Neural network to identify individuals embedded in the smartphone
 Apple began to use in-depth training to identify individuals since iOS 10. With the release of the Vision framework, developers can now use this technology and many other machine vision algorithms in their applications. When developing the framework, we had to overcome significant problems in order to preserve the privacy of users and work effectively on the hardware of the mobile device. The article discusses these problems and describes how the algorithm works.
Apple began to use in-depth training to identify individuals since iOS 10. With the release of the Vision framework, developers can now use this technology and many other machine vision algorithms in their applications. When developing the framework, we had to overcome significant problems in order to preserve the privacy of users and work effectively on the hardware of the mobile device. The article discusses these problems and describes how the algorithm works.Introduction
For the first time, the definition of persons in public APIs appeared in the Core Image framework through the CIDetector class. These APIs also worked in Apple’s own applications, such as Photos. The very first version of CIDetector used to determine the method based on the Viola-Jones algorithm [1] . CIDetector's consistent enhancements were based on the achievements of traditional machine vision.
With the advent of deep learning and its application to machine vision problems, the accuracy of face detection systems has taken a significant step forward. We had to completely rethink our approach in order to benefit from this paradigm shift. Compared to traditional computer vision, models in depth learning require an order of magnitude more memory, much more disk space, and more computational resources.
As of today, a typical high-performance smartphone is not a viable platform for vision models with in-depth training. Most industry players bypass this limitation by using cloud APIs. There, the pictures are sent for analysis to the server, where the system of in-depth training gives the result in the definition of persons. In cloud services, powerful desktop GPUs with a large amount of available memory usually work. Very large network models, and potentially entire ensembles of large models, can work on the server side, allowing customers (including mobile phones) to take advantage of large depth learning architectures that cannot be run locally.
')
Apple iCloud Photo Library - a cloud solution for storing photos and videos. Each photo and video before sending it to iCloud Photo Library is encrypted on the device and can only be decrypted on the device with the corresponding iCloud account. Therefore, for the work of machine vision systems in depth learning, we had to implement algorithms directly in the iPhone.
Here had to solve several problems. Depth learning models have to be delivered as part of the operating system, occupying the valuable NAND space. They need to be loaded into RAM and take away significant computing resources of the GPU and / or CPU. Unlike cloud services, where resources can be allocated exclusively for computer vision tasks, system resources are shared with other running applications on a computing device. Finally, the calculations must be sufficiently effective to process a large collection of Photos photos at a reasonable time, but without significant power consumption or heat.
The rest of the article discusses our approach to using algorithms to identify individuals in the depth learning system and how we successfully managed to overcome the difficulties in order to achieve maximum accuracy. We will discuss:
- how we fully utilized our GPU and CPU (using BNNS and Metal);
- memory optimization for neural network output, image loading and caching;
- how we implemented the neural network in such a way as not to interfere with the work of many other simultaneously performed tasks on the iPhone.
Transition from Viola-Jones method to deep learning
When we started working on in-depth training to identify individuals in 2014, deep convolutional neural networks (GNSS) only started to show promising results in object detection tasks. The most famous among all was the model OverFeat [2] , which demonstrated some simple ideas and showed that the GNSS is quite effective in detecting objects in images.
The OverFeat model derived the correspondence between a fully connected layers of a neural network and convolutional layers with valid filter convolutions in the same spatial dimensions as the input data. This work clearly showed that a binary classification network with a fixed receptive field (for example, 32 × 32 with a natural pitch of 16 pixels) can potentially be used for images of arbitrary size (for example, 320 × 320) and produce a map of the appropriate size at the output (in this example 20 × 20). The scientific article describing OverFeat also contained clear recipes on how to produce tighter output cards, effectively reducing the neural network pitch.
We initially founded the architecture on some ideas from the article on OverFeat, which resulted in a fully convolutional network (see Figure 1) with a multitasking goal:
- binary classification to predict the presence or absence of a person in the input data;
- regression to predict the parameters of the bounding box that best localizes the face in the input data.
We experimented with different training options for such a neural network. For example, a simple learning procedure was to create a large set of data with tiles of fixed-size images that corresponded to the minimum valid size of the input data, so that each tile generated one result at the output of the neural network. The training data set is perfectly balanced, so half of the tiles have a face (positive class), and no half (negative class) on the other half. For each positive tile, the true coordinates (x, y, w, h) of the faces were specified. We have trained the neural network to optimize for the multitasking goal described above. After learning, the neural network learned to predict the presence of a face in the image and, in the event of a positive answer, gave out the coordinates and scale of the face in the frame.
