How data warehouses are arranged: a review for beginners
The international market for hyper-scalable data centers is growing at an annual rate of 11%. The main “drivers” - enterprises, connected devices and users - they ensure the constant appearance of new data. Along with the volume of the market, requirements for storage reliability and data availability are growing.
The key factor influencing both criteria is storage systems. Their classification is not limited to equipment types or brands. In this article, we will look at the types of storages — block, file, and object — and determine for what purposes each of them is suitable.

/ Flickr / Jason Baker / CC
')
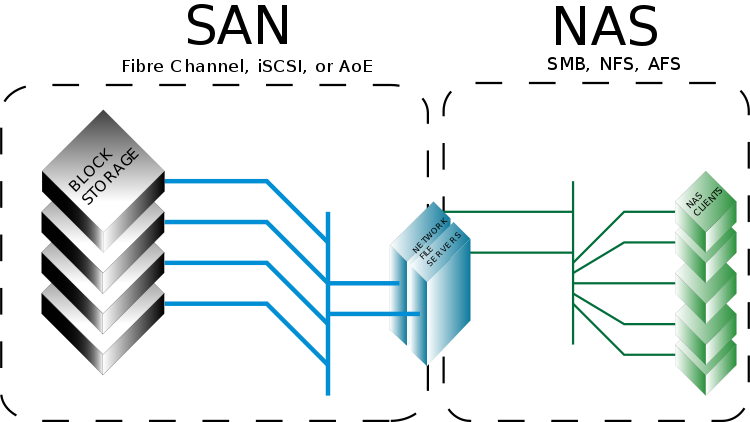
Storage at the block level underlies the operation of a traditional hard disk or magnetic tape. Files are broken up into “slices” of the same size, each with its own address, but without metadata. An example is a situation where the HDD driver writes and reads blocks at addresses on a formatted disk. Such storage systems are used by many applications, for example, by most relational DBMSs, which include Oracle, DB2, and others. In networks, access to block hosts is organized using SAN using Fiber Channel, iSCSI or AoE protocols.
The file system is the intermediate between block storage and application I / O. The most common example of file type storage is NAS. Here, the data is stored as files and folders, collected in a hierarchical structure, and accessible through client interfaces by name, directory name, etc.
/ Wikimedia / Mennis / CC
It should be noted that the separation “SAN is only network drives, and NAS is a network file system” artificially. When the iSCSI protocol appeared, the boundary between them began to blur. For example, at the beginning of zero, NetApp began to provide iSCSI on its NAS, and EMC to “put” NAS gateways on SAN arrays. This was done to improve the usability of the systems.
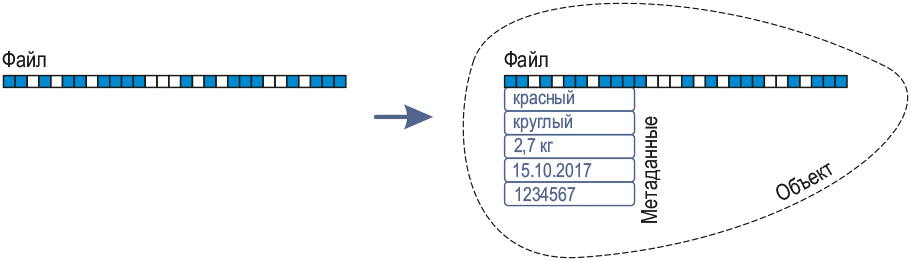
As for object storages, they differ from file and block ones by the absence of a file system. The tree structure of the file storage here replaces the flat address space. No hierarchy — just objects with unique identifiers that allow the user or client to retrieve data.
Mark Goros, CEO and Co-Founder of Carnigo, compares this method of organization with the parking service, which involves issuing a car. You just leave your car to a parking attendant who takes her to the parking lot. When you come to pick up the transport, you just show the coupon - the car is returned to you. You do not know what parking space he stood on.
Most object stores allow you to attach metadata to objects and aggregate them into containers. Thus, each object in the system consists of three elements: data, metadata, and a unique identifier — the assigned address. At the same time, object storage, unlike block storage, does not limit metadata to file attributes — here you can customize them.
