Hinton's capsule nets

On October 27, 2017, an article by Dr. Jofri Hinton and co-authors from Google Brain appeared . Hinton is more than a renowned machine learning scientist. He once developed the math of backpropagation of errors, was the scientific adviser of Yang Lekun, author of the architecture of convolutional networks.
Although the presentation was quite modest, it is correct to talk about a revolutionary change in the approach to artificial neural networks (INS). They called the new approach "capsule networks". While in the Russian segment of the Internet there is little information about them, therefore, I will fill this gap.
So, as it turned out, Hinton in recent years has been looking for ideas that will make it possible to do something cooler than convolutional networks in computer vision. What did he not like in CNN (convolutional neural networks, convolutional neural networks)? Basically, the max-pooling layer and the invariance of detection only to the position in the image. It is used to reduce the dimension of the outputs of the convolutional layers, ignoring the small differences in the spatial structure of the images (or other types of data).
')

From the image it is clear how this layer works: it selects the maximum in the exit window of the convolutional layer. This part of the information is lost. In fact, it is not so obvious to prove, and there may even be classes of objects for which information loss does not happen. In addition, in a number of architectures convolutional networks, the max-pooling layer simply does not exist. But, nevertheless, - max-pooling is really quite a layer vulnerable to criticism.
Even more criticism of convolutional networks is at the end of one of my past articles . Hinton talks about similar problems.
In addition, a large "elephant", which we, the engineers, try not to notice in our room is a mini column in the cerebral cortex, which clearly must have an understandable, limited and not too primitive function.

So Hinton says: neural capsules are minicolumns, they can correspond to recognizable objects, their characteristics. The total activity of neurons characterizes the probability of recognition. The output information inside the capsule should be enough to restore the input almost without loss.
Architecture
For those who are a little involved in convolutional networks, this picture explains almost everything:
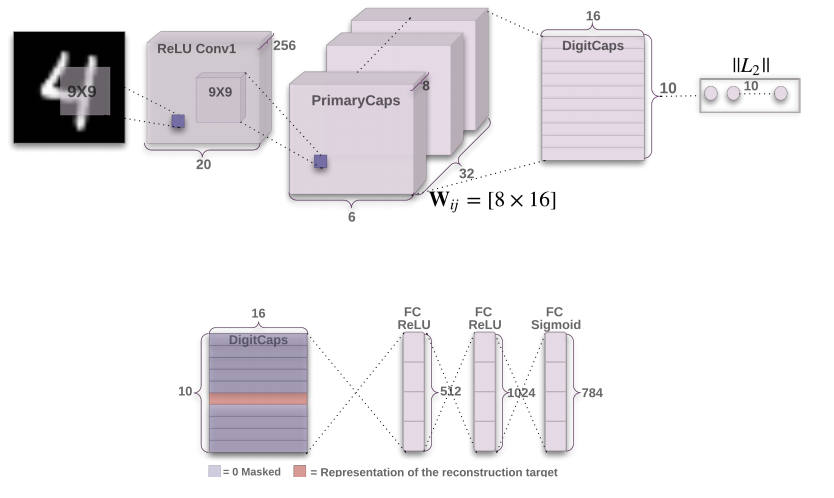
So, first comes the standard selection of features that are invariant to translation in the image using a convolutional layer. Even if you do not know what a convolutional layer is, you can still read further - this is not critical here.
Then 32 more convolutional layers are distinguished, each of which looks at the first convolutional layer. This is already unusual, and the picture does not explain why. For dynamic routing (of course, routing, but let it be routing, otherwise it looks like speech about network technologies). This is one of the two "chips" that distinguishes this architecture from the rest, so it deserves a separate chapter.
Then comes the “digitCaps” layer - the capsules that Hinton is talking about. Although he calls the previous layer “primaryCaps”, i.e. primary capsules, they do not carry a particularly new function in themselves. What matters is how they are then connected to digitCaps.
