Generation of natural speech in a 3CX call center based on deep learning
Introduction
Often we need to reproduce audio information that has not been recorded in advance and is dynamically extracted from the data source: the name of the person, the name of the city, the status of the order, etc. Especially this feature is in demand in call centers and self-service portals.
For this, it is best to use TTS (text-to-speech) technology, since it dynamically creates the necessary audio files, and the voice application running on the 3CX server loses them to the subscriber. To generate audio files, a certain web service is used, after which a local WAV file is created. When the conversation with the subscriber is completed, the file is deleted to free up disk space.
For this feature, 3CX should register an account with Amazon Web Services. 3CX uses the Amazon Polly TTS web service. After exploring various TTS services, we found that Amazon Polly has excellent generation quality, good language coverage , many different voices and a very affordable price. It is also free for the first year of use! On the other hand, in the future we plan to add support for TTS from other global manufacturers.
')
Please note - for TTS generation, you must use 3CX v15.5 SP2 and higher.
3CX Call Flow Designer has received a new type of audio message Text to Speech Audio Prompt. You can choose it in any place where you want to play the message, for example, in components Prompt Playback, Menu, User Input and others.
In this article, we’ll show you how to create an Amazon Web Services account, enable Amazon Polly, and start using the Text to Speech Audio Prompt component to generate natural speech in your call center.
Please note - the 3CX CFD development environment is free. But voice applications will be run only on 3CX Pro and Enterprise editions . Download CFD from here .
For your convenience, a demo project of this voice application comes with the 3CX CFD distribution and is located in the Documents \ 3CX Call Flow Designer Demos folder.
Create an Amazon Web Services (AWS) account
Before you start working with a CFD application, create an Amazon Web Services account. To do this, read the manual from Amazon.
Creating an Identity and Access Management (IAM) Service User
After creating an AWS account, create a user whose credentials our voice application uses to access AWS. Follow the Amazon manual . Specify the type of access Programmatic access. When setting permissions, select Attach existing policies directly, then find and tick AmazonPollyFullAccess.
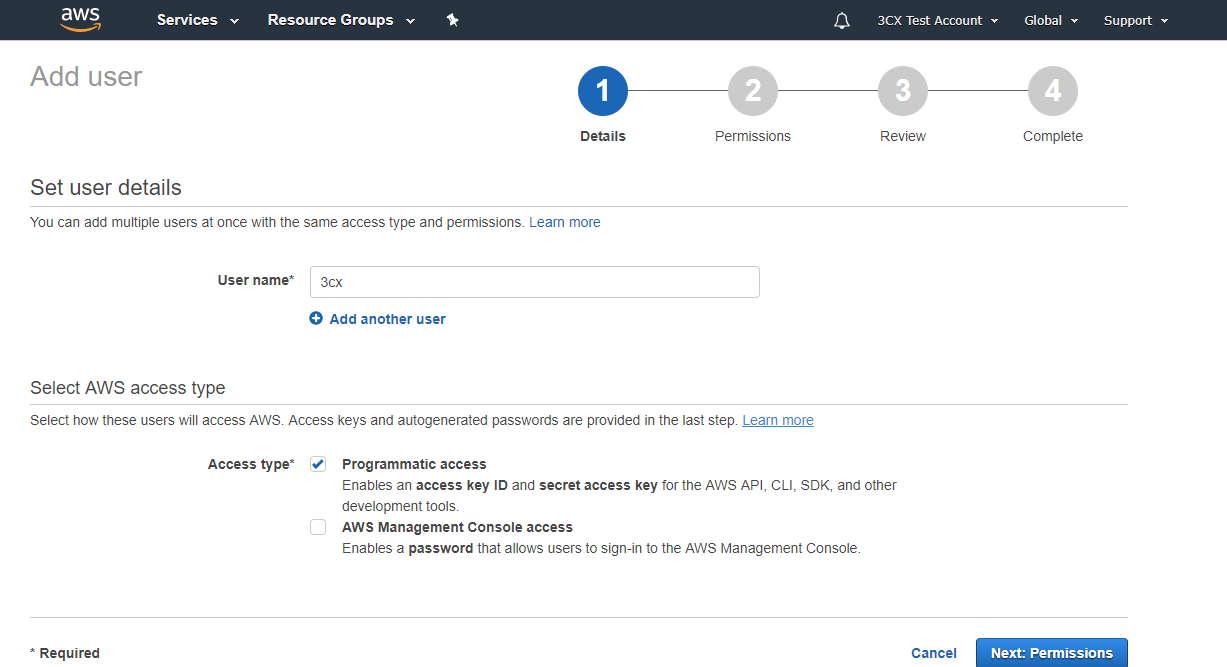
Then go to the user settings in the Security credentials section and click Create access key. Fix the Access key ID and Secret access key - this data will be required when setting up the TTS service in the voice application.

Attention! Check out the Amazon Polly TTS restrictions . These restrictions should not create problems in most CFD applications, but keep them in mind.
Project creation
To create a CFD project, go to File → New → Project, specify the project location folder and its name, for example, TextToSpeechDemo.
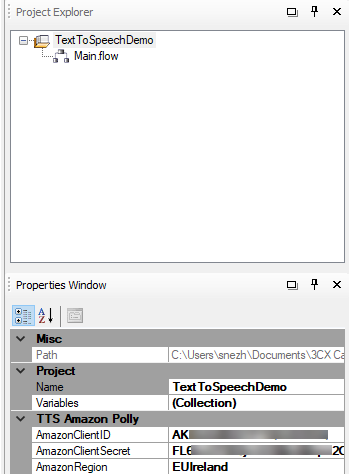
Select the project in the Project Explorer section. Consider the project parameters (section Properties), which must be specified for the operation of TTS:
- AmazonClientID - Access key ID generated above.
