Metrics storage: how we switched from Graphite + Whisper to Graphite + ClickHouse
Hello! In my last article I wrote about the organization of a modular monitoring system for microservice architecture. Nothing stands still, our project is constantly growing, and the number of stored metrics is also increasing. How we organized the transition from Graphite + Whisper to Graphite + ClickHouse under conditions of high loads, read about the expectations from it and the migration results under the cat.

Before I tell you how we organized the transition from storing metrics in Graphite + Whisper to Graphite + ClickHouse, I would like to give information about the reasons for making this decision and about the shortcomings of Whisper with which we lived for a long time.
Graphite + Whisper Problems
1. High load on the disk subsystem
At the time of the transition, about 1.5 million metrics per minute arrived to us. With such a stream, disk utilization on servers was ~ 30%. In general, this was quite acceptable - everything worked stably, was quickly written, read quickly ... Until such time as one of the development teams rolled out a new feature and sent us 10 million metrics per minute. It was then that the disk subsystem was overloaded, and we saw 100% recycling. The problem was quickly resolved, but the sediment remained.
2. Lack of replication and consistency
Most likely, as well as everyone who uses / used Graphite + Whisper, we poured the same flow of metrics to several Graphite servers at once to create fault tolerance. And there were no special problems with this - until the moment when one of the servers for any reason did not fall. Sometimes we managed to pick up the fallen server fairly quickly, and carbon-c-relay managed to upload metrics from its cache to it, and sometimes not. And then in the metrics there was a hole that we tightened up with rsync. The procedure was quite long. Saved only what happened like this very rarely. We also periodically took a random set of metrics and compared them with other ones on neighboring nodes of the cluster. In about 5% of cases, several values differed, which did not make us very happy.
3. A large amount of space occupied
Since we write to Graphite not only infrastructural, but also business metrics (and now also metrics from Kubernetes), quite often we get a situation where only a few values are present in the metric, and the .wsp file is created taking into account the entire retention period, and occupies a pre-allocated amount of space, which we had was equal to ~ 2Mb. The problem is aggravated by the fact that there are a lot of such files over time, and when building reports on them to read empty points it takes a lot of time and resources.
Immediately I would like to note that the problems described above can be dealt with by various methods and with varying degrees of efficiency, but the more data begins to flow to you, the more they become more acute.
Having all of the above (taking into account the previous article ), as well as the constant increase in the number of received metrics, the desire to transfer all the metrics to the storage interval of 30 seconds. (if necessary - up to 10 seconds), we decided to try Graphite + ClickHouse as a promising alternative to Whisper.
Graphite + ClickHouse. Expectations
Having visited several mitap guys from Yandex, having read a couple of articles on Habré , reviewed the documentation and found the sane components for ClickHouse strapping under Graphite, we decided to act!
I wanted to get the following:
- reduce the utilization of the disk subsystem from 30% to 5%;
- reduce the amount of space occupied from 1TB to 100GB;
- be able to take 100 million metrics per minute to the server;
- data replication and fault tolerance out of the box;
- do not sit on this project for a year and make the transition for some imputed term;
- switch without downtime.
Quite ambitious, right?
Graphite + ClickHouse. Components
To obtain data using the Graphite protocol and then write them to ClickHouse, carbon-clickhouse (golang) was chosen.
The latest release of ClickHouse, a stable version 1.1.54253, was chosen as a database for storing time series. There were problems when working with him: there were a lot of errors in the logs, and it was not entirely clear what to do with them. In the discussion with Roman Lomonosov (by carbon-clickhouse, graphite-clickhouse, and many, many things), the older release 1.1.54236 was chosen. Errors disappeared - everything began to work with a bang.
Graphite-clickhouse (golang) was chosen for reading data from ClickHouse. The API for Graphite is carbonapi (golang). To organize replication between ClickHouse tables, a zookeeper was used. For routing metrics, we left us the beloved carbon-c-relay (C) (see previous article) .
Graphite + ClickHouse. Table structure
“Graphite” is the database we created for monitoring tables.
“Graphite.metrics” is a table with a ReplicatedReplacingMergeTree engine (replicated ReplacingMergeTree ). This table stores the names of the metrics and the paths to them.
CREATE TABLE graphite.metrics ( Date Date, Level UInt32, Path String, Deleted UInt8, Version UInt32 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.metrics', 'r1', Date, (Level, Path), 8192, Version); “ Graphite.data ” is a table with the ReplicatedGraphiteMergeTree engine (replicated by GraphiteMergeTree ). This table stores metric values.
CREATE TABLE graphite.data ( Path String, Value Float64, Time UInt32, Date Date, Timestamp UInt32 ) ENGINE = ReplicatedGraphiteMergeTree('/clickhouse/tables/replicator/graphite.data', 'r1', Date, (Path, Time), 8192, 'graphite_rollup') “Graphite.date_metrics” is a conditionally filled table with the ReplicatedReplacingMergeTree engine. The names of all metrics that met during the day are recorded in this table. The reasons for the creation are described in the “Problems” section at the end of this article.
