LLVM testing
Continued. Start here .
When a program reaches a certain size, it can be guaranteed that it is poorly specified and cannot be fully understood by one person. This is confirmed many times a day by people who are poorly aware of each other’s work. The program has many dependencies, including the compiler, the operating system, libraries, each of which contains its own bugs, and all this is updated from time to time. Moreover, the software should usually work on several different platforms, each of which has its own characteristics. Given the large number of opportunities for misbehavior, why at all can we expect our large program to work as expected? One of the most important things is testing. Thus, we can make sure that the software works as it should in any configuration and platform that is important for us, and when it does not work, there will be smart people who can trace and fix the problem.
Today we will discuss testing LLVM. In many ways, the compiler is a good test object.
But on the other hand, compilers are not so easy to test:
')
So, knowing these basic things, consider how LLVM is tested.
The first line of defense of LLVM against bugs is a test suite that runs when a developer builds a “check” target. All of these tests must be completed before the developer commits the patch to LLVM (and, of course, many patches may include new tests). On my fairly fast desktop, 19,267 tests pass in 96 seconds. The number of tests that are run depends on which additional LLVM projects you have downloaded (compiler-rt, libcxx, etc.) and, to a lesser extent, on software that is automatically detected on your machine (i.e. bundles with OCaml will not be tested until OCaml is installed). These tests should be quick, and developers can run them often, as mentioned here . Additional tests are run when building targets such as check-all and check-clang.
Some modular and regression tests work at the API level, they use Google Test , a lightweight framework that provides C ++ macros to connect a test framework. Here is an example test:
The first argument of the macro TEST_F indicates the name of the collection of tests, and the second is the name of the specific test. The methods parseAssembly () and expectPattern () call the LLVM API and check the result. This example is taken from ValueTrackingTest.cpp . A single file can contain many tests, speeding up the passage of tests due to the absence of fork / exec.
Another infrastructure used by the LLVM quick test suite is lit , LLVM Integrated Tester. lit is based on the shell, it executes the test commands, and concludes that the test passed successfully if all the commands completed successfully.
Here is an example of a test for lit (I took it from the beginning of this file , which contains additional tests that do not matter now):
This test verifies that InstCombine, the passage of the peephole-optimization of the intermediate code level, can notice useless instructions: zext, shl and add are not needed here. The CHECK-LABEL line finds the line from which the optimized code function starts, the first CHECK-NEXT checks that the instruction goes further and, the second CHECK-NEXT checks that the ret instruction goes further (thanks to Michael Kuperstein for a correct and timely explanation of this test).
To run tests, the file is interpreted three times. First, it is scanned, and it searches for lines that contain “RUN:”, and all relevant commands are executed. Further, the file is interpreted by the opt utility, the LLVM IR optimizer, this happens because lit replaced the% s variables with the name of the file being processed. Since comments in the text LLVM IR begin with a semicolon, the lit directives are ignored by the optimizer. The optimizer output is sent to FileCheck utility, which parses the file again, searches for commands, such as CHECK and CHECK-NEXT, they force the utility to search for the string in its stdin, and return a non-zero exit code if any given string is not found (CHECK-LABEL is used to separate a file into a set of logically separate tests).
