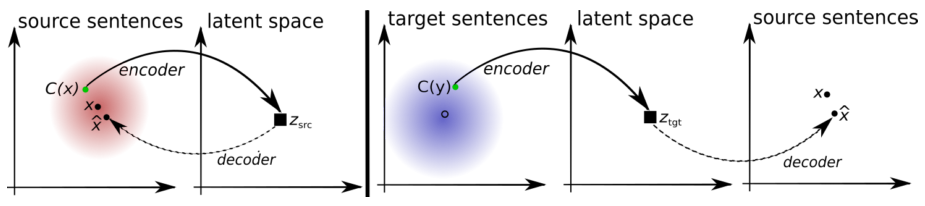
The principle of operation of the machine translation system without parallel data. Autoencoder (left): the model learns to restore the sentence from the distorted version. x is a sentence, C (x) is its distorted version, x̂ is a reconstruction. Translator (right): the model is learning to translate the sentence into another language. The input to it is a distorted translation generated by the version of the model from the previous iteration. The first version of the model is a lexicon (dictionary), also trained without the use of parallel data. The combination of the two models achieves translation quality comparable to systems trained on parallel data. The illustration is taken from the article [9].
How to participate
Applications for the qualifying round of the hackathon will be accepted until January 8. The task of the qualifying round is to train the machine translation system from English to German. There are no restrictions on data and methods yet: participants can use any buildings and pre-trained models and choose the system architecture to their own taste. However, it should be remembered that the system will be tested on a set of proposals on IT topics - this involves the use of data from relevant sources. And, although there are no restrictions on the architecture, it is assumed that when performing a qualifying task, participants will become familiar with neural network translation models in order to better cope with the main task of the hackathon.
50 people whose systems will show the best translation quality (which will be measured by the BLEU metric [10]) will be able to participate in the hackathon. Those who do not pass the selection should not be upset - they can visit the hackathon as listeners: every day there will be lectures by specialists in machine translation, machine learning and word processing, open to everyone.
Bibliography
- Sequence to Sequence Learning with Neural Networks . I.Sutskever, O.Vinyals, QVLe.
- LSTM: A Search Space Odyssey . K.Greff, RKSrivastava, J.Koutník, BRSteunebrink, J.Schmidhuber.
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation . K.Cho, BvMerrienboer, C.Gulcehre, D.Bahdanau, F.Bougares, H.Schwenk, Y.Bengio.
- Neural Machine Translation by Jointly Learning to Align and Translate . D.Bahdanau, K.Cho, Y.Bengio.
- Effective Approaches to Attention-based Neural Machine Translation . M.-T.Luong, H.Pham, CDManning.
- On Using Monolingual Corpora in Neural Machine Translation . C.Gulcehre, O.Firat, K.Xu, K.Cho, L.Barrault, H.-C.Lin, F.Bougares, H.Schwenk, Y.Bengio.
- Improving Neural Machine Translation Models with Monolingual Data . R.Sennrich, B.Haddow, A..Birch.
- Earth Mobility Distance Regularization . M.Zhang, Y.Liu, H.Luan, Y.Liu, M.Sun.
- Unsupervised Machine Translation Using Monolingual Corpora Only . G.Lample, L.Denoyer, M.Ranzato.
- BLEU: a method for automatic evaluation of machine translation . K.Papineni, S.Roukos, T.Ward, W.-J.Zhu.
Source: https://habr.com/ru/post/345318/
All Articles