Netflix selects the best movie covers for each viewer.
From the blog Netflix Technology
For many years, the main goal of the Netflix personal recommendation system was to choose the right movies — and offer them to users on time. With thousands of films in the catalog and diverse customer preferences across hundreds of millions of accounts, it is critical to recommend accurate films to each of them. But the work of the recommendation system does not end there. What can be said about a new and unfamiliar film that will arouse your interest? How to convince you that he is worthy of viewing? It is very important to answer these questions to help people discover new content for themselves, especially unfamiliar films.
One of the solutions to the problem is to take into account pictures or covers for films. If the picture looks convincing, then it serves as a push and some kind of visual "proof" that the film is worth watching. It can depict an actor known to you, an exciting moment like a car chase or a dramatic scene that captures the essence of a movie or a series. If we show the perfect movie cover on your home page (as they say, a picture is worth a thousand words), then maybe, just maybe, you decide to choose this movie. This is just one more thing in which Netflix differs from traditional media: we have not one product, but more than 100 million different products, and each user receives personal recommendations and personalized covers .
')

Netflix home page without covers. So historically, our recommendation algorithms have seen the page
In a previous paper, we discussed how to find one perfect cover for each film for all users. Using the algorithms of multi-armed bandits, we searched for the best cover for a particular movie or series, for example, “Very Strange Things” (Stranger Things). This picture provided the maximum number of views from the maximum number of our users. But given the incredible variety of tastes and preferences - would not it be better to choose the optimal picture for each of the viewers to emphasize aspects of the film that are important specifically for him ?

The covers of the sci-fi series “Very Strange Things,” each of which has chosen our personalization algorithm for more than 5% of hits. Different pictures show the breadth of topics in the series and go beyond what a single cover can show.
For inspiration, let's take a look at options where personalizing covers makes sense. Consider the following examples where different users have different histories of watched movies. On the left of the three films that people watched in the past. To the right of the arrow is the cover that we will recommend to him.
Let's try to choose a personal picture for the film "Good Will Hunting." Here we can derive a solution based on the extent to which the user prefers different genres and themes. If a person watched a lot of romantic movies, “Good Will Hunting” can attract his attention with a picture of Matt Damon and Minnie Driver. And if a person watched a lot of comedies, then he might be interested in this film after seeing the image of Robbie Williams, a famous comedian.

In another case, let’s imagine how different preferences regarding the cast can affect the personalization of the cover for “Pulp Fiction”. If a user watched a lot of movies with Uma Thurman, then he is more likely to respond positively to the cover of "Pulp Fiction" with Uma. At the same time, a fan of John Travolta may be more interested in watching a movie if he sees John on the cover.

Of course, not all cover customization tasks are so easy to solve. So let's not rely on manually written rules, but rely on signals from the data. In general, with the help of customization of covers, we help each individual image to pave the best path to each user, thereby improving the quality of the service.
At Netflix, we algorithmically adapt many aspects of the site’s work for each user individually, including the rows on the main page , the films for these rows , the galleries for display, our messages, and so on. Every new aspect that we personalize brings new challenges. Personalization of covers is not an exception, there are unique problems here.
One of the problems is that we can only use a single copy of the image for display to the user. In contrast, the typical settings of the recommendations allow the user to demonstrate different options , so that we can gradually explore his preferences based on the choices made. This means that the choice of a picture is the problem of a chicken and eggs in a closed cycle: a person chooses films only with pictures that we decided to choose for him. What we are trying to understand is when showing a particular cover pushed a person to watch a movie (or not), and when a person would watch a movie (or not) regardless of the cover. Therefore, customization of covers combines different algorithms together. Of course, to properly personalize covers, you need to collect a lot of data in order to find signals about which particular copies of covers have a significant advantage over the rest for a particular user.
