ChatScript Intelligent Chatbots: Development Practice and JavaScript Integration
Today we are publishing the second part of the translation of material on the development of chat bots using ChatScript and JavaScript. Last time, we were mainly engaged in theory. Namely, they talked about chat bots usage scenarios and the internal structure of CS applications. Today there will be more practice. Namely, we will discuss the working environment of ChatScript, talk about the integration of CS and JS, and discuss approaches to solving problems characteristic of chat bots.

ChatScript has a command line interface (CLI, Command Line Interface), which is used during development as an aid. In particular, it is necessary to build chat bots.
The basic command that will be needed during the course of work is, of course
')
Another useful command is
The
The
The
In the process of adding new rules, it is useful to check whether they violate the work of previously created templates. There is a very useful command for this
When executing the command, a detailed report will be displayed on which phrases the system successfully passed the test, and on which phrases it did not:
CS is a lightweight process, so it is quite possible to run several instances of it on one computer. Moreover, operations such as pattern matching and concept searching are well optimized, they work very fast and support many connections. In order to check whether CS is fast enough, we wrote our own small benchmark aimed at studying the performance of a chat bot under load. Our wrapper class, written in JS, sends a set of 10,000 requests and measures the time it takes the engine to answer them. Here are the results of these tests:
The number of requests per second is less than one would expect, given the time taken to process one request.
This happens because groups of messages are sent asynchronously, using promises. Therefore, by multiplying the received number of requests per second by the total number of seconds that the test took, we get a number that is less than 10,000.
When you are working on a bot, expand its functionality, it is useful to periodically check whether, taking into account recent changes, what has been written before continues to work normally. This, in fact, occurs quite often, especially if the templates you create are too general and may correspond to input data that you did not expect to match. In order to cope with such problems, CS has a regression testing mechanism that can be used during the development process. In order to prepare a data set for regression testing, you need to do the following:
1. Create a fresh build with a stable chat bot version. To do this, in CLI CS you need to run the following commands:
2. Create a list with all the phrases you want to test during the test. You can put a file with it anywhere, but I prefer to store such files in the
3. Now you need to organize the output of the output data that the bot generated based on the test list to the log. The system will take input data, send it to the chat bot and receive answers from it. The command must include the user name that is used to perform the regression test, and the path to save the output. Again, you can use any path, but I advise you to store this output in the
4. Initialize the file for the regression test (after completing this operation, enter:
5. Perform a test and check whether the system has passed or not:
Being engaged in the development of a bot, designed to work with input data related to a certain topic, you need to create your own concepts.
It is useful to group only the words and phrases related by meaning. It helps to reuse concepts in different templates and allows you to know in advance about the meanings of concepts in the concept. Ideally, if all the words used are different, this mechanism works fine. However, when working with large lists of terms, some words may appear in different concepts. A completely normal approach is to not use these concepts in the same template. However, I had to work with concepts that, when used together, had collisions in one of the types of phrases. The main problem was that we, in fact, did not know anything about the order of the terms from the concept in the phrases. That is why I had to use a construction of the form
This is how this template works. After the CS engine finds the first value in
The first way is to exclude values that cause a collision between
The second approach is to invite users to apply the parameters in the same order in which they appear in the template. This solution can be used only if there is a clear protocol for communicating with the bot, and users know in advance when certain phrases are used.
Concept Collision
And finally, the third way to deal with collisions is to organize a set of terms where all collisions are moved to a separate concept, and then this concept is added to the template. Then you can find out whether the data transmitted to the bot correspond to the concepts between the concepts or one of the concepts. It looks like this:
In our project, I was faced with the difficult task of implementing a chat bot for several different topics. The same user phrases could be related to each of them, but these messages should have been processed differently depending on the topic being discussed with the bot. I found two solutions to this problem.
