Creating a decentralized music player on IPFS
This article describes the results of two-month experiments with IPFS. The main result of these experiments was the creation of a proof-of-concept streaming audio player capable of building a music library solely on the basis of information published in the IPFS distributed network, starting with the metadata (album name, tracklist, cover), ending directly with audio files.
Thus, being a desktop electron-application, the player does not depend on a single centralized resource.
IPFS
How it works
At first glance, the technology resembles something between BitTorrent, DC, git and blockchain. On the second one, it turns out that IPFS can store and distribute objects of any of the above mentioned protocol.
To begin with, IPFS is a peer-to-peer network of computers that exchange data. For its formation, a combination of various network technologies is used, which develops within the framework of a separate project libp2p . Each computer has a special cache, where for the time being stored data that the user has published or downloaded. Information in the IPFS cache is stored as blocks and is not fixed by default. As soon as the space becomes scarce, the local garbage collector will clean up blocks that have not been accessed for a long time. The pin / unpin methods are responsible for pinning / unpinning the information in the cache.
For each block, a unique cryptographic imprint of its contents is calculated, which then acts as a link to this content in the IPFS space. Blocks can be merged into merkle-tree objects whose nodes have their own footprint, calculated on the basis of lower node / block prints. Here begins the most curious.
IPLD-DAG
IPFS consists of a large number of smaller Protocol Labs projects, one of which is called IPLD (InterPlanetary Linked Data). I'm not sure that I can correctly explain the essence, so I'll leave the link to the specification curious.
In short, the architecture described in the previous paragraph is so flexible that it can be used to recreate more complex structures, such as the blockchain, unix-like file system or git repository. To do this, use the appropriate interfaces / plugins.
So far, I have worked exclusively with the dag interface, which allows you to publish regular JSON objects to IPFS:
const obj = { simple: 'object' } const dagParams = { format: 'dag-cbor', hashAlg: 'sha3-512' } const cid = await ipfs.dag.put(obj, dagParams) If successful, a content identifier (CID) object is returned, inside which a unique imprint of the published information is stored, as well as methods for converting it into various formats. That way you can get the base-string.
const cidString = cid.toBaseEncodedString() console.log(cidString) // zdpuAzE1oAAMpsfdoexcJv6PmL9UhE8nddUYGU32R98tzV5fv This string can be used to get data back using the get method. In this case, no additional parameters are required, since the line contains information about the data format and the encryption algorithm used:
const obj = await ipfs.dag.get(cidString) console.log(obj.value) // { // simple: 'object' // } Further more. You can publish a second object, one of the fields of which will refer to the first.
const obj2 = { complex: 'object', link: { '/' : cidString // cid- } } const cid2 = await ipfs.dag.put(obj2, dagParams) const cid2String = cid2.toBaseEncodedString() When trying to get obj2 back, all internal links will be resolved, unless otherwise specified by a special parameter.
const obj2 = await ipfs.dag.get(cid2String) console.log(obj2.value) // { // complex: "object", // link: { // "simple" : "object" // } // } You can request the value of a separate field, for which you need to add a postfix of the form /_ field_name to the CID line.
const result = await ipfs.dag.get(cid2String+"/complex") console.log(result.value) // object In this way, you can “walk” around the entire object, including its links to other objects as if they were one large object. Since links are cryptographic hashes of content, an object cannot contain a link to itself.
The concept of IPLD implies the ability to refer not only to other DAG objects, but also any other IPLD structures. Thus, one field of your object can refer to a git-commit, and another to a bitcoin transaction.
Pub / Sub
A fundamental role in the implementation of the conceived functionality was played by the pubsub interface. With it, you can subscribe to p2p-rooms, united by a special key line, send your messages and receive other people.
const topic = ' ' const receiveMsg = (msg) => { // } await ipfs.pubsub.subscribe(topic, receiveMsg) const msg = new Buffer('') await ipfs.pubsub.publish(topic, msg) One of the first pubsub-based applications was the irc-like p2p-chat orbit ( still working , if that). You subscribe to the channel, you receive messages, the story is stored between the participants and gradually “forgotten”. Such a Vypress for the entire web.
Both in go and js versions of IPFS, the pubsub interface is turned on by a special parameter, since it is still considered an experimental technology.
