Eight C ++ 17 features that every developer should use
We’ll talk about eight handy changes that affect your everyday code. Four changes concern the language itself, and four more - its standard library.
You may also be interested in the article Ten C ++ 11 Features, which every C ++ developer should use
Thanks
I took some examples from the reports at conferences of the Russian C ++ User Group - for this many thanks to its organizers and speakers! I took examples from:
- Anton Polukhin. C ++ 17 (C ++ SIBERIA 2016)
- Alexander Fokin. C ++ 17, which we deserve (C ++ SIBERIA 2017)
1. Decomposition at the announcement (structural bindings)
- use decomposition when declaring variables: auto [a, b, c] = std :: tuple (32, "hello" s, 13.9)
- return a structure or a tuple from a function instead of assigning out parameters
It is convenient to decompose std::pair , std::tuple and structures using the new syntax:
#include <string> struct BookInfo { std::string title; // In UTF-8 int yearPublished = 0; }; BookInfo readBookInfo(); int main() { // title year, auto [title, year] = readBookInfo(); } In C ++ 17, there are restrictions on decomposition when declaring:
- types of decomposable elements cannot be explicitly specified
- cannot use nested decomposition of the form
auto [title, [header, content]] = ...
Decomposition in the declaration, in principle, can decompose any class - it is enough to write a hint once by specializing tuple_element , tuple_size and get . Read more in the article Adding C ++ 17 structured bindings support to your classes (blog.tartanllama.xyz)
Decomposition during declaration works well in std::map<> and std::unordered_map<> containers with the old .insert() method and two new methods:
- The try_emplace method performs insertion if and only if the specified key is not yet in the container.
- If the specified key is already in the container, nothing happens: in particular, the rvalue values are not moved
- The insert_or_assign method either inserts or assigns the value of an existing element.
An example of a decomposition with try_emplace and a key-value decomposition when traversing a map:
#include <string> #include <map> #include <cassert> #include <iostream> int main() { std::map<std::string, std::string> map; auto [iterator1, succeed1] = map.try_emplace("key", "abc"); auto [iterator2, succeed2] = map.try_emplace("key", "cde"); auto [iterator3, succeed3] = map.try_emplace("another_key", "cde"); assert(succeed1); assert(!succeed2); assert(succeed3); // key value range-based for for (auto&& [key, value] : map) { std::cout << key << ": " << value << "\n"; } } 2. Automatic output of template parameters
Key rules:
- functions of the form
std::make_pairno longer needed: feel free to writestd::pair{10, "hello"s}expressions, the compiler itself will output the type - template RAII of the form
std::lock_guard<std::mutex> guard(mutex);become shorter:std::lock_guard guard(mutex); - the
std::make_uniqueandstd::make_sharedare still needed
You can create your own hints for automatic display of template parameters: see Automatic_deduction_guides
An interesting feature: the constructor from initializer_list<> skipped for a list of one element. For some JSON libraries (such as json_spirit) this can be fatal. Do not play with recursive types and STL containers!
#include <vector> #include <type_traits> #include <cassert> int main() { std::vector v{std::vector{1, 2}}; // vector<int>, vector<vector<int>> static_assert(std::is_same_v<std::vector<int>, decltype(v)>); // assert(v.size() == 2); } 3. Declaring nested namespaces
Avoid nesting of namespaces, and if not avoided, then declare them like this:
namespace product::account::details { // ... ... } 4. Attributes nodiscard, fallthrough, maybe_unused
Key rules:
- terminate all case blocks, except the last, with either the
[[fallthrough]]attribute or thebreak;instructionbreak; - use
[[nodiscard]]for functions returning an error code or owning a pointer (whether smart or not) - use
[[maybe_unused]]for variables that are only needed for checking in assert
For more information about attributes, see the article How to use attributes from C ++ 17 . There will be brief excerpts.
In C ++, you have to add break after each case to the switch constructs, and even an experienced developer can easily forget about this. The fallthrough attribute comes to the rescue, which can be pasted to an empty instruction. In fact, the attribute is attached to the case following the empty instruction.
enum class option { A, B, C }; void choice(option value) { switch (value) { case option::A: // ... case option::B: // warning: unannotated fall-through between // switch labels // ... [[fallthrough]]; case option::C: // no warning // ... break; } } To take advantage of the attribute, the warning -Wimplicit-fallthrough should be included in GCC and Clang. After enabling this option, each case that does not have a fallthrough attribute will generate a warning.
