Atos IT Challenge Launch Report
Do you have a thing called a pet project or a side project? The same project that you would do for your own pleasure, for yourself, for self-development or for expanding your portfolio. Personally, for a long time I had nothing to show. However, as part of the Atos IT Challenge 2018 competition that started this fall, I had the opportunity to start such a project.
About competition
Let me explain: for the seventh year in a row, Atos chooses some hot topic in the IT world and invites teams of students all over the world to come up with and implement an idea dedicated to this topic. The competition is quite significant: students who have gone to the main tour will work half a year under the guidance of an experienced mentor, and only in June will they learn about the results. The prize fund against the background of such a volume of work is not amazing: 10,000, 5,000 and 3,000 euros settled down on the prize steps, but yes, in fact, it’s not money that attracts above all.
I think the main thing is the opportunity to upgrade in a new area for myself, at the same time applying it in a real project. And implementing it all in the company of his comrades, of course.
About this year's theme
“Chat bots for life and business” - this is the core, on the basis of which you need to come up with your own idea. Chat means communication, speech and text. Therefore, without knowledge of NLP - “natural language processing”, or “natural language processing” - nowhere.
As it is known, students perceive information best of all on the night before the exam, and we, guided by the same logic, decide to participate, and to improve our NLP knowledge along the way. Things like a simple text classification have long been subject to us, but as part of the competition we have to figure out the Q & A systems, the summarization algorithms - in general, everything becomes more interesting.
About applications
Until December 1, participants submitted applications with descriptions of ideas, and, I must say, it turned out to be a difficult task to make an application. We were asked for the business model of the future application, and technical feasibility, architecture, and final benefits for users and our partners.
We are classic techie students, and we were with business models before the competition and are not really familiar with them. However, thanks to the good book by Osterwalder and Pigne, Building Business Models, they were able to portray something similar to the truth.
Applications, of course, are seen only by the judges, however, the participants can see the name and description - summary - of the ideas of their rivals.
About Us
We are four students of the Voronezh State University. Four enough creative people who love art and music. Perhaps that is why we began to start not from the business applications of chatbots, but from a topic that was far from monetary gain: painting.
It would be interesting to you to talk with the robot about the picture, what do you see? Discuss the details, share your impressions?
For us, the answer is obvious: of course, it would be interesting! Great, but what is the best way to communicate with the system if you don't want to look at the phone? Of course, in a voice.
This is how the primary idea was formed: the bot with whom you talk about art and what you see.
The perfection of any interface in its absence. You just say what you think and get an answer. No script, framework or commands. In a word, “Zen” - and in this we see the value and future of this kind of systems and applications.
About others
Before December 1, applications were filed, and a week later, on December 7, a list of ideas from other teams was opened to us. There were a lot of them: 204.
Here are some that we liked:
- Drawing up an identikit on the description of the appearance of the suspect. Here, the dialogue part seems to be understandable, and the application is obvious.
- Virtual teacher . The team claims that they will make a hologram that would tell the material and answer questions.
But ... weird:
- Receiving diagnoses of symptoms , calling a husband for an hour - in short, many services packed in chat bots are not quite clear why.
- Chat bots as chat bots: to talk. And that's all. ( here or here )
- And finally, our favorite : an application that works like an alarm clock when you reach a certain location. Where is the bot? We have not found. But “works on iOS, Android, Windows Phone and BlackBerry”.
Read the description of each of the ideas, of course, laziness. And if a programmer is too lazy to do something, then he writes a program for this, doesn't he?
