SOC for beginners. How to organize monitoring of incidents and response to attacks in the 24x7 mode
We continue the cycle of our articles “SOC for beginners”. Last time we talked about how to implement Threat Intelligence in a company and not regret it. Today I would like to talk about how to organize processes to ensure continuous monitoring of incidents and rapid response to attacks.
In the first half of 2017, the cumulative average daily flow of IS events processed by SIEM systems and used by Solar JSOC to provide service was 6.156 billion . Events with suspicion of the incident - an average of about 960 per day . Every sixth incident is critical . At the same time, for our clients, including Tinkoff Bank, CTC Media or Pochta Bank, the issue of promptly informing about an attack and receiving recommendations on counteraction is very serious.
We decided to tell how we solved this problem, what problems we encountered, and what method of work organization we use in the end.
')

Team building
It is obvious that for successful incident management it is necessary to create something like dispatching service, which will coordinate the elimination of incidents and serve as a single point of contact with the customer.
In order to delineate responsibilities and responsibilities within the service, we have divided it into several levels, which over time have been scaled in accordance with the new tasks. After numerous attempts and approaches to the projectile, we got the following picture:
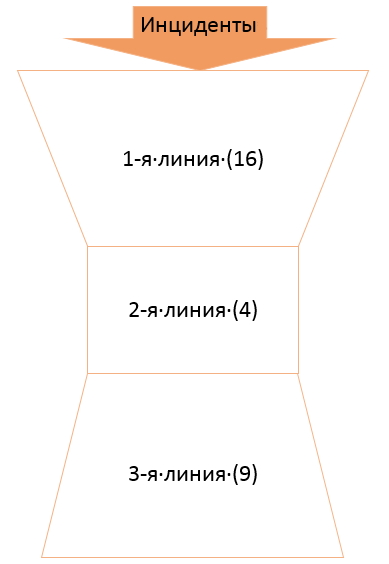
The first line of Solar JSOC is monitoring engineers who are responsible for the timely response to the incident and its analysis, filtering false positives, as well as for preparing an analytical report on all typed incidents. Timely reaction is considered to meet the requirements of the SLA. The first line works in shifts to ensure the response and analysis of incidents in 24x7 mode.
The second line is response engineers, specialists in specific products and areas of information security, on whom atypical incidents fall according to their area of expertise.
Usually, the Service Desk has an “inverted pyramid” structure, and, as you see, we have an hourglass. The fact is that a somewhat atypical story has arisen with the third line. The third line consists of analysts assigned to specific customers and possessing the most complete information on their infrastructure and internal processes. Escalation on them occurs in the following situations:
To ensure monitoring 24x7 at night, weekends and holidays, an on-duty analyst is allocated. So, it turned out that with an increase in the number of customers and scaling of the service, the need for analysts in the first place increases.
The team of specialists in forensics and reverse engineering of malware stands apart. They are connected if the incident is associated with a virus infection or penetration attack.
To remain effective, the service of the monitoring center must constantly evolve. For example, the quality of monitoring is highly dependent on the content of the SIEM system, so it is necessary to constantly develop new scenarios for identifying incidents and optimize existing ones. In addition, it is necessary to stay abreast of new technologies and evaluate the possible benefits from their use within the service. For example, a retrospective analysis of indicators of compromise by means of SIEM takes too much time, and you need to find a tool that will perform this task faster. We have created a separate group, which consists of three people and deals exclusively with the development of the service.
It is important to clarify that the content needs to be adapted for each Customer: tune the rules to reduce the number of false positives, build a connection profile for a new segment, etc. The selected group cannot cope with such a scope of work, therefore we have appointed analysts from the third line to perform this task, who have thoroughly studied the characteristics of their customers and know where and what they have pain.
Having dealt with the internal structure, we began to build processes of interaction with customers in addition to communications as part of the investigation of incidents. In other words, it was necessary to build SLA management, which would allow to control the level of service and customer satisfaction. At this stage, the role of another group of specialists arose - service managers who are involved in monitoring the parameters of the quality of services prescribed in the contract. These parameters must always be measurable, that is, representable in the form of numeric metrics.