Another problem is to understand the impact of changing the cover we show the user in different sessions. Does changing the cover of the film reduce the visibility of the film and make it more difficult to visualize it, for example, if the user has previously become interested in the film, but has not watched it yet? Or does changing the cover contribute to changing the solution thanks to an improved picture selection? Obviously, if we found the best cover for this person, it should be used; but constant changes can confuse the user. Changing pictures cause an attribution problem, since it becomes unclear which cover has generated interest in the film for the user.
Further, there is the problem of understanding how the covers interact on one page or in one session. Maybe the bold close-up of the main character is effective for the film, because it stands out among other covers on the page. But if all the covers have similar characteristics, the page as a whole will lose its appeal. It may not be enough to consider each cover separately and you need to think about choosing a different set of covers on a page or during a session. In addition to neighboring covers, the effectiveness of each specific cover may also depend on what other facts and resources (for example, synopsis, trailers, etc.) we show for this film. A variety of combinations appear in which each object emphasizes additional aspects of the film, increasing the chances of a positive impact on the viewer.
Effective personalization requires a good set of covers for each movie. This means that different resources are required, each of which is attractive, informative and indicative of a film in order to avoid clickbate. The set of images for the film should also be diverse enough to cover a wide potential audience interested in various aspects of the content. In the end, how attractive and informative a particular cover depends on the individual person who sees it. Therefore, we need artwork, emphasizing not only different themes in the film, but also different aesthetics. Our groups of artists and designers as they can try to create pictures that are diverse in all respects. They take into account the personalization algorithms that select pictures during the creative process of their creation.
Finally, engineers have the task of providing personalization of covers on a large scale. The site is actively using images - and therefore there are a lot of pictures on it. So the personalization of each resource means processing at the peak of more than 20 million requests per second with a small delay. Such a system should be reliable: incorrect rendering of the cover in our UI will significantly worsen the impression of the site. Our personalization engine should also respond quickly to the release of new films, that is, quickly master personalization in a cold start situation. Then, after the launch, the algorithm must continuously adapt, since the effectiveness of the covers may change over time - this depends on the film's life cycle and on the changing tastes of the audience.
Netflix's recommendation engine is largely based on machine learning algorithms. Traditionally, we collect a lot of data about the use of the service by users. Then we launch a new machine learning algorithm on this data package. Then we test it in production through A / B tests on a random sample of users. Such tests make sure that the new algorithm is better than the current system in production. The users in group A are given the current system in production, and the users in group B are the result of the new algorithm. If group B demonstrates greater involvement in the work of the Netflix service, then we roll out a new algorithm to the entire audience. Unfortunately, with this approach, many users for a long time can not use the new system, as shown in the illustration below.

To reduce the period of time unavailability of the new service, we abandoned the batch method of machine learning in favor of the online method. To personalize the covers, we use a specific framework for machine learning - contextual bandits (contextual bandits). Instead of waiting for a complete data packet to be collected, waiting for the model to learn, and then waiting for the A / B tests to complete, contextual thugs quickly determine the best choice of movie cover for each user and context. In short, contextual gangs are a class of machine learning algorithms online that compensate for the costs of collecting the training data needed for continuous learning of an unbiased model with the advantages of using the trained model in the context of each user. In our previous work on choosing the best cover without personalization, we used non-context thugs who found the best cover regardless of context. In the case of personalization, the context of a particular user is taken into account, since each of them perceives each image differently.
The key feature of context thugs is that they reduce the service unavailability period. At a high level, data for contextual gunman learning comes in through the introduction of controlled randomization into the predictions of the trained model. Randomization schemes can be of varying complexity: from simple epsilon-greedy algorithms with a uniform distribution of randomness to closed-loop schemes that adaptively change the degree of randomization, which is a function of the uncertainty of the model parameters. We broadly call this process the study of data . The choice of strategy for the study depends on the number of candidate covers in the presence and the number of users for whom the system is being deployed. With this data study, it is necessary to record information about the randomization of each cover choice. This log allows you to correct distorted deviations from the selection and, thus, impartially carry out an autonomous assessment of the model, as described below.
