WebRTC: how two browsers agree on voice and video calls
Spoiler: no way. For them, it makes the developer.
When they began to kill Flash many years ago, not only browser games suffered. Flash has traditionally been strong in voice and video calls: direct access to the microphone, camera, speakers, the ability to work with UDP packets. In HTML5, the WebRTC technology was replaced. The one that, a few months ago, finally landed on Safari and Edge. Now you can call from a web page open on the iPhone to another web page, for example, opened in Firefox Quantum on Linux.
One of the “chips” WebRTC, which Flash did not have is the ability of P2P connections between browsers. But for peer-to-peer to work, the programmer will have to suffer. How browsers agree on where to send UDP packets, and what the developer should do - under the cat.
"Alarm" - something that they try not to talk about
Most WebRTC tutorials are a story about a cool Flash replacement, voice and video calls from browsers, a beautiful story about peer-to-peer and a ten megabyte video stream without delays during a video call from your iPhone to a Windows laptop, provided they are connected to the same WiFi. As a code, several JavaScript lines are usually shown, convincingly demonstrating how simple everything is.
')
The trick is that a wrapper over WebRTC is usually demonstrated. And apart from hiding from the developer of guts RTCPeerConnection and MediaDevices.getUserMedia , such wrappers hide all communication between the two browsers from the developer using their own cloud and technology stack: be it PubNub, Twilio or our Voximplant. Doing work for the developer is good and right. But by simplifying the technology stack, we often put a time bomb when a lack of understanding of the processes under the hood leads to a breakdown of the deadlines that work through the solutions and “technical problems” that tech support likes to talk about.

This story is about the signaling in WebRTC, how we and other companies are doing it, and how you can make it if you want to create your solution from scratch and without using ready-made services.
Why do I need a server for a P2P call
Hearing the phrase "peer-to-peer", we usually recall the torrents. Who seems to have no central server. What is “signaling” in WebRTC and where is its server?
Suppose you made a web page with WebRTC and JavaScript code. Opened it on three laptops connected to your WiFi and want the first laptop to make a video call to the third. How does WebRTC on the first laptop know that it needs to connect to the third one? What would we do at the site of WebRTC developers?
The first thing that comes to mind is to transfer the first notebook's IP address of the third notebook to WebRTC and let them send UDP packets. But this method will work only if both devices are connected to the same network and this network allows them to receive packets from each other (surprise - public WiFi in hotels and conference sites often does not allow). And what if we have not one, but three WiFi access points? And all three laptops are connected to different access points and have the same virtual IP address, for example "192.168.0.5". Where to the browser launched on the first laptop to send packets?
It can be assumed that in this situation there will be no call, and in any case we will need an external server with a “real” IP address through which browsers on both laptops will be able to communicate with each other. But the authors of WebRTC considered that voice and video are traffic-intensive communications, and if millions of Skype for Web users or Google Hangouts call through public servers, then these servers will burst. The creators of WebRTC have provided technology with the ability to “punch” NAT and establish P2P connections, even if both devices have virtual IP addresses and cannot directly exchange packets. The payment was the same "alarm". A developer cannot simply transfer to WebRTC the IP address of a second device or an external server. He needs to help both browsers carefully inspect the network and agree with each other. And for this he needs his Signaling Server.
Offer, Answer, ICE candidates and other scary words.
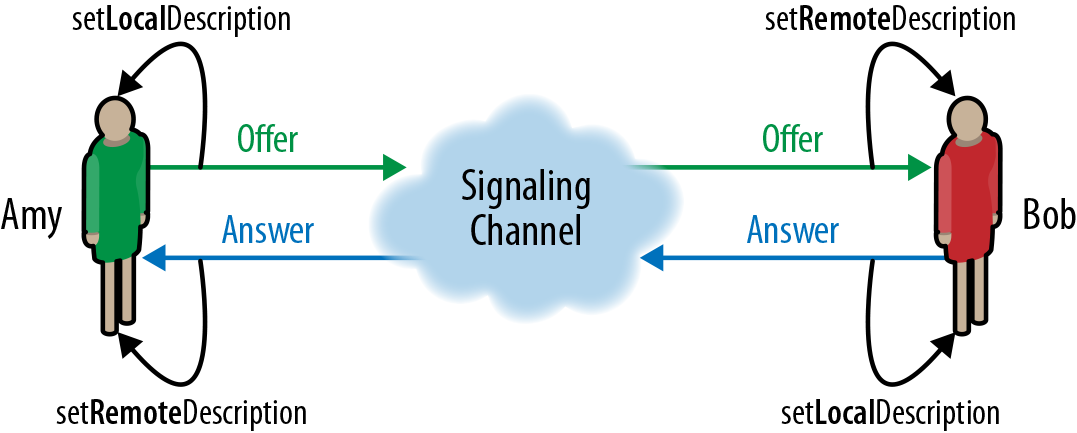
So, what does a video call between two browsers look like from a developer’s point of view?
- After all the preliminary preparation and creation of the necessary JavaScript objects on the first browser, the WebRTC method is called createOffer () , which returns a text package in SDP format (or, in the future, a JSON serializable object, if the oRTC version of the API picks up the “classic”). This package contains information about what the developer wants for communication: voice, video, or send data, what codecs are there - the whole story
- And now - the alarm. The developer should in some way (really, it is written in the specification!) To transfer this text package to the second browser. For example, using your own Internet server and WebSocket connection from both browsers.
