Convolution network in python. Part 2. Derivation of formulas for training models

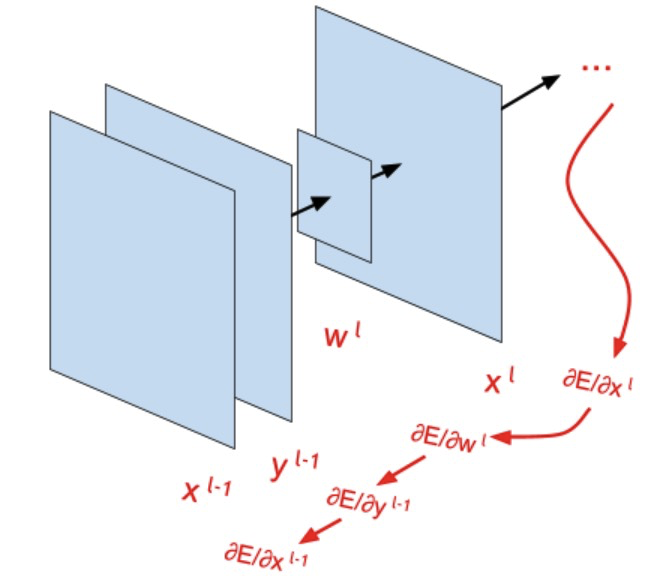
In the last article, we examined conceptually all the layers and functions of which the future model will consist. Today we will derive formulas that will be responsible for teaching this model. Layers will be disassembled in reverse order - starting with the loss function and ending with the convolutional layer. If there are difficulties in understanding the formulas, I recommend that you familiarize yourself with the detailed explanation (in the pictures) of the error back-propagation method, and also recall the rule of differentiation of a complex function .
Derivation of a formula for back propagation of an error through the loss function
This is just a partial derivative of the loss function. on the exit model.
With derivative in the numerator, we refer as a derivative of a complex function: . Here, by the way, you can see how reduced and , and it becomes clear why in the formula we initially added
At first I used the standard deviation, but for the classification problem it is better to use a cross-entropy ( link with explanation). Below is the formula for backprop, I tried to write the formula output in as much detail as possible:
Remember that
Output backprop formula through activation functions
... via ReLU
Where - designation backprop through the activation function.
')
That is, we skip the error through those elements that were selected maximum during the direct passage through the activation function (multiply the error from the previous layers by one), and do not skip for those that were not selected and, accordingly, did not affect the result (multiply error from previous layers to zero).
... through sigmoid
Here you need to remember that
Wherein Is a sigmoid formula
Further we denote as (Where )
... also via softmax (or here )
These calculations seemed to me a bit more complicated, since the softmax function for the i-th output depends not only on its but from all others , the sum of which lies in the denominator of the formula for direct passage through the network. Therefore, the formula for backprop “splits” into two: the partial derivative with respect to and :
Apply the formula Where and
Wherein
And the partial derivative with respect to :
Based on the formula above, there is a nuance with what the function should return (in the code) when back propagating an error for with softmax, as in this case for calculating one all are used or in other words each affects all :

In the case of softmax will be equal to (sum appeared!), that is:
At the same time for all we have, it is backprop through the loss function. It remains to find for all and all - that is, it is a matrix. Below is the matrix multiplication in the “unfolded” form, so that it is better to understand why - matrix and where matrix multiplication comes from.
It was just about this last in the decomposition matrix - . See how to multiply matrices and we get . So, the output of the backprop function (in the code) for softmax should be the matrix , when multiplied by which is already calculated at that time we will get .
Backprop through a full mesh network

Displaying the backprop formula for updating the weights matrix fc networks
We decompose the sum in the numerator and we find that all partial derivatives are equal to zero, except for the case that equals . This case occurs when . The dash here is to denote the “internal” cycle by that is, it is a completely different iterator, not related to of
And this is how it will look like a matrix:
Dimension of the matrix equals , and in order to produce a matrix multiplication, the matrix should be transposed. Below I quote the matrices completely, in a “unfolded” form, so that the calculations seem clearer.
Displaying the backprop formula to update the matrix
For bias, all calculations are very similar to the previous item:
It is clear that
In the matrix form, too, everything is quite simple:
The output of the formula is backprop through
In the formula below, the amount of arises from the fact that each connected to each (remember that the layer is called fully connected )
We decompose the numerator and see that all partial derivatives are equal to zero, except for the case when :
And in matrix form:
Further, the matrix in the "open" form. I note that I deliberately left the indices of the latest matrix in the form in which they were before transposition, so that it was better to see which element went where after transposition.
Further we denote as , and all formulas for back propagation of error through subsequent layers of a fully meshed network are calculated in the same way.
Backprop through Maxpooling
The error “passes” only through those values of the initial matrix that were chosen as the maximum at the max-cooling step. The remaining error values for the matrix will be zero (which is logical, because the values for these elements were not selected by the max-spooling function during the direct passage through the network and, accordingly, did not affect the final result).
