Multi-pattern matching on GPU myth or reality

Some lyrics
In the old days, when the grass was greener and the trees were taller, I firmly believed that such scary words as thread divergence, cache missing, coalescing global memory accesses and others do not effectively implement the task of multiple search on the GPU. The years went by, the confidence did not disappear, but one fine day I came across the PFAC library. If you are interested in what she is capable of - welcome under cat.
Why all this
Why do we do it and what do we want to get? The most interesting fact is the performance of the PFAC library. I want to get a high speed of work, obtained through the use of a GPU. For comparison, we will use the CPU and OpenMP implementation of the PFAC algorithm.
I assume that the reader has some understanding of the architecture of CUDA. If this is not the case yet, then the main ideas can be found in articles, for example, here and here .
')
About the library
The PFAC library was developed in 2012 and adapted to the architecture and capabilities of the video cards of that time, so if you have a video card with compute capability no higher than 3.0, you are ready to install ubuntu 12.04 and cuda 4.2, then everything should take off from the box. However, we are not looking for easy ways and in this article we will work with ubuntu 16.04 and cuda 9.0. A laptop with an Intel Core i7-7500U, GeForce 940MX and 8 GB of RAM will be used as a test bench.
Before we rush into battle and count gigabits, I will say a few words about the algorithmic part in order to understand what awaits us.
The library implements a parallel Aho-Korasik algorithm without gatherings. PFAC, respectively, is short for Parallel Failureless Aho-Corasick. The algorithm builds a prefix tree without gathering and packs it into a table.
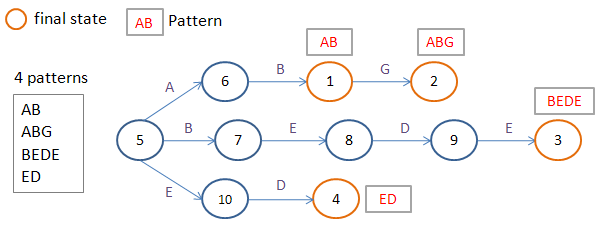
As stated in the documentation, each thread processes data, starting with its input symbol.

However, if you look at the source, each thread handles 4 characters, which is associated with memory alignment.
All the scary words with which I started the article have a place to be in this decision. No one guarantees that all the threads inside one warp (32 successive threads inside one block) will process closely located data in the table. There are also no guarantees that all the threads inside the warp will move along one branch of the branch or exit the cycle of passage through the tree at one time.
But I suggest not to think about the bad, and with burning eyes and optimistic attitude to start a computational experiment.
Deployment
First, let's try deploying PFAC. I believe that CUDA is already installed, as well as the paths to nvcc and libraries added.
Go to the project, do make. Waiting - all is well, everything is unfolded. Harsh reality - some strange mistakes. It turns out that for CUDA 9.0 assemblies for video cards with compute capability below 3.0 are deprecated. This can be fought. You just need to change the src / makefile.
Sample Makefile for compute capability 5.0.
# # Makefile in directory src # # resource usage: # # To compile a dynamic module # (1) nvcc cannot accept -fPIC, so compile .cu to .cu.cpp first # nvcc -arch=sm_50 -cuda ../src/PFAC_kernel.cu # # (2) then use g++ to comple PFAC_notex_shared_reorder.cu.cpp # g++ -fPIC -c PFAC_kernel.cu.cpp # # (3) finally combine two object files to a .so library # g++ -shared -o libpfac.so $(LIBS) PFAC_kernel.cu.o ... # # $(LIBS) is necessary when compiling PFAC library on 32-bit machine # include ../common.mk INC_DIR = ../include LIB_DIR = ../lib OBJ_DIR = ../obj INCPATH += -I../include/ CU_SRC = PFAC_kernel.cu CU_SRC += PFAC_reduce_kernel.cu CU_SRC += PFAC_reduce_inplace_kernel.cu CU_SRC += PFAC_kernel_spaceDriven.cu CPP_SRC = PFAC_reorder_Table.cpp CPP_SRC += PFAC_CPU.cpp CPP_SRC += PFAC_CPU_OMP.cpp CPP_SRC += PFAC.cpp inc_files = $(INC_DIR)/PFAC_P.h $(INC_DIR)/PFAC.h 35 CU_OBJ = $(patsubst %.cu,%.o,$(CU_SRC)) CU_CPP = $(patsubst %.cu,%.cu.cpp,$(CU_SRC)) CPP_OBJ = $(patsubst %.cpp,%.o,$(CPP_SRC)) cppobj_loc = $(patsubst %.o,$(OBJ_DIR)/%.o,$(CPP_OBJ)) cppobj_fpic_loc = $(patsubst %.o,$(OBJ_DIR)/%_fpic.o,$(CPP_OBJ)) cu_cpp_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp,$(CU_CPP)) cu_cpp_obj_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp.o,$(CU_CPP)) all: mk_libso_no50 mk_lib_fpic mk_libso_no50: $(cu_cpp_sm50_loc) $(CXX) -shared -o $(LIB_DIR)/libpfac_sm50.so $(LIBS) $(cu_cpp_obj_sm50_loc) mk_liba: $(cppobj_loc) ar cru $(LIB_DIR)/libpfac.a $(cppobj_loc) ranlib $(LIB_DIR)/libpfac.a mk_lib_fpic: $(cppobj_fpic_loc) $(CXX) -shared -o $(LIB_DIR)/libpfac.so $(cppobj_fpic_loc) $(LIBS) $(OBJ_DIR)/%_fpic.o: %.cpp $(inc_files) $(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/PFAC_CPU_OMP_reorder_fpic.o: PFAC_CPU_OMP_reorder.cpp $(inc_files) $(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/PFAC_CPU_OMP_reorder.o: PFAC_CPU_OMP_reorder.cpp $(inc_files) $(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/%.o: %.cpp $(inc_files) $(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/sm50_%.cu.cpp: %.cu $(NVCC) -arch=sm_50 -cuda $(INCPATH) -o $@ $< $(CXX) -fPIC -O2 -c -o $@.o $@ #clean : # rm -f *.linkinfo # rm -f $(OBJ_DIR)/* # rm -f $(EXE_DIR)/* ####### Implicit rules .SUFFIXES: .o .c .cpp .cc .cxx .C .cpp.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .cc.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .cxx.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .Co: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .co: $(CC) -c $(CFLAGS) $(INCPATH) -o "$@" "$<" ####### Build rules Rebuild.