An important strategic task of testing is to use coverage analysis tools to find parts of the code base that is not covered by tests. Here is a recent LLVM coverage report based on the launch of modular / regression tests. This data is interesting enough to study them in more detail. Let's take a look at the InstCombine coverage, which is generally very good ( link unavailable, unfortunately. Approx. Trans .). An interesting project for someone who wants to start working with LLVM is writing tests to cover non-tested parts of InstCombine. For example, here's the first uncovered test code (highlighted in red) in InstCombineAndOrXor.cpp:
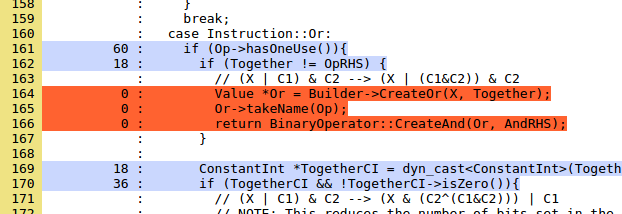
The comment tells us that it is looking for a conversion pass, and it should be fairly easy to write a test for this code. Code that cannot be tested is dead, sometimes dead code should be deleted, in other cases, as in this example (from the same file), the code will not be dead only if a bug appears:
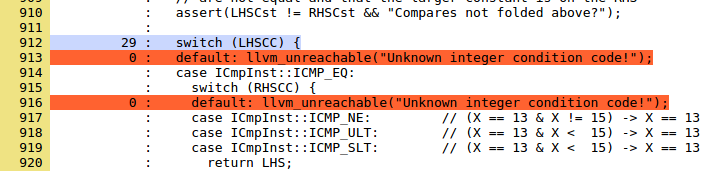
Attempting to cover these lines is a good idea, but in this case you are trying to find a bug in LLVM, and not just improve the test suite. It might be a good idea to teach the cover analysis tool not to tell us about strings marked as unreachable.
In contrast to regression / unit tests that are part of the LLVM repository and can be run quickly, the test suite is external and takes more time. It is not expected that developers will run these tests before a commit, however these tests are run automatically and often with LNT (see the next section). The LLVM test suite contains entire programs that are compiled and run; this is not intended for any specific optimizations, but to confirm the quality and correctness of the generated code as a whole.
For each benchmark, the test suite contains test input and the corresponding expected output. Some parts of the test suite are external, meaning that there is support for invoking these tests, but the tests themselves are not part of the test suite and must be downloaded separately, usually due to non-free software being used.
LNT (LLVM Nightly Test) does not contain any tests; it is a tool for aggregating and analyzing test results, focused on monitoring the quality of the code generated by the compiler. Contains local utilities for running tests and validating results, as well as a server database and web frontend that makes it easy to view the results. NTS results (Nightly Test Suite) are here .
Linux / Windows BuiltBot and Darwin BuiltBot (I don’t know why there are two) are used to make sure that LLVM is configured, built, and passes modular / regression tests on a large number of different platforms and in various configurations. BuildBot has the support of the blame team in order to find the problem commit and send a letter to its author.
Some testing efforts are undertaken outside the core of the LLVM community and are not systematic in terms of which version of LLVM is being tested. These tests appeared thanks to the efforts of individual developers who wanted to try some special tool or technique. For example, for a long time, my group tested Clang + LLVM using Csmith and reported errors found (see the high-level description ). Sam Liedes used afl-fuzz to test Clang. Zhendong Su and his group found a very impressive number of bugs. Nuno Lopes did an awesome test-based optimization test based on formal methods that I hope to write about in a short time.
The last level of testing, of course, is done by LLVM users, who sometimes cause crashes and improper compilations that other test methods have missed. I often wanted to better understand the occurrence of compiler bugs. The reasons for the incorrect compilation of a custom code can be difficult to identify, since it is difficult to reduce the code so as to identify the cause of the bug. However, people use pseudo-random changes in the code during the debag process, cope with the problem due to randomness and soon forget about it.
A great innovation would be the implementation of a translation validation scheme in LLVM that would use an SMT-solver to prove that the compiler output corresponds to the input. There are many problems here, including unspecified behavior, and the fact that it is difficult to scale validation to large functions, which, in practice, cause compilation errors.
A "test oracle" is a way to determine if a test has passed or not. Simple oracles include checks like "compiler ended with code 0" or "compiled benchmark gave the expected output." But so many interesting bugs will be missed, such as “use after release”, which did not cause the program to crash or overflow the whole (see p.7 of this article with an example for GCC). Bug detectors such as ASan, UBSan, and Valgrind can equip the program with oracles derived from the C and C ++ standards, giving many useful features for finding bugs. To run LLVM under Valgrind with test case execution, pass -DLLVM_LIT_ARGS = "- v --vg" in CMake, but be prepared for the fact that Valgrind gives false positives that are difficult to eliminate. To test LLVM with UBSan, pass DLLVM_USE_SANITIZER = Undefined to CMake. This is great, but a lot of work is needed, as UBSan / ASan / MSan does not catch all instances of undefined behavior and also certain, but incorrect behavior, such as the overflow of an unsigned integer in GCC in the example above.