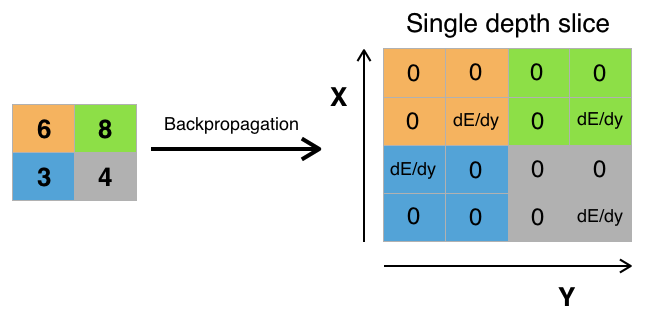
Here is the python maxpooling implementation:
code_demo_maxpool.py
git link
import numpy as np y_l = np.array([ [1,0,2,3], [4,6,6,8], [3,1,1,0], [1,2,2,4]]) other_parameters={ 'convolution':False, 'stride':2, 'center_window':(0,0), 'window_shape':(2,2) } def maxpool(y_l, conv_params): indexes_a, indexes_b = create_indexes(size_axis=conv_params['window_shape'], center_w_l=conv_params['center_window']) stride = conv_params['stride'] # y_l_mp = np.zeros((1,1)) # y_l y_l_mp_to_y_l = np.zeros((1,1), dtype='<U32') # backprop ( ) # if conv_params['convolution']: g = 1 # else: g = -1 # # i j y_l , for i in range(y_l.shape[0]): for j in range(y_l.shape[1]): result = -np.inf element_exists = False for a in indexes_a: for b in indexes_b: # , if i*stride - g*a >= 0 and j*stride - g*b >= 0 \ and i*stride - g*a < y_l.shape[0] and j*stride - g*b < y_l.shape[1]: if y_l[i*stride - g*a][j*stride - g*b] > result: result = y_l[i*stride - g*a][j*stride - g*b] i_back = i*stride - g*a j_back = j*stride - g*b element_exists = True # , i j if element_exists: if i >= y_l_mp.shape[0]: # , y_l_mp = np.vstack((y_l_mp, np.zeros(y_l_mp.shape[1]))) # y_l_mp_to_y_l y_l_mp y_l_mp_to_y_l = np.vstack((y_l_mp_to_y_l, np.zeros(y_l_mp_to_y_l.shape[1]))) if j >= y_l_mp.shape[1]: # , y_l_mp = np.hstack((y_l_mp, np.zeros((y_l_mp.shape[0],1)))) y_l_mp_to_y_l = np.hstack((y_l_mp_to_y_l, np.zeros((y_l_mp_to_y_l.shape[0],1)))) y_l_mp[i][j] = result # y_l_mp_to_y_l , # y_l y_l_mp_to_y_l[i][j] = str(i_back) + ',' + str(j_back) return y_l_mp, y_l_mp_to_y_l def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b out_maxpooling = maxpool(y_l, other_parameters) print(' :', '\n', out_maxpooling[0]) print('\n', ' backprop:', '\n', out_maxpooling[1]) Sample script output
The second matrix that the function returns is the coordinates of the elements selected from the original matrix during the max-mining operation.
Backprop through a convolutional network
Displays backprop formula for convolution kernel update
(1) here we simply substitute the formula for strokes over and simply denote that this is another iterator.
(2) here we decompose the sum in the numerator by and :
that is, all partial derivatives in the numerator, except those for which will be zero. Wherein equals
All above refers to convolution. The backprop formula for cross-correlation is similar, except for the change of sign when and :
Here it is important to see that the convolution kernel itself does not participate in the final formula. There is a kind of convolution operation, but with the participation of and , with the role of the core , but still it is a little like convolution, especially with a step value greater than one: then “Splits” by that completely ceases to resemble familiar convolution. This “decay” is due to the fact that and iterated inside the formula loop. You can see how it all looks with the help of the demo code:
code_demo_convolution_back_dEdw_l.py
git link
import numpy as np w_l_shape = (2,2) # stride = 1 dEdx_l = np.array([ [1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16]]) # stride = 2 'convolution':False ( - x_l ) # dEdx_l = np.array([ # [1,2], # [3,4]]) # stride = 2 'convolution':True # dEdx_l = np.array([ # [1,2,3], # [4,5,6], # [7,8,9]]) y_l_minus_1 = np.zeros((4,4)) other_parameters={ 'convolution':True, 'stride':1, 'center_w_l':(0,0) } def convolution_back_dEdw_l(y_l_minus_1, w_l_shape, dEdx_l, conv_params): indexes_a, indexes_b = create_indexes(size_axis=w_l_shape, center_w_l=conv_params['center_w_l']) stride = conv_params['stride'] dEdw_l = np.zeros((w_l_shape[0], w_l_shape[1])) # if conv_params['convolution']: g = 1 # else: g = -1 # # a b for a in indexes_a: for b in indexes_b: # y_l, ( stride>1) x_l demo = np.zeros([y_l_minus_1.shape[0], y_l_minus_1.shape[1]]) result = 0 for i in range(dEdx_l.shape[0]): for j in range(dEdx_l.shape[1]): # , if i*stride - g*a >= 0 and j*stride - g*b >= 0 \ and i*stride - g*a < y_l_minus_1.shape[0] and j*stride - g*b < y_l_minus_1.shape[1]: result += y_l_minus_1[i*stride - g*a][j*stride - g*b] * dEdx_l[i][j] demo[i*stride - g*a][j*stride - g*b] = dEdx_l[i][j] dEdw_l[indexes_a.index(a)][indexes_b.index(b)] = result # "" w_l # demo print('a=' + str(a) + '; b=' + str(b) + '\n', demo) return dEdw_l def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b print(convolution_back_dEdw_l(y_l_minus_1, w_l_shape, dEdx_l, other_parameters)) Sample script output
Displays the backprop formula for updating bias scales
Similar to the previous paragraph, only replace on . We will use one bias for one feature map:
that is, if you decompose the sum over all and , we will see that all partial derivatives by will be equal to one:
For one feature map, there is only one bias that is “associated” with all the elements of this map. Accordingly, when adjusting the bias value, all the values from the map obtained during back propagation of the error should be taken into account. As an alternative, you can take as many bias for a separate feature map as there are elements in this map, but in this case, the bias parameters are too many — more than the parameters of the convolution kernels themselves. For the second case it is also easy to calculate the derivative - then each (note bias has already had subscripts ) will be equal to each .