The study of data with contextual thugs usually comes at a price, since the choice of cover during a user session may with some probability not coincide with the most optimal predicted cover for this session. How does such randomization affect the impression of working with the site (and, consequently, our metrics)? Based on more than 100 million users, losses due to exploring data are usually very small and are amortized over a large user base, since each user implicitly helps provide feedback for the covers in a small part of the catalog. This makes insignificant losses due to the examination of data for each user, which is important to take into account when choosing contextual thugs for a key aspect of user interaction with the site. Randomizing and exploring data with contextual thugs would be less attractive in case of greater losses.
In our online learning scheme, we get a data set for learning, where for each element of a set of interrelated data (user, film, cover) it is indicated whether such a choice led to the decision to watch a movie or not. Moreover, we can control the process of learning in such a way that the choice of covers does not change too often. This gives a clearer attribution of the attractiveness of a particular cover for the user. We also carefully monitor the indicators and avoid the "clickbate" when teaching the model to recommend certain covers, as a result of which the user starts watching the movie, but in the end remains unsatisfied.
In this online learning setting, we train the context gangster model to choose the best cover for each user, depending on their context. We usually have dozens of candidate covers for each film. To train the model, we can simplify the problem by making a ranking of the covers. Even with this simplification, we still get information about the user's preferences, since each candidate cover is liked by some users and disliked by others. These preferences are used to predict the effectiveness of each triad (user, film, cover). The best prediction with the study of data gives a competent balance of learning models with a teacher or contextual thugs with Thompson Sampling, LinUCB or Bayesian methods.
In context models, the context is usually represented as a feature vector, which is used as input to the model. On the role of signs fit many signals. In particular, these are many user attributes: watched movies, movie genres, user interaction with a particular movie, his country, language, device used, time of day and day of the week. Since the algorithm selects the covers along with the movie recommendation engine, we can also use signals that various recommendation algorithms think about the title, regardless of the cover.
An important consideration is that some images are obviously better in their own right than others in the pool of candidates. We mark the total share of views ( take rates ) for all images in the data study. These coefficients simply represent the number of quality views divided by the number of impressions. In our previous work on the selection of covers without personalization, the image was chosen according to the overall efficiency coefficient for the entire audience. In the new contextual personalization model, the overall factor is still important and is taken into account when selecting the cover for a specific user.
After the above learning model, it is used to rank the images in each context. The model predicts the likelihood of viewing a film for a given cover in a given user context. According to these probabilities, we sort the set of candidate covers and choose the one that gives the highest probability. We show it to a specific user.
Our contextual bandit algorithms before rolling out online are first evaluated offline using a technique known as replay [1]. This method allows you to answer hypothetical questions based on records in the data study log (Fig. 1). In other words, we can compare offline what would happen in historical sessions in different scenarios using different algorithms in an unbiased way.