So, each capsule (or minicolumn) has a strict meaning: the amplitude of the vector in each of them corresponds to the probability of having one of the numbers in the image.
A rather important part of the architecture was hidden at the bottom of the image: a decoder, to the input of which a layer of DigitCaps is fed, while all the capsules are zeroed out except for one that “won” in amplitude. Decoders are essentially an inverted ANN (artificial neural network), the input is a small vector, and the output is the original image. This decoder provides the second most important "chip" of this architecture: the contents of one capsule must fully describe the subset of a specific digit supplied to the input. Otherwise, the decoder will not be able to restore the original image. There is another useful property of a decoder - it is a regularization method. Close codes in capsules will be in Euclid's close images.
For example, the article presents the result of the "movement" component in one of the capsules (in this case responsible for the number 6):

The components of the capsule vector are responsible for the Hinton digit representation form.
Dynamic routing
Hinton, Frosst and Sara Sabour write: “There are many ways to realize the idea of capsule networks. And dynamic routing as proposed is just one example. ” Therefore, it may be that soon more elegant solutions will appear. But so far everything works as follows:
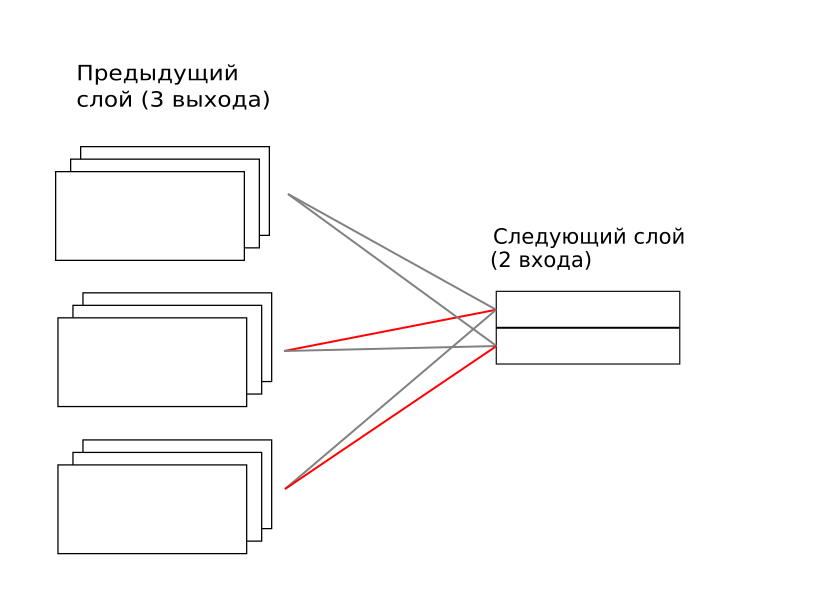
Each capsule from the previous layer is connected with each next one. Here "connected" means that there is a weight matrix between each capsule from the previous layer and each next one. These weights are trained, as in a conventional artificial neural network using the method of back propagation of errors. But over these weights by coefficients a factor for each pair is superimposed, with the factor ultimately must tend to one or zero. In the limit, each capsule from the top level “listens” to only one capsule from the bottom at a time. In the image above, the first capsule from the top level draws attention only to the second capsule of the bottom one, and the second one at the top one - only to the third one from the bottom one. Note that this matrix is temporary and must be calculated anew for each example. Further, I will call it a “temporary matrix”. But fully connected weight matrices between all capsules are trained and their weights always exist, despite the fact that they are not implemented every time.
How is this temporary matrix calculated? A rather tricky iterative process: when a new example of a capsule network is presented, it is estimated what contribution to the top level capsule vector is given by each connection to the lower level. The compound that makes a greater contribution increases its weight in the time matrix, and then everything is normalized so that the coefficients do not go to infinity. And this is repeated 3 times.
It is not obvious here, but, in fact, it is the realization of the principle “the winner takes everything”. Well, because of the iterative principle, here "the winner takes almost everything." And so is the distribution of roles at the lower level: each element begins to better describe some of its situation for each of the top-level capsules.