The first option relates to the message level. You can specify an additional prefix that will apply to a specific topic and add it to each message that needs to be processed in the context of a specific topic. For example, we have vegetarian and regular restaurants. In this case, the question “what salads do you have?” (“Which salads do you have?”) Should be given different answers. The rules with this approach will look something like this:
It can be seen that the phrases “vegetarian fastfood” and “common fastfood”, indicating, respectively, vegetarian and ordinary cuisine, will be added to the message before sending it to ChatScript. The main advantage of this approach is that there is only one instance of the chat bot that will handle phrases from all possible topics. But at the same time, it complicates the development process, as the size of the script increases, it turns out to be more difficult to expand and maintain. In addition, this, at some stage of the work, may lead to additional conflicts between different topics.
The second solution to the problem of processing the same statements on different topics is to transfer similar topics into different chat bots. With this approach, before launching bots on the server, each of them must have its own folders for storing CS assemblies and user data. Each bot will work independently, on its own port. Before launching each instance, you must specify the location of the folders with the assembly, user data and the port number in the form of additional parameters (for example, -
A similar approach, when several bot instances are used, simplifies the expansion of each of them. The minus is the additional load on the server.
The creator of ChatScript declares that, in fact, there is no need to place different bots on different ports, and I believe that he is right. Bots can exist together, in one assembly. In the application I was working on, an approach using different ports was used to separate the bot instances and, if necessary, simplify disabling part of the logic implemented in the system (for example, if some clients do not need the support of all the implemented themes for which created the bots). As a result, the use of different ports for different bots is an optional technique, however, in my case, it was he who was used, and in similar cases it can also be used.
The CS engine has a built-in mechanism for handling words entered with errors. Usually long words can be recognized even if they contain typos. However, it may happen that a common error in a certain engine word is not recognized. There are several ways to deal with this problem.
The first approach is to describe a word inside a pattern using a wildcard in the part of the word where a typo may appear:
This pattern, namely, its “app * ach” part, will correspond to words beginning with “app” and ending in “ach”, and it does not matter how many characters there are between them, and what symbols they are. As a result, both the correct and incorrect, in terms of the correctness of the spelling of the word, options will correspond to this rule.
The second approach is to create a concept for a word with frequently encountered typos and include all variants of such typos in this concept. Then this concept can be used in templates instead of the word:
Please note that I used the
The third option suits me best. It lies in the fact that you can expand the existing database of engine fixes. In order to do this, you need to add to the file
After that, just restart the engine.
Using ChatScript, it is easy to implement the logic of processing phrases and studying user information, but in any case, if CS capabilities are needed in some web project, you need to establish communication with the server on which the bot is running. Unfortunately, CS does not allow to organize data exchange via HTTP. However, for these purposes you can use TCP sockets.
When using the Node.js server, in order to establish a connection with the bot, you need to connect the
As a rule, all connections to chat bots from JS look like this:
You can simplify the connection by adding an additional level of abstraction, using the methods of the
In order to clearly understand how CS integrates with JS, and learn about the architecture of a JavaScript web application that will use ChatScript as an engine for recognizing user messages, take a look at the following figure.
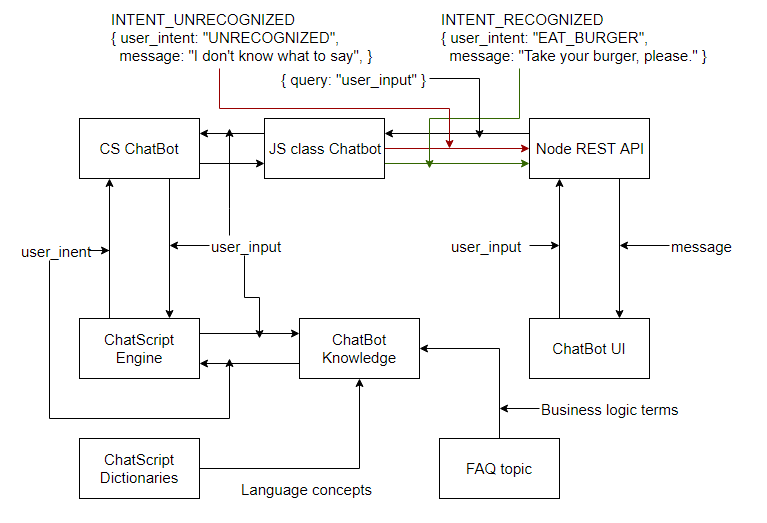
Application architecture using chat bot on CS
As you can see, the process starts in the user interface. This part of the system depends on exactly what technologies are used to implement the chat interface that provides user interaction with the bot. Then comes the REST API layer (in our case, this is the server on Node.js). The REST API server uses the CS wrapper class written in JS, described above. It is this part of the system that sends the user's message to the chat bot using TCP sockets and processes the answers of the bot, which either recognized the message or not. The next component is the implementation of chat bots on CS, which performs message recognition. There could be, for example, one huge topic containing all the rules, or logic implemented in the form of several entities. We have already talked about this, once again I note that the internal structure of the bot depends on the needs of a particular project. For the recognition of user phrases and issuing answers, the chat bot uses the CS engine, where it compares with patterns, searches in the knowledge base and in dictionaries. In addition, here you can add an additional feature: your own concept with terms related to the application domain. This may be necessary in order for a chat bot to define terms and answer frequently asked questions.