In projects with high performance requirements, you can practice avoiding the emission of exceptions (at least in some components). In such cases, an operation execution error is reported by the return code returned from the function. However, it is very easy to forget to check this code.
[[nodiscard]] std::unique_ptr<Bitmap> LoadArrowBitmap() { /* ... */ } void foo() { // warning: ignoring return value of function declared // with warn_unused_result attribute LoadArrowBitmap(); } If you use, for example, your own class of errors, you can specify the attribute once in its declaration.
class [[nodiscard]] error_code { /* ... */ }; error_code bar(); void foo() { // warning: ignoring return value of function declared // with warn_unused_result attribute bar(); } Sometimes programmers create a variable that is used only in the debug version to store the error code of the called function. Perhaps this is just a code design error, and the return value should always be processed. However:
// ! ! auto result = DoSystemCall(); (void)result; // unused variable assert(result >= 0); // [[maybe_unused]] auto result = DoSystemCall(); assert(result >= 0); 5. Class string_view for string parameters
Rules:
- in the parameters of all functions and methods instead of
const string&try to accept non-possessingstring_viewby value- return from the functions and methods owning the
string, as before
- return from the functions and methods owning the
- be careful with returning the string_view from a function: this can lead to a hanging link problem (dangling pointers)
For more information on why string_view is best applied only to parameters, see std :: string_view is constructed from temporary instances of strings.
The string_view class string_view good because it is easily constructed from both std::string and const char* without additional memory allocation. It also has constexpr support and repeats the std :: string interface. But there is a minus: for string_view presence of a null character at the end is not guaranteed.
6. Classes optional and variant
The use of optional<> and variant<> so wide that I will not even try to fully describe them in this article. Key rules:
- prefer
optional<T>instead ofunique_ptr<T>for the composition of an object T whose lifetime is shorter than the owner’s lifetime- for PIMPL, use
unique_ptr<Impl>, because the definition of Impl is hidden in the class implementation file
- for PIMPL, use
- use variant type instead of enum or polymorphic classes in a situation where states, such as license status, cannot be described by enum constants due to the presence of additional data in each of the states
- use variant type instead of enum in a situation where data, such as an error code in an exception, must be processed in all variants, and incomplete variant processing should result in a compilation error
- use variant type instead of any wherever possible
- optional can be used to compose an object whose lifetime is shorter than the owner's lifetime
- do not use
optionalfor error handling: it does not carry any information about the error- to return the value or error, you can write your class
Expected<Value, Error>, based onboost::variant<...> - but you can not write and take ready: github.com/martinmoene/expected-lite
- to return the value or error, you can write your class
Sample code with optional:
// nullopt - nullopt_t, // optional ( nullptr ) std::optional<int> optValue = std::nullopt; // ... optValue ... // , -1 const int valueOrFallback = optValue.value_or(-1); - optional has
operator*andoperator->, as well as the convenience method.value_or(const T &defaultValue) - optional has a value method, which, unlike
operator*, throws an exceptionstd::bad_optional_accesswhen there is no value - optional has comparison operators “==”, “! =”, “<”, “<=”, “>”, “> =”, while
std::nulloptless than any valid value - optional has an explicit conversion operator to bool
Example code with variant: here we use variant to store one of several states in the case when different states may have different data
struct AnonymousUserState { }; struct TrialUserState { std::string userId; std::string username; }; struct SubscribedUserState { std::string userId; std::string username; Timestamp expirationDate; LicenseType licenceType; }; using UserState = std::variant< AnonymousUserState, TrialUserState, SubscribedUserState >; The variant advantage in its approach to memory management: data is stored in fields of type variant type without additional allocations of memory. This makes the size of the variant type dependent on the types that make it up. So a size table on 32-bit processors may look like (but this is not accurate):
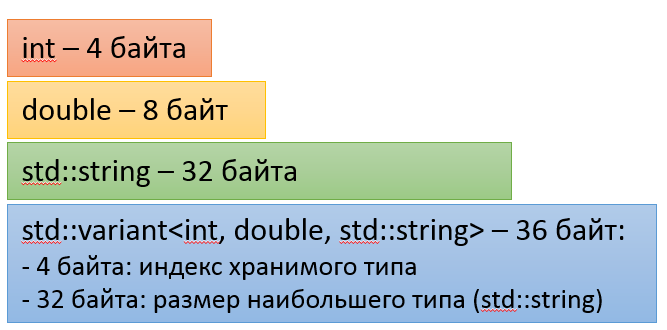
7. Use the functions std :: size, std :: data, std :: begin, std :: end
- use std :: size to measure the length of the C-style array
- this function works with arrays and with STL containers, but will generate a compilation error when you try to pass a normal pointer to it
- use std :: data to get a variable pointer to the beginning of a string, array, or
std::vector<>- Previously, to obtain such a pointer, we used the expression
&text[0], but it has undefined behavior on empty lines.