Here are the metrics for monitoring the quality of the monitoring service we chose:
In addition to directly monitoring the incidents, the process of providing services revealed two quite frequent activities - connecting a new event source and launching / refining the incident detection scenario. To put these operations under control, we have introduced two new metrics:
Well, the last metric concerns the availability of the service. To simplify the control, we have combined the set of accessibility indicators of all the technical means involved in the provision of the service into one - the accessibility of the platform.
Let's see what kind of team we finally got together:





First problems
It would seem that the processes were regulated, the roles are painted, the interaction is established, it is time to fight. But, having started the service and connected the first customers, we began to face a shaft of problems. As the entire flow of incidents falls first on the first line, difficulties began to manifest themselves with it.
The first line in any case has a qualification lower than the others and operates 24x7. In such circumstances, there is always the risk of error: for example, closing a combat incident as false positive. If this leads to serious consequences for the customer, no one will look for the culprit, and reputational damage will fall on the whole team.
Hence the important question: how to control the quality of case analysis and analysis? If you want to simplify your life, the specialist can choose the incident easier or closer to the topic in which he understands better. With this approach, an “undesired” incident may appear that no one wants to take, and it will slowly float over the SLA boundaries, become overdue, or even not be disassembled.
The following risk applies only to commercial monitoring centers. The operator is forced to process a continuous stream of alerts coming from a large number of customers, and may in the confusion send an answer to the wrong address. What consequences, I think, it is not required to explain.
What to do if the load has increased, and the first line begins to sink under the flow of incidents?
Well, let's start in order:
To facilitate the work of the first line, we have developed detailed instructions and rules for handling all typical incidents. The instructions describe:

The instructions greatly help the engineer to comply with the incident SLA and quickly make a decision about whether to escalate the case further or can be managed on its own.
To solve the problem of monitoring the work of the first line, we have developed a system for evaluating waste cases, which includes more than a dozen categories. For example, informational content of the alert, correctness of the analysis and filling of the incident card, etc.
The duties of each third-line analyst include a weekly review of several dozen incidents that have been disassembled by the first line. Based on the results of the review, the analyst may comment on the development of the above categories. To make the review as useful as possible, we have developed clear criteria for the selection of cases:
A short review might look like this:
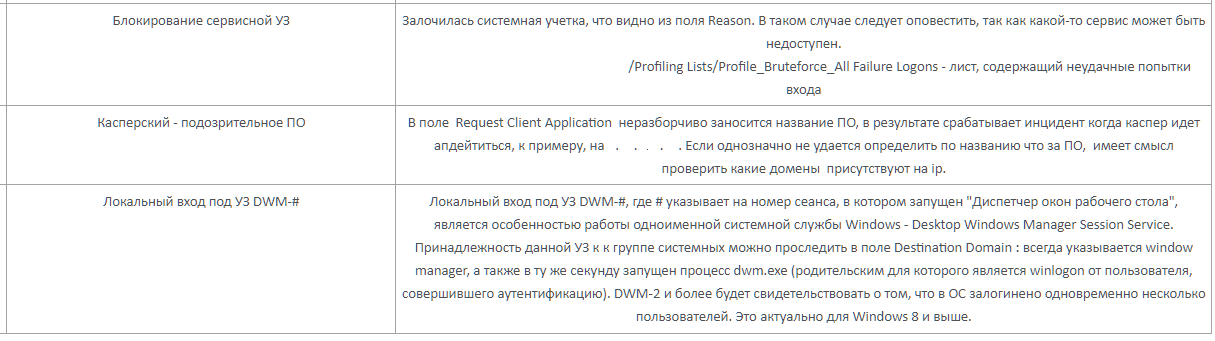
The results of the evaluations are taken into account in the motivational scheme of the first line both in a positive and in a negative direction. Such a solution to the problem, of course, is very costly. However, for us this is the best option, because the consequences of a missed incident will cost us much more. Also, public debriefings of improperly processed incidents are practiced so that the mistakes made do not recur.