Fig. 1. Improved GNSS face detection architecture
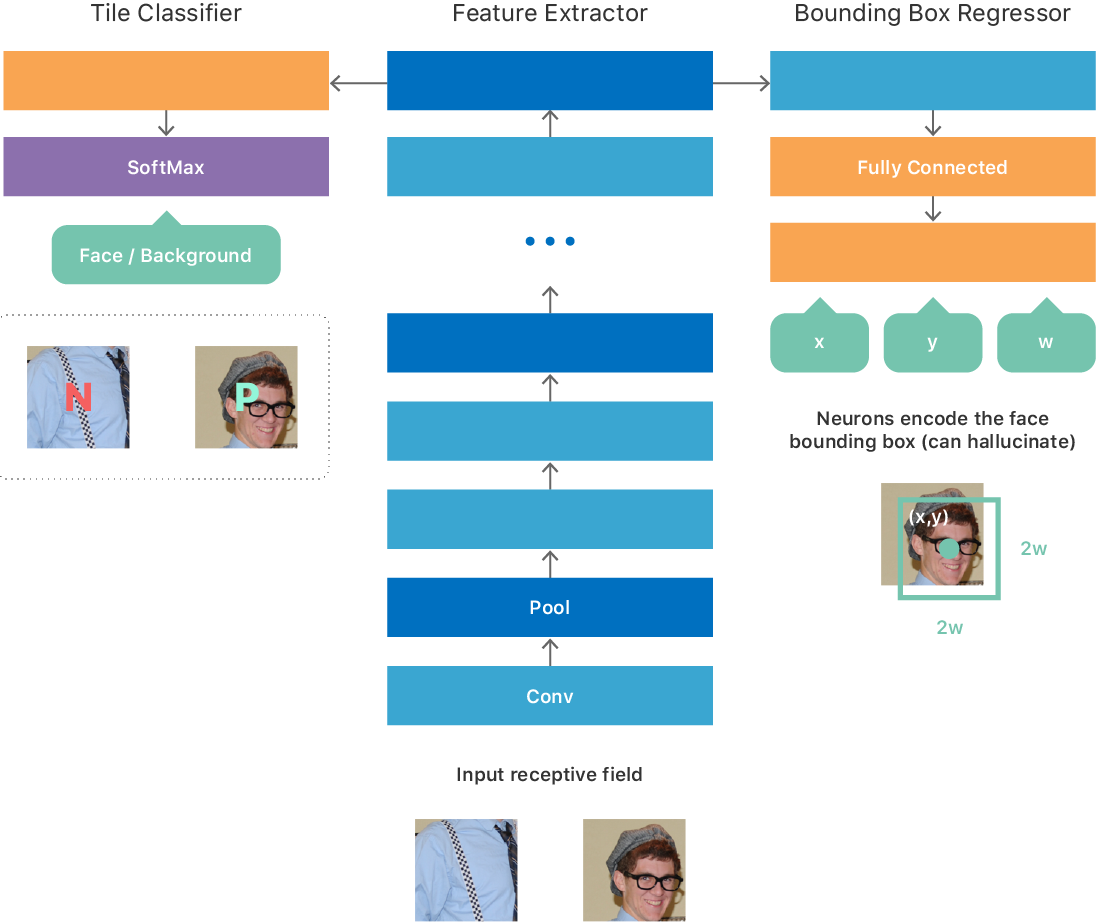
Since the network is fully convolved, it can effectively process an image of arbitrary size and make an output map 2D. Each point on the map corresponds to the input image tile and contains the prediction of the neural network regarding the presence or absence of a face on this tile, as well as its location / scale (see the input and output of GNSS in Fig. 1).
With such a neural network, you can build a fairly standard processing pipeline for identifying individuals. It consists of a multiscale image pyramid, a neural network for determining faces, and a post-processing module. A multiscale pyramid is required to process faces of all sizes. The neural network is applied at each level of the pyramid, from where candidates for recognition are extracted (see Fig. 2). The post-processing module then brings together candidates from all scales to produce a list of bounding boxes that match the final prediction of the neural network by the faces in the image.
