How to analyze the tone of tweets using machine learning in PHP
All good!
Well, as promised, we are sharing with you another material that we studied as part of the preparation of our PHP course . We hope that it will be interesting and useful for you.
Introduction
')
Recently, it seems that everyone and everyone is talking about machine learning. Your feeds in social networks are filled with messages about ML, Python, TensorFlow, Spark, Scala, Go, and so on; and if we have something in common with you, then you can ask, but what about PHP?
Yes, how about machine learning and PHP? Fortunately, someone was crazy enough not only to ask this question, but also to develop a universal library of machine learning, which we can use in our next project. In this post we will look at PHP-ML - a library for machine learning in PHP - and we will write a tonality analysis class that we can later use for our own chat or tweet bot. The main objectives of this post are:

What is machine learning?
Machine learning is a subset of the field of artificial intelligence research that focuses on providing "computers the opportunity to learn without being precisely programmed." This is achieved by using common algorithms that can “learn” from a specific data set.
For example, one of the common ways to use machine learning is classification. Classification algorithms are used to place data in different groups or categories. Some examples of classification applications:
Machine learning is a general term that encompasses many universal algorithms for different tasks. There are two main types of algorithms, classified according to how they learn - learning with a teacher and learning without a teacher.
Teaching with a teacher
In training with the teacher, we train our algorithm using the training data in the form of an input object (vector) and the desired output value; The algorithm analyzes learning data and creates a so-called target function, which we can apply to a new, unmarked data set.
In the rest of this post, we will focus on learning with the teacher, simply because it is clearer and easier to check relationships; Keep in mind that both algorithms are equally important and interesting; others argue that learning without a teacher is more useful because it eliminates the need for training data.
Teaching without a teacher
This type of training, on the contrary, works without training data from the very beginning. We do not know the desired resulting data set values, and we allow the algorithm to draw conclusions only from the sample; Learning without a teacher is especially convenient for identifying hidden patterns in data.
PHP-ML
I present to you PHP-ML, a library that claims to be a new approach to machine learning in PHP. The library implements algorithms, neural networks and tools for data preprocessing, cross-checking and feature extraction.
I will be the first to notice that PHP is an unusual choice for machine learning, since language strengths are not well suited for machine learning implementations. However, not all machine learning applications need to process petabytes of data and do massive computations — for simple applications, PHP and PHP-ML should be enough for us
The best use that I can provide for this library right now is to implement the classifier, be it something like a spam filter or even text tonality analysis. We are going to define the classification problem and work out a solution step by step to find out how we can use PHP-ML in our projects.
Task
To illustrate the process of implementing PHP-ML and add some machine learning to our applications, I wanted to find an interesting problem to solve and the best way to demonstrate the classifier is to create a class for analyzing the tonalities of the tweets.
One of the key requirements for creating successful machine learning projects is a reliable source data set. Data sets are crucial because they allow us to train our classifier on already classified examples. Since there has been a lot of noise in the media around the airlines lately, what could be better than tweets from airline customers?
Fortunately, the data in the form of a set of tweets are already available to us thanks to Kaggle.io . Using this link you can download the US Airline Sentiment twitter database from their website.