A broken commit can cause a drop in the test at any level. Such a commit is either repaired (if it is not difficult), or rejected, if it has deep flaws or is undesirable in the light of new information provided by the fallen test. This happens often to protect against frequent changes to a large and complex code base with many real users.
When a test fails, and the problem is difficult to fix immediately, but it can be fixed, for example, when new features are completed, the test can be labeled XFAIL, or “expected failure”. Such tests are taken into account by the testing tools separately, and do not fall into the total score of dropped tests, which must be fixed before the patch is accepted.
Testing a large, portable, widely used software system is a difficult task that involves a lot of work if we want to save LLVM users from bugs. Of course, there are other very important things that are needed to preserve the high quality of the code: good design, code review, intermediate presentation semantics, static analysis, periodic reworking of problem areas.
Introduction
When a program reaches a certain size, it can be guaranteed that it is poorly specified and cannot be fully understood by one person. This is confirmed many times a day by people who are poorly aware of each other’s work. The program has many dependencies, including the compiler, the operating system, libraries, each of which contains its own bugs, and all this is updated from time to time. Moreover, the software should usually work on several different platforms, each of which has its own characteristics. Given the large number of opportunities for misbehavior, why at all can we expect our large program to work as expected? One of the most important things is testing. Thus, we can make sure that the software works as it should in any configuration and platform that is important for us, and when it does not work, there will be smart people who can trace and fix the problem.
Today we will discuss testing LLVM. In many ways, the compiler is a good test object.
- Input format (source code) and output format (assembly code) are well understood and have independent specifications.
- Many compilers have an intermediate representation (IR), which is documented in itself and can be displayed and parsed, which makes it easier (although not always) internal testing.
- Often the compiler is one of the independent implementations of the specification, such as the C ++ standard, which allows for differential testing. Even if many implementations are not available, we can often test the compiler by comparing with ourselves, comparing the output of various backends or various optimization modes.
- Compilers usually do not have network functions, concurrency, time dependencies, and always interact with the outside world in a very limited way. Moreover, compilers are usually deterministic.
- Compilers usually do not work for a long time, and we do not need to worry about resource leaks and recovery after errors occur.
But on the other hand, compilers are not so easy to test:
')
- Compilers must be fast, and they are often written in an unsafe language, and have not enough asserts. They use caching and lazy calculations when possible, which increases their complexity. Moreover, the separation of compiler functions into many clear, independent small passes slows down the compiler, and tends to combine unrelated or loosely coupled functions, making the compiler more difficult to understand, test, and support.
- Invariants of the internal data structures of the compiler can be completely hellish and not fully documented.
- Some compilation algorithms are complex, and almost never the compiler implements textbook algorithms exactly, but with more or less differences.
- Compiler optimizations interact in a complex way.
- Compilers of unsafe languages do not have any obligations when compiling unspecified behavior, shifting responsibility for the absence of UB outside the compiler limits (and to the person who writes the tests for the compiler). This complicates differential testing.
- Standards for correctness of compilers are very high, because a program that is incorrectly compiled is difficult to debug, and the compiler can quietly add vulnerabilities to any compiled code.
So, knowing these basic things, consider how LLVM is tested.
Modular and Regression Tests
The first line of defense of LLVM against bugs is a test suite that runs when a developer builds a “check” target. All of these tests must be completed before the developer commits the patch to LLVM (and, of course, many patches may include new tests). On my fairly fast desktop, 19,267 tests pass in 96 seconds. The number of tests that are run depends on which additional LLVM projects you have downloaded (compiler-rt, libcxx, etc.) and, to a lesser extent, on software that is automatically detected on your machine (i.e. bundles with OCaml will not be tested until OCaml is installed). These tests should be quick, and developers can run them often, as mentioned here . Additional tests are run when building targets such as check-all and check-clang.