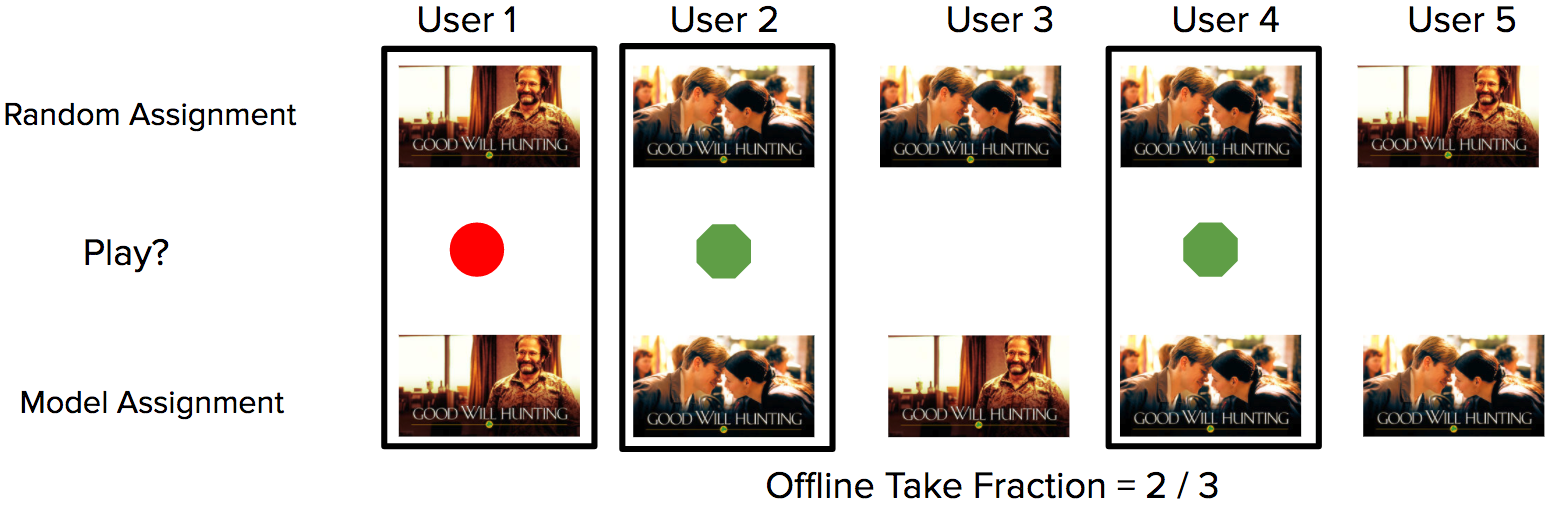
Fig. 1. A simple example of calculating the replay metric based on data from the log. Each user is assigned a random image (top row). The system registers in the log the showing of the cover and the fact whether the user launched the movie for playback (green circle) or not (red). The metric for a new model is calculated by comparing profiles, where random assignments and model assignments are the same (black square) and calculating the share of successful launches in this subset (take fraction).
The replay metric shows how much the percentage of users who launched a movie will change when using a new algorithm compared to the algorithm that is used in production now. For the covers, we are interested in several metrics, including the success rate described above. In fig. Figure 2 shows how contextual thug helps to increase the share of launches in a directory compared to a random choice or a non-contextual thug.
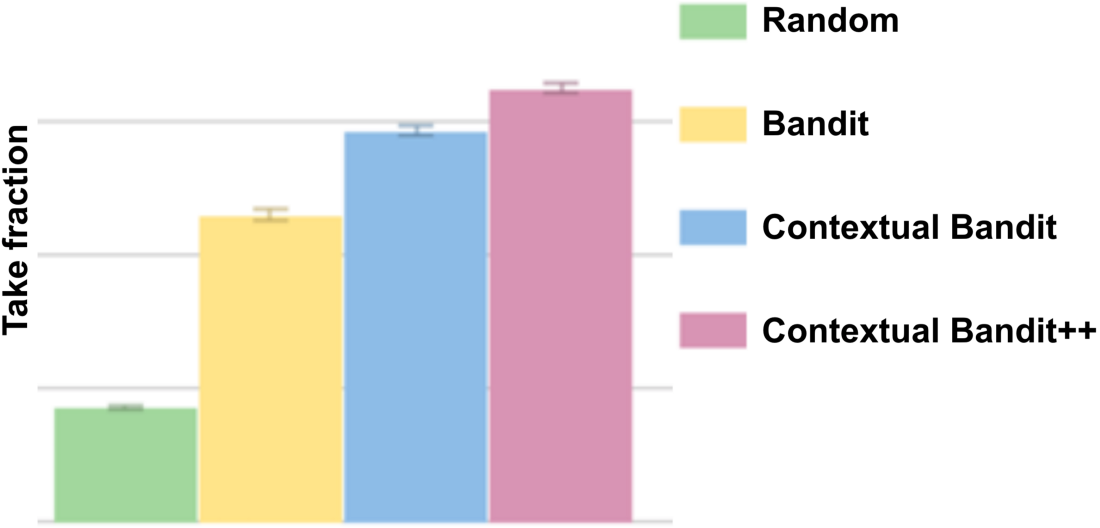
Fig. 2: Average share of launches (the more, the better) for different algorithms based on the replay metric from the image data study log. Rule Random (green) selects one image at random. A simple Bandit algorithm (yellow) selects the image with the largest share of launches. Contextual bandit algorithms (blue and pink) use context to select different images for different users.