Decision
Let's start by exploring the dataset we're working on. The raw dataset has the following columns:
And it looks like in the example :
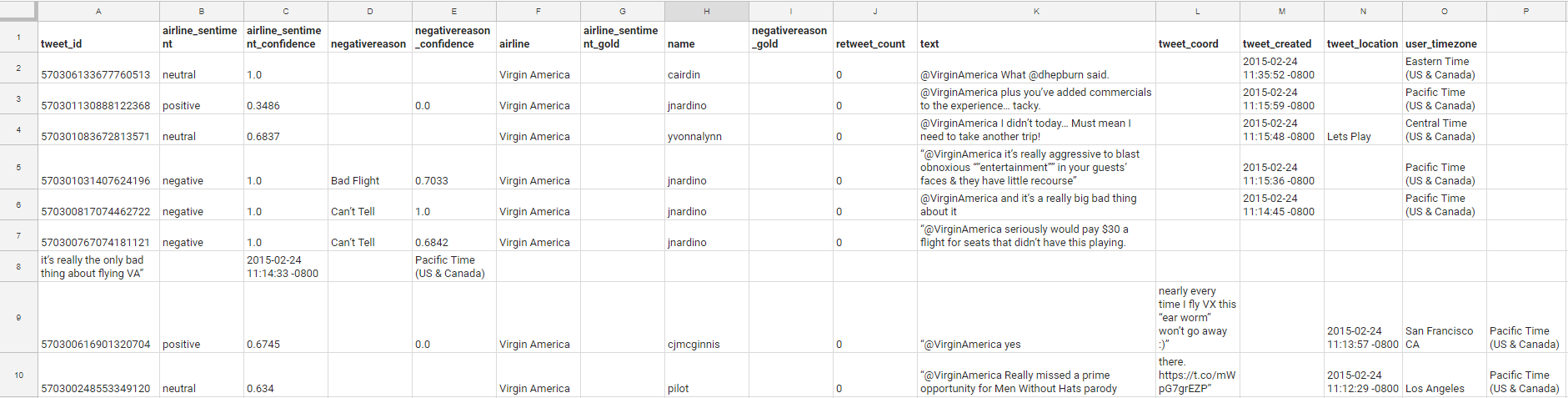
The file contains 14,640 tweets - for us this is a sufficient set of data. Now, with so many columns available to us, we have more data than we need for our example; for practical purposes, we are only interested in the following columns:
Where
If you need an introduction to Composer, see here .
To make sure that we installed everything correctly, let's create a quick script that will load our data file
Now run the
So far this does not look useful, does it? Let's look at the
The
If you look a little closer, we will see that the class divides the CSV file into two internal arrays: samples and targets. The samples contain all the functions provided by the file, and the targets contain known values (negative, positive or neutral).
Based on the foregoing, we can see that the format our CSV file should follow looks like this:
We will need to create a clean dataset only with those columns with which we need to continue working. Let's call this script
Nothing complicated, enough to do this work. Let's do it with
Now let's move on and point our reviewDataset.php script to a clean data set:
Bam! This is the data we can work with! So far, we have created simple scripts for data management. Next we create a new class in
Our Sentiment class will need two functions in our tonality analysis class:
At the root of the project, create a script
Step 1. Loading a dataset
We already have the base code we can use to load the CSV into the data object from our previous examples. We will use the same code with a few minor changes:
Here an array is created that contains only properties — in this case, the tweet text that we are going to use to train our classifier.
Step 2: Preparing the dataset
Now the transfer of raw text to the classifier will lead to a loss of benefit and accuracy, since tweets are significantly different from each other. Fortunately, there are ways to work with text when trying to apply classification or machine learning algorithms. In this example, we will use the following two classes:
Let's start with our text vectorizer:
Then apply the Tf-idf Transformer:
Our sample array is now in a format that our classifier understands. We have not finished yet, we need to mark each sample with an appropriate mood.
Step 3. Creating a set of training materials
Fortunately, PHP-ML already knows how to do this, and the code is pretty simple:
We could use this data set and train our classifier. However, we lack the test data set to use as a test, so we are going to “read” a little and divide our original data set into two: a set of training materials and a much smaller data set that will be used to check the accuracy of our model.
This approach is called cross validation. This term comes from statistics and can be defined as follows:
Step 4: Classifier Training
Finally, we are ready to go back and implement our class SentimentAnalysis. If you have not noticed, a huge part of machine learning is related to the collection and processing of data; the actual implementation of machine learning models tends to be much less involved.