Whew! It seems to be all right. Add to LD_LIBRARY_PATH the path to the lib folder. We try to run the test example simple_example - the error takes off:
simple_example.cpp:64: int main(int, char**): Assertion `PFAC_STATUS_SUCCESS == PFAC_status' failed.If you add the output PFAC_status - we get the status 10008, which corresponds to PFAC_STATUS_ARCH_MISMATCH. For reasons unknown, the architecture is not supported.
We dive into the code deeper. In the src / PFAC.cpp file, we find the following code that generates this status.
there’s not much
int device_no = 10*deviceProp.major + deviceProp.minor ; if ( 30 == device_no ){ strcpy (modulepath, "libpfac_sm30.so"); }else if ( 21 == device_no ){ strcpy (modulepath, "libpfac_sm21.so"); }else if ( 20 == device_no ){ strcpy (modulepath, "libpfac_sm20.so"); }else if ( 13 == device_no ){ strcpy (modulepath, "libpfac_sm13.so"); }else if ( 12 == device_no ){ strcpy (modulepath, "libpfac_sm12.so"); }else if ( 11 == device_no ){ strcpy (modulepath, "libpfac_sm11.so"); }else{ return PFAC_STATUS_ARCH_MISMATCH ; } From the comments next to it becomes clear that the code does not work only with compute capability 1.0. Replace this fragment with
int device_no = 10*deviceProp.major + deviceProp.minor ; if ( 11 > device_no ) return PFAC_STATUS_ARCH_MISMATCH ; sprintf(modulepath, "libpfac_sm%d.so", device_no); It seems now everything is fine. More explicit dependencies on the version of the computational capabilities of the video card are not observed.
Again, try running the test version. Observe a strange error:
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memory.Fortunately, there is a way to enable debug information in the library.
In the include / PFAC_P.h file you need to uncomment the line
#define PFAC_PRINTF( ... ) printf( __VA_ARGS__ ) And, accordingly, comment out
//#define PFAC_PRINTF(...) Now, after running simple_example, you can see a more distinct error message:
Error: cannot bind texture, 11264 bytes invalid texture reference
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memoryYeah, so the problem is not the allocation of memory, but the use of texture memory. PFAC allows you to disable texture memory. Let's try to use it. In the test / simple_example.cpp file, after creating the handle, add the line:
PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF ) ; The miracle happened, the console gave us the long-awaited lines.
Something found
At position 0, match pattern 1
At position 1, match pattern 3
At position 2, match pattern 4
At position 4, match pattern 4
At position 6, match pattern 2However, ancient manuscripts suggest that texture memory improves performance through the use of texture cache. Well, let's try to run PFAC with texture memory.
PFAC supports 2 modes of operation PFAC_TIME_DRIVEN and PFAC_SPACE_DRIVEN. We are interested in the first. The implementation is located in the src / PFAC_kernel.cu file.
We find the lines where the texture memory is mounted on the global one:
cuda_status = cudaBindTexture( &offset, (const struct textureReference*) texRefTable, (const void*) handle->d_PFAC_table, (const struct cudaChannelFormatDesc*) &channelDesc, handle->sizeOfTableInBytes ) ; For video cards with compute capability 5.0 and later, the implementation of the texture memory operation is somewhat changed and the access mode set is incorrect, so we replace this line with
cuda_status = cudaBindTexture( &offset, tex_PFAC_table, (const void*) handle->d_PFAC_table, handle->sizeOfTableInBytes ) ; After that, in the test / simple_example.cpp file we turn on the texture memory again:
PFAC_setTextureMode(handle, PFAC_TEXTURE_ON ) ; We check the work - everything works.
Testing and Comparison
Now look at the performance of the library.