Primary data analysis
Data acquisition
At first, everything is simple: import libraries and download data from the site.
import requests as rq import bs4 as bs from toolz.functoolz import excepts root = 'https://www.atositchallenge.net/students-ideas/' soup = bs.BeautifulSoup(rq.get(root).text, 'html5lib') data = soup.select('div.ideas-wrapper a') len(data) # -> 204 mk_safe = lambda f: excepts(Exception, f, lambda _: np.NaN) def extract_short_info(r): get_href = mk_safe(lambda x: x['href']) get_title = mk_safe(lambda x: x.select_one('div.caption-container h3').text) get_uni = mk_safe(lambda x: x.select_one('div.caption-container p.university').text) get_flag = mk_safe(lambda x: x.select_one('img.flag')['alt']) return { 'url': get_href(r), 'title': get_title(r), 'university': get_uni(r), 'country': get_flag(r) } df = pd.DataFrame([extract_short_info(x) for x in data]) df.country = df.country.str.split(' ').apply(lambda x: x[-1]) df.country = df.country.map({'Turkey': '', 'China': '', 'Singapore': '', 'India': '', 'Kong': '', 'France': '', 'States': '', 'Taiwan': '', 'Kingdom': '', 'Senegal': '', 'Philippines': '', 'Malaysia': '', 'Canada': '', 'Brazil': '', 'Russia': '', 'Romania': '', 'Belgium': '', 'Japan': '', 'Germany': '', 'Cameroon': '', 'Poland': '','Netherlands': '', 'Spain': '','Egypt': '', 'Mexico': '','Morocco': '','Austria': ''}) Our intermediate result:
df.head() 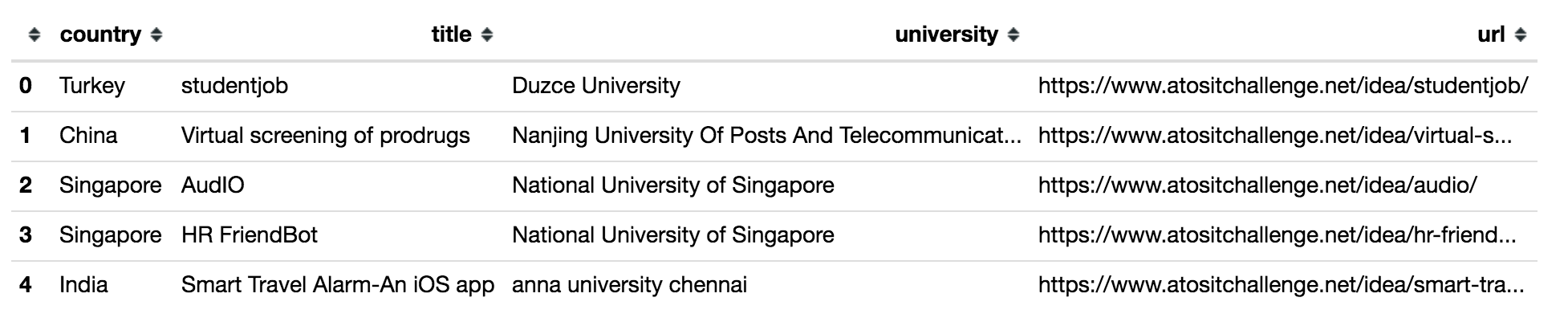
The url column contains pages with each of the ideas. On them, however, a little bit of new information: the composition of the team and the text of the description. Download them and attach to our original dataframe:
def download_description(title, url): try: soup = bs.BeautifulSoup(rq.get(url).text, 'html5lib') get_summary = mk_safe(lambda x: x.select_one('p.summary').text) get_members = mk_safe(lambda x: x.select('p.members')[0].text) summary = get_summary(soup) members = get_members(soup) except: return None return { 'title': title, 'summary': summary, 'members': members } results = list(df.apply(lambda row: download_description(row['title'], row['url']), axis=1)) df_summaries = pd.DataFrame(list(results)) df = df.merge(df_summaries) And the final result - in the studio!
df.head() 
Visualization
Well, let's see what we're dealing with? What do we have with the countries?