Fig. 2. The process of identifying individuals
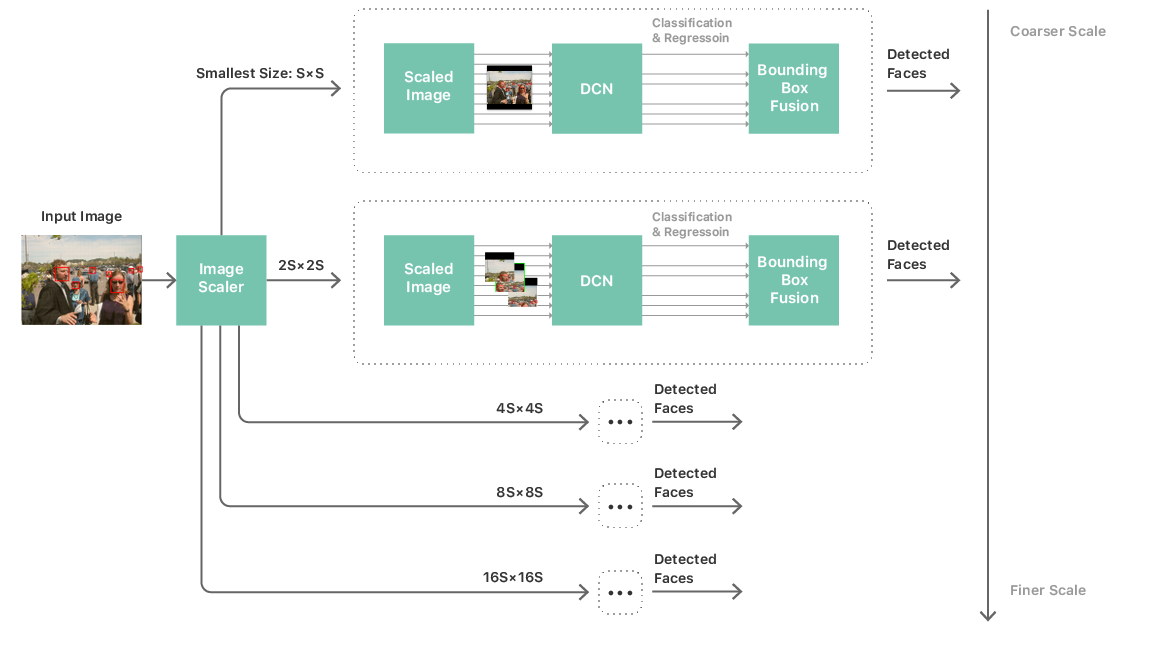
Such a strategy made it more realistic to launch a deep convolutional neural network and complete scanning of an image on a mobile gland. But the complexity and size of the neural network remained the main bottlenecks in performance. Solving this problem meant not only limiting the neural network with a simple topology, but also limiting the number of layers, the number of channels per layer and the size of the core of convolutional filters. These limitations raised an important problem: our neural networks, which provided acceptable accuracy, are far from simple: most of them have more than 20 layers plus several network-in-network modules [3] . The use of such networks in the image scanning framework described above is absolutely impossible due to unacceptable performance and power consumption. In fact, we cannot even load a neural network into memory. The task boils down to how to train a simple and compact neural network that can simulate the behavior of accurate, but very complex networks.
We decided to use an approach that is informally known as teacher-student learning [4] . This approach provides a mechanism for learning the second fine-and-deep neural network (“student”), so that it very closely matches the output of a large complex neural network (“teacher”), which we trained as described above. The student neural network consists of a simple repeating structure of 3 × 3 convolutions and subsample layers, and its architecture is adapted to maximize the use of our neural network output engine (see Figure 1).
Now, finally, we have an algorithm for the deep neural network of determining persons, suitable for running on a mobile gland. We repeated several training cycles and obtained a neural network model sufficiently accurate to perform the assigned tasks. Although this model is accurate and capable of working on a mobile device, there is still a huge amount of work to make it possible in practice to deploy the model on millions of user devices.
Image Processing Pipeline Optimization
Practical considerations for in-depth training have greatly influenced the choice of architecture for an easy-to-use developer platform, which we call Vision. It soon became apparent that to create a great framework, not just great algorithms are enough. I had to greatly optimize the image processing pipeline.
We didn’t want developers to think about scaling, color conversion, or image sources. Face detection should work well regardless of whether the stream from the camera is used in real time, video processing, files from disk or from the web. It should work regardless of the type and format of the image.