To avoid the temptation to choose an easier incident, we deprived the engineers of the first line of the opportunity to choose a case for analysis. The scoring system decides for it, which distributes each incident into one of three zones: green, yellow or red. The distribution takes into account 5 indicators:
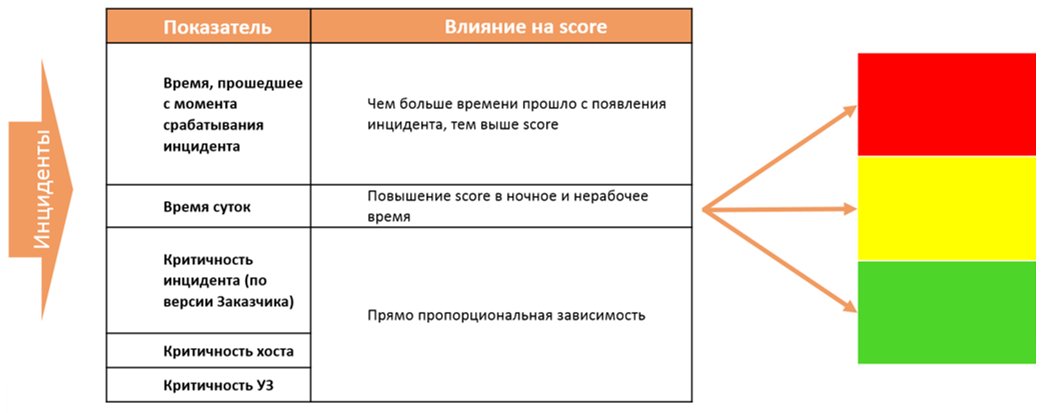
As a result, the free engineer automatically receives the incident with the highest score.
We minimized the risk of sending a response to the wrong address due to the fact that the operator does not work directly with e-mail. To automate the monitoring service, we chose the Kayako HelpDesk system, adapted it to our specifics, integrated it with the mail, and put the monitoring service for it. When sending a reply, pre-configured notification profiles are triggered, in which the routes to the respective customer’s specialists are registered. In order to be able to analyze the incident, a ticket is attached to it in the console of the SIEM system.

We predict the load, starting from the current shift load, the planned decision time and the flow density of incoming alerts. Here we again use the distribution by zones: if a lot of “red” incidents have accumulated, then it’s time to put out the fire with all available forces. If necessary, specialists of the 2nd line, or in a critical situation, a duty analyst are connected to the primary case analysis.
What is the result
Of course, these are not all the problems that we encountered on our way, and not all of them we managed to solve them completely. For example, here are a few “hung” questions: what to do with the incident if the customer did not provide feedback on it? Do I have to close it every other day or remain in unchanged condition before receiving a response? What to do if the customer reported on the elimination of the incident, and a day later it arises again? Or from the customer there is no feedback, and the incident occurs daily?
But, nevertheless, the distance traveled and the results suggest that we have reached a fairly high level of maturity in the organization of processes.
As a result, we will try to impose all the described roles and tasks on the RACI-matrix of the distribution of responsibility. Immediately make a reservation that this table describes only a small piece of the tasks and responsibility of SOC (to be honest, it’s all too big and terrible to publish in the article):

The construction of SOC is a long way, on which you can collect a lot of various rakes, even without going up to the technical aspects. I hope I managed to point out some of them and suggest workarounds. Unfortunately, I cannot guarantee that you will not encounter problems unique to you. But, as we have repeatedly said, the road will be mastered by walking. Well, prepare your forehead :).
In the first half of 2017, the cumulative average daily flow of IS events processed by SIEM systems and used by Solar JSOC to provide service was 6.156 billion . Events with suspicion of the incident - an average of about 960 per day . Every sixth incident is critical . At the same time, for our clients, including Tinkoff Bank, CTC Media or Pochta Bank, the issue of promptly informing about an attack and receiving recommendations on counteraction is very serious.
We decided to tell how we solved this problem, what problems we encountered, and what method of work organization we use in the end.
')
Team building
It is obvious that for successful incident management it is necessary to create something like dispatching service, which will coordinate the elimination of incidents and serve as a single point of contact with the customer.