counts = df.country.value_counts() counts.plot.bar(); 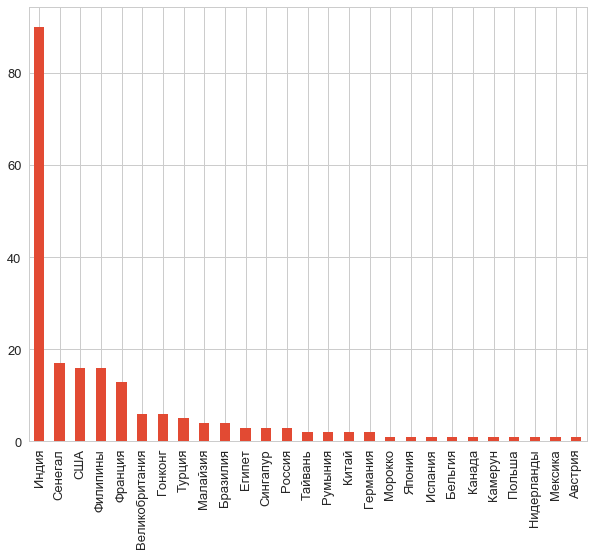
Gee! Students from India are no longer an example.
india_part = pd.Series(data=[counts[0], counts[1:].sum()], index=['', ' ']) f, ax = plt.subplots(1, 1, figsize=(10, 10)) india_part.plot.pie(ax=ax); ax.set_ylabel(''); 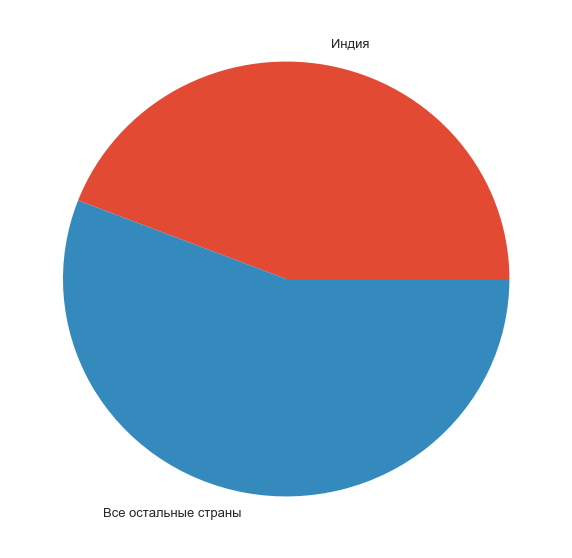
Indeed: almost half of all participants are guys from the country of sacred cows and cost-effective space programs.
The shares of the remaining participants by country were distributed like this:
f, ax = plt.subplots(1, 1, figsize=(11, 11)) counts[1:].plot.pie(ax=ax); ax.set_ylabel(''); 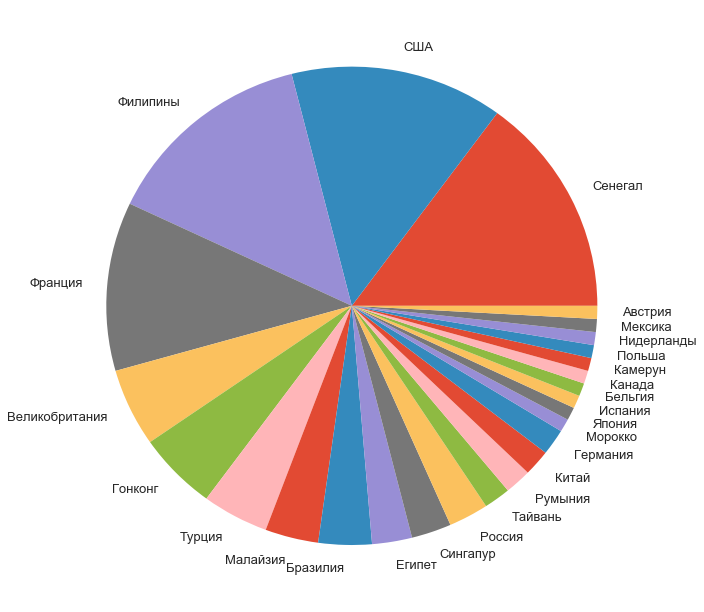
And how are you doing with universities?