We were worried about power consumption and memory usage, especially in the process of streaming and image capture. The memory consumption worried us, including in the case of processing 64-megapixel panoramas. We solved these problems using partial sub-sampling decoding and automatic tiling. This made it possible to start the tasks of machine vision in large images, even with a non-standard aspect ratio.
Another problem was the matching of color spaces. Apple has a wide range of APIs, but we did not want to load developers with work on choosing a color space. This takes over the Vision framework, thus lowering the threshold of entry for successfully introducing machine vision into any application.
Vision is also optimized by efficient reuse and processing of intermediate links. Detecting faces, determining the coordinates of faces, and some other tasks of computer vision — they all work on the same mapped intermediate image. By abstracting the interface to the level of algorithms and finding the optimal place to process the image or buffer, Vision is able to create and cache intermediate images - this improves the performance of various computer vision tasks even without the intervention of the developer.
The reverse is also true. From the perspective of the central interface, we can direct the development of the algorithm in such a direction as to optimize the reuse or sharing of intermediate data. Vision implements several different and independent machine vision algorithms. For different algorithms to work well together, they share the same input resolutions and color spaces where possible.
Performance Optimization for Mobile Iron
The pleasure of an easy-to-use framework will quickly disappear if the face detection API is not able to work in real time or in background system processes. Users expect that the detection of faces works automatically and imperceptibly during the processing of photo albums, or triggered immediately after the shot. They do not want the battery charge to decrease or the system to brake because of this. Apple mobile devices are multi-tasking. Therefore, the background process of machine vision should not significantly affect other system functions.
We have implemented several strategies to reduce memory consumption and use of the GPU. To reduce memory usage, we allocate intermediate layers of our neural networks by analyzing the computational graph. This allows you to assign multiple layers to one buffer. Being fully deterministic, such a technique nevertheless reduces memory consumption without affecting performance or fragmentation in memory, and it can be used for both CPUs and GPUs.
The Vision detector works with five neural networks (one for each level of a multi-scale pyramid, as shown in Fig. 2). For these five neural networks, the total weights and parameters are indicated, but they have different formats of input and output data and intermediate layers. To further reduce memory consumption, we run a memory optimization algorithm on a shared graph compiled by these five networks, which significantly reduces memory consumption. Also, all neural networks together use the same buffers with weights and parameters, again reducing the amount of allocated memory.
To achieve better performance, we use the fully convoluted nature of the neural network: all scales dynamically change to match the resolution of the input image. Compared with the alternative approach - fitting the image to a square grid of a neural network (laid with empty strips) - fitting the neural network to the image size allows you to drastically reduce the total number of operations. Since as a result of this rearrangement, the topologies of operations do not change and, due to the high performance of the rest of the distributor, dynamic shape change does not consume more resources than allocation.
To ensure interactivity and the absence of UI slowdowns while the deep neural network is running in the background process, we have divided the work orders for the GPU for each layer of the neural network so that each task is executed for no longer than one millisecond. This allows the driver to change contexts, allocating resources for higher priority tasks in time, such as animation UI, which reduces and sometimes completely eliminates dropping frames.
Together, these strategies ensure that the user will enjoy local work with low latency and private mode, although he doesn’t even know that the neural networks on the smartphone perform several hundred billion floating point operations every second.
Using the Vision framework
Have we been able to achieve our goal and develop a high-performance, easy-to-use API for identifying individuals? You can try the Vision framework and decide for yourself. Here are some resources to get you started:
- Presentation from WWDC: “ Vision Framework: Development on Core ML ”
- Vision Framework Help
- Manual "Core ML and Vision: Machine Learning in iOS 11" [5]
Literature
[1] Viola, P., Jones, MJ Robust Real-Time Object Detection . Published in Proceedings of the Computer Vision and Pattern Recognition Conference , 2001. ↑
[2] Sermanet, Pierre, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun. OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks . arXiv: 1312.6229 [Cs], December 2013 ↑
[3] Lin, Min, Qiang Chen, Shuicheng Yan. Network In Network . arXiv: 1312.4400 [Cs], December 2013 ↑
[4] Romero, Adriana, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, Yoshua Bengio. FitNets: Hints for Thin Deep Nets . arXiv: 1412.6550 [Cs], December 2014 ↑
[5] Tam, A. Core ML and Vision: Machine learning in iOS Tutorial . Retrieved from www.raywenderlich.com , September 2017. ↑
Source: https://habr.com/ru/post/343810/
All Articles