Some modular and regression tests work at the API level, they use Google Test , a lightweight framework that provides C ++ macros to connect a test framework. Here is an example test:
TEST_F(MatchSelectPatternTest, FMinConstantZero) { parseAssembly( "define float @test(float %a) {\n" " %1 = fcmp ole float %a, 0.0\n" " %A = select i1 %1, float %a, float 0.0\n" " ret float %A\n" "}\n"); // This shouldn't be matched, as %a could be -0.0. expectPattern({SPF_UNKNOWN, SPNB_NA, false}); } The first argument of the macro TEST_F indicates the name of the collection of tests, and the second is the name of the specific test. The methods parseAssembly () and expectPattern () call the LLVM API and check the result. This example is taken from ValueTrackingTest.cpp . A single file can contain many tests, speeding up the passage of tests due to the absence of fork / exec.
Another infrastructure used by the LLVM quick test suite is lit , LLVM Integrated Tester. lit is based on the shell, it executes the test commands, and concludes that the test passed successfully if all the commands completed successfully.
Here is an example of a test for lit (I took it from the beginning of this file , which contains additional tests that do not matter now):
; RUN: opt < %s -instcombine -S | FileCheck %s define i64 @test1(i64 %A, i32 %B) { %tmp12 = zext i32 %B to i64 %tmp3 = shl i64 %tmp12, 32 %tmp5 = add i64 %tmp3, %A %tmp6 = and i64 %tmp5, 123 ret i64 %tmp6 ; CHECK-LABEL: @test1( ; CHECK-NEXT: and i64 %A, 123 ; CHECK-NEXT: ret i64 } This test verifies that InstCombine, the passage of the peephole-optimization of the intermediate code level, can notice useless instructions: zext, shl and add are not needed here. The CHECK-LABEL line finds the line from which the optimized code function starts, the first CHECK-NEXT checks that the instruction goes further and, the second CHECK-NEXT checks that the ret instruction goes further (thanks to Michael Kuperstein for a correct and timely explanation of this test).
To run tests, the file is interpreted three times. First, it is scanned, and it searches for lines that contain “RUN:”, and all relevant commands are executed. Further, the file is interpreted by the opt utility, the LLVM IR optimizer, this happens because lit replaced the% s variables with the name of the file being processed. Since comments in the text LLVM IR begin with a semicolon, the lit directives are ignored by the optimizer. The optimizer output is sent to FileCheck utility, which parses the file again, searches for commands, such as CHECK and CHECK-NEXT, they force the utility to search for the string in its stdin, and return a non-zero exit code if any given string is not found (CHECK-LABEL is used to separate a file into a set of logically separate tests).
An important strategic task of testing is to use coverage analysis tools to find parts of the code base that is not covered by tests. Here is a recent LLVM coverage report based on the launch of modular / regression tests. This data is interesting enough to study them in more detail. Let's take a look at the InstCombine coverage, which is generally very good ( link unavailable, unfortunately. Approx. Trans .). An interesting project for someone who wants to start working with LLVM is writing tests to cover non-tested parts of InstCombine. For example, here's the first uncovered test code (highlighted in red) in InstCombineAndOrXor.cpp:
The comment tells us that it is looking for a conversion pass, and it should be fairly easy to write a test for this code. Code that cannot be tested is dead, sometimes dead code should be deleted, in other cases, as in this example (from the same file), the code will not be dead only if a bug appears:
Attempting to cover these lines is a good idea, but in this case you are trying to find a bug in LLVM, and not just improve the test suite. It might be a good idea to teach the cover analysis tool not to tell us about strings marked as unreachable.
LLVM test suite
In contrast to regression / unit tests that are part of the LLVM repository and can be run quickly, the test suite is external and takes more time. It is not expected that developers will run these tests before a commit, however these tests are run automatically and often with LNT (see the next section). The LLVM test suite contains entire programs that are compiled and run; this is not intended for any specific optimizations, but to confirm the quality and correctness of the generated code as a whole.