- AmazonClientSecret - Secret access key, generated above.
- AmazonRegion — select the AWS geographic region nearest to the 3CX server location.
These parameters will be used in any message of the Text To Speech Audio Prompt type in this project.
Adding the Prompt Playback component
As mentioned earlier, TTS is usually used to generate speech from text obtained from a database or web service. But to simplify our example, we will prepare a short phrase, add a variable from our voice application to it and convert it all into speech. We will define the AccountBalance variable and set its value to 100. Then we will prepare the phrase: “Your account balance is $ 100”.
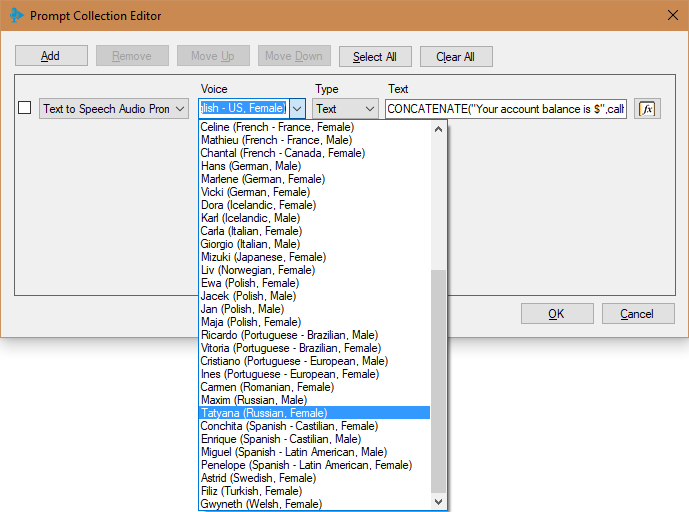
To add the Prompt Playback component:
- Move the Prompt Playback component to the Main callflow application window. Select a component and in the properties section rename it to playPrompt.
- In the same place, open the Prompt Collection Editor by clicking the button next to the Prompts property.
- Click Add to add a new message to the collection and change the message type to Text to Speech Audio Prompt.
- Select the voice you want to use. The list of votes is sorted by language. The voices available for Amazon Polly are listed here . If Amazon releases a new voice that is not listed, you can start using it by entering an identifier from the Name / ID column. If you want a certain voice to always be installed in the application by default, select it in the 3CX CFD Tools> Options> Component Templates> Text To Speech menu. For our example, we will use the voice of Joanna (English - US, Female).
- Select text type: Text and SSML (Speech Synthesis Markup Language). Typically, you will use Text. At the same time, the value of the Text property is a normal character set (plain text), and the TTS service will synthesize it as is. If you specify the SSML type, the Text property value is an XML file in accordance with the SSML specification. SSML allows you to set various speech parameters: pronunciation, volume, speed. For more information, see the manual Using SSML . In our example, the Text type is used.
- Specify an expression for the Text option. Depending on the type of text selected in the previous step, the expression should return plain text for synthesis or XML data, in accordance with the SSML specification. For our example, we use the following expression:
CONCATENATE("Your account balance is $",callflow$.AccountBalance) Compiling and installing the application on the 3CX server
Voice application is ready! Now it should be compiled and uploaded to the 3CX server. For this:
- Go to Build> Build All, and the CFD will create the PredictiveDialerDemo.tcxvoiceapp file.
- Go to the 3CX management interface, in the Call Queues section. Create a new Call Queue, specify the name and extension number of the Queue, and then set the Voice Applications option and download the compiled file.
- Save changes to the queue. Call the Queue extension number to test the application. Please note - at the very first call to the application, TTS generation can be performed with a delay of several seconds. This is related to the authentication process and occurs only once.
Conclusion
Typically, synthesized speech uses several static messages, for example, a greeting for users or a choice of a menu option, and several dynamic messages — for example, an account balance. It is advisable to use the Polly TTS service only for variable data - this will avoid the additional cost of synthesizing duplicate phrases. On the other hand, it is necessary that all phrases be pronounced in the same voice. To do this, it’s best to create ready-made voice files for static phrases via the Amazon Polly console and upload them as WAV files to a voice application. Use these files in regular Audio File Prompt messages instead of repeated dynamic generation.
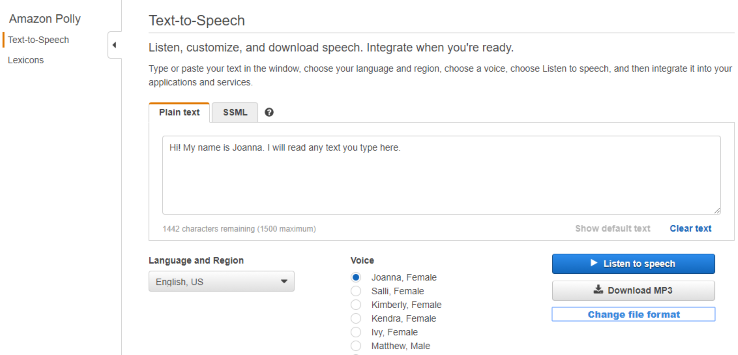
In the Amazon Polly console, select your language, region, desired voice, enter the desired text, and click Download MP3. Please note, 3CX uses the audio format WAV, Mono, 8.000 Hz, 16 bit. Therefore, after downloading the file, convert it to a supported format, as indicated here .
Source: https://habr.com/ru/post/344260/
All Articles