/ 1cloud
Block storage has a set of tools that provide increased performance: the host bus adapter unloads the processor and frees up its resources for other tasks. Therefore, block storage systems are often used for virtualization. Also well suited for working with databases.
The disadvantages of block storage are the high cost and complexity of management. Another disadvantage of block repositories (which also applies to file storage, of which later) is the limited amount of metadata. Any additional information has to be processed at the application and database levels.
Among the advantages of file storage emit simplicity. The file is given a name, it receives metadata, and then "finds" itself a place in directories and subdirectories. File storage is usually cheaper compared to block systems, and hierarchical topology is convenient when processing small amounts of data. Therefore, with their help, file sharing systems and local archiving systems are organized.
Perhaps the main drawback of file storage is its “limitations”. Difficulties arise as a large amount of data is accumulated - it becomes difficult to find the necessary information in a pile of folders and attachments. For this reason, file systems are not used in data centers where speed is important.
As for object storages, they are well scaled, therefore, they are able to work with petabytes of information. According to statistics, the amount of unstructured data worldwide will reach 44 zettabytes by 2020, which is 10 times more than it was in 2013. Due to their ability to work with growing data volumes, object storage has become standard for most of the most popular services in the cloud: from Facebook to DropBox.
Vaults like Haystack Facebook replenish 350 million photos daily and store 240 billion media files. The total amount of this data is estimated at 357 petabytes.
Storage of copies of data is another function that object stores do well with. According to research , 70% of the information lies in the archive and rarely changes. For example, such information may be system backups that are necessary for disaster recovery.
But it is not enough just to store unstructured data, sometimes they need to be interpreted and organized. File systems have limitations in this regard: management of metadata, hierarchy, backup - all this becomes an obstacle. Object storage is equipped with internal mechanisms for checking the correctness of files and other functions that ensure the availability of data.
Flat address space is also an advantage of object storage — data located on a local or cloud server is retrieved in the same simple way. Therefore, such storage is often used to work with Big Data and media . For example, they are used by Netflix and Spotify. By the way, the capabilities of the object storage are now available in the 1cloud service.
With built-in data protection tools using object storage, you can create a reliable geographically distributed backup center. Its API is based on HTTP, so it can be accessed, for example, through a browser or cURL. To send a file to the object storage from the browser, you can write the following:
After sending, the necessary metadata is added to the file. For this there is such a request:
The rich meta-information of objects will allow optimizing the storage process and minimizing its costs. These advantages — scalability, extensibility of metadata, high-speed access to information — make object storage systems the best choice for cloud applications.
However, it is important to remember that for some operations, for example, working with transactional workloads, the efficiency of the solution is inferior to block storages. And its integration may require changes in application logic and workflows.
PS A few more materials about storing data from the 1cloud blog:
The key factor influencing both criteria is storage systems. Their classification is not limited to equipment types or brands. In this article, we will look at the types of storages — block, file, and object — and determine for what purposes each of them is suitable.
/ Flickr / Jason Baker / CC
')
Storage types and their differences
Storage at the block level underlies the operation of a traditional hard disk or magnetic tape. Files are broken up into “slices” of the same size, each with its own address, but without metadata. An example is a situation where the HDD driver writes and reads blocks at addresses on a formatted disk. Such storage systems are used by many applications, for example, by most relational DBMSs, which include Oracle, DB2, and others. In networks, access to block hosts is organized using SAN using Fiber Channel, iSCSI or AoE protocols.
The file system is the intermediate between block storage and application I / O. The most common example of file type storage is NAS. Here, the data is stored as files and folders, collected in a hierarchical structure, and accessible through client interfaces by name, directory name, etc.
/ Wikimedia / Mennis / CC
It should be noted that the separation “SAN is only network drives, and NAS is a network file system” artificially. When the iSCSI protocol appeared, the boundary between them began to blur. For example, at the beginning of zero, NetApp began to provide iSCSI on its NAS, and EMC to “put” NAS gateways on SAN arrays. This was done to improve the usability of the systems.