- After receiving the offer on the second browser, the developer passes it to WebRTC using the setRemoteDescription () method. Then it calls the createAnswer () method, which returns the same text package in SDP format, but for the second browser and taking into account the received package from the first
- Signaling continues: the developer sends the answer text packet back to the first browser
- Having received the answer on the first browser, the developer passes it to WebRTC using the already mentioned setRemoteDescription () method, after which WebRTC in both browsers is minimally aware of each other. Can I connect? Unfortunately no. In fact, everything is just beginning
- WebRTC in both browsers begins to examine the state of the network connection (in fact, the standard does not indicate when it should be done, and for many browsers WebRTC begins to study the network immediately after creating the corresponding objects, so as not to create unnecessary delays after connecting). When the developer in the first step created WebRTC objects, he should at least send the address of the STUN server. This is the server that, in response to the UDP packet “what is my IP”, transmits the IP address from which it received the packet. WebRTC uses the STUN server to obtain an “external” IP address, compare it with the “internal” one and see if there is NAT. And if so, what reverse ports does NAT use to route UDP packets?
- From time to time, WebRTC on both browsers will invoke the onicecandidate callback, passing the already familiar SIP packet with information for the second participant in the connection. This package contains information about internal and external IP addresses, connection attempts, ports used by NAT, and so on. The developer uses signaling to transfer these packets between browsers. The transmitted packet is sent to WebRTC using the addIceCandidate () method .
- After some time, WebRTC will establish a peer-to-peer connection. Or will not, if NAT will interfere. For such cases, the developer can send the address of the TURN server, which will be used as an external connecting element: both browsers will transmit through it UDP packets with voice or video. If the STUN-server can be found free (for example, google has), then the TURN-server will have to be raised itself. No one is interested in passing through itself terabytes of video traffic just like that
All these nuances can be hidden if you use a ready-made platform. Our Web SDK correctly configures WebRTC, patches SDP packages, supports Voximplant's WebSocket connection and takes care of many more details. And of course, we have our own STUN- and TURN-servers to connect in any case. But you can not hide the nuances and make yourself! The APIs available in browsers now allow you to make alarms in many ways, about them below.
Simple HTTP request signaling that does not work
The first thing that comes to mind is the simplest HTTP-server and xmlHttpRequest / fetch from the browser. Alas, it will work only for “hello world” from the textbook. In real life, the server will fall on such a number of requests. Which will have to be done quite often, so that by pressing “connect” the user does not wait a few minutes to “establish a connection”. And they will also have to be done often because WebRTC is a realtime story, and offer / answer / ice needs to be transmitted very quickly. A delay of even a few seconds can serve as a signal to WebRTC that “nothing happens”, after which the engine will stop trying to establish a connection. Alternatively, you can try the “long polling” technique, but in practice it does not work very well and the intermediate Internet infrastructure likes to tear off such “slow” HTTP requests.

WebSockets-alarm: m ost e ffective t actics a vailable
Most solutions that use WebRTC use WebSockets for signaling. The protocol is already “old” enough to be supported by the vast majority of used web browsers and network equipment. And if you use a wrapper like socket.io or SocketJS, then in those rare cases when the WebSocket is not working, you can degrade to HTTP long polling, which will work "at least somehow." On the server side, a WebSockets connection, over which no data is transmitted, consumes almost no resources, and the server can safely serve tens of thousands of web pages waiting for a call.
What problems can there be with WebSockets? Well, connections sometimes break off - this needs to be handled. They also have high keep alive timeouts - the connection may look alive, but in fact it is already broken somewhere on the intermediate equipment. And we will know about it only when the next keep alive package does not come, and this may be ten minutes. During which they are trying to reach us, but they cannot. This mechanism is left to the implementations of browsers and servers, so the ping-pong frame from the server will be useful to check and tweak if necessary.
HTTP / 2-signaling as a modern analogue of WebSocket
When HTTP version 2 becomes more popular, WebSockets and Server Side Events are likely to be a thing of the past. A binary channel of communication with the server in both directions, through which you can get both an HTML page and pictures, and organize WebRTC signaling - this is very cool. Unfortunately, despite the support of the latest versions of popular browsers, HTTP / 2 is still dangerous to use for projects with a wide audience. The reason - in the intermediate equipment that make up the "skeleton" of the Internet. All these routers, gateways, barricades and pussies of twenty years ago often complete HTTP / 2 connections, not understanding what it is and trying to “protect” something from someone.
WebRTC signaling as an example of recursion
And for WebRTC signaling, you can use another WebRTC connection! It sounds strange, but this method has its advantages. If the first WebRTC connection is established between the browser and the cloud (as we do for non-P2P calls) with some other signaling, then such a connection can then use the Data Channel API. Which favorably differs from WebSockets in that it can work not only “like TCP”, but also “like UDP”, very quickly sending packets without guaranteed delivery. This method allows you to very quickly signal connections - faster than WebSockets and HTTP / 2. In some cases, this method is what you need. For example, in games.
TL; DL
Summarizing everything described: before WebRTC establishes a peer-to-peer connection, the developer must provide two browsers (or other devices); Google's libwebrtc library allows using WebRTC on everything that compiles C ++
Illustration to Kata from the site www.elasticrtc.com
Dragon illustration from www.sococo.com/blog/webrtc-signaling-here-be-dragons
Source: https://habr.com/ru/post/344794/
All Articles