For each benchmark, the test suite contains test input and the corresponding expected output. Some parts of the test suite are external, meaning that there is support for invoking these tests, but the tests themselves are not part of the test suite and must be downloaded separately, usually due to non-free software being used.
Lnt
LNT (LLVM Nightly Test) does not contain any tests; it is a tool for aggregating and analyzing test results, focused on monitoring the quality of the code generated by the compiler. Contains local utilities for running tests and validating results, as well as a server database and web frontend that makes it easy to view the results. NTS results (Nightly Test Suite) are here .
Buildbot
Linux / Windows BuiltBot and Darwin BuiltBot (I don’t know why there are two) are used to make sure that LLVM is configured, built, and passes modular / regression tests on a large number of different platforms and in various configurations. BuildBot has the support of the blame team in order to find the problem commit and send a letter to its author.
Eclectic Testing Effort
Some testing efforts are undertaken outside the core of the LLVM community and are not systematic in terms of which version of LLVM is being tested. These tests appeared thanks to the efforts of individual developers who wanted to try some special tool or technique. For example, for a long time, my group tested Clang + LLVM using Csmith and reported errors found (see the high-level description ). Sam Liedes used afl-fuzz to test Clang. Zhendong Su and his group found a very impressive number of bugs. Nuno Lopes did an awesome test-based optimization test based on formal methods that I hope to write about in a short time.
Testing in the wild
The last level of testing, of course, is done by LLVM users, who sometimes cause crashes and improper compilations that other test methods have missed. I often wanted to better understand the occurrence of compiler bugs. The reasons for the incorrect compilation of a custom code can be difficult to identify, since it is difficult to reduce the code so as to identify the cause of the bug. However, people use pseudo-random changes in the code during the debag process, cope with the problem due to randomness and soon forget about it.
A great innovation would be the implementation of a translation validation scheme in LLVM that would use an SMT-solver to prove that the compiler output corresponds to the input. There are many problems here, including unspecified behavior, and the fact that it is difficult to scale validation to large functions, which, in practice, cause compilation errors.
Alternate test oracles
A "test oracle" is a way to determine if a test has passed or not. Simple oracles include checks like "compiler ended with code 0" or "compiled benchmark gave the expected output." But so many interesting bugs will be missed, such as “use after release”, which did not cause the program to crash or overflow the whole (see p.7 of this article with an example for GCC). Bug detectors such as ASan, UBSan, and Valgrind can equip the program with oracles derived from the C and C ++ standards, giving many useful features for finding bugs. To run LLVM under Valgrind with test case execution, pass -DLLVM_LIT_ARGS = "- v --vg" in CMake, but be prepared for the fact that Valgrind gives false positives that are difficult to eliminate. To test LLVM with UBSan, pass DLLVM_USE_SANITIZER = Undefined to CMake. This is great, but a lot of work is needed, as UBSan / ASan / MSan does not catch all instances of undefined behavior and also certain, but incorrect behavior, such as the overflow of an unsigned integer in GCC in the example above.
What happens if the test fails?
A broken commit can cause a drop in the test at any level. Such a commit is either repaired (if it is not difficult), or rejected, if it has deep flaws or is undesirable in the light of new information provided by the fallen test. This happens often to protect against frequent changes to a large and complex code base with many real users.
When a test fails, and the problem is difficult to fix immediately, but it can be fixed, for example, when new features are completed, the test can be labeled XFAIL, or “expected failure”. Such tests are taken into account by the testing tools separately, and do not fall into the total score of dropped tests, which must be fixed before the patch is accepted.
Conclusion
Testing a large, portable, widely used software system is a difficult task that involves a lot of work if we want to save LLVM users from bugs. Of course, there are other very important things that are needed to preserve the high quality of the code: good design, code review, intermediate presentation semantics, static analysis, periodic reworking of problem areas.
Source: https://habr.com/ru/post/343594/
All Articles