Once a set of rules has been created in a script, it may be difficult to find out exactly what rule was called to process a certain phrase, in a situation where the two patterns overlap. In this case, the CS creator advises the use of the construction
In our small example, all the code is placed in one file. But when the size of such a file grows, it makes sense to divide the script into parts. That is why I decided to create separate directories for concepts (the
The main script, which contains rules related to one response category, can be replaced with an empty template and the
Here is an example of a file with an auxiliary topic:
, . .
, - ChatScript Node.js, - CS. , CS, GitHub.
Dear readers! -, , CS?
ChatScript environment
Command line interface
ChatScript has a command line interface (CLI, Command Line Interface), which is used during development as an aid. In particular, it is necessary to build chat bots.
The basic command that will be needed during the course of work is, of course
:build . With its help, first of all, you need to collect the bot's zero level to use concepts that are predefined in the system (for example, ~yes , ~timeinfo , ~number ). Then they collect everything that relates to a specific bot, giving the same name in this command that was used for the file with the list of topics used in the script.')
Another useful command is
:reset . It returns the bot to its original state, and, in addition, clears all variables for long-term data storage (these values are preserved even after assembly).The
:trace command allows you to perform a full trace of the stack of rules and topics called during the analysis of the last portion of data received from the user.The
:why command :why used to display the rules, the application of which affected the latest output generated by the bot. To switch between users, use the command :user , which, as a parameter, takes the user name.The
:quit command stops the chatScript process.In the process of adding new rules, it is useful to check whether they violate the work of previously created templates. There is a very useful command for this
:verify . The developer, in order to use it, you need to add in front of each template a set of phrases to which it should correspond. The syntax of these check phrases is: #! I want burger #! I will take salad #! I need icecream u: BURGER (I {will} [want need take] ~food_type) When executing the command, a detailed report will be displayed on which phrases the system successfully passed the test, and on which phrases it did not:
fastfood> :verify fastfood VERIFYING ~fastfood ...... Pattern failed to match 1 ~fastfood.1.0: I need icecream => u: FOOD ( ^want ( _~food_type ) ) Adjusted Input: I need ice_cream Canonical Input: I need ice_cream 1 verify findings of 3 trials. ▍Performance
CS is a lightweight process, so it is quite possible to run several instances of it on one computer. Moreover, operations such as pattern matching and concept searching are well optimized, they work very fast and support many connections. In order to check whether CS is fast enough, we wrote our own small benchmark aimed at studying the performance of a chat bot under load. Our wrapper class, written in JS, sends a set of 10,000 requests and measures the time it takes the engine to answer them. Here are the results of these tests:
Total messages count: 10000 Chunks count: 100 Chunks size: 100 Percentage of the requests served within a certain time (ms) 10%: 10 20%: 13 30%: 15 40%: 17 50%: 19 60%: 21 70%: 23 80%: 25 90%: 27 100%: 29 Time taken for tests: 19.972 seconds. Requests per second: 500.70098137392347 [#/sec] Time per request: 1.9972 [ms] The number of requests per second is less than one would expect, given the time taken to process one request.
This happens because groups of messages are sent asynchronously, using promises. Therefore, by multiplying the received number of requests per second by the total number of seconds that the test took, we get a number that is less than 10,000.