We have three classification algorithms to implement a sentiment analysis class:
For this exercise, we will use the simplest of all, the NaiveBayes classifier, so let's continue and change our class to implement the learning function:
As you can see, we let PHP-ML do all the hard work for us. We simply create a small abstraction for our project. But how do we know if our classifier really trains and works? Time to use our
Step 5: Classifier Accuracy Check
Before we can continue testing our classifier, we need to implement a prediction method:
And once again, PHP-ML helps us out. Let's change the classifyTweets class as follows:
Finally, we need a way to verify the accuracy of our learning model; fortunately, PHP-ML does this, too, and they have several metric classes. In our case, we are interested in the accuracy of the model. Let's look at the code:
We should see something like:
Conclusion
This article is too big, so let's repeat what we learned:
This post also served as an introduction to the PHP-ML library and, I hope, gave you an idea of what the library can do and how it can be built into your own projects.
Finally, this post is by no means comprehensive, and there are many opportunities to learn, improve, and experiment; Here are some ideas for you to talk about how to develop the direction:
THE END
As always, we are waiting for your comments and opinions.
Well, as promised, we are sharing with you another material that we studied as part of the preparation of our PHP course . We hope that it will be interesting and useful for you.
Introduction
')
Recently, it seems that everyone and everyone is talking about machine learning. Your feeds in social networks are filled with messages about ML, Python, TensorFlow, Spark, Scala, Go, and so on; and if we have something in common with you, then you can ask, but what about PHP?
Yes, how about machine learning and PHP? Fortunately, someone was crazy enough not only to ask this question, but also to develop a universal library of machine learning, which we can use in our next project. In this post we will look at PHP-ML - a library for machine learning in PHP - and we will write a tonality analysis class that we can later use for our own chat or tweet bot. The main objectives of this post are:
- Exploring general concepts related to machine learning and text analysis
- PHP-ML features and disadvantages overview
- Definition of the problem that we will solve.
- Proof that a PHP machine learning attempt is not a completely insane target (optional)
What is machine learning?
Machine learning is a subset of the field of artificial intelligence research that focuses on providing "computers the opportunity to learn without being precisely programmed." This is achieved by using common algorithms that can “learn” from a specific data set.
For example, one of the common ways to use machine learning is classification. Classification algorithms are used to place data in different groups or categories. Some examples of classification applications:
- Post spam filters
- Market segmentation packages
- Fraud protection systems
Machine learning is a general term that encompasses many universal algorithms for different tasks. There are two main types of algorithms, classified according to how they learn - learning with a teacher and learning without a teacher.
Teaching with a teacher
In training with the teacher, we train our algorithm using the training data in the form of an input object (vector) and the desired output value; The algorithm analyzes learning data and creates a so-called target function, which we can apply to a new, unmarked data set.
In the rest of this post, we will focus on learning with the teacher, simply because it is clearer and easier to check relationships; Keep in mind that both algorithms are equally important and interesting; others argue that learning without a teacher is more useful because it eliminates the need for training data.
Teaching without a teacher
This type of training, on the contrary, works without training data from the very beginning. We do not know the desired resulting data set values, and we allow the algorithm to draw conclusions only from the sample; Learning without a teacher is especially convenient for identifying hidden patterns in data.
PHP-ML
I present to you PHP-ML, a library that claims to be a new approach to machine learning in PHP. The library implements algorithms, neural networks and tools for data preprocessing, cross-checking and feature extraction.
I will be the first to notice that PHP is an unusual choice for machine learning, since language strengths are not well suited for machine learning implementations. However, not all machine learning applications need to process petabytes of data and do massive computations — for simple applications, PHP and PHP-ML should be enough for us
The best use that I can provide for this library right now is to implement the classifier, be it something like a spam filter or even text tonality analysis. We are going to define the classification problem and work out a solution step by step to find out how we can use PHP-ML in our projects.
Task
To illustrate the process of implementing PHP-ML and add some machine learning to our applications, I wanted to find an interesting problem to solve and the best way to demonstrate the classifier is to create a class for analyzing the tonalities of the tweets.
