Best CI / CD practices with Kubernetes and GitLab (review and video report)

On November 7, at the HighLoad ++ 2017 conference, in the “DevOps and Operation” section, a report “Best CI / CD Practices from Kubernetes and GitLab” was heard. In it, we share practical experience in solving problems that arise when building an effective CI / CD process based on these Open Source solutions.
By tradition, we are glad to present a video with a report (about an hour, much more informative than an article) and the main squeeze in text form.
')
CI / CD and key requirements
By CI / CD (Continuous Integration, Continuous Delivery, Continuous Delivery), we understand all the stages of delivering code from a Git repository to production and its subsequent maintenance until it is “removed” from production. The existing interpretations of the CI / CD terms allow for a different attitude towards this last stage (operation in production), but our experience says that excluding it from CI / CD leads to numerous problems.
Before describing specific practices, we summarized the main factors that influence the complexity of CI / CD:
- How is the main process built? The options are: one or more environments, dynamic environments, several distributed sites.
- How is testing done? Run the code analyzer, unit tests without environment (ie, without runtime dependencies), functional / integration / component tests in the environment, tests in the “full” environment for microservices (end-to-end, regression).
- What separation of rights is required? Simple (just write code / roll out for certain users), different rights for environments, multi-stage approval (the team leader allows rollouts to the stage, and QA for production), a collegial solution.
- What is the architecture of the application ? Stateless service, stateful application, multi-component application, microservice architecture.
All of these options are summarized in a general graph, which illustrates what tools can be used to close various needs:
There are other, more general (but no less important!) Requirements for CI / CD:

Finally, we, as a company implementing and maintaining the CI / CD system, have additional requirements for the products used:
- they should be Open Source (this is our “outlook on life”, and the practical side of the issue: the availability of code, the absence of restrictions in the application);
- “ Multi-scale ” (products must work equally efficiently in companies with one developer and with fifty);
- interoperability (compatibility with each other, independence from the equipment supplier, cloud provider, etc.);
- ease of use ;
- focus on the future (we must be sure not only that the products are suitable now, but also have prospects for development).
CI / CD Solutions
The stack of products that meet all requirements, we have the following:
- GitLab;
- Docker;
- Kubernetes;
- Helm (for managing packages in Kubernetes);
- dapp (our open source utility to simplify / improve the build and deployment processes).
And the total CI / CD cycle from Git to operation using the listed tools looks like this:
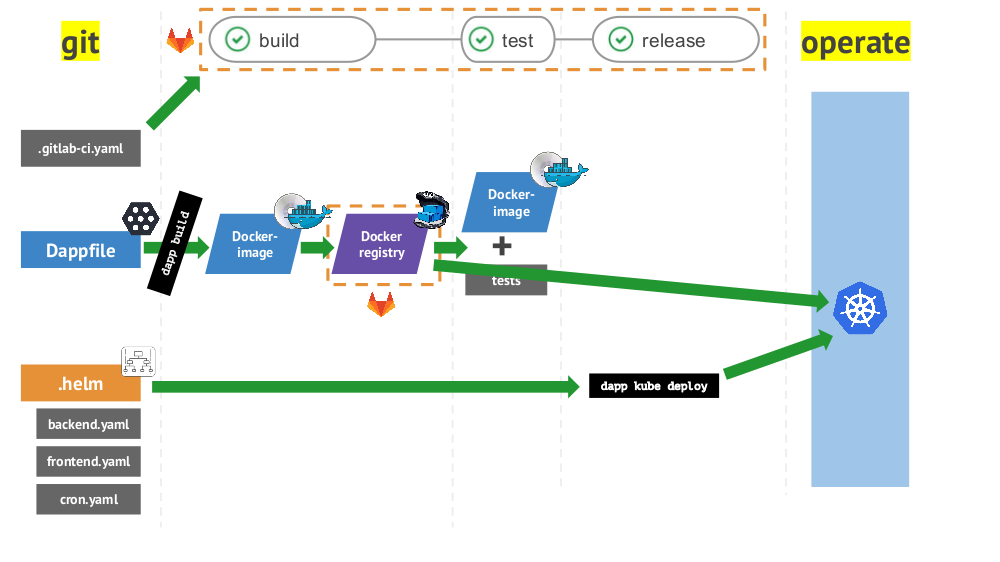
Practices
№1. Composition of the Docker image
The image must contain everything that is required for the application to work:
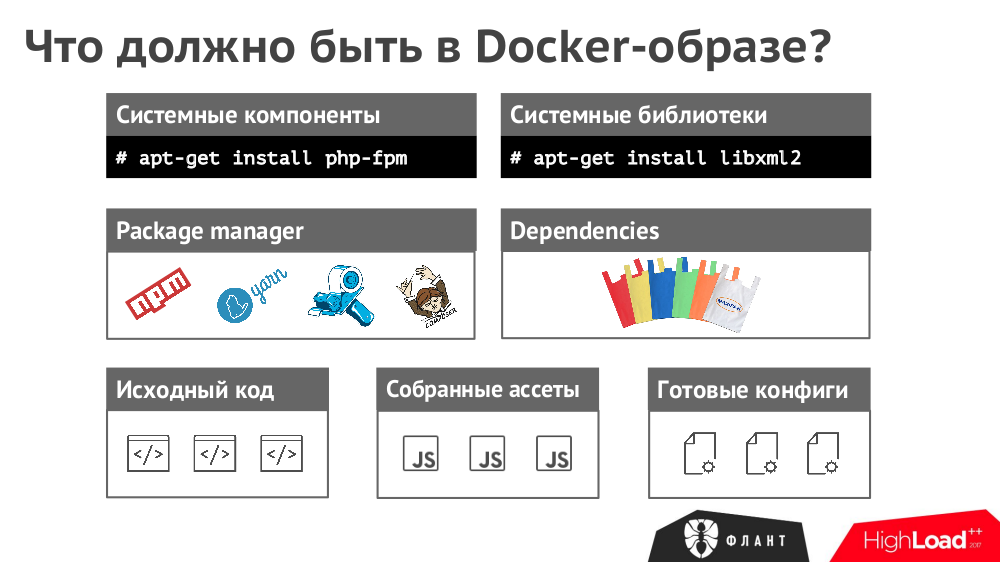
№2. One image for everything
Once assembled, a Docker image should be used everywhere. Otherwise, the QA may not be checked by the same thing that will be downloaded to production (reassembled at another point in time).