CREATE MATERIALIZED VIEW graphite.date_metrics ( Path String, Level UInt32, Date Date) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicator/graphite.date_metrics', 'r1', Date, (Level, Path, Date), 8192) AS SELECT toUInt32(length(splitByChar('.', Path))) AS Level, Date, Path FROM graphite.data “Graphite.data_stat” is a conditionally filled table with the ReplicatedAggregatingMergeTree engine (replicated by AggregatingMergeTree ). This table records the number of incoming metrics broken down to 4 levels of nesting.
CREATE MATERIALIZED VIEW graphite.data_stat ( Date Date, Prefix String, Timestamp UInt32, Count AggregateFunction(count)) ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/replicator/graphite.data_stat', 'r1', Date, (Timestamp, Prefix), 8192) AS SELECT toStartOfMonth(now()) AS Date, replaceRegexpOne(Path, '^([^.]+\\.[^.]+\\.[^.]+).*$', '\\1') AS Prefix, toUInt32(toStartOfMinute(toDateTime(Timestamp))) AS Timestamp, countState() AS Count FROM graphite.data GROUP BY Timestamp, Prefix Graphite + ClickHouse. Component Interaction Scheme
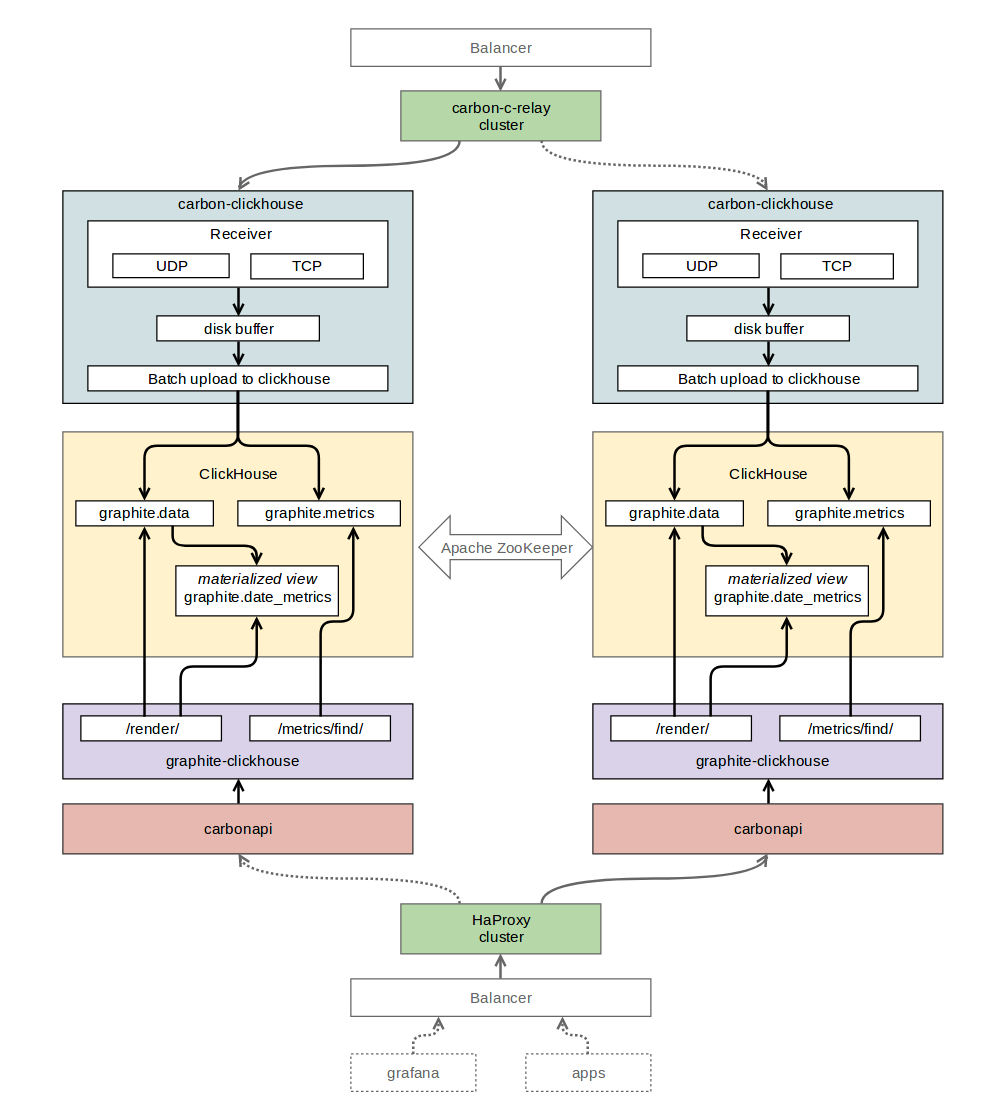
Graphite + ClickHouse. Data migration
As we remember from the expectations of this project, the transition to ClickHouse should be without downtime, respectively, we had to somehow switch our entire monitoring system to a new repository as transparently as possible for our users.
We did it like this.