Fig. 3: An example of a contextual image selection depending on the type of profile. "Comedy" corresponds to the profile, which looks mainly comedy. Similarly, the “romantic” profile watches mostly romantic films. The contextual thug chooses the image of Robin Williams, the famous comedian, for profiles prone to comedies, while at the same time choosing the image of the kissing couple for profiles that are more prone to romance.
After offline experiments with many different models, we identified those that demonstrate a significant increase in the replay metric - and eventually launched A / B testing to compare the most promising contextual thugs of personalization compared to unauthorized thugs. As expected, personalization worked and led to a significant increase in our key metrics. We also saw a reasonable correlation between offline replay metrics and online metrics. Online results also gave some interesting insights. For example, personalization has shown a greater effect if the user has not previously encountered the movie. It makes sense: it is logical to assume that the cover is more important for people less familiar with the film.
Using this approach, we have taken the first steps to personalize the selection of covers for our recommendations and on the website. The result was a significant improvement in how users find new content ... so we rolled out the system for everyone! This example is the first example of personalization not only of what we recommend to our users, but also how we recommend it. But there are many opportunities to expand and improve the initial approach. This includes the development of algorithms for a cold start, when personalization of new covers and new films is carried out as quickly as possible, for example, using computer vision techniques. Another possibility is to extend the personalization approach to other types of used covers and other informational fragments in the film description: synopses, metadata, and trailers. There is also a broader problem: to help artists and designers determine which new covers to add to the set in order to make the film even more attractive for different types of audiences.
[1] L. Li, W. Chu, J. Langford, X. Wang, “Contextual-bandit-based News Article Recommendation Algorithms" in Proceedings of the Fourth ACM International Conference on Web Search and Data Mining , New York, NY, USA, 2011, pp. 297–306.
For many years, the main goal of the Netflix personal recommendation system was to choose the right movies — and offer them to users on time. With thousands of films in the catalog and diverse customer preferences across hundreds of millions of accounts, it is critical to recommend accurate films to each of them. But the work of the recommendation system does not end there. What can be said about a new and unfamiliar film that will arouse your interest? How to convince you that he is worthy of viewing? It is very important to answer these questions to help people discover new content for themselves, especially unfamiliar films.
One of the solutions to the problem is to take into account pictures or covers for films. If the picture looks convincing, then it serves as a push and some kind of visual "proof" that the film is worth watching. It can depict an actor known to you, an exciting moment like a car chase or a dramatic scene that captures the essence of a movie or a series. If we show the perfect movie cover on your home page (as they say, a picture is worth a thousand words), then maybe, just maybe, you decide to choose this movie. This is just one more thing in which Netflix differs from traditional media: we have not one product, but more than 100 million different products, and each user receives personal recommendations and personalized covers .
')
Netflix home page without covers. So historically, our recommendation algorithms have seen the page
In a previous paper, we discussed how to find one perfect cover for each film for all users. Using the algorithms of multi-armed bandits, we searched for the best cover for a particular movie or series, for example, “Very Strange Things” (Stranger Things). This picture provided the maximum number of views from the maximum number of our users. But given the incredible variety of tastes and preferences - would not it be better to choose the optimal picture for each of the viewers to emphasize aspects of the film that are important specifically for him ?
The covers of the sci-fi series “Very Strange Things,” each of which has chosen our personalization algorithm for more than 5% of hits. Different pictures show the breadth of topics in the series and go beyond what a single cover can show.
For inspiration, let's take a look at options where personalizing covers makes sense. Consider the following examples where different users have different histories of watched movies. On the left of the three films that people watched in the past. To the right of the arrow is the cover that we will recommend to him.