We collect temporary images from the
git branch and release images from the git tag :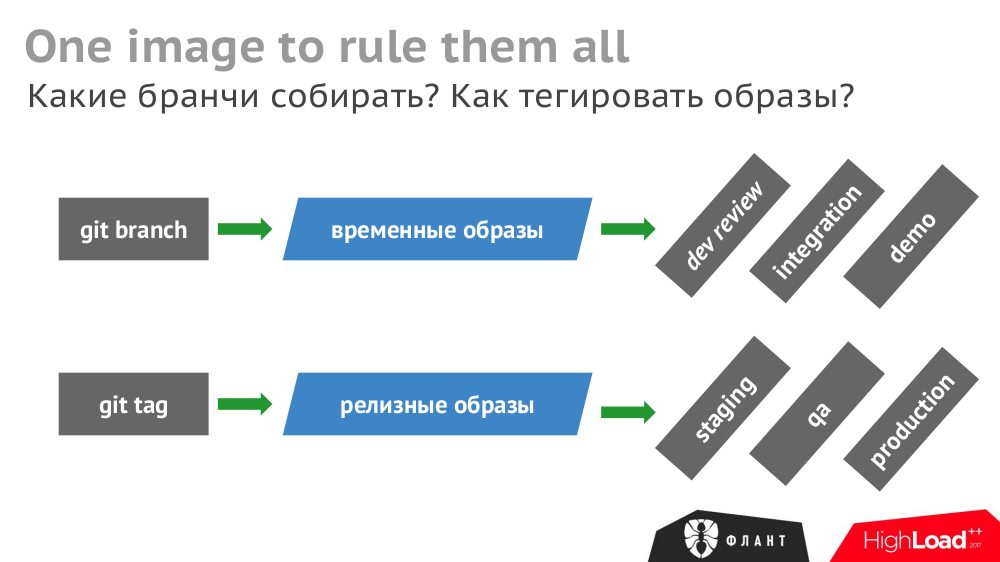
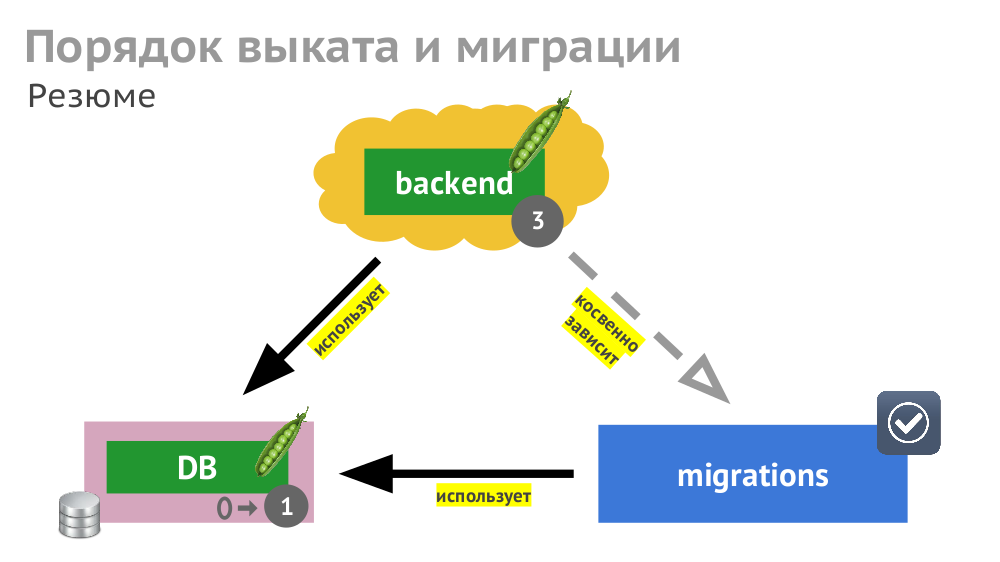
Number 3. Rollout and migration
The operation of the various components described in Kubernetes (backend as Deployment , DBMS as StatefulSet , etc.) may depend on each other. In the case of a “rectilinear” rollout, the K8s will update the components and restart them (in the case of an unsuccessful start):
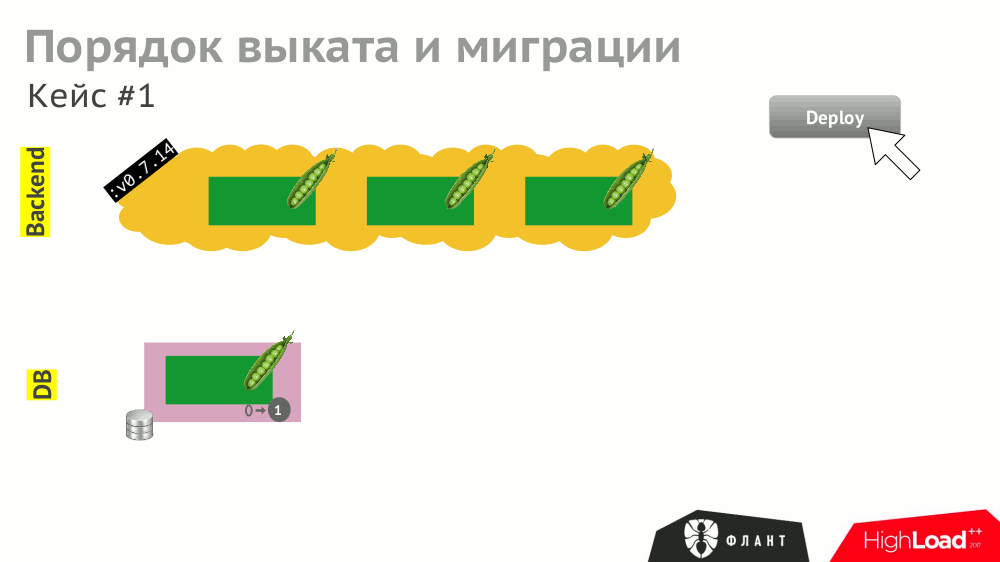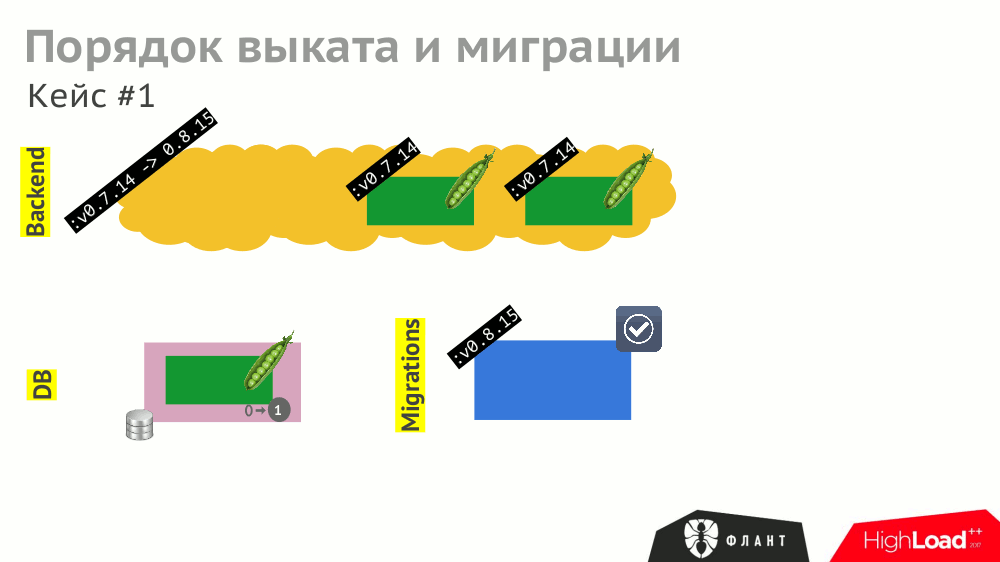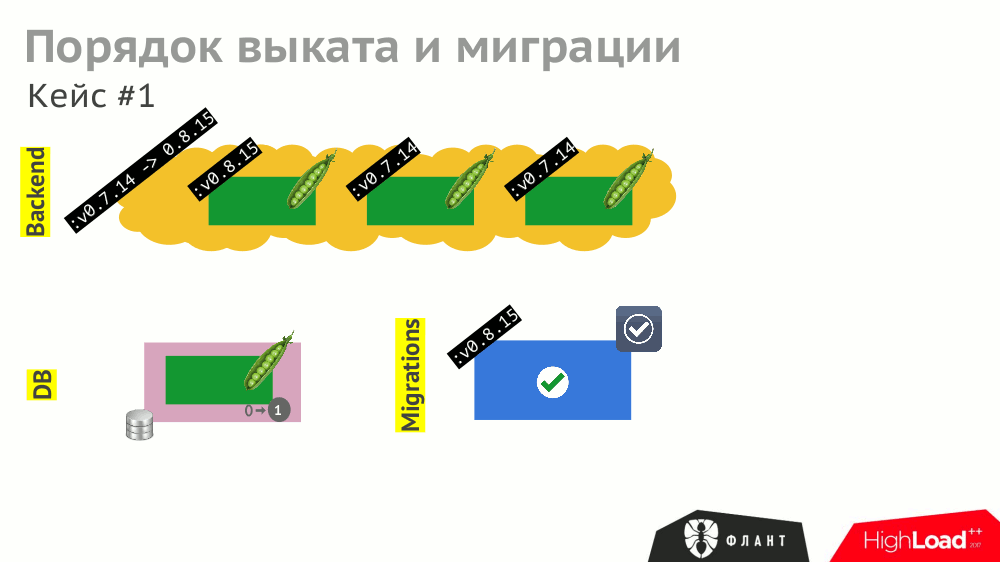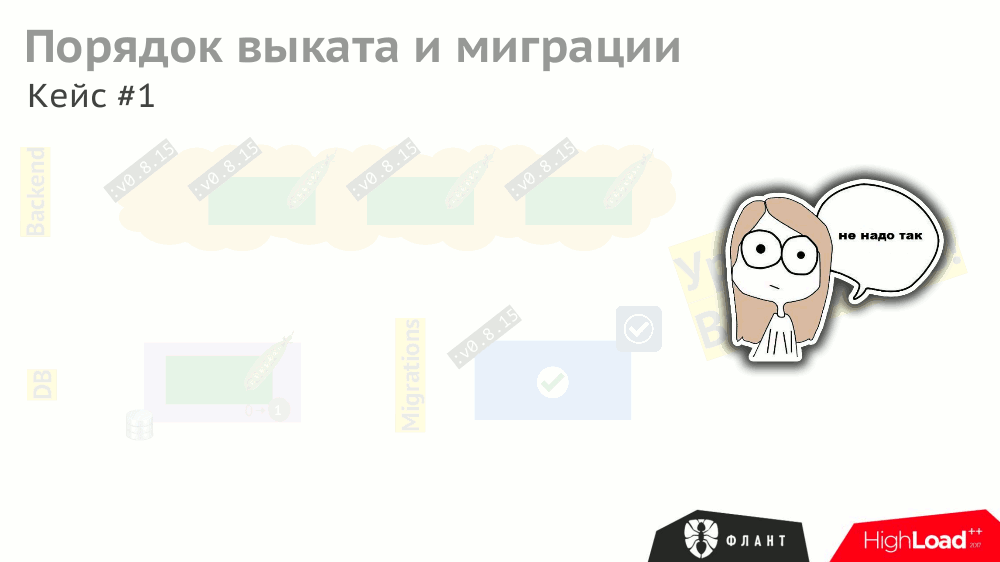