In order to delineate responsibilities and responsibilities within the service, we have divided it into several levels, which over time have been scaled in accordance with the new tasks. After numerous attempts and approaches to the projectile, we got the following picture:
The first line of Solar JSOC is monitoring engineers who are responsible for the timely response to the incident and its analysis, filtering false positives, as well as for preparing an analytical report on all typed incidents. Timely reaction is considered to meet the requirements of the SLA. The first line works in shifts to ensure the response and analysis of incidents in 24x7 mode.
The second line is response engineers, specialists in specific products and areas of information security, on whom atypical incidents fall according to their area of expertise.
Usually, the Service Desk has an “inverted pyramid” structure, and, as you see, we have an hourglass. The fact is that a somewhat atypical story has arisen with the third line. The third line consists of analysts assigned to specific customers and possessing the most complete information on their infrastructure and internal processes. Escalation on them occurs in the following situations:
- Analysis of anomalous activities to identify incidents.
- Response to atypical critical incidents of their customers.
- Participation in the investigation of IS incidents not recorded by monitoring.
- Also, analysts are engaged in technical survey, connection and adaptation of source settings.
To ensure monitoring 24x7 at night, weekends and holidays, an on-duty analyst is allocated. So, it turned out that with an increase in the number of customers and scaling of the service, the need for analysts in the first place increases.
The team of specialists in forensics and reverse engineering of malware stands apart. They are connected if the incident is associated with a virus infection or penetration attack.
To remain effective, the service of the monitoring center must constantly evolve. For example, the quality of monitoring is highly dependent on the content of the SIEM system, so it is necessary to constantly develop new scenarios for identifying incidents and optimize existing ones. In addition, it is necessary to stay abreast of new technologies and evaluate the possible benefits from their use within the service. For example, a retrospective analysis of indicators of compromise by means of SIEM takes too much time, and you need to find a tool that will perform this task faster. We have created a separate group, which consists of three people and deals exclusively with the development of the service.
It is important to clarify that the content needs to be adapted for each Customer: tune the rules to reduce the number of false positives, build a connection profile for a new segment, etc. The selected group cannot cope with such a scope of work, therefore we have appointed analysts from the third line to perform this task, who have thoroughly studied the characteristics of their customers and know where and what they have pain.
Having dealt with the internal structure, we began to build processes of interaction with customers in addition to communications as part of the investigation of incidents. In other words, it was necessary to build SLA management, which would allow to control the level of service and customer satisfaction. At this stage, the role of another group of specialists arose - service managers who are involved in monitoring the parameters of the quality of services prescribed in the contract. These parameters must always be measurable, that is, representable in the form of numeric metrics.
Here are the metrics for monitoring the quality of the monitoring service we chose:
- The reaction time to the incident from the moment of its fixation is the time elapsed from the moment of the receipt and registration of the request until the beginning of work. This indicator reflects how quickly we commit to process the flow of incoming alerts. In our case, this is 20 minutes for critical incidents.
- The time of analysis and preparation of analytical information on the incident is the time elapsed from the moment of the actual beginning of work on the problem until the closing of the application. Everything is simple - the customer must understand how quickly we will be able to analyze the situation and give recommendations on counteraction. Our SLA implies that this time should not exceed 60 minutes for an ordinary incident and 40 for a critical incident.
In addition to directly monitoring the incidents, the process of providing services revealed two quite frequent activities - connecting a new event source and launching / refining the incident detection scenario. To put these operations under control, we have introduced two new metrics:
- The execution time for the connection of new typical sources. Our standard is 24 hours.
- Execution time for script rework. In accordance with SLA, we have to solve this problem in 72 hours.
Well, the last metric concerns the availability of the service. To simplify the control, we have combined the set of accessibility indicators of all the technical means involved in the provision of the service into one - the accessibility of the platform.
Let's see what kind of team we finally got together:
First problems
It would seem that the processes were regulated, the roles are painted, the interaction is established, it is time to fight. But, having started the service and connected the first customers, we began to face a shaft of problems. As the entire flow of incidents falls first on the first line, difficulties began to manifest themselves with it.
The first line in any case has a qualification lower than the others and operates 24x7. In such circumstances, there is always the risk of error: for example, closing a combat incident as false positive. If this leads to serious consequences for the customer, no one will look for the culprit, and reputational damage will fall on the whole team.