One of the key requirements for creating successful machine learning projects is a reliable source data set. Data sets are crucial because they allow us to train our classifier on already classified examples. Since there has been a lot of noise in the media around the airlines lately, what could be better than tweets from airline customers?
Fortunately, the data in the form of a set of tweets are already available to us thanks to Kaggle.io . Using this link you can download the US Airline Sentiment twitter database from their website.
Decision
Let's start by exploring the dataset we're working on. The raw dataset has the following columns:
- tweet_id
- airline_sentiment
- airline_sentiment_confidence
- negativereason
- negativereason_confidence
- airline
- airline_sentiment_gold
- name
- negativereason_gold
- retweet_count
- text
- tweet_coord
- tweet_created
- tweet_location
- user_timezone
And it looks like in the example :
The file contains 14,640 tweets - for us this is a sufficient set of data. Now, with so many columns available to us, we have more data than we need for our example; for practical purposes, we are only interested in the following columns:
- text
- airline_sentim
Where
text is a property, and airline_sentiment is a target. The remaining columns can be discarded because they will not be used for our exercise. Start by creating a project and initializing the builder using the following file: { "name": "amacgregor/phpml-exercise", "description": "Example implementation of a Tweet sentiment analysis with PHP-ML", "type": "project", "require": { "php-ai/php-ml": "^0.4.1" }, "license": "Apache License 2.0", "authors": [ { "name": "Allan MacGregor", "email": "amacgregor@allanmacgregor.com" } ], "autoload": { "psr-4": {"PhpmlExercise\\": "src/"} }, "minimum-stability": "dev" } composer installIf you need an introduction to Composer, see here .
To make sure that we installed everything correctly, let's create a quick script that will load our data file
Tweets.csv and make sure that it contains the data we need. Copy the following code as reviewDataset.php to the root of our project: <?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('datasets/raw/Tweets.csv',1); foreach ($dataset->getSamples() as $sample) { print_r($sample); } Now run the
reviewDataset.php script, and look at the result: Array( [0] => 569587371693355008 ) Array( [0] => 569587242672398336 ) Array( [0] => 569587188687634433 ) Array( [0] => 569587140490866689 ) So far this does not look useful, does it? Let's look at the
CsvDataset class to better understand what's going on inside: <?php public function __construct(string $filepath, int $features, bool $headingRow = true) { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, 'rb')) { throw FileException::cantOpenFile(basename($filepath)); } if ($headingRow) { $data = fgetcsv($handle, 1000, ','); $this->columnNames = array_slice($data, 0, $features); } else { $this->columnNames = range(0, $features - 1); } while (($data = fgetcsv($handle, 1000, ',')) !== false) { $this->samples[] = array_slice($data, 0, $features); $this->targets[] = $data[$features]; } fclose($handle); } The
CsvDataset constructor takes three arguments:- Source CSV File Path
- An integer specifying the number of properties in our file.
- Boolean value indicating whether the first row is a header
If you look a little closer, we will see that the class divides the CSV file into two internal arrays: samples and targets. The samples contain all the functions provided by the file, and the targets contain known values (negative, positive or neutral).