- Previously, to obtain such a pointer, we used the expression
It may be better to rely on the GSL library (C ++ Core Guidelines Support Library) for byte manipulations.
8. Use std :: filesystem
Key rules:
- pass
std::filesystem::pathinstead of strings in all parameters that imply the path - be careful with the
canonicalfunction: perhaps you meant the lexically_normal method- canonical handles symbolic links, but lexically_normal does not
- canonical requires a path to exist, but lexically_normal does not
- on Windows, an attempt to glue together a path that is too-too-long and a ".." and then apply canonical may fail: Boost throws an exception because the path to the file is too long
- be careful with the
relativefunction: perhaps you meant lexically_relative - try to use noexcept versions of functions (with an error code) if the error is acceptable to you
- for example, use the noexcept version of the exists function, otherwise you will get exceptions for some network paths!
- do not use boost :: filesystem
What is bad boost :: filesystem? It turns out that he has several design problems:
- Boost has not solved the problem of 2038; more precisely, this task was shifted to time_t, but in Linux it is still 32-bit!
- there is a great article on that topic 2038: only 21 years left
- the STL version of the filesystem has all the means to work with encodings
Any experienced programmer knows the difference in processing paths between Windows and UNIX systems:
- in Windows, paths are accepted as UTF-16 strings (or even UCS-2 strings, i.e., surrogate pairs in paths should be avoided!), the often used wchar_t type represents a 2-byte character in UTF-16 encoding, and backslash “\”
- in UNIX, paths are accepted as UTF-8 strings, rarely used wchar_t represents a 4-byte character in UCS32 encoding, and the path separator is the forward slash “/”
Of course, filesystem abstracts from such differences and makes it easy to work with both platform-specific strings and universal UTF-8:
- To get the UTF-8 version of the path, use the u8string method .
- to construct a path from a UTF-8 string, use the free function u8path
- do not use the
std::filesystem::pathconstructor fromstd::string- on Windows, the constructor considers the OS encoding as the input encoding!
Bonus rule: stop reinventing clamp, int_to_string and string_to_int
The std :: clamp function complements the min and max functions. It cuts off the meaning from above and below. A similar function boost::clamp is available in earlier versions of C ++.
The rule "do not reinvent the clamp" can be summarized: in any large project, avoid duplicating small functions and expressions for rounding, clipping values, etc. - just add it to your library once.
A similar rule works for string processing tasks. Do you have your own little library for strings and parsing? Does it have parsing or number formatting? If so, replace your implementation with calls to_chars and from_chars
The to_chars and from_chars support error handling. They return two values:
- the first is of type
char*orconst char*respectively, and points to the first code unit (i.e. char or wchar_t) that could not be processed - the second is of type
std::error_codeand reports detailed error information suitable for throwing an exception std :: system_error
Since in the application code, the error response method may differ, you should place the to_chars and from_chars calls inside your libraries and utility classes.
#include <utility> // , 0 // ( atoi, ) template<class T> T atoi_17(std::string_view str) { T res{}; std::from_chars(str.data(), str.data() + str.size(), res); return res; } ')
Source: https://habr.com/ru/post/343622/
All Articles