Installing the HA Master Kubernetes Cluster with Kubespray

Kubespray (formerly Kargo) is a set of Ansible roles for installing and configuring an orchestration system with Kubernetes containers. In this case, AWS, GCE, Azure, OpenStack or regular virtual machines can act as IaaS. The project used to be called Kargo. This is an open source project with an open development model, so if you wish, anyone can influence its life cycle.
Habré has already written about installing Kubernetes using Kubeadm , but there are significant drawbacks to this method: it still does not support multimaster configurations and, at times, is not very flexible. Kubespray, although it uses Kubeadm under the hood, already has the functionality of providing high availability for both the wizard and etcd during the installation phase. On its comparison with other relevant methods of installing Kubernetes, you can read the link https://github.com/kubernetes-incubator/kubespray/blob/master/docs/comparisons.md
')
In this article we will create 5 servers on Ubuntu 16.04 OS. In my case, their list will be as follows:
192.168.20.10 k8s-m1.me 192.168.20.11 k8s-m2.me 192.168.20.12 k8s-m3.me 192.168.20.13 k8s-s1.me 192.168.20.14 k8s-s2.me We add them to the / etc / hosts of all these servers, including the local system, or to the dns server. The firewall and other restrictions on the network of these hosts must be deactivated. In addition, it is necessary to allow IPv4 forwarding and each of the hosts must have free access to the Internet to download docker images.
Copy the public rsa-key to each server from the list:
$ ssh-copy-id ubuntu@server.me Specify the required user and key to connect from the local machine:
$ vim ~/.ssh/config ... Host *.me User ubuntu ServerAliveInterval 60 IdentityFile ~/.ssh/id_rsa Where ubuntu is the user on whose behalf the connection to the server will occur, and id_rsa is the private key. Moreover, this user needs the ability to execute sudo commands without a password .
Clone the Kubespray repository:
$ git clone https://github.com/kubernetes-incubator/kubespray.git After copying the inventory directory to edit its contents:
$ cp -r inventory my_inventory $ cd my_inventory As an example, use inventory.example :
$ mv inventory.example inventory $ vim inventory k8s-m1.me ip=192.168.20.10 k8s-m2.me ip=192.168.20.11 k8s-m3.me ip=192.168.20.12 k8s-s1.me ip=192.168.20.13 k8s-s2.me ip=192.168.20.14 [kube-master] k8s-m1.me k8s-m2.me k8s-m3.me [etcd] k8s-m1.me k8s-m2.me k8s-m3.me [kube-node] k8s-s1.me k8s-s2.me [k8s-cluster:children] kube-node kube-master Based on the above, we will install the HA installation of Kubernetes: etcd, the storage of cluster configuration parameters will consist of 3 nodes for the presence of a quorum, and the services of Kubernetes Master (kube-apiserver, controller-manager, scheduler, etc.) will be duplicated three times. Of course, nothing prevents to render the service etcd completely separately.
At this stage I would like to tell a little more about how the HA mode is implemented for masters. Each Kubernetes worker (in our case, this is k8s-s * .me) will install Nginx in balancing mode, in the upstream of which all Kubernetes masters will be described:
stream { upstream kube_apiserver { least_conn; server kube-master_ip1:6443; server kube-master_ip2:6443; server kube-master_ip3:6443; } server { listen 127.0.0.1:6443; proxy_pass kube_apiserver; proxy_timeout 10m; proxy_connect_timeout 1s; } Accordingly, in the event of the fall of one of the wizards, Nginx will exclude it from the upstream and stop forwarding requests to such a server.