And even if all these events are correctly processed by the components (which should also be foreseen), the overall roll-out time will be delayed due to different timeouts in Kubernetes that are triggered (and accumulated) due to the need to wait for other services to start (for example, the backend is waiting for the updated database to be available ie, with the migration).
To shorten the roll-out time, you need to take into account (and prescribe) not only explicit dependencies between components (the backend is waiting for the availability of the DBMS), but also indirect ones (the backend should not be updated before the migrations).
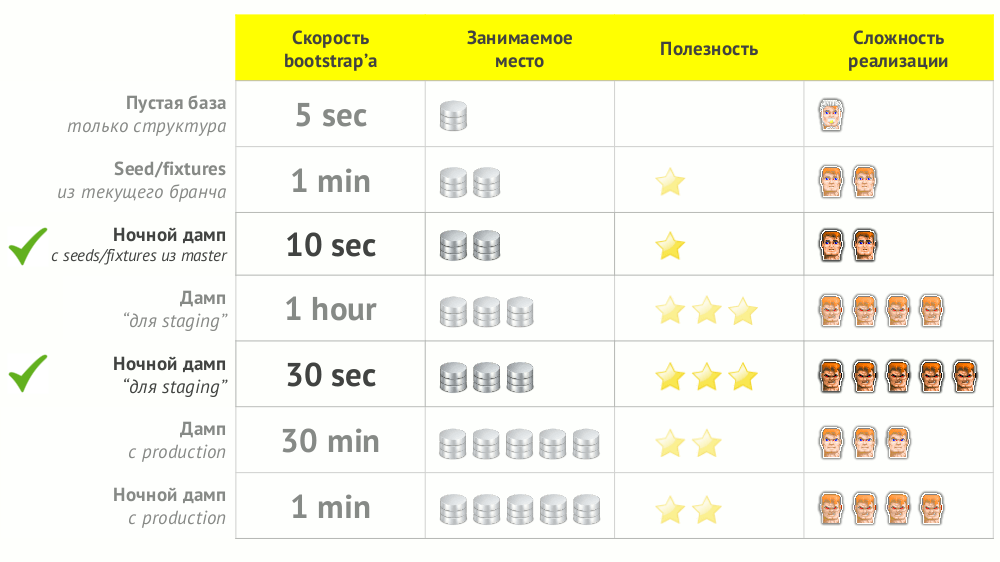
№4. Bootstrap DB
DBMS is filled with data in two ways: loading the finished dump or loading the seeds / fixtures. The path to Kubernetes for the first case is after starting the DBMS to start the job ( Job ), which loads the dump. After that, the launch of migrations (they are indirectly dependent on the dump), and then the launch of the backend (indirectly dependent on migrations).
The launch sequence for a case with sids changes and looks like this: 1) DBMS, 2) migrations, 3) task with sidami, 4) backend (can be run in parallel with sidami, since it should not depend on sids).

After going through the various paths of the bootstrap database, we came to the optimality of two: a night dump with seeds / fixtures from the master and a night dump for staging.