Let's try to choose a personal picture for the film "Good Will Hunting." Here we can derive a solution based on the extent to which the user prefers different genres and themes. If a person watched a lot of romantic movies, “Good Will Hunting” can attract his attention with a picture of Matt Damon and Minnie Driver. And if a person watched a lot of comedies, then he might be interested in this film after seeing the image of Robbie Williams, a famous comedian.
In another case, let’s imagine how different preferences regarding the cast can affect the personalization of the cover for “Pulp Fiction”. If a user watched a lot of movies with Uma Thurman, then he is more likely to respond positively to the cover of "Pulp Fiction" with Uma. At the same time, a fan of John Travolta may be more interested in watching a movie if he sees John on the cover.
Of course, not all cover customization tasks are so easy to solve. So let's not rely on manually written rules, but rely on signals from the data. In general, with the help of customization of covers, we help each individual image to pave the best path to each user, thereby improving the quality of the service.
Problems
At Netflix, we algorithmically adapt many aspects of the site’s work for each user individually, including the rows on the main page , the films for these rows , the galleries for display, our messages, and so on. Every new aspect that we personalize brings new challenges. Personalization of covers is not an exception, there are unique problems here.
One of the problems is that we can only use a single copy of the image for display to the user. In contrast, the typical settings of the recommendations allow the user to demonstrate different options , so that we can gradually explore his preferences based on the choices made. This means that the choice of a picture is the problem of a chicken and eggs in a closed cycle: a person chooses films only with pictures that we decided to choose for him. What we are trying to understand is when showing a particular cover pushed a person to watch a movie (or not), and when a person would watch a movie (or not) regardless of the cover. Therefore, customization of covers combines different algorithms together. Of course, to properly personalize covers, you need to collect a lot of data in order to find signals about which particular copies of covers have a significant advantage over the rest for a particular user.
Another problem is to understand the impact of changing the cover we show the user in different sessions. Does changing the cover of the film reduce the visibility of the film and make it more difficult to visualize it, for example, if the user has previously become interested in the film, but has not watched it yet? Or does changing the cover contribute to changing the solution thanks to an improved picture selection? Obviously, if we found the best cover for this person, it should be used; but constant changes can confuse the user. Changing pictures cause an attribution problem, since it becomes unclear which cover has generated interest in the film for the user.
Further, there is the problem of understanding how the covers interact on one page or in one session. Maybe the bold close-up of the main character is effective for the film, because it stands out among other covers on the page. But if all the covers have similar characteristics, the page as a whole will lose its appeal. It may not be enough to consider each cover separately and you need to think about choosing a different set of covers on a page or during a session. In addition to neighboring covers, the effectiveness of each specific cover may also depend on what other facts and resources (for example, synopsis, trailers, etc.) we show for this film. A variety of combinations appear in which each object emphasizes additional aspects of the film, increasing the chances of a positive impact on the viewer.
Effective personalization requires a good set of covers for each movie. This means that different resources are required, each of which is attractive, informative and indicative of a film in order to avoid clickbate. The set of images for the film should also be diverse enough to cover a wide potential audience interested in various aspects of the content. In the end, how attractive and informative a particular cover depends on the individual person who sees it. Therefore, we need artwork, emphasizing not only different themes in the film, but also different aesthetics. Our groups of artists and designers as they can try to create pictures that are diverse in all respects. They take into account the personalization algorithms that select pictures during the creative process of their creation.
Finally, engineers have the task of providing personalization of covers on a large scale. The site is actively using images - and therefore there are a lot of pictures on it. So the personalization of each resource means processing at the peak of more than 20 million requests per second with a small delay. Such a system should be reliable: incorrect rendering of the cover in our UI will significantly worsen the impression of the site. Our personalization engine should also respond quickly to the release of new films, that is, quickly master personalization in a cold start situation. Then, after the launch, the algorithm must continuously adapt, since the effectiveness of the covers may change over time - this depends on the film's life cycle and on the changing tastes of the audience.
