Serverless tensorflow on AWS Lambda
Machine learning and neural networks are becoming increasingly indispensable for many companies. One of the main problems they face is the deployment of such applications. I want to show to show a practical and convenient way of such deployment, for which you do not need to be an expert in cloud technologies and clusters. For this we will use the serverless infrastructure.
Introduction
Recently, many tasks in the product are solved using models created by machine learning or neural networks. Often these are tasks that have been solved for many years by ordinary deterministic methods and are now easier and cheaper to solve through ML.
Having modern frameworks like Keras or Tensorflow and catalogs of ready-made solutions, it becomes easier to create models that provide the necessary accuracy for the product.
My colleagues call this “commoditization of machine learning” and in some ways they are right. The most important thing is that today it is easy to find / download / train a model and you want to be able to deploy it as well.
Again, when working in a startup or a small company, it is often necessary to quickly check assumptions, not only technical, but also market. And for this you need to quickly and easily deploy the model, expecting not strong, but still traffic.
To solve this deployment problem, I liked working with cloud microservices.
Amazon, Google and Microsoft recently provided FaaS - function as a service. They are relatively cheap, they are easy to deploy (Docker is not required) and you can run a nearly unlimited number of entities in parallel.
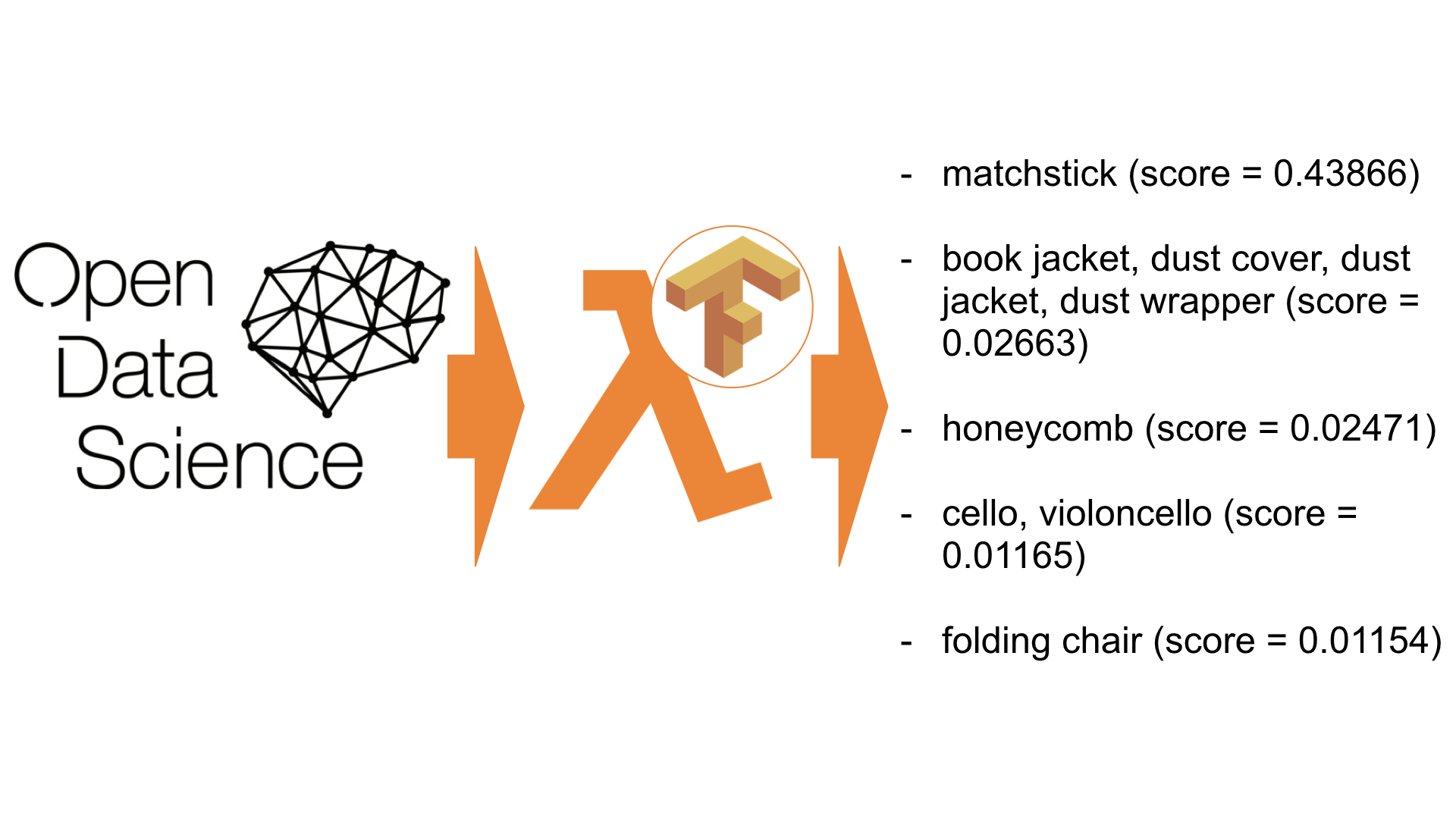
Now I’ll tell you how you can cover TensorFlow / Keras models on AWS Lambda - FaaS from Amazon. As a result, there is an API for recognizing content on images that cost $ 1 for 20,000 recognitions. Is it cheaper? Maybe. Can it be easier? Hardly.
Function-as-a-service
Consider a diagram of different types of deployments of applications:
On the left we see on premise - when we own the server. Next, we see Infrastructure-as-a-Service - here we are already working with a virtual machine - a server located in a data center. The next step is Platform-as-a-Service, when we no longer have access to the machine itself, but we manage the container in which the application will run. And finally, Function-as-a-Service, when we control only the code, and everything else is hidden from us. This is good news, as we will see later, which gives us a very cool functionality.