▍Continuous integration in CS
When you are working on a bot, expand its functionality, it is useful to periodically check whether, taking into account recent changes, what has been written before continues to work normally. This, in fact, occurs quite often, especially if the templates you create are too general and may correspond to input data that you did not expect to match. In order to cope with such problems, CS has a regression testing mechanism that can be used during the development process. In order to prepare a data set for regression testing, you need to do the following:
1. Create a fresh build with a stable chat bot version. To do this, in CLI CS you need to run the following commands:
./BINARIES/ChatScript local debug=":build 0" > /dev/null ./BINARIES/ChatScript local debug=":build food" > /dev/null 2. Create a list with all the phrases you want to test during the test. You can put a file with it anywhere, but I prefer to store such files in the
REGRESS directory of a CS project. At the beginning of this file there should be a command to set up the user used for testing, and the reset command, which allows you to clear long-term data storage variables. At the end of the file also need to insert a reset . For our chat bot, the corresponding file might look like this: :user test :reset I want burger I will take salad I need ice-cream :reset 3. Now you need to organize the output of the output data that the bot generated based on the test list to the log. The system will take input data, send it to the chat bot and receive answers from it. The command must include the user name that is used to perform the regression test, and the path to save the output. Again, you can use any path, but I advise you to store this output in the
RAWDATA_YOURBOT directory. For this purpose, you can create a separate folder, in our case the RAWDATA_FOOD/TEST folder was used. You can generate the output using the following command: ./BINARIES/ChatScript local login=test_user source=REGRESS/food.txt > /dev/null 4. Initialize the file for the regression test (after completing this operation, enter:
quit in the CS console): ./BINARIES/ChatScript local login=test_user debug=":regress init test_user RAWDATA/FOOD/TEST/food.txt" 5. Perform a test and check whether the system has passed or not:
./BINARIES/ChatScript local login=test_user debug=":regress RAWDATA/TEST/food.txt" The practice of developing chat bots on CS
▍ Resolution of collisions in concepts
Being engaged in the development of a bot, designed to work with input data related to a certain topic, you need to create your own concepts.
It is useful to group only the words and phrases related by meaning. It helps to reuse concepts in different templates and allows you to know in advance about the meanings of concepts in the concept. Ideally, if all the words used are different, this mechanism works fine. However, when working with large lists of terms, some words may appear in different concepts. A completely normal approach is to not use these concepts in the same template. However, I had to work with concepts that, when used together, had collisions in one of the types of phrases. The main problem was that we, in fact, did not know anything about the order of the terms from the concept in the phrases. That is why I had to use a construction of the form
<< … >> in order for the system to match words located in any order: u: ANY_ORDER_MATCH (I want << {_~concept_A} {_~concept_B} >>) This is how this template works. After the CS engine finds the first value in
~concept_A , it no longer performs its search in ~concept_B . This gives us errors of the first type, or false-positive matches. Since, due to collisions, one cannot lose the correct values, which coincide with the system, I found three ways to solve such problems.The first way is to exclude values that cause a collision between
~concept_A and ~concept_B . However, such an approach would not be particularly useful if there is a need for accurate phrase recognition results, since a certain set of values will be lost.The second approach is to invite users to apply the parameters in the same order in which they appear in the template. This solution can be used only if there is a clear protocol for communicating with the bot, and users know in advance when certain phrases are used.
Concept Collision
And finally, the third way to deal with collisions is to organize a set of terms where all collisions are moved to a separate concept, and then this concept is added to the template. Then you can find out whether the data transmitted to the bot correspond to the concepts between the concepts or one of the concepts. It looks like this:
u: ANY_ORDER_MATCH (I want << {_~concept_A} {_~concept_B} {_~concept_A_collision} >>) Several topics in one chat bot, or several topics in several bots?
In our project, I was faced with the difficult task of implementing a chat bot for several different topics. The same user phrases could be related to each of them, but these messages should have been processed differently depending on the topic being discussed with the bot. I found two solutions to this problem.