As for object storages, they differ from file and block ones by the absence of a file system. The tree structure of the file storage here replaces the flat address space. No hierarchy — just objects with unique identifiers that allow the user or client to retrieve data.
Mark Goros, CEO and Co-Founder of Carnigo, compares this method of organization with the parking service, which involves issuing a car. You just leave your car to a parking attendant who takes her to the parking lot. When you come to pick up the transport, you just show the coupon - the car is returned to you. You do not know what parking space he stood on.
Most object stores allow you to attach metadata to objects and aggregate them into containers. Thus, each object in the system consists of three elements: data, metadata, and a unique identifier — the assigned address. At the same time, object storage, unlike block storage, does not limit metadata to file attributes — here you can customize them.
/ 1cloud
Applicability of different types of storage systems
Block storage
Block storage has a set of tools that provide increased performance: the host bus adapter unloads the processor and frees up its resources for other tasks. Therefore, block storage systems are often used for virtualization. Also well suited for working with databases.
The disadvantages of block storage are the high cost and complexity of management. Another disadvantage of block repositories (which also applies to file storage, of which later) is the limited amount of metadata. Any additional information has to be processed at the application and database levels.
File storage
Among the advantages of file storage emit simplicity. The file is given a name, it receives metadata, and then "finds" itself a place in directories and subdirectories. File storage is usually cheaper compared to block systems, and hierarchical topology is convenient when processing small amounts of data. Therefore, with their help, file sharing systems and local archiving systems are organized.
Perhaps the main drawback of file storage is its “limitations”. Difficulties arise as a large amount of data is accumulated - it becomes difficult to find the necessary information in a pile of folders and attachments. For this reason, file systems are not used in data centers where speed is important.
Object Storage
As for object storages, they are well scaled, therefore, they are able to work with petabytes of information. According to statistics, the amount of unstructured data worldwide will reach 44 zettabytes by 2020, which is 10 times more than it was in 2013. Due to their ability to work with growing data volumes, object storage has become standard for most of the most popular services in the cloud: from Facebook to DropBox.
Vaults like Haystack Facebook replenish 350 million photos daily and store 240 billion media files. The total amount of this data is estimated at 357 petabytes.
Storage of copies of data is another function that object stores do well with. According to research , 70% of the information lies in the archive and rarely changes. For example, such information may be system backups that are necessary for disaster recovery.
But it is not enough just to store unstructured data, sometimes they need to be interpreted and organized. File systems have limitations in this regard: management of metadata, hierarchy, backup - all this becomes an obstacle. Object storage is equipped with internal mechanisms for checking the correctness of files and other functions that ensure the availability of data.
Flat address space is also an advantage of object storage — data located on a local or cloud server is retrieved in the same simple way. Therefore, such storage is often used to work with Big Data and media . For example, they are used by Netflix and Spotify. By the way, the capabilities of the object storage are now available in the 1cloud service.
With built-in data protection tools using object storage, you can create a reliable geographically distributed backup center. Its API is based on HTTP, so it can be accessed, for example, through a browser or cURL. To send a file to the object storage from the browser, you can write the following:
<form action = "[url_storage/account/container/object]" method = "post" enctype = "multipart/form-data"> <input type="hidden" name="redirect" value="[url_result]"> <input type="hidden" name="signature" value="[hmac]"> <input type="file" name="file_name"> <input type="submit"> </form> After sending, the necessary metadata is added to the file. For this there is such a request:
curl -i [url_storage/account/container/object] -X POST -H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]" The rich meta-information of objects will allow optimizing the storage process and minimizing its costs. These advantages — scalability, extensibility of metadata, high-speed access to information — make object storage systems the best choice for cloud applications.
However, it is important to remember that for some operations, for example, working with transactional workloads, the efficiency of the solution is inferior to block storages. And its integration may require changes in application logic and workflows.
PS A few more materials about storing data from the 1cloud blog:
Source: https://habr.com/ru/post/345154/
All Articles