university_counts = df.groupby('country')[['university']]\ .agg('nunique')\ .sort_values(by='university', ascending=False) university_counts\ .plot.bar(colors=['#ffea2d' if k != '' else '#ff2d2d' \ for k in university_counts.index]); plt.gca().legend_.remove() plt.ylabel(' '); plt.xlabel(''); y_ticks = list(plt.yticks()[0]) y_ticks.remove(0) plt.yticks(y_ticks + [1]); 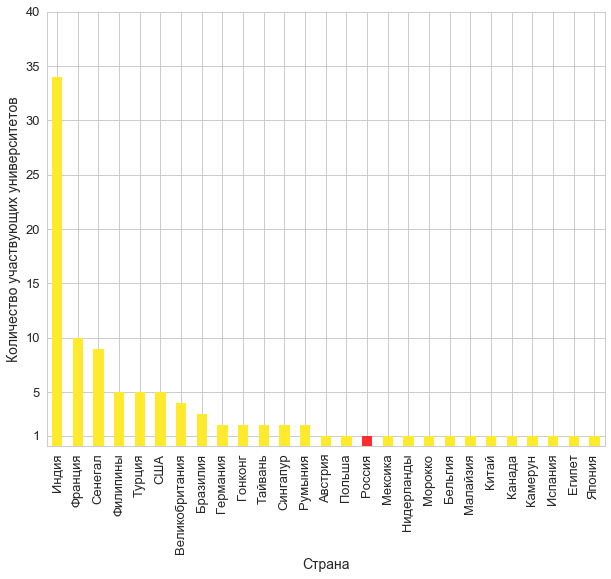
Yes. Like this. Disappointingly. All three participating teams from Russia from the same university are ours. Where are you guys, well, how so? ..
df['number_of_members'] = df.members.str.split('|').apply(lambda x: len(x)) avg_members = df.groupby('country').agg('mean').sort_values(by='number_of_members', ascending=False) avg_members.plot.bar(colors=['r' if x=='' else ('#2dbcff' if x != '' else '#ffea2d') for x in avg_members.index]); plt.gca().legend_.remove() plt.xlabel(''); plt.ylabel(' '); 
We only managed to get around India only in the strength of friendship: the graph shows that our teams are on average more complete.
Well, let's proceed to the most meat, - to the text?
Text analysis
Team names
As a bot you name, he will talk about that. Maybe the trends of this year in the themes of bots will be visible from the names of the projects? Let's get a look:
import re from nltk import word_tokenize from nltk.corpus import stopwords from nltk import FreqDist titles = ' '.join(df.title.values) tokens = [x.lower() for x in word_tokenize(titles) if re.match("[a-zA-Z\d]+", x) is not None] tokens = [x for x in tokens if x not in stopwords.words('english')] We remove the obviously unrelated words, which, however, are sure to pop up (“chat”, “chatbot”, “intelligent”, “system” and others) and build a frequency dictionary:
fd = FreqDist(tokens) [fd.pop(x) for x in ['chatbot', 'bot', 'service', 'ai', 'virtual', 'companion', 'system', 'app', 'intelligent', 'chatbots', 'robot', 'assistant', 'smart', 'solutions']]; len(fd) # 328 plt.figure(figsize=(18, 3)); fd.plot(40, cumulative=False) 
The truth is already looking: this year, bots are popular, designed to help with health. They are caught up with bots dedicated to travel and shopping. Is the application obvious? Sound? Good project implementation will show.
Descriptions of ideas
We now proceed to the processing of text descriptions of ideas.