Based on the foregoing, we can see that the format our CSV file should follow looks like this:
| feature_1 | feature_2 | feature_n | target | We will need to create a clean dataset only with those columns with which we need to continue working. Let's call this script
generateCleanDataset.php : <?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Exception\FileException; $sourceFilepath = __DIR__ . '/datasets/raw/Tweets.csv'; $destinationFilepath = __DIR__ . '/datasets/clean_tweets.csv'; $rows =[]; $rows = getRows($sourceFilepath, $rows); writeRows($destinationFilepath, $rows); /** * @param $filepath * @param $rows * @return array */ function getRows($filepath, $rows) { $handle = checkFilePermissions($filepath); while (($data = fgetcsv($handle, 1000, ',')) !== false) { $rows[] = [$data[10], $data[1]]; } fclose($handle); return $rows; } /** * @param $filepath * @param string $mode * @return bool|resource * @throws FileException */ function checkFilePermissions($filepath, $mode = 'rb') { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, $mode)) { throw FileException::cantOpenFile(basename($filepath)); } return $handle; } /** * @param $filepath * @param $rows * @internal param $list */ function writeRows($filepath, $rows) { $handle = checkFilePermissions($filepath, 'wb'); foreach ($rows as $row) { fputcsv($handle, $row); } fclose($handle); } Nothing complicated, enough to do this work. Let's do it with
phpgenerateCleanDataset.php .Now let's move on and point our reviewDataset.php script to a clean data set:
Array ( [0] => @AmericanAir That will be the third time I have been called by 800-433-7300 an hung on before anyone speaks. What do I do now??? ) Array ( [0] => @AmericanAir How clueless is AA. Been waiting to hear for 2.5 weeks about a refund from a Cancelled Flightled flight & been on hold now for 1hr 49min ) Bam! This is the data we can work with! So far, we have created simple scripts for data management. Next we create a new class in
src/class/SentimentAnalysis.php . <?php namespace PhpmlExercise\Classification; /** * Class SentimentAnalysis * @package PhpmlExercise\Classification */ class SentimentAnalysis { public function train() {} public function predict() {} } Our Sentiment class will need two functions in our tonality analysis class:
- A training function that will accept samples and data set labels, as well as some additional parameters.
- A prediction function that will take an unmarked data set and assign a label set based on the training data.
At the root of the project, create a script
classifyTweets.php . We will use it to create and test our class of analysis of tonalities. Here is the template we will use: <?php namespace PhpmlExercise; use PhpmlExercise\Classification\SentimentAnalysis; require __DIR__ . '/vendor/autoload.php'; // Step 1: Load the Dataset // Step 2: Prepare the Dataset // Step 3: Generate the training/testing Dataset // Step 4: Train the classifier // Step 5: Test the classifier accuracy Step 1. Loading a dataset
We already have the base code we can use to load the CSV into the data object from our previous examples. We will use the same code with a few minor changes:
<?php ... use Phpml\Dataset\CsvDataset; ... $dataset = new CsvDataset('datasets/clean_tweets.csv',1); $samples = []; foreach ($dataset->getSamples() as $sample) { $samples[] = $sample[0]; } Here an array is created that contains only properties — in this case, the tweet text that we are going to use to train our classifier.
Step 2: Preparing the dataset
Now the transfer of raw text to the classifier will lead to a loss of benefit and accuracy, since tweets are significantly different from each other. Fortunately, there are ways to work with text when trying to apply classification or machine learning algorithms. In this example, we will use the following two classes:
- Token Count Vectorizer: This class converts a collection of sample text into a vector of tokens. In fact, every word on our twitter becomes a unique number and tracks the number of occurrences of a word in a particular text sample.
- Tf-idf Transformer: abbreviation for term frequency - inverse document frequency (word frequency - the inverse frequency of the word in the document), is a numeric statistic used to assess the importance of a word in the context of a document that is part of a document collection or corpus.
Let's start with our text vectorizer:
<?php ... use Phpml\FeatureExtraction\TokenCountVectorizer; use Phpml\Tokenization\WordTokenizer; ... $vectorizer = new TokenCountVectorizer(new WordTokenizer()); $vectorizer->fit($samples); $vectorizer->transform($samples); Then apply the Tf-idf Transformer:
<?php ... use Phpml\FeatureExtraction\TfIdfTransformer; ... $tfIdfTransformer = new TfIdfTransformer(); $tfIdfTransformer->fit($samples); $tfIdfTransformer->transform($samples); Our sample array is now in a format that our classifier understands. We have not finished yet, we need to mark each sample with an appropriate mood.