The first option relates to the message level. You can specify an additional prefix that will apply to a specific topic and add it to each message that needs to be processed in the context of a specific topic. For example, we have vegetarian and regular restaurants. In this case, the question “what salads do you have?” (“Which salads do you have?”) Should be given different answers. The rules with this approach will look something like this:
u: (< vegetarian fastfood what salads) We have $list_of_vegeterain_salads u: (< common fastfood what salads) We have $list_of_salads_with_meat It can be seen that the phrases “vegetarian fastfood” and “common fastfood”, indicating, respectively, vegetarian and ordinary cuisine, will be added to the message before sending it to ChatScript. The main advantage of this approach is that there is only one instance of the chat bot that will handle phrases from all possible topics. But at the same time, it complicates the development process, as the size of the script increases, it turns out to be more difficult to expand and maintain. In addition, this, at some stage of the work, may lead to additional conflicts between different topics.
The second solution to the problem of processing the same statements on different topics is to transfer similar topics into different chat bots. With this approach, before launching bots on the server, each of them must have its own folders for storing CS assemblies and user data. Each bot will work independently, on its own port. Before launching each instance, you must specify the location of the folders with the assembly, user data and the port number in the form of additional parameters (for example, -
./BINARIES/ChatScript topic=./TOPIC_VEGETARIAN users=./USERS_VEGETARIAN port=1045) .A similar approach, when several bot instances are used, simplifies the expansion of each of them. The minus is the additional load on the server.
The creator of ChatScript declares that, in fact, there is no need to place different bots on different ports, and I believe that he is right. Bots can exist together, in one assembly. In the application I was working on, an approach using different ports was used to separate the bot instances and, if necessary, simplify disabling part of the logic implemented in the system (for example, if some clients do not need the support of all the implemented themes for which created the bots). As a result, the use of different ports for different bots is an optional technique, however, in my case, it was he who was used, and in similar cases it can also be used.
▍Tonlet Handling
The CS engine has a built-in mechanism for handling words entered with errors. Usually long words can be recognized even if they contain typos. However, it may happen that a common error in a certain engine word is not recognized. There are several ways to deal with this problem.
The first approach is to describe a word inside a pattern using a wildcard in the part of the word where a typo may appear:
u: TYPO_PATTERN (I [want need will] use first app*ach) This pattern, namely, its “app * ach” part, will correspond to words beginning with “app” and ending in “ach”, and it does not matter how many characters there are between them, and what symbols they are. As a result, both the correct and incorrect, in terms of the correctness of the spelling of the word, options will correspond to this rule.
The second approach is to create a concept for a word with frequently encountered typos and include all variants of such typos in this concept. Then this concept can be used in templates instead of the word:
concept: ~frequency IGNORESPELLING [frequency ferquency freuqency] topic: ~topic_with_typos keep repeat [] u: TYPO_CONCEPT (I know ~frequency of typo) Please note that I used the
IGNORESPELLING flag IGNORESPELLING . This allows you to avoid warnings about errors in the concept during the assembly of the bot.The third option suits me best. It lies in the fact that you can expand the existing database of engine fixes. In order to do this, you need to add to the file
ChatScript_LIVEDATA_ENGLISH_SUBSTITUTES_spellfix.txt lines containing the word and spelling variants of this misspelled word: misspell mispell After that, just restart the engine.
Chat ChatScript interaction with JavaScript
Using ChatScript, it is easy to implement the logic of processing phrases and studying user information, but in any case, if CS capabilities are needed in some web project, you need to establish communication with the server on which the bot is running. Unfortunately, CS does not allow to organize data exchange via HTTP. However, for these purposes you can use TCP sockets.