Derivation of the backprop formula through the convolution layer
Here, everything is similar to the previous conclusions:
Decomposing the sum in numerator by and , we obtain that all partial derivatives are equal to zero, except in the case when and , and correspondingly, , . This is true only for convolution, for cross-correlation there should be and and correspondingly, and . And then the final formula in the case of cross-correlation will look like this:
The resulting expressions are the same convolution operation, with the familiar kernel being the core. . But, the truth is, everything looks like a familiar convolution only if stride is equal to one, in cases of another step, something completely different is already obtained (similar to the case of backprop for updating the convolution kernel): matrix starts to “break” across the matrix , capturing its different parts (again, because the indices and at iterated inside the formula loop).
Here you can see and test the code:
code_demo_convolution_back_dEdy_l_minus_1.py
git link
import numpy as np w_l = np.array([ [1,2], [3,4]]) # stride = 1 dEdx_l = np.zeros((3,3)) # stride = 2 'convolution':False ( - x_l ) # dEdx_l = np.zeros((2,2)) # stride = 2 'convolution':True # dEdx_l = np.zeros((2,2)) y_l_minus_1_shape = (3,3) other_parameters={ 'convolution':True, 'stride':1, 'center_w_l':(0,0) } def convolution_back_dEdy_l_minus_1(dEdx_l, w_l, y_l_minus_1_shape, conv_params): indexes_a, indexes_b = create_indexes(size_axis=w_l.shape, center_w_l=conv_params['center_w_l']) stride = conv_params['stride'] dEdy_l_minus_1 = np.zeros((y_l_minus_1_shape[0], y_l_minus_1_shape[1])) # if conv_params['convolution']: g = 1 # else: g = -1 # for i in range(dEdy_l_minus_1.shape[0]): for j in range(dEdy_l_minus_1.shape[1]): result = 0 # demo = np.zeros([dEdx_l.shape[0], dEdx_l.shape[1]]) for i_x_l in range(dEdx_l.shape[0]): for j_x_l in range(dEdx_l.shape[1]): # "" w_l a = g*i_x_l*stride - g*i b = g*j_x_l*stride - g*j # if a in indexes_a and b in indexes_b: a = indexes_a.index(a) b = indexes_b.index(b) result += dEdx_l[i_x_l][j_x_l] * w_l[a][b] demo[i_x_l][j_x_l] = w_l[a][b] dEdy_l_minus_1[i][j] = result # demo print('i=' + str(i) + '; j=' + str(j) + '\n', demo) return dEdy_l_minus_1 def create_axis_indexes(size_axis, center_w_l): coordinates = [] for i in range(-center_w_l, size_axis-center_w_l): coordinates.append(i) return coordinates def create_indexes(size_axis, center_w_l): # coordinates_a = create_axis_indexes(size_axis=size_axis[0], center_w_l=center_w_l[0]) coordinates_b = create_axis_indexes(size_axis=size_axis[1], center_w_l=center_w_l[1]) return coordinates_a, coordinates_b print(convolution_back_dEdy_l_minus_1(dEdx_l, w_l, y_l_minus_1_shape, other_parameters)) Sample script output
Interestingly, if we perform cross-correlation, then at the stage of direct passage through the network, we do not turn the convolution kernel upside down, but we turn it over during the back propagation of the error when passing through the convolution layer. If we apply the convolution formula, everything happens exactly the opposite.
In this article, we have deduced and examined in detail all the formulas for the back-propagation of error, that is, formulas that allow the future model to be trained. In the next article, we will connect all this into one integral code, which will be called a convolutional network, and we will try to train this network to predict classes on a real dataset. And also we will check, how much all calculations are correct in comparison with the library for machine learning tensorflow.
Source: https://habr.com/ru/post/344116/
All Articles