Thus, during recognition (as well as during training), for each capsule responsible for a specific figure, the problem is solved: which model of the lower level capsules describes the observed image better. And then the amplitude of each of the vectors in the upper level capsules is estimated to decide which figure is most likely.
If you want to understand the mathematics in detail, then it is described in the original article. And in more detail here .
Experimental results
Experimented on a well-known database of images MNIST, in which 10 numbers are presented in words in different variations.
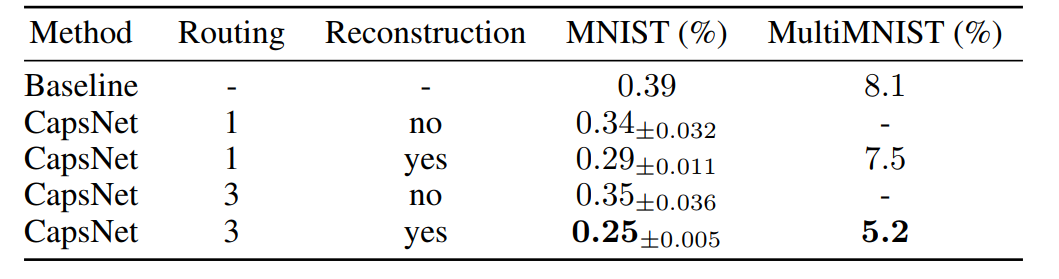
What are these lines about? Adding a decoder and dynamic routing with three iterations helps. In the second column, the result is on MNIST when 2 digits are superimposed on each other. This is an interesting ability of capsule networks to choose not one capsule of the winner, but two at once. The only thing that doesn't work is if two identical numbers are drawn on top of each other in a slightly different way.
IMHO on MNIST you can get any accuracy. The test sample size is 10,000, which means that with 99.7% accuracy there are only 30 errors. And changing these or other parameters of the algorithm, you can always reduce this error due to only accidents. Therefore, we can only talk about the contribution of this or that mechanism to the result (and then, in fact, it will be controversial and statistically unreliable). For example, the entire dynamic routing mechanism gives an improvement of only 0.04%, i.e. on 4 images. So, there were 29 errors, it became 25. The probability that dynamic routing did not help is still very serious.
Of course, I think it all works and helps. Just do not pay attention to the result on MNIST. The concept itself is important, and MNIST allowed to debug and check its implementation. And this is an important step - now we can all touch the implementation, for example in tensorflow , and understand how it works, personally.
What does all this mean? Strong AI, which will enslave us all?
Because of the dynamic development of the concept of convolutional networks (and still recurrent, but Hinton does not explain how his ideas can absorb them, although they can) a couple of years ago, everyone in the industry began to think that nothing more was needed. Everything is training - give the data! And it is only a matter of time when all tasks are solved. But it is not. And I think that it is very important that a person who is considered the father of deep learning speaks of the severe inferiority of existing approaches, looking for new directions.
This means that from October 27, 2017 more research groups will start searching for the next step in artificial intelligence, more people will formulate what is the difference between “weak” AI and “strong”, competition will begin among previously marginal, and later trend theories which should replace existing models. And this is all very good! Now opens a new Wild West in the field of AI.
Announcement, take this opportunity
Not so long ago, in this article , armed with the ideas of Alexei Redozubov, which are almost orthogonal to the existing established consensus, I tried to show an alternative approach using the example of car numbers.
Last year, our surveys also did not stand still. For example, we wrote a demonstration on MNIST on Keras, which is now not even ashamed to share with the community. And the capsule networks only convinced that the formulation of the function of minicolumns is extremely important at the current stage, and here it is somewhat different from what Hinton gives (for the better, of course).
Therefore, in the coming days I will publish a similar article in the wake of the MNIST training session and articles on arxiv within the framework of the concept of “completely non-neural networks” (we’ll not think of a name).
Source: https://habr.com/ru/post/343726/
All Articles