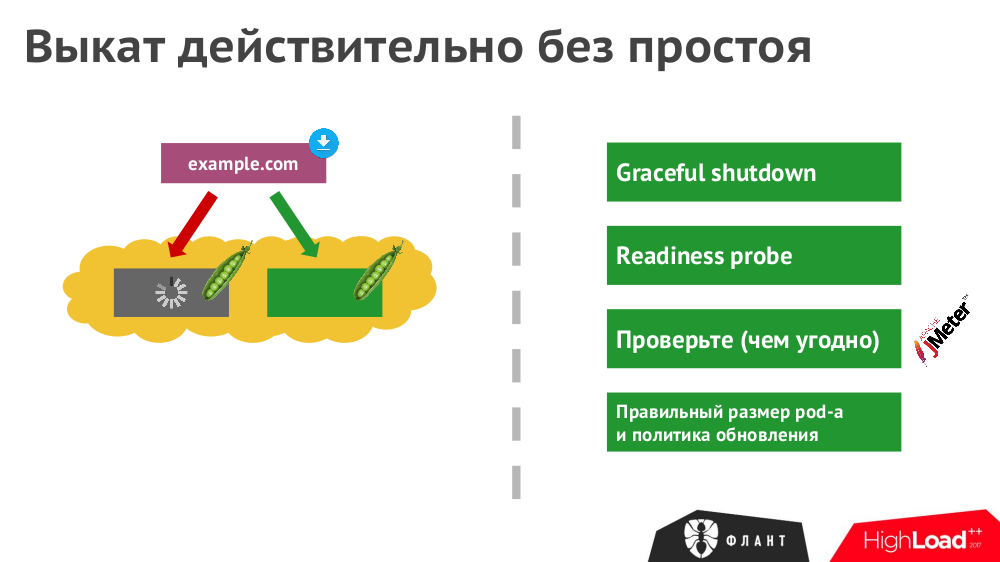
№5. Vykat without idle
Even with the correct deployment of new versions of the application in Kubernetes, not all the nuances will be automatically taken into account. To truly guarantee complete absence of downtime:
- Do not forget about the correct completion of all HTTP requests,
- check the actual availability of the application (open port) using the readiness probes specified in K8s,
- Simulate load during deployment (check if all requests have been completed)
- consider the performance margin of the pods available in the infrastructure at the time of deployment.
№6. "Atomicity" roll out
If an error has occurred during the update of any infrastructure component (the update could not roll out), a notification will be given in the GitLab pipelines, but the infrastructure itself will remain in a state of