AWS Lambda is the implementation of FAAS on the AWS platform. Briefly about implementation. The container for it is a zip archive [code + libraries]. The code is the same as on the local machine. AWS deploys this code on containers depending on the number of external requests (triggers). There are essentially no boundaries on top - the current limit is 1000 containers working at the same time, but it can easily be raised to 10,000 or more through support.
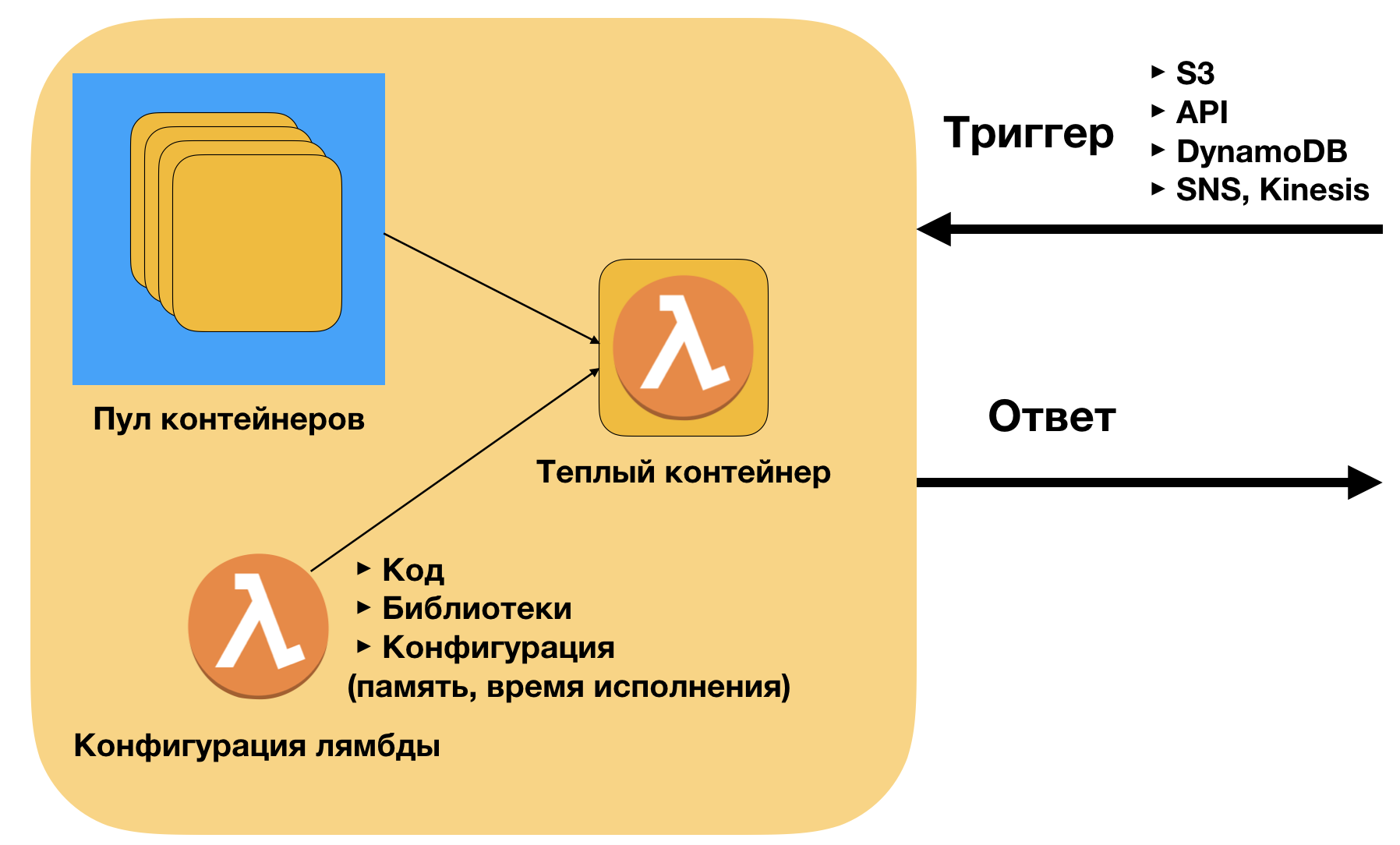
Main advantages of AWS Lambda:
- Easy Deploy (without docker) - only code and libraries
- Easy to connect to triggers (API, S3, SNS, DynamoDB)
- Good scaling - in production we launched over 40 thousand invocations simultaneously. It is possible and more.
- Low call price. For my colleagues from the BD referral it is also important that microservices support the pay-as-you-go model for using the service. This makes it understandable for the unit economy to use the model when scaling.
Why port neural networks to serverless
First of all, I want to clarify that for my examples I use Tensorflow - an open framework that allows developers to create, train and deploy machine learning models. At the moment, it is the most popular library for deep learning and is used by both experts and beginners.