In carbon-c-relay, they added a rule to send an additional stream of metrics to the carbon-clickhouse of one of the servers participating in the replication of ClickHouse tables.
We wrote a small python script that, using the whisper-dump library, read all the .wsp files from our repository and sent this data to the above described carbon-clickhouse in 24 threads. The number of metrics accepted in carbon-clickhouse reached 125 ppm, and ClickHouse did not even sweat.
We created a separate DataSource in Grafana in order to debug functions used in existing dashboards. We identified a list of functions that we used, but they were not implemented in carbonapi. We added these functions, and sent PR `s to authors carbonapi (special thanks to them).
- To switch the reading load in balancers settings, endpoints were changed from graphite-api (API interface for Graphite + Whisper) to carbonapi.
Graphite + ClickHouse. results
reduced utilization of the disk subsystem from 30% to 1%;
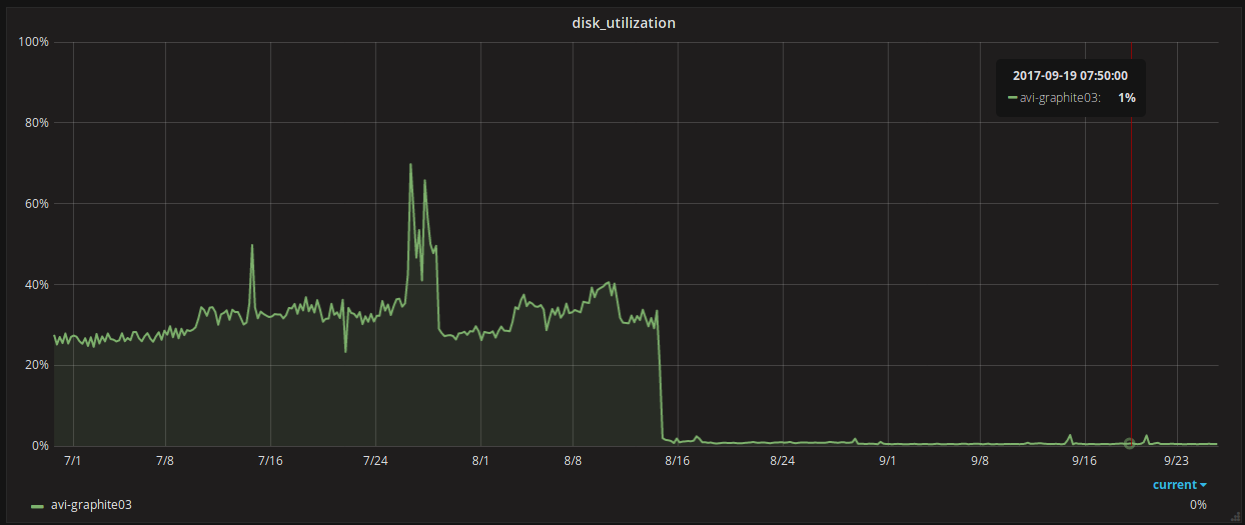
- reduced the amount of space occupied from 1 TB to 300 GB;
- we have the ability to take 125 million metrics per minute to the server (peaks at the time of migration);
- translated all metrics to a thirty-second storage interval;
- received data replication and fault tolerance;
- switched without downtime;
- spent all about 7 weeks.
Graphite + ClickHouse. Problems
In our case, it was not without pitfalls. That's what we encountered after the transition.
- ClickHouse does not always re-read configs on the fly, sometimes it needs to be reloaded. For example, in the case of the description of the zookeeper cluster in the ClickHouse config, it was not used until the restart of the clickhouse-server.
- There were no large ClickHouse requests, so in our graphite-clickhouse, the ClickHouse connection string looks like this:
url = "http://localhost:8123/?max_query_size=268435456&max_ast_elements=1000000" - In ClickHouse, quite often new versions of stable releases are released, there may be surprises in them: be careful.
- Dynamically created containers in kubernetes send a large number of metrics with a short and random period of life. There are not many points on such metrics, and there are no problems with space. But when building queries, ClickHouse raises a huge amount of these same metrics from the 'metrics' table. In 90% of cases, data on them for the window (24 hours) is missing. But the time to search for this data in the table 'data' is spent, and ultimately rests on a timeout. In order to solve this problem, we began to conduct a separate view with information on the metrics that we met during the day. Thus, when building reports (graphs) for dynamically created containers, we only poll those metrics that were encountered within a given window, and not for all the time that has speeded up the construction of reports on them several times. For the above solution, a graphite-clickhouse (fork) was compiled, including the implementation of working with the date_metrics table.
Graphite + ClickHouse. Tags
Since version 1.1.0, Graphite has officially supported tags . And we are actively thinking about what and how to do to support this initiative on the graphite + clickhouse stack.
Graphite + ClickHouse. Anomaly detector
Based on the infrastructure described above, we implemented a prototype of the anomaly detector, and it works! But about him - in the next article.
Subscribe, click the up arrow and be happy!
')
Source: https://habr.com/ru/post/343928/
All Articles