For testing we will use signatures provided by clamAV
Download the file main.cvd. Next, unpack
dd if=main.cvd of=main.tar.gz bs=512 skip=1 tar xzvf main.tar.gz We will test on the signatures of the main.mdb file. We do many routine actions: we cut off n lines and consider them to be patterns, shaflim input data, etc. I think here it’s no longer necessary to bump into the details.
In order to play with performance, I have somewhat modernized the test / simple_example.cpp file.
Today it looks like this
#include <stdio.h> #include <iostream> #include <stdlib.h> #include <string.h> #include <assert.h> #include <chrono> #include <PFAC.h> int main(int argc, char **argv) { if(argc < 2){ printf("args input file, input pattern\n" ); return 0; } char dumpTableFile[] = "table.txt" ; char *inputFile = argv[1]; //"../test/data/example_input" ; char *patternFile = argv[2];//"../test/pattern/example_pattern" ; PFAC_handle_t handle ; PFAC_status_t PFAC_status ; int input_size ; char *h_inputString = NULL ; int *h_matched_result = NULL ; // step 1: create PFAC handle PFAC_status = PFAC_create( &handle ) ; PFAC_status = PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF); printf("%d\n", PFAC_status); assert( PFAC_STATUS_SUCCESS == PFAC_status ); // step 2: read patterns and dump transition table PFAC_status = PFAC_readPatternFromFile( handle, patternFile) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to read pattern from file, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } // dump transition table FILE *table_fp = fopen( dumpTableFile, "w") ; assert( NULL != table_fp ) ; PFAC_status = PFAC_dumpTransitionTable( handle, table_fp ); fclose( table_fp ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to dump transition table, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } //step 3: prepare input stream FILE* fpin = fopen( inputFile, "rb"); assert ( NULL != fpin ) ; // obtain file size fseek (fpin , 0 , SEEK_END); input_size = ftell (fpin); rewind (fpin); // allocate memory to contain the whole file h_inputString = (char *) malloc (sizeof(char)*input_size); assert( NULL != h_inputString ); h_matched_result = (int *) malloc (sizeof(int)*input_size); assert( NULL != h_matched_result ); memset( h_matched_result, 0, sizeof(int)*input_size ) ; // copy the file into the buffer input_size = fread (h_inputString, 1, input_size, fpin); fclose(fpin); auto started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on GPU PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } auto done = std::chrono::high_resolution_clock::now(); std::cout << "gpu_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count()<< std::endl; memset( h_matched_result, 0, sizeof(int)*input_size ) ; PFAC_setPlatform(handle, PFAC_PLATFORM_CPU); started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on CPU PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } done = std::chrono::high_resolution_clock::now(); std::cout << "cpu_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count()<< std::endl; memset( h_matched_result, 0, sizeof(int)*input_size ) ; PFAC_setPlatform(handle, PFAC_PLATFORM_CPU_OMP); started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on OMP PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } done = std::chrono::high_resolution_clock::now(); std::cout << "omp_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count() << std::endl; PFAC_status = PFAC_destroy( handle ) ; assert( PFAC_STATUS_SUCCESS == PFAC_status ); free(h_inputString); free(h_matched_result); return 0; } Because for time measurements I use std :: chrono, in the test / Makefile file you need to add the -std = c ++ 0x flag. And do not forget to set the number of threads for OpenMP (I used 4 myself):
export OMP_NUM_THREADS=4 Now you can begin to measure performance. Let's see what the GPU can show. The length of each pattern is 32, the length of the input data is 128 MB.
We get the following schedule:

As the number of patterns grows, performance degrades. This is not surprising, because the Aho-Corasica algorithm without gathering depends not only on the input data, but also on the patterns, since for each position in the text, it is necessary to go deep into the tree for the length of the matched substring of the text with the prefix of any attribute, and with an increase in the number of patterns, the probability of finding a substring coinciding with a certain prefix increases.
And now a more interesting graph - acceleration, with the help of the GPU.
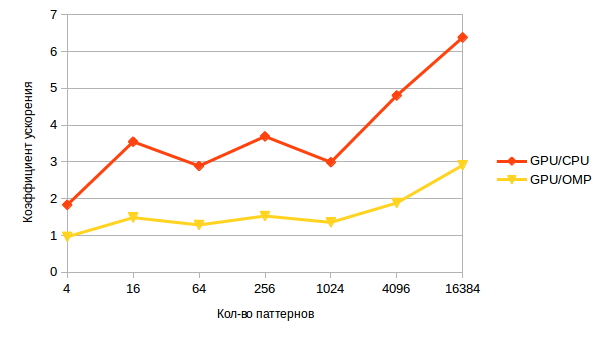
On a small number of patterns, it is almost imperceptible, it is eaten by data transfer. However, as the number increases, so does the acceleration, which indicates the potential possibilities of the GPU in an unusual task.
Instead of output
When I took on this task, I was skeptical, because there can be no such thing. However, the result gives hope for the possibility of using CUDA in an uncharacteristic industry.
The path of the researcher does not end there, it will take a lot of work, a lot of performance research and comparisons with competitors.
The first step is made, do not lose hope!
Source: https://habr.com/ru/post/344938/
All Articles