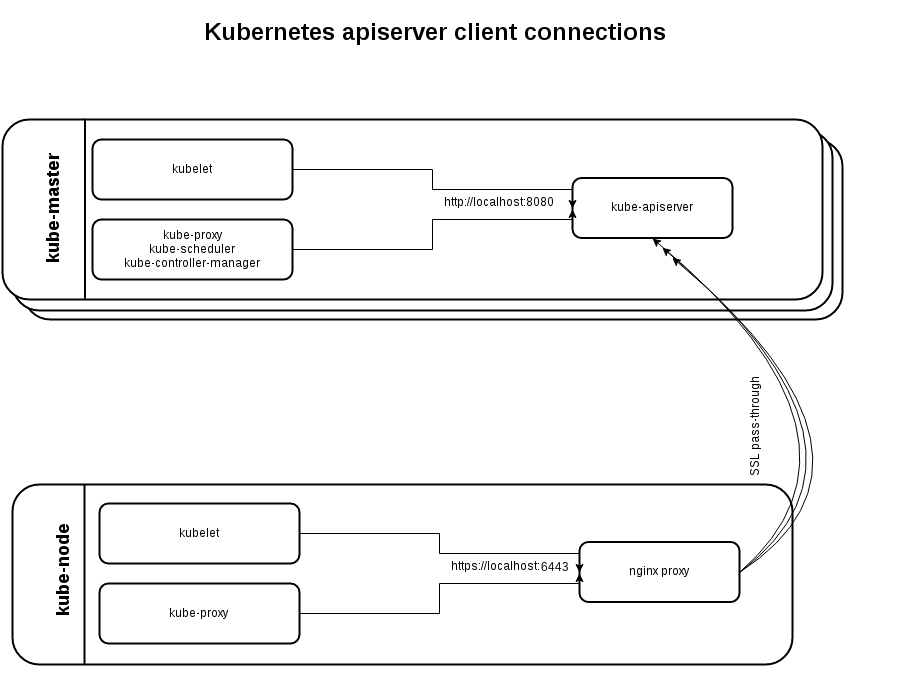
This scheme allows you to exclude a single point of failure: in case of a master crash, another master will take over his work, and Nginx responsible for forwarding requests will work on each worker.
At the cluster installation stage, it is possible to disable this internal balancer and take care of everything yourself. This may be, for example, some third-party Nginx or HAProxy. However, we should not forget that in order to ensure high availability, they must work in pairs, between members of which, if necessary, Virtual IP must migrate. VIP can be implemented using various technologies such as Keepalived, Heartbeat, Pacemaker, etc.
On the wizard, kube-apiserver works simultaneously on 2 ports: local 8080 without encryption (for services running on the same server) and external HTTPS 6443. The latter, as I have already mentioned, is used to communicate with workers and can be useful if the services of one masters (kubelet, kube-proxy, etc.) must be transferred to other hosts.
Let's continue the work on creating a test cluster. Edit group_vars / all.yml :
$ vim group_vars/all.yml ... bootstrap_os: ubuntu ... kubelet_load_modules: true In addition to Ubuntu 16.04, Kubespray also supports installation on nodes with CoreOS, Debian Jessie, CentOS / RHEL 7, that is, on all major current distributions.
If necessary, you should also look in group_vars / k8s-cluster.yml , where you can specify the required version of Kubernetes to be installed, choose a plugin for the overlay network (by default it is calico, but other options are available), install efk (elasticsearch / fluentd / kibana), helm, istio, netchecker, etc.
I also recommend watching the roles / kubernetes / preinstall / tasks / verify-settings.yml . Here are the basic checks that will be performed before starting the installation of Kubernetes. For example, checks for the presence of a sufficient amount of RAM (at the moment, it is at least 1500MB for masters and 1000MB for nodes ), the number of etcd servers (to ensure their quorum must be an odd number) and so on. In the latest releases of Kubespray, there is an additional requirement for swap: it must be turned off on all nodes in the cluster.
If Ansible is not yet present on the local system, install it along with the netaddr module:
# pip install ansible # pip install netaddr It is important to note that the netaddr and ansible module should work with the same version of Python.
After this, we can proceed with the installation of the Kubernetes cluster:
$ ansible-playbook -i my_inventory/inventory cluster.yml -b -v Alternatively, the rsa key and the user for the connection can be passed as arguments, for example:
$ ansible-playbook -u ubuntu -i my_inventory/inventory cluster.yml -b -v --private-key=~/.ssh/id_rsa Typically, the installation of the cluster takes about 15-20 minutes, but it also depends on your hardware. After we can check whether everything works correctly, for which you need to connect to any host in the cluster and do the following:
root@k8s-m1:~# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-m1 Ready master 28m v1.8.4+coreos.0 k8s-m2 Ready master 28m v1.8.4+coreos.0 k8s-m3 Ready master 28m v1.8.4+coreos.0 k8s-s1 Ready node 28m v1.8.4+coreos.0 k8s-s2 Ready node 28m v1.8.4+coreos.0 root@k8s-m1:~# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-node-2z6jz 1/1 Running 0 27m kube-system calico-node-6d6q6 1/1 Running 0 27m kube-system calico-node-96rgg 1/1 Running 0 27m kube-system calico-node-nld9z 1/1 Running 0 27m kube-system calico-node-pjcjs 1/1 Running 0 27m kube-system kube-apiserver-k8s-m1 1/1 Running 0 27m ... kube-system kube-proxy-k8s-s1 1/1 Running 0 26m kube-system kube-proxy-k8s-s2 1/1 Running 0 27m kube-system kube-scheduler-k8s-m1 1/1 Running 0 28m kube-system kube-scheduler-k8s-m2 1/1 Running 0 28m kube-system kube-scheduler-k8s-m3 1/1 Running 0 28m kube-system kubedns-autoscaler-86c47697df-4p7b8 1/1 Running 0 26m kube-system kubernetes-dashboard-85d88b455f-f5dm4 1/1 Running 0 26m kube-system nginx-proxy-k8s-s1 1/1 Running 0 28m kube-system nginx-proxy-k8s-s2 1/1 Running 0 28m As you can see, by default, the kubernetes-dashboard web panel was installed immediately. Details regarding her work can be found at the following link https://github.com/kubernetes/dashboard