transition. The problem component will not retain the original (old) version, as GitLab "thinks", but will be able to not completely rolling out the new version.
The problem is solved by using the built-in rollback feature in the event of such an error. And most likely it should be provided only in production, since In dev-contours, you are likely to want to look at the problem component in its transition state (to understand the causes of the problem).
№7. Dynamic environments
The built-in capabilities in GitLab allow for git push of any branch (if there is a Helm chart for a full bootstrap infrastructure) to deploy an application installation (with the same namespace) ready for use in Kubernetes. Similarly, there will be a deletion of the namespace when deleting a branch.
However, with the active use of this feature, the resources required for the infrastructure are expanding rapidly. Therefore, there are several recommendations for optimizing dynamic environments:

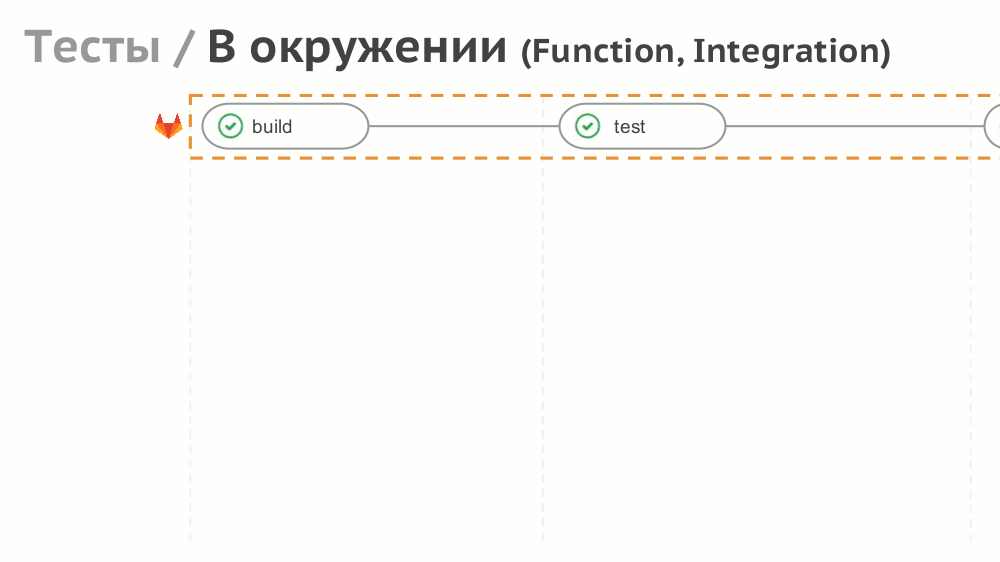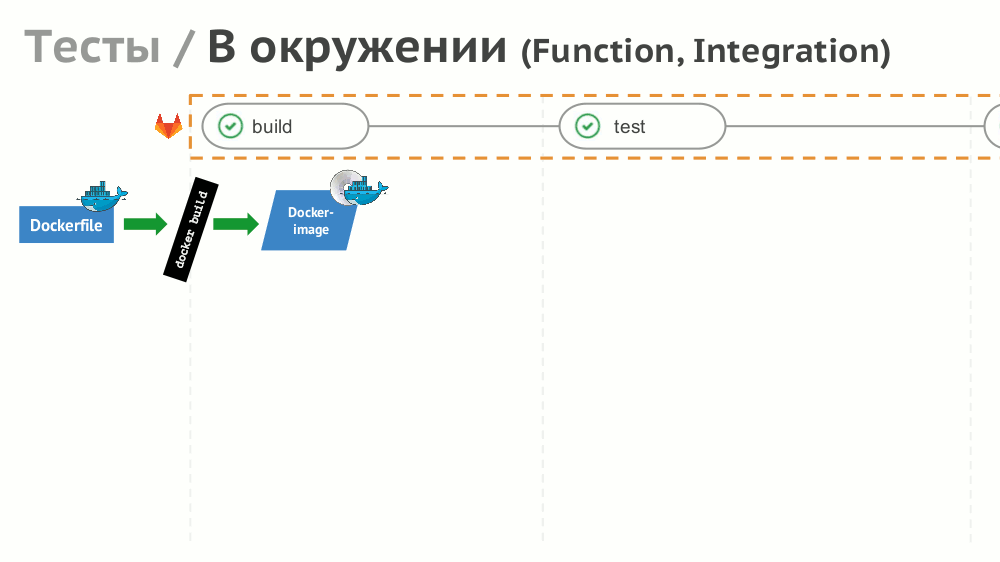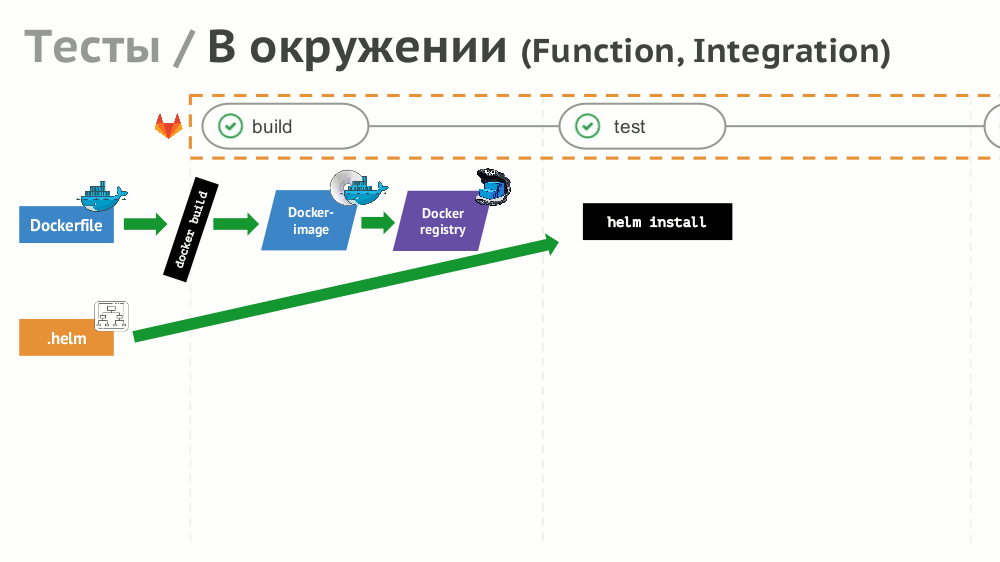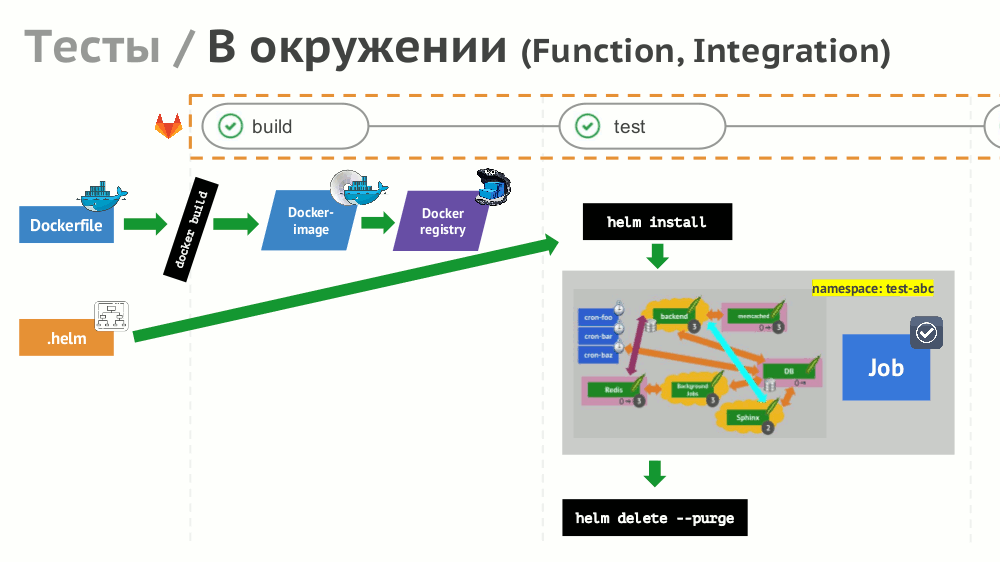
№8. Tests
If the implementation of simple tests (not needing an environment) is simple, then for functional and integration testing we suggest creating a dynamic environment with the help of Helm:
Results
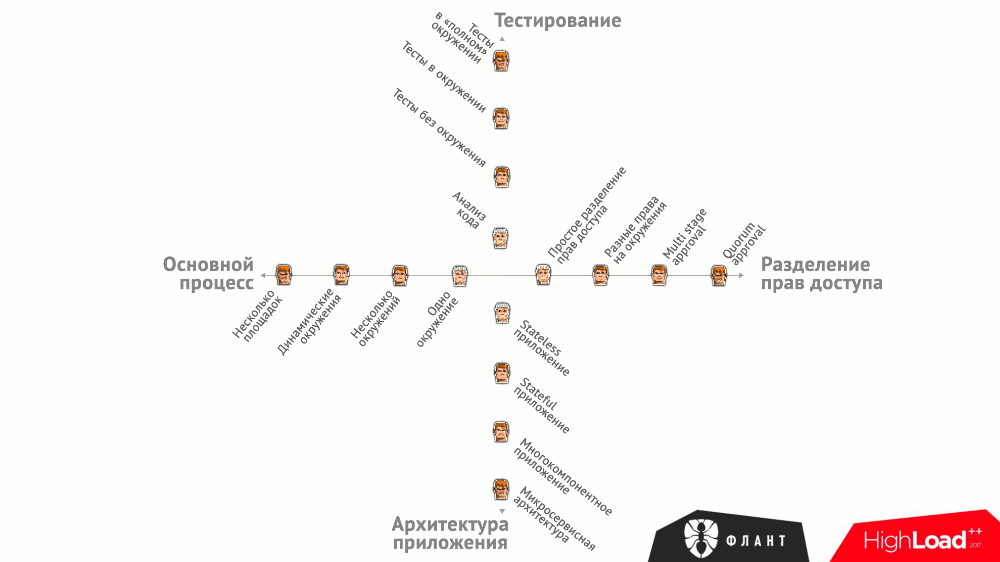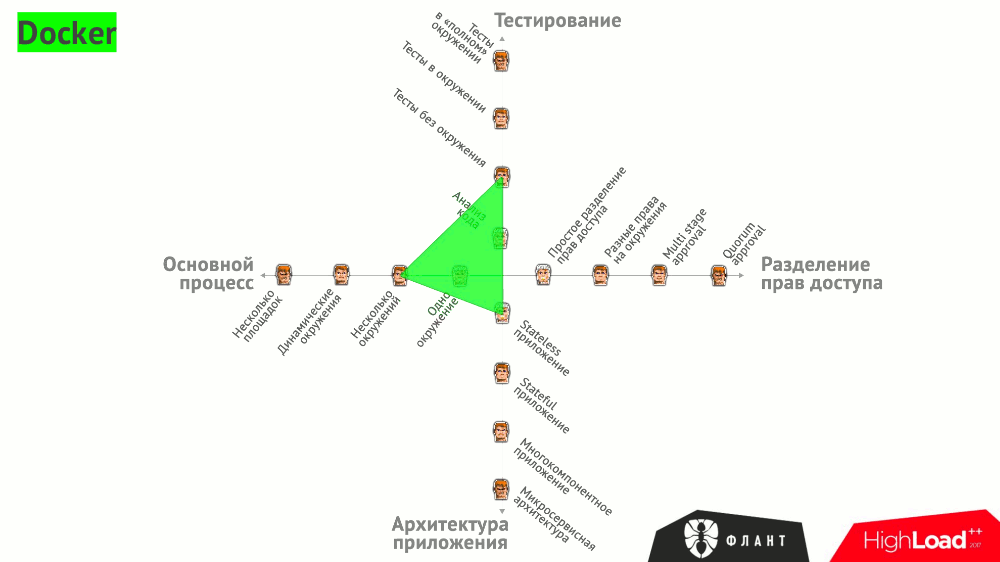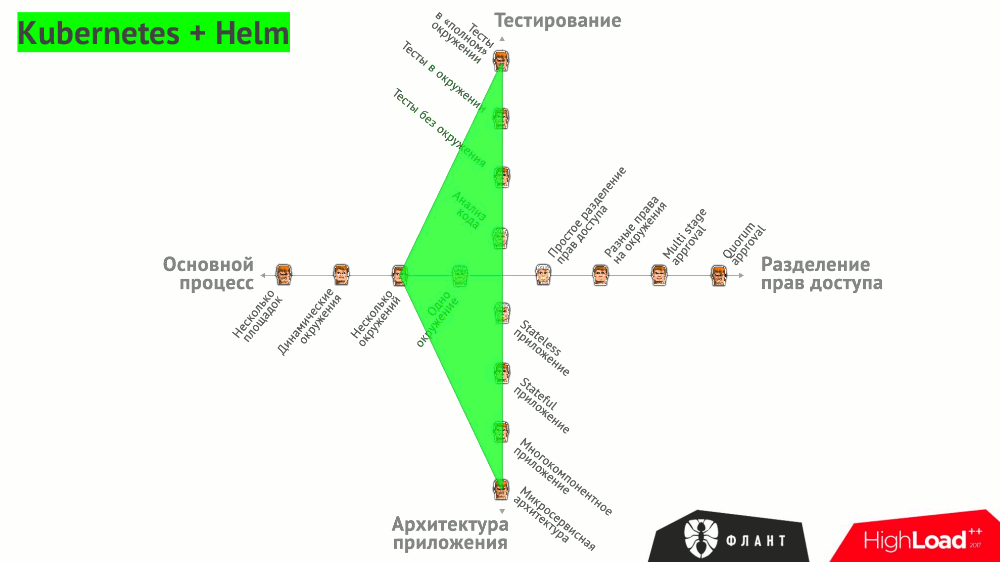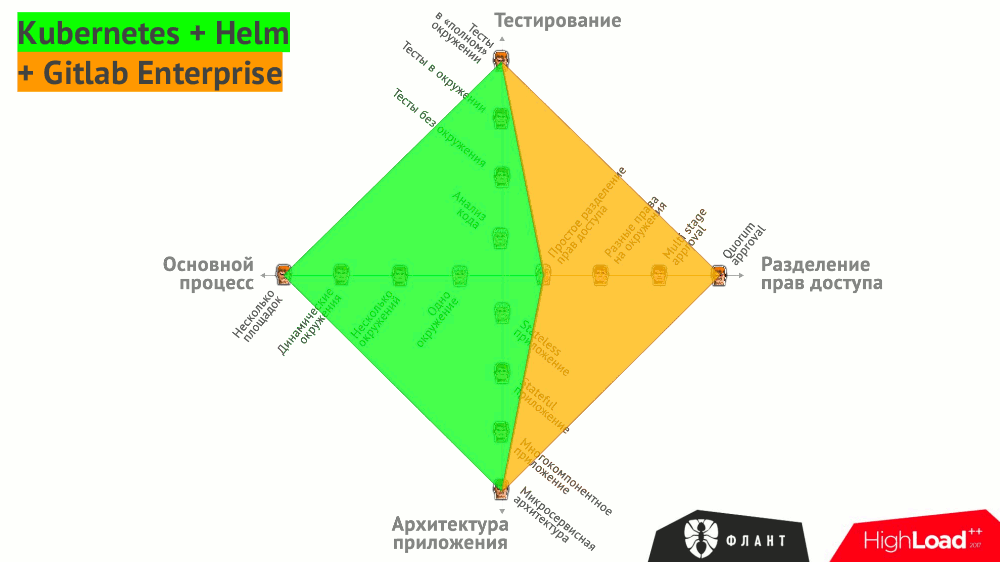
Returning to the initial schedule with the requirements for CI / CD ...
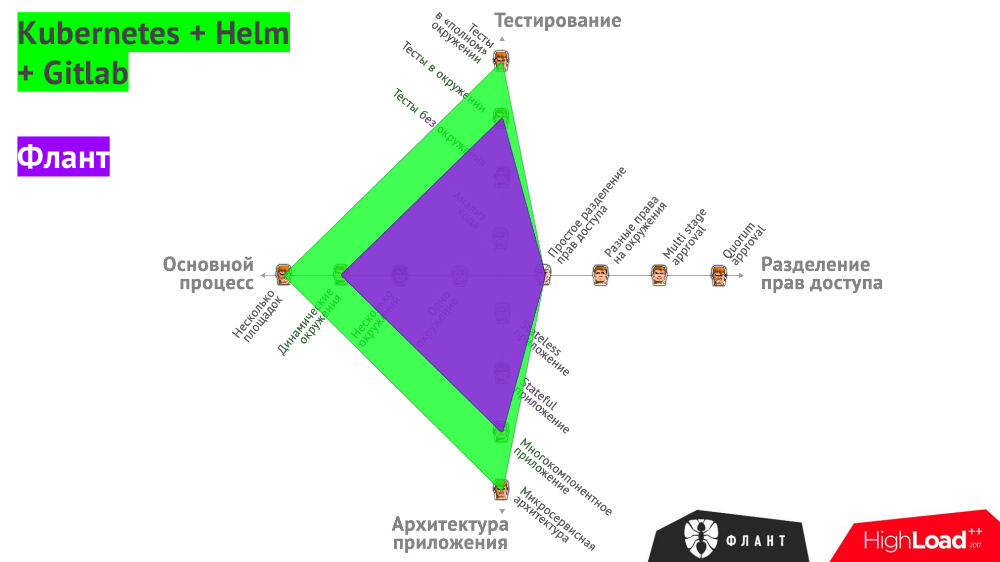
The described practices based on Open Source-products allow solving problems marked in green. Violet highlighted the area of problems with which we work in the company “Flant” literally every day.
Video and slides
Video from the performance (about an hour) published on YouTube .
Presentation of the report:
PS
Other reports on our blog:
- " Databases and Kubernetes "; (Dmitry Stolyarov; November 8, 2018 on HighLoad ++) ;
- “ Monitoring and Kubernetes ”; (Dmitry Stolyarov; May 28, 2018 on RootConf) ;
- “ Our experience with Kubernetes in small projects (review and video report) ”; (Dmitry Stolyarov; June 6, 2017 at RootConf) ;
- “ We assemble Docker images for CI / CD quickly and conveniently along with dapp ” (Dmitry Stolyarov; November 8, 2016 on HighLoad ++) ;
- “ Practices of Continuous Delivery with Docker ” (Dmitry Stolyarov; May 31, 2016 at RootConf) .
You may also be interested in the following publications:
Source: https://habr.com/ru/post/345116/
All Articles