Context gangster approach
Netflix's recommendation engine is largely based on machine learning algorithms. Traditionally, we collect a lot of data about the use of the service by users. Then we launch a new machine learning algorithm on this data package. Then we test it in production through A / B tests on a random sample of users. Such tests make sure that the new algorithm is better than the current system in production. The users in group A are given the current system in production, and the users in group B are the result of the new algorithm. If group B demonstrates greater involvement in the work of the Netflix service, then we roll out a new algorithm to the entire audience. Unfortunately, with this approach, many users for a long time can not use the new system, as shown in the illustration below.
To reduce the period of time unavailability of the new service, we abandoned the batch method of machine learning in favor of the online method. To personalize the covers, we use a specific framework for machine learning - contextual bandits (contextual bandits). Instead of waiting for a complete data packet to be collected, waiting for the model to learn, and then waiting for the A / B tests to complete, contextual thugs quickly determine the best choice of movie cover for each user and context. In short, contextual gangs are a class of machine learning algorithms online that compensate for the costs of collecting the training data needed for continuous learning of an unbiased model with the advantages of using the trained model in the context of each user. In our previous work on choosing the best cover without personalization, we used non-context thugs who found the best cover regardless of context. In the case of personalization, the context of a particular user is taken into account, since each of them perceives each image differently.
The key feature of context thugs is that they reduce the service unavailability period. At a high level, data for contextual gunman learning comes in through the introduction of controlled randomization into the predictions of the trained model. Randomization schemes can be of varying complexity: from simple epsilon-greedy algorithms with a uniform distribution of randomness to closed-loop schemes that adaptively change the degree of randomization, which is a function of the uncertainty of the model parameters. We broadly call this process the study of data . The choice of strategy for the study depends on the number of candidate covers in the presence and the number of users for whom the system is being deployed. With this data study, it is necessary to record information about the randomization of each cover choice. This log allows you to correct distorted deviations from the selection and, thus, impartially carry out an autonomous assessment of the model, as described below.
The study of data with contextual thugs usually comes at a price, since the choice of cover during a user session may with some probability not coincide with the most optimal predicted cover for this session. How does such randomization affect the impression of working with the site (and, consequently, our metrics)? Based on more than 100 million users, losses due to exploring data are usually very small and are amortized over a large user base, since each user implicitly helps provide feedback for the covers in a small part of the catalog. This makes insignificant losses due to the examination of data for each user, which is important to take into account when choosing contextual thugs for a key aspect of user interaction with the site. Randomizing and exploring data with contextual thugs would be less attractive in case of greater losses.
In our online learning scheme, we get a data set for learning, where for each element of a set of interrelated data (user, film, cover) it is indicated whether such a choice led to the decision to watch a movie or not. Moreover, we can control the process of learning in such a way that the choice of covers does not change too often. This gives a clearer attribution of the attractiveness of a particular cover for the user. We also carefully monitor the indicators and avoid the "clickbate" when teaching the model to recommend certain covers, as a result of which the user starts watching the movie, but in the end remains unsatisfied.
Model training
In this online learning setting, we train the context gangster model to choose the best cover for each user, depending on their context. We usually have dozens of candidate covers for each film. To train the model, we can simplify the problem by making a ranking of the covers. Even with this simplification, we still get information about the user's preferences, since each candidate cover is liked by some users and disliked by others. These preferences are used to predict the effectiveness of each triad (user, film, cover). The best prediction with the study of data gives a competent balance of learning models with a teacher or contextual thugs with Thompson Sampling, LinUCB or Bayesian methods.
Potential signals
In context models, the context is usually represented as a feature vector, which is used as input to the model. On the role of signs fit many signals. In particular, these are many user attributes: watched movies, movie genres, user interaction with a particular movie, his country, language, device used, time of day and day of the week. Since the algorithm selects the covers along with the movie recommendation engine, we can also use signals that various recommendation algorithms think about the title, regardless of the cover.