Exclusively for a basic check, we’ll pour it out with two containers:
$ vim first-pod.yaml apiVersion: v1 kind: Pod metadata: name: first-pod spec: containers: - name: sise image: mhausenblas/simpleservice:0.5.0 ports: - containerPort: 9876 resources: limits: memory: "64Mi" cpu: "500m" - name: shell image: centos:7 command: - "bin/bash" - "-c" - "sleep 10000" $ kubectl apply -f first-pod.yaml pod "first-pod" created $ kubectl get pods NAME READY STATUS RESTARTS AGE first-pod 2/2 Running 0 16s $ kubectl exec first-pod -c sise -i -t -- bash [root@first-pod /]# curl localhost:9876/info {"host": "localhost:9876", "version": "0.5.0", "from": "127.0.0.1"} It was a Python test application from http://kubernetesbyexample.com/ .
Oddly enough, Docker 17.03.1-ce was installed as the containerization system, although the official documentation mentions that version 1.13 is best to use. The version of Docker that will be installed, described in roles / docker / defaults / main.yml and, theoretically, you can overwrite it in the configuration files above or pass the value as an argument.
Ansible Kubespray scripts also support scaling of cluster nodes. To do this, update inventory, in which we will add a new node (worker):
$ vim my_inventory/inventory k8s-m1.me ip=192.168.20.10 k8s-m2.me ip=192.168.20.11 k8s-m3.me ip=192.168.20.12 k8s-s1.me ip=192.168.20.13 k8s-s2.me ip=192.168.20.14 k8s-s3.me ip=192.168.20.15 [kube-master] k8s-m1.me k8s-m2.me k8s-m3.me [etcd] k8s-m1.me k8s-m2.me k8s-m3.me [kube-node] k8s-s1.me k8s-s2.me k8s-s3.me [k8s-cluster:children] kube-node kube-master Of course, the node k8s-s3.me should also be properly configured, like the previous nodes. Now we can start cluster scaling:
$ ansible-playbook -i my_inventory/inventory scale.yml -b -v According to the Kubespray documentation, you can use a preliminary procedure with cluster.yml for this, however, with scale.yml it will take much less time. As a result, we can now observe a new node through kubectl:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-m1 Ready master 6h v1.8.4+coreos.0 k8s-m2 Ready master 6h v1.8.4+coreos.0 k8s-m3 Ready master 6h v1.8.4+coreos.0 k8s-s1 Ready node 6h v1.8.4+coreos.0 k8s-s2 Ready node 6h v1.8.4+coreos.0 k8s-s3 Ready node 19m v1.8.4+coreos.0 That's all. Also this article can be read in Ukrainian at http://blog.ipeacocks.info/2017/12/kubernetes-part-iv-setup-ha-cluster.html
Ps. It is better to immediately write about all errors in private — we will promptly fix it.
Links
kubespray.io
github.com/kubernetes-incubator/kubespray
github.com/kubernetes-incubator/kubespray/blob/master/docs/getting-started.md
github.com/kubernetes-incubator/kubespray/blob/master/docs/ansible.md
github.com/kubernetes-incubator/kubespray/blob/master/docs/ha-mode.md
dickingwithdocker.com/2017/08/deploying-kubernetes-vms-kubespray
medium.com/@olegsmetanin/how-to-setup-baremetal-kubernetes-cluster-with-kubespray-and-deploy-ingress-controller-with-170cdb5ac50d
github.com/kubernetes-incubator/kubespray
github.com/kubernetes-incubator/kubespray/blob/master/docs/getting-started.md
github.com/kubernetes-incubator/kubespray/blob/master/docs/ansible.md
github.com/kubernetes-incubator/kubespray/blob/master/docs/ha-mode.md
dickingwithdocker.com/2017/08/deploying-kubernetes-vms-kubespray
medium.com/@olegsmetanin/how-to-setup-baremetal-kubernetes-cluster-with-kubespray-and-deploy-ingress-controller-with-170cdb5ac50d
Source: https://habr.com/ru/post/344704/
All Articles