Idea
At some point in my audiophile life, I noticed that I had been listening to music for a long time exclusively using Google Music. And not only on the phone, but already on the desktop. There are several reasons, but the main one is significantly fewer clicks between “I want to listen” and “listen” in most everyday situations in comparison with the same torrents. The second most important reason is the size of the available library. Very rarely, I don’t find what I’m looking for (much more often I meet regional restrictions). But this is not an advantage over torrents, but other streaming services.

It became curious whether it is possible to create an application comparable in usability based solely on distributed data sources. Over time, two main conditions were formulated under which this task becomes feasible:
- the ability to directly track the appearance of data in a distributed network,
- data published by network members should be standardized.
In the BitTorrent ecosystem, when someone wants to download something, in most cases he will have to first access the torrent directory - a regular site located on a regular server for a normal ip under a regular domain. The first condition is necessary so that the application can form a local database automatically and without the participation of centralized resources.
The second condition is the most important. To execute it, it is necessary that the information published by the participants of the distributed network is executed in accordance with the model / scheme that is known in advance by all the others. This makes the distributed data space available for search and filtering systems, increases their effectiveness.
As it turned out, IPFS makes it possible to provide both of these conditions, and quite effectively.
Implementation
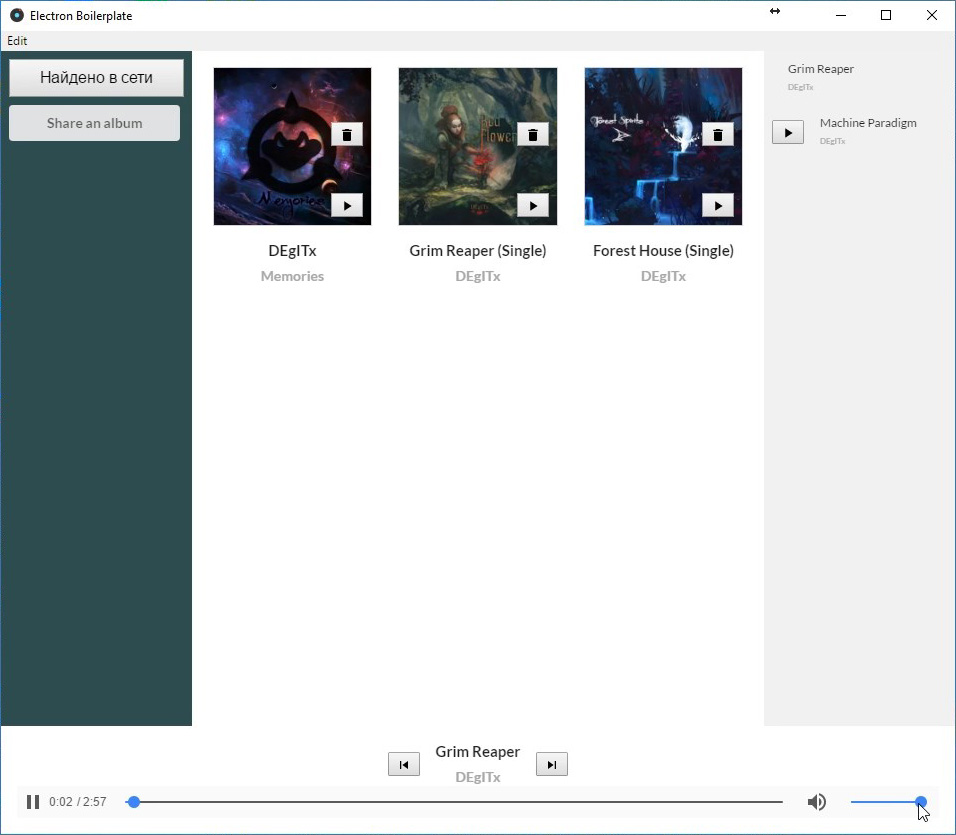
At present, "Phathofon" is a primitive record player. Here is almost all of its functionality:
- posting albums in IPFS
- list of found albums
- opportunity to play an album
Let's start with the publication. In the previous chapter, I said that information in a distributed network should be somehow standardized. In the "Pathhone" this task is achieved through the album json-scheme.
const albumSchema = { type: "object", properties: { title: { type: "string" }, artist: { type: "string" }, cover: { type: "string" }, tracks: { type: "array" items: { type: "object", properties: { title: { type: "string" }, artist: { type: "string" }, hash: { type: "string" } } } } } } In accordance with this scheme, a specific copy is checked and then published. For this is the usual form of input.