At the moment, the main way to deploy machine learning models is cluster. If we want to make a REST API for deep learning, it will look like this:
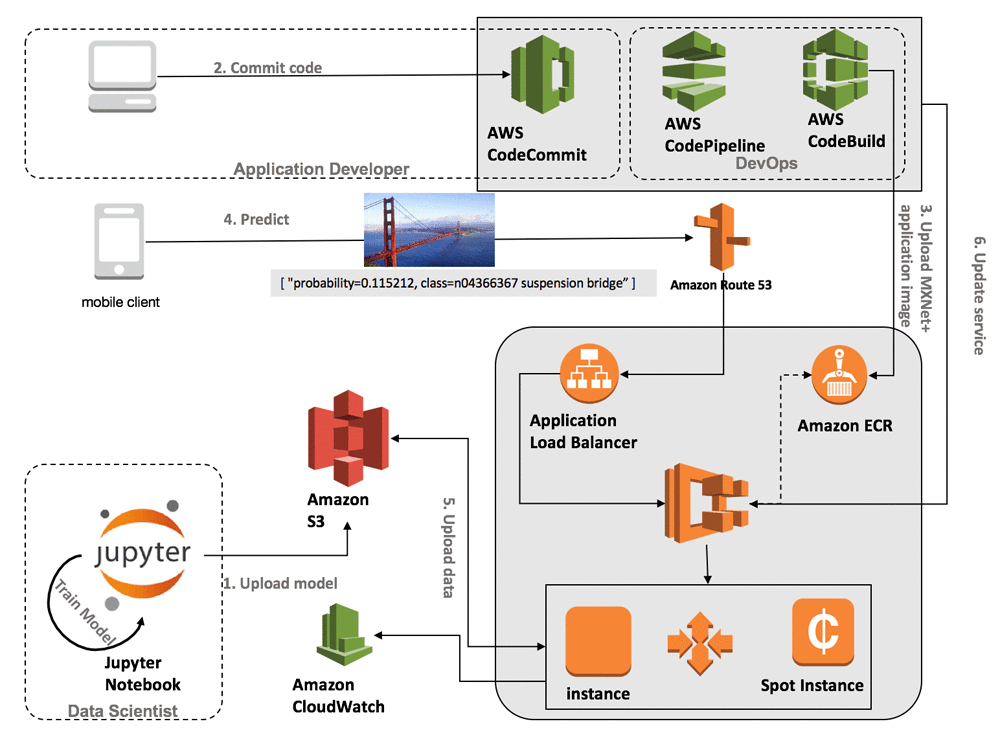
( Image from AWS blog )
Seems bulky? At the same time, you will have to take care of the following things:
- register the logic of traffic distribution on cluster machines
- prescribe the logic of scaling, trying to find a middle ground between downtime and inhibition
- register the behavior logic of the container - logging, managing incoming requests
On AWS Lambda, the architecture will look noticeably simpler:
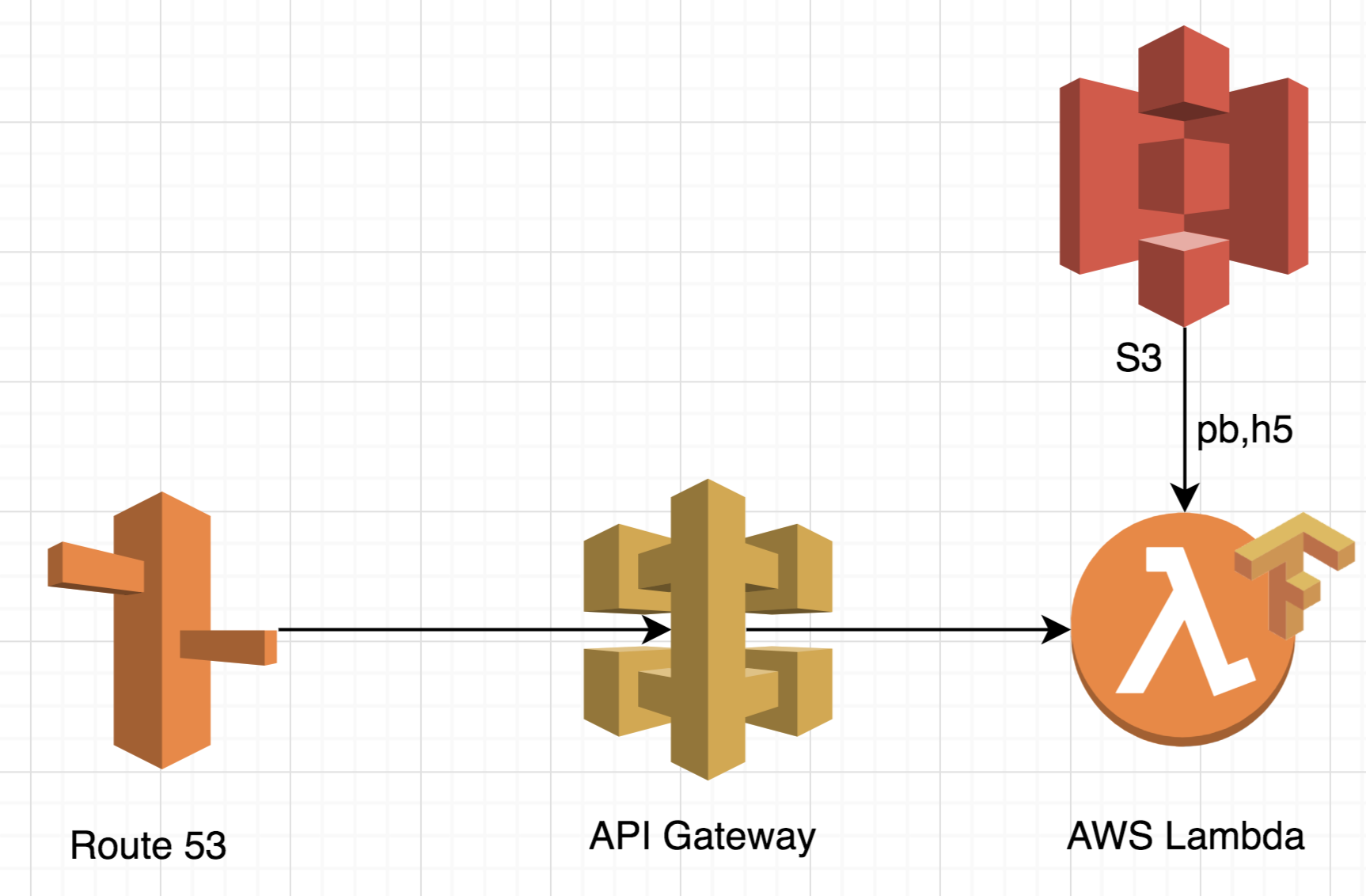
Firstly, this approach is very scalable. It can process up to 10 thousand simultaneous requests without prescribing any additional logic. This feature makes the architecture ideal for processing peak loads, since it does not require additional processing time.
Secondly, you do not have to pay for a simple server. In Serverless architecture, payment is made for one request. This means that if you have 25 thousand requests, you will only pay for 25 thousand requests, regardless of the flow they received. Thus, not only the cost becomes more transparent, but the cost itself is very low. For example on Tensorflow, which I will show later, the cost is 20-25 thousand requests for 1 dollar. A cluster with similar functionality costs much more, and it is more profitable to become only on a very large number of requests (> 1 million).
Thirdly, the infrastructure becomes much larger. No need to work with the docker, to prescribe the logic of scaling and load distribution. In short, the company will not have to hire an additional person to support the infrastructure, and if you are dataseentist, then you can do everything with your own hands.
As you will see below, deploying the entire infrastructure requires no more than 4 lines of code for the above application.
It would be incorrect not to say about the shortcomings of the serverless infrastructure and about the cases when it will not work. AWS Lambda has strict limitations on processing time and available memory, which must be kept in mind.
First, as I mentioned earlier, clusters become more profitable after a certain number of requests. In cases where you do not have a peak load and a lot of rekvestov, the cluster will be more profitable.
Secondly, AWS Lambda has a small, but certain start time (100-200ms). For deep learning applications it takes some more time to download the model from S3. For example, which I will show below, a cold start will be 4.5 seconds, and a warm start will be 3 seconds. For some applications this may not be critical, but if your application is focused on processing a single request as quickly as possible, the cluster would be a better option.
application
We now turn to the practical part.
For this example, I use a fairly popular application of neural networks - image recognition. Our application takes a picture as an input and returns a description of the object on it. Applications of this kind are widely used to filter images and classify multiple images into groups. Our application will try to recognize a photo of a panda.