Step 3. Creating a set of training materials
Fortunately, PHP-ML already knows how to do this, and the code is pretty simple:
<?php ... use Phpml\Dataset\ArrayDataset; ... $dataset = new ArrayDataset($samples, $dataset->getTargets()); We could use this data set and train our classifier. However, we lack the test data set to use as a test, so we are going to “read” a little and divide our original data set into two: a set of training materials and a much smaller data set that will be used to check the accuracy of our model.
<?php ... use Phpml\CrossValidation\StratifiedRandomSplit; ... $randomSplit = new StratifiedRandomSplit($dataset, 0.1); $trainingSamples = $randomSplit->getTrainSamples(); $trainingLabels = $randomSplit->getTrainLabels(); $testSamples = $randomSplit->getTestSamples(); $testLabels = $randomSplit->getTestLabels(); This approach is called cross validation. This term comes from statistics and can be defined as follows:
Cross-validation (cross-validation, sliding control, English cross-validation) is a method for evaluating an analytical model and its behavior on independent data. In evaluating the model, the available data is divided into k parts. Then, the model is trained at the k − 1 parts of the data, and the rest of the data is used for testing. The procedure is repeated k times; as a result, each of the k pieces of data is used for testing. The result is an assessment of the effectiveness of the selected model with the most uniform use of available data.- Wikipedia.com
Step 4: Classifier Training
Finally, we are ready to go back and implement our class SentimentAnalysis. If you have not noticed, a huge part of machine learning is related to the collection and processing of data; the actual implementation of machine learning models tends to be much less involved.
We have three classification algorithms to implement a sentiment analysis class:
- Support Vector Machine
- K-closest neighbors method (KNearestNeighbors)
- Naive Bayes Classifier (NaiveBayes)
For this exercise, we will use the simplest of all, the NaiveBayes classifier, so let's continue and change our class to implement the learning function:
<?php namespace PhpmlExercise\Classification; use Phpml\Classification\NaiveBayes; class SentimentAnalysis { protected $classifier; public function __construct() { $this->classifier = new NaiveBayes(); } public function train($samples, $labels) { $this->classifier->train($samples, $labels); } } As you can see, we let PHP-ML do all the hard work for us. We simply create a small abstraction for our project. But how do we know if our classifier really trains and works? Time to use our
testSamples and testLabels .Step 5: Classifier Accuracy Check
Before we can continue testing our classifier, we need to implement a prediction method:
<?php ... class SentimentAnalysis { ... public function predict($samples) { return $this->classifier->predict($samples); } } And once again, PHP-ML helps us out. Let's change the classifyTweets class as follows:
<?php ... $predictedLabels = $classifier->predict($testSamples); Finally, we need a way to verify the accuracy of our learning model; fortunately, PHP-ML does this, too, and they have several metric classes. In our case, we are interested in the accuracy of the model. Let's look at the code:
<?php ... use Phpml\Metric\Accuracy; ... echo 'Accuracy: '.Accuracy::score($testLabels, $predictedLabels); We should see something like:
Accuracy: 0.73651877133106% Conclusion
This article is too big, so let's repeat what we learned:
- Having a good data set from the start is crucial to the implementation of machine learning algorithms.
- The difference between learning with a teacher and without.
- The value and use of cross-validation in machine learning.
- What vectorization and transformation is necessary to prepare textual data sets for machine learning.
- How to implement the analysis of the mood of tweets using the classifier NaiveBayes PHP-ML.
This post also served as an introduction to the PHP-ML library and, I hope, gave you an idea of what the library can do and how it can be built into your own projects.
Finally, this post is by no means comprehensive, and there are many opportunities to learn, improve, and experiment; Here are some ideas for you to talk about how to develop the direction:
- Replace the NaiveBayes algorithm with the support vector method.
- If you try to run the full dataset (14,000 lines), you will probably notice how much memory load will increase. Try to implement the constancy of the model so that it does not need to be trained in each run.
- Move the dataset generation to your own helper class.
THE END
As always, we are waiting for your comments and opinions.
Source: https://habr.com/ru/post/345082/
All Articles