from nltk import SnowballStemmer summaries = '. '.join(df.summary) sbs = SnowballStemmer('english') tokens = [x.lower() for x in word_tokenize(summaries) if re.match("[a-zA-Z\d]+", x) is not None] tokens = [x for x in tokens if x not in stopwords.words('english')] # 18546 tokens = [sbs.stem(x) for x in tokens] len(tokens) # 18623 fd = FreqDist(tokens) len(fd) # -> 3301, 4877 plt.figure(figsize=(18, 3)); fd.plot(40, cumulative=False) 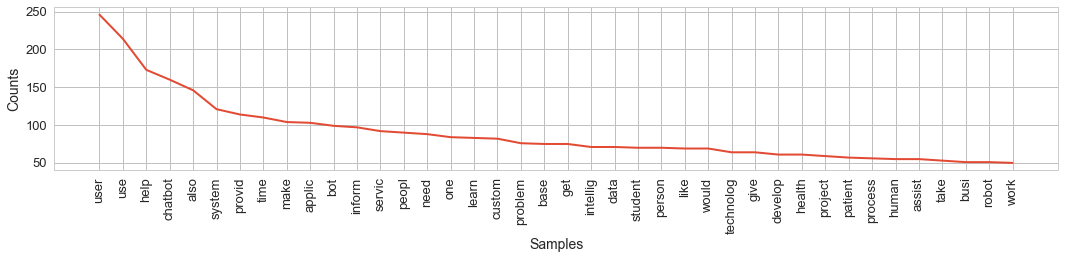
The resulting words in pairs form funny, but, in general, the correct statements are: “users use”, “chatbot helps” and “also the system provides”. Paying attention to the most common words, one can easily imagine what the average text with the description looks like: it is that problems are solved with the help of a bot, the project is technologically advanced and serves people. All right! But I hope that the judges have enough patience to finish reading these two hundred altruistic odes, ..
Short retelling
.. if there is not enough patience, with the help of the famous gensim, you can ask to display a brief summary of all this mass:
from gensim.summarization import summarize, keywords print(summarize(summaries, word_count=150)) It’s not a problem. The cabling is where you need to travel. it can be a nightlife.
And keywords:
ks = keywords(summaries, words=30, lemmatize=True) for i, x in enumerate(ks.split('\n')): ending = '\t' if (i+1) % 4 != 0 else '\n' print(x.ljust(14), end=ending) users likely inform helped basing provider chatbotics servicing humanity persons people data timings uses learns news medications health differences applicability technological customization problems businesses bots foods student experiences needed And then Ostap suffered
And then I thought that I could force generative models to make new descriptions of new ideas! Let's go!
import markovify markov = markovify.Text(summaries) for i in range(10): print(markov.make_sentence()) In the form of a liquid It is a process that has been carried out.
Well archiBOT is your loyal helper, pick up the user queries.
But due to their preferences like location, price range, seating capacity, etc. There will be a lot of help.
It is a type of third party.
He said that he was not satisfied with the general personality tests.
Based on the disease.
Though the Talking Glossary is available in the field or farms.
No more waiting for a subscription.
He didn’t need to panick for nothing.
We can be classified in the university.
Particularly cool moments and striking:
BEWARE everything knows you
After the results are so intrigued, you can find the original idea and see what its essence is.
You can’t make it a little bit more than that. to this bot. it can help you in any issue. There are a few simple questions. These questions are based on Cognitive Behavioral Therapy. Although it can never be a real therapist, it can be him / her up. He is going to get it. It is not a question of any kind.
Word cloud
Since everyone loves word clouds (and do not say that you are not one of those!), I could not make it to you.
from wordcloud import WordCloud from PIL import Image mask_image = Image.open("mask.png") mask = np.array(mask_image) wordcloud = WordCloud(background_color="white", colormap='plasma', width=mask_image.width, height=mask_image.height, max_words=2000, mask=mask, stopwords=stopwords.words('english')) wordcloud.generate(summaries); wordcloud.to_file("cloud.png"); plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.show() 
Conclusion
There is still a lot of work ahead of us, and we hope that we will not be disappointed with its result. Judges have no less difficult work to do: in the stated topics there are health care, recruitment, shopping, education, travel, and even trading and bitcoins!
In the meantime, we are in a low start position. We prepared a twitter account in order to write there notes about the development in progress. By the way, the advertising mini-video was even filmed if you would be interested.
I will be glad to hear any criticism, comments at your service.
')
Source: https://habr.com/ru/post/344254/
All Articles