Hence the important question: how to control the quality of case analysis and analysis? If you want to simplify your life, the specialist can choose the incident easier or closer to the topic in which he understands better. With this approach, an “undesired” incident may appear that no one wants to take, and it will slowly float over the SLA boundaries, become overdue, or even not be disassembled.
The following risk applies only to commercial monitoring centers. The operator is forced to process a continuous stream of alerts coming from a large number of customers, and may in the confusion send an answer to the wrong address. What consequences, I think, it is not required to explain.
What to do if the load has increased, and the first line begins to sink under the flow of incidents?
Well, let's start in order:
To facilitate the work of the first line, we have developed detailed instructions and rules for handling all typical incidents. The instructions describe:
- Basic information on the incident (target, event sources, name).
- Trigger logic.
- Signs of false positives.
- Possible consequences of the incident.
- Recommendations on counteraction, etc.
The instructions greatly help the engineer to comply with the incident SLA and quickly make a decision about whether to escalate the case further or can be managed on its own.
To solve the problem of monitoring the work of the first line, we have developed a system for evaluating waste cases, which includes more than a dozen categories. For example, informational content of the alert, correctness of the analysis and filling of the incident card, etc.
The duties of each third-line analyst include a weekly review of several dozen incidents that have been disassembled by the first line. Based on the results of the review, the analyst may comment on the development of the above categories. To make the review as useful as possible, we have developed clear criteria for the selection of cases:
- High criticality incidents.
- Incidents involving critical sources (for example, the banking arm of the CBD and similar highly critical workstations).
- Profiling incidents (if not included in the first two categories).
- Triggered by Threat Intelligence feeds.
- New incident scenarios (less than 1 month since the launch into the first line).
A short review might look like this:
The results of the evaluations are taken into account in the motivational scheme of the first line both in a positive and in a negative direction. Such a solution to the problem, of course, is very costly. However, for us this is the best option, because the consequences of a missed incident will cost us much more. Also, public debriefings of improperly processed incidents are practiced so that the mistakes made do not recur.
To avoid the temptation to choose an easier incident, we deprived the engineers of the first line of the opportunity to choose a case for analysis. The scoring system decides for it, which distributes each incident into one of three zones: green, yellow or red. The distribution takes into account 5 indicators:
As a result, the free engineer automatically receives the incident with the highest score.
We minimized the risk of sending a response to the wrong address due to the fact that the operator does not work directly with e-mail. To automate the monitoring service, we chose the Kayako HelpDesk system, adapted it to our specifics, integrated it with the mail, and put the monitoring service for it. When sending a reply, pre-configured notification profiles are triggered, in which the routes to the respective customer’s specialists are registered. In order to be able to analyze the incident, a ticket is attached to it in the console of the SIEM system.
We predict the load, starting from the current shift load, the planned decision time and the flow density of incoming alerts. Here we again use the distribution by zones: if a lot of “red” incidents have accumulated, then it’s time to put out the fire with all available forces. If necessary, specialists of the 2nd line, or in a critical situation, a duty analyst are connected to the primary case analysis.
What is the result
Of course, these are not all the problems that we encountered on our way, and not all of them we managed to solve them completely. For example, here are a few “hung” questions: what to do with the incident if the customer did not provide feedback on it? Do I have to close it every other day or remain in unchanged condition before receiving a response? What to do if the customer reported on the elimination of the incident, and a day later it arises again? Or from the customer there is no feedback, and the incident occurs daily?
But, nevertheless, the distance traveled and the results suggest that we have reached a fairly high level of maturity in the organization of processes.
As a result, we will try to impose all the described roles and tasks on the RACI-matrix of the distribution of responsibility. Immediately make a reservation that this table describes only a small piece of the tasks and responsibility of SOC (to be honest, it’s all too big and terrible to publish in the article):
The construction of SOC is a long way, on which you can collect a lot of various rakes, even without going up to the technical aspects. I hope I managed to point out some of them and suggest workarounds. Unfortunately, I cannot guarantee that you will not encounter problems unique to you. But, as we have repeatedly said, the road will be mastered by walking. Well, prepare your forehead :).
Source: https://habr.com/ru/post/344632/
All Articles