When using the Node.js server, in order to establish a connection with the bot, you need to connect the
net package and, before sending the message line to the bot, in a special way to prepare it. First of all, you need to add a prefix and postfix to the message being sent. The prefix consists of the username and the name of the outputmacro macro used in the control script. Between this information, you must use special delimiter characters. In our example, simplecontrol.top used from the Harry chat bot, the macro is called harry . In order for a bot to establish a connection, it must be started without the local parameter (by default it is on port 1024, but this can be changed using the key of the form port=PORT_NUMBER , for example - ./BINARIES/ChatScript port=1055 ) .As a rule, all connections to chat bots from JS look like this:
const net = require('net'); const prefix = 'username\x00harry\x00'; const post = '\x00' const client = new net.Socket(); client.connect(1024, '127.0.0.1', (err) => { client.write(prefix + 'some message' + post); }); client.on('data', (data) => response.toString()); You can simplify the connection by adding an additional level of abstraction, using the methods of the
Socket object, writing a wrapper class in JS to organize interaction with CS. In this class, it is enough to have an asynchronous method of sending data and a constructor to set the host name of the server and the port before interacting with the CS engine. As an additional parameter, the user name can be passed to such a constructor. CS is able to communicate with various users, as it saves the state and stores all the data that he learned about the user in long-term memory.CS CS and JS integration architecture
In order to clearly understand how CS integrates with JS, and learn about the architecture of a JavaScript web application that will use ChatScript as an engine for recognizing user messages, take a look at the following figure.
Application architecture using chat bot on CS
As you can see, the process starts in the user interface. This part of the system depends on exactly what technologies are used to implement the chat interface that provides user interaction with the bot. Then comes the REST API layer (in our case, this is the server on Node.js). The REST API server uses the CS wrapper class written in JS, described above. It is this part of the system that sends the user's message to the chat bot using TCP sockets and processes the answers of the bot, which either recognized the message or not. The next component is the implementation of chat bots on CS, which performs message recognition. There could be, for example, one huge topic containing all the rules, or logic implemented in the form of several entities. We have already talked about this, once again I note that the internal structure of the bot depends on the needs of a particular project. For the recognition of user phrases and issuing answers, the chat bot uses the CS engine, where it compares with patterns, searches in the knowledge base and in dictionaries. In addition, here you can add an additional feature: your own concept with terms related to the application domain. This may be necessary in order for a chat bot to define terms and answer frequently asked questions.
▍ Debugging
Once a set of rules has been created in a script, it may be difficult to find out exactly what rule was called to process a certain phrase, in a situation where the two patterns overlap. In this case, the CS creator advises the use of the construction
:verify blocking , which allows you to get information about intersecting topics. There is another convenient approach. It was he who approached me. I decided to create a variable that is intended to hold the name of the rule. Then this variable simply joins everything that the bot produces. As a result, you can immediately see which of the existing patterns causes a conflict when processing certain input data. In code, it looks like this: u: BURGER (I {will} [want need take] _~burger) $rule = BURGER $order = _0 ^respond(~make_order) u: DRINKS (I {will} [want need take] _~drink_type) $rule = DRINKS $order = _0 ^respond(~make_order) topic: ~make_order keep repeat nostay [] u: () Okay, you can take your $order. (Catched in rule $rule) Project structure
In our small example, all the code is placed in one file. But when the size of such a file grows, it makes sense to divide the script into parts. That is why I decided to create separate directories for concepts (the
CONCEPTS directory), responses ( RESPONDERS ) and tests ( TESTS ): - FOOD - CONCEPTS - RESPONDERS - TESTS - food.top - simplecontroll.top The main script, which contains rules related to one response category, can be replaced with an empty template and the
^respond method to call topics from another file (the nostay flag should be used in this topic, because after processing the response, we need to return in the main topic). Here is the file food.top , which contains the main topic: # main topic in file RAWDATA/FOOD/food.top topic: ~food keep repeat [] u: DRINKS () ^respond(~drinks) u: MEALS () ^respond(~meals) Here is an example of a file with an auxiliary topic:
# topic in file RAWDATA/FOOD/RESPONDERS/drinks.top topic: ~drinks keep repeat nostay [] u: DRINK (^want(_~drink_type)) Ok, take and drink your _0 . , . .
# concepts in file RAWDATA/FOOD/CONCEPTS/food_concepts.top concept: ~food_type [burger potato salad ice-cream vegan_'s_burger] concept: ~drink_type [~alcohol ~non_alcohol] concept: ~non_alcohol [cola juice milk water] concept: ~alcohol [rum gean wiskey vodka] Results
, - ChatScript Node.js, - CS. , CS, GitHub.
Dear readers! -, , CS?
Source: https://habr.com/ru/post/344970/
All Articles