At first it was assumed that the publication will occur directly from the file system. Standardization of data would be achieved using a special .meta file, where all the necessary properties and connections of the instance would be described. But after experimenting a little I came to the conclusion that doing it through the interface of the application itself would be more convenient, clearer and more efficient.

An important detail - the attached files are published separately using ipfs.files.add() . Returned CIDs are inserted into the corresponding input in a separate line. The input is left in case there is no file at hand, but its CID is known.When the form is completed and the user presses "ADD ALBUM" the final JSON data is first checked for compliance with the scheme, then published using the DAG interface, after which the resulting CID in the form of a buffer is sent to a special pubsub room.
const isValid = validateAlbumObj(albumObj) // if (isValid) { const albumCid = await ipfs.dag.put(albumObj, dagParams) // dag await ipfs.pubsub.publish(albumSchemaCidString, albumCid.buffer) // CID pubsub } The obvious solution would be to use something like "albums", "music-albums" or, in extreme cases, "pathephone" as a room key, if you want to isolate the network within your application. But then a cleverer thought came to mind - to use the CID string of the album's json scheme as a key. In the end, it is the data scheme that truly merges all copies of the application. Moreover, it is from this room that one can expect that all received messages will contain verified instances of this scheme.
const handleReceivedMessage = async (message) => { try { const { data, from } = message // data - , from - id const cid = new CID(data).toBaseEncodedString() // , CID-, CID- base- const { value } = await ipfs.dag.get(cid) const isValid = validateAlbumObj(value) // if (isValid) { // value - , , } else { throw new Error('invalid schema instance received') } } catch (error) { // } } const albumSchemaCid = await ipfs.dag.put(albumSchema, dagParams) const albumSchemaCidString = albumSchemaCid.toBaseEncodedString() await ipfs.pubsub.subscribe( albumSchemaCidString, handleReceivedMessage ) As you can see, each "arriving" object is still checked for compliance with the scheme, since no one interferes with any member of the network, knowing the key, to purposefully begin to flood the room. At the same time, the uniqueness of the key minimizes the likelihood of accidental intervention. On the other hand, if any other application starts to use the same scheme as the “Gambler”, then together they will begin to form and use the same data space, which can be a plus.
Behind the brackets are some application-specific things, like storing an object in a database.
The process of publishing an album on one computer and getting it on another can be seen on the video . The speed is almost instant, but it depends on a large number of factors. There was a case when the computers did not end up in one “swarm”, so the transfer failed.
Metabin gate
I described everything described above in the form of an npm-module called @metabin/gate . It hides the details, leaving the developer only to transfer the ipfs node and the json scheme:
const gate = await openGate( ipfsNode, // js-ipfs js-ipfs-api schema // json-schema, (instance, cid) => { // instance - // cid - base-encoded } ) await gate.send(instance) // await gate.close() findings
IPFS is one of the most advanced technologies for distributed information sharing. Despite the fact that both (and go and javascript) versions are in the alpha stage, they are already used by some relatively popular applications, like OpenBazaar or d.tube. Another thing is that they use it mainly only as a file storage.
This can be understood, given that IPFS is mainly regarded as a kind of alternative to BitTorrent. The concept of IPLD and the capabilities of the respective interfaces are rarely in the spotlight. Although, in my opinion, this is the most promising development of Protocol Labs, which makes it possible to distribute normal data objects via IPFS.
pubsub uncomplicatedly combining files , dag and pubsub interfaces, the developer gets a free, self-organizing data source for his application. Add Electron and get a pretty tempting technology stack:
- does not require servers
- does not require a domain name
- speed of data distribution is limited only by the quantity and quality of participants
- complexity and data structure is limited only by your imagination
- don't bother with cross-browser support
- high resistance to censorship
Of course, not all applications need such autonomy at all, given that it leads to a loss of control over the content. Not to mention that all this is quite an experimental area. How such a network will scale, how it will affect performance, whether it is possible to influence this process - there are many questions that have not yet been formulated.
Nevertheless, the possibilities and prospects are curious.
Links
')
Source: https://habr.com/ru/post/344410/
All Articles