An important consideration is that some images are obviously better in their own right than others in the pool of candidates. We mark the total share of views ( take rates ) for all images in the data study. These coefficients simply represent the number of quality views divided by the number of impressions. In our previous work on the selection of covers without personalization, the image was chosen according to the overall efficiency coefficient for the entire audience. In the new contextual personalization model, the overall factor is still important and is taken into account when selecting the cover for a specific user.
Image selection
After the above learning model, it is used to rank the images in each context. The model predicts the likelihood of viewing a film for a given cover in a given user context. According to these probabilities, we sort the set of candidate covers and choose the one that gives the highest probability. We show it to a specific user.
Efficiency mark
Offline
Our contextual bandit algorithms before rolling out online are first evaluated offline using a technique known as replay [1]. This method allows you to answer hypothetical questions based on records in the data study log (Fig. 1). In other words, we can compare offline what would happen in historical sessions in different scenarios using different algorithms in an unbiased way.
Fig. 1. A simple example of calculating the replay metric based on data from the log. Each user is assigned a random image (top row). The system registers in the log the showing of the cover and the fact whether the user launched the movie for playback (green circle) or not (red). The metric for a new model is calculated by comparing profiles, where random assignments and model assignments are the same (black square) and calculating the share of successful launches in this subset (take fraction).
The replay metric shows how much the percentage of users who launched a movie will change when using a new algorithm compared to the algorithm that is used in production now. For the covers, we are interested in several metrics, including the success rate described above. In fig. Figure 2 shows how contextual thug helps to increase the share of launches in a directory compared to a random choice or a non-contextual thug.
Fig. 2: Average share of launches (the more, the better) for different algorithms based on the replay metric from the image data study log. Rule Random (green) selects one image at random. A simple Bandit algorithm (yellow) selects the image with the largest share of launches. Contextual bandit algorithms (blue and pink) use context to select different images for different users.
| Profile type | Image Rating A | Image Rating B |
|---|---|---|
| Comedy | 5.7 | 6.3 |
| Romantic | 7.2 | 6.5 |
Fig. 3: An example of a contextual image selection depending on the type of profile. "Comedy" corresponds to the profile, which looks mainly comedy. Similarly, the “romantic” profile watches mostly romantic films. The contextual thug chooses the image of Robin Williams, the famous comedian, for profiles prone to comedies, while at the same time choosing the image of the kissing couple for profiles that are more prone to romance.
Online
After offline experiments with many different models, we identified those that demonstrate a significant increase in the replay metric - and eventually launched A / B testing to compare the most promising contextual thugs of personalization compared to unauthorized thugs. As expected, personalization worked and led to a significant increase in our key metrics. We also saw a reasonable correlation between offline replay metrics and online metrics. Online results also gave some interesting insights. For example, personalization has shown a greater effect if the user has not previously encountered the movie. It makes sense: it is logical to assume that the cover is more important for people less familiar with the film.
Conclusion
Using this approach, we have taken the first steps to personalize the selection of covers for our recommendations and on the website. The result was a significant improvement in how users find new content ... so we rolled out the system for everyone! This example is the first example of personalization not only of what we recommend to our users, but also how we recommend it. But there are many opportunities to expand and improve the initial approach. This includes the development of algorithms for a cold start, when personalization of new covers and new films is carried out as quickly as possible, for example, using computer vision techniques. Another possibility is to extend the personalization approach to other types of used covers and other informational fragments in the film description: synopses, metadata, and trailers. There is also a broader problem: to help artists and designers determine which new covers to add to the set in order to make the film even more attractive for different types of audiences.
Links
[1] L. Li, W. Chu, J. Langford, X. Wang, “Contextual-bandit-based News Article Recommendation Algorithms" in Proceedings of the Fourth ACM International Conference on Web Search and Data Mining , New York, NY, USA, 2011, pp. 297–306.
Source: https://habr.com/ru/post/344994/
All Articles