Memo: Model and original code are available here.
We will use the following stack:
- API Gateway to manage requests
- AWS Lambda for processing
- Serverless Deployment Framework
“Hello world” code
First, you need to install and configure the Serverless framework, which we will use to orchestrate and deploy the application. Link to guide .
Make an empty folder and run the following command:
serverless install -u https://github.com/ryfeus/lambda-packs/tree/master/tensorflow/source -n tensorflow cd tensorflow serverless deploy serverless invoke --function main --log You will receive the following response:
/tmp/imagenet/imagenet_synset_to_human_label_map.txt /tmp/imagenet/imagenet_2012_challenge_label_map_proto.pbtxt /tmp/imagenet/classify_image_graph_def.pb /tmp/imagenet/inputimage.jpg giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107) indri, indris, Indri indri, Indri brevicaudatus (score = 0.00779) lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00296) custard apple (score = 0.00147) earthstar (score = 0.00117) As you can see, our application successfully recognized the panda picture (0.89).
Voila We successfully closed the neural network for image recognition on Tensorflow on AWS Lambda.
Consider the code in more detail.
Let's start with the configuration file. Nothing non-standard - we use the basic configuration of AWS Lambda.
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handler If we look at the 'index.py' file itself, we will see that we first download the model ('.pb' file) into the '/ tmp /' folder on AWS Lambda, and then import it in the standard way through Tensorflow.
Below are links to parts of the code in Github that you should keep in mind if you want to insert your own model:
strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/classify_image_graph_def.pb' strFile = '/tmp/imagenet/classify_image_graph_def.pb' downloadFromS3(strBucket,strKey,strFile) print(strFile) def create_graph(): with tf.gfile.FastGFile(os.path.join('/tmp/imagenet/', 'classify_image_graph_def.pb'), 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name='') strFile = '/tmp/imagenet/inputimage.jpg' if ('imagelink' in event): urllib.urlretrieve(event['imagelink'], strFile) else: strBucket = 'ryfeuslambda' strKey = 'tensorflow/imagenet/cropped_panda.jpg' downloadFromS3(strBucket,strKey,strFile) print(strFile) Getting predictions from the model :
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data}) predictions = np.squeeze(predictions) Now let's add the API to the lambda.
API example
The easiest way to add an API is to modify the configuration YAML file.
service: tensorflow frameworkVersion: ">=1.2.0 <2.0.0" provider: name: aws runtime: python2.7 memorySize: 1536 timeout: 300 functions: main: handler: index.handler events: - http: GET handler Now let's redo the stack:
serverless deploy We get the following.
Service Information service: tensorflow stage: dev region: us-east-1 stack: tensorflow-dev api keys: None endpoints: GET - https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler functions: main: tensorflow-dev-main To test the API you can simply open as a link:
https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler Or use curl:
curl https://<urlkey>.execute-api.us-east-1.amazonaws.com/dev/handler We'll get:
{"return": "giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)"} Conclusion
We created an API for the Tensorflow model based on AWS Lambda using a Serverless framework. Everything was done quite simply and this approach saved us a lot of time compared to the traditional approach.
By modifying the configuration file, you can connect many other AWS services, such as SQS for stream processing of tasks, or you can create a chatbot using AWS Lex.
As my hobby, I port many libraries to make serverless more friendly. You can find them here . The MIT project has a license, so you can safely modify and use it for your tasks.
Libraries include the following examples:
- Machine Learning (Scikit, LightGBM)
- Computer vision (Skimage, OpenCV, PIL)
- Text Recognition (Tesseract)
- Text Analysis (Spacy)
- Web scraping (Selenium, PhantomJS, lxml)
- API Testing (WRK, pyrestest)
I am very happy to see how others use serverless for their projects. Be sure to tell feedback in the comments and successful development of you.
')
Source: https://habr.com/ru/post/343538/
All Articles