MSA and more: how we create high-load services for the bank
Designing high-loaded services is no longer a mysterious skill that only enlightened senseis have. Today, for this there are well-established practices that are combined and modified depending on the characteristics of the company and its business. We want to talk about our best practices and tools for creating high-load services.

Immediately make a reservation that we will focus on custom development. As common sense bequeathed to us, we start designing with the setting of business tasks. And including we define, whether the system will be high-loaded. It is clear that over time it will change (for example, the load profile will change), therefore, when describing business logic, we lay down the likely paths of development where it is possible. Let's say if this is some kind of customer service, then you can predict a change in the size of the audience. Sometimes it is immediately clear how the system will change over time, and some control points are difficult to predict.
At the initial stage, we can calculate the data volumes that we need for storage, calculate the initial load on our abstract service and its growth rate. You can also classify data by type of work with them: storage, writing or reading, and depending on this to optimize processes.
')
We have a KPI for the system, on the basis of which the permissible degree of its degradation is determined. For most systems, response time is critical. In some cases, it can reach a few seconds, while in others it takes a millisecond. Also at this stage is determined by the degree of accessibility of the system. As a rule, we develop high-availability systems or systems of continuous operation: with availability from 99.9% to 99.999%.
Having decided on the business logic, permissible data volumes and system behavior, we begin to build data movement diagrams. This is necessary in order to understand which design pattern is best to choose. And after constructing the diagrams, we proceed to the design itself.
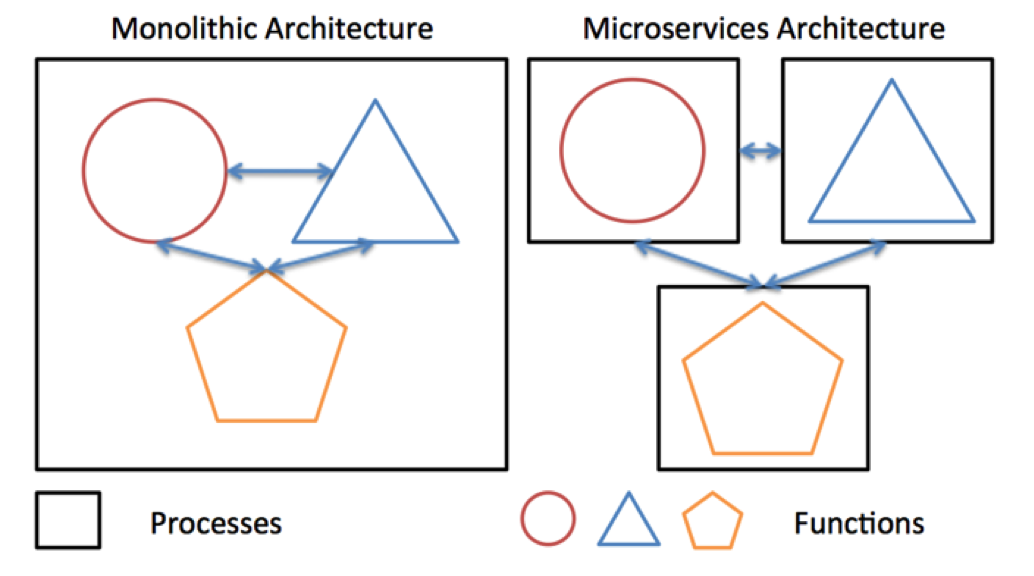
Recently, when creating high-loaded systems, we prefer a service-oriented architecture. In particular, microservice so fashionable in recent years: we take the functionality of the system and divide it into small pieces - services, each of which performs some small task. There can be a lot of services, hundreds or thousands. Such an architecture facilitates system support, and changes made to individual services have a much smaller effect on the system as a whole.
Another important feature of microservice architecture is also good scalability.
But besides the weighty advantages, microservice architecture has a significant drawback: it is not always possible to divide business logic into fairly small functional pieces.
This task is complex, and, as a rule, is solved at the design stage. The downside of the medal is interservice interaction. You must ensure that the messaging overhead is not too large. This is achieved mainly by choosing effective methods for serializing / deserializing data (more on this below), moving interacting services “closer” to each other, or combining them into one microservice. But if it is possible to successfully divide the logic into small tasks, then all the advantages of microservice architecture will be at your service.
Microservice architecture allows you to place services on a large number of nodes and lay the necessary redundancy in case of failure of some nodes (pah-pah-pah). The redundancy scheme largely depends on the initial tasks. Somewhere it is impossible to allow pauses and instant service restoration is required - in this case the Active / Active scheme is used when the balancer instantly disconnects the failed node. In other cases, let us assume a small idle time at the time of service restoration, and then the Active / Standby scheme is used, when the backup node is not immediately available, but after a short period of time, until the service is automatically transferred to the backup node.
Obvious examples of the need to use options for Active / Active schemes can serve as remote banking services - Internet and mobile banking.
Traditionally, VTB Bank has a fairly large amount of customized software development. Until recently, the technologies .NET and Java Enterprise were mainly used for these purposes. Now these funds are already considered by us as legacy. For new projects, we started to use approaches based on microservice architecture (MSA - Microservice Architecture).
More specifically, the new systems in the bank are designed as a set of microservices on the Spring Boot platform. The main reasons for choosing the Spring Framework were its prevalence in the IT services market, as well as the relative ease of its use in the development of services and microservices.
As a rule, a web interface developed using React or Angular, interacting with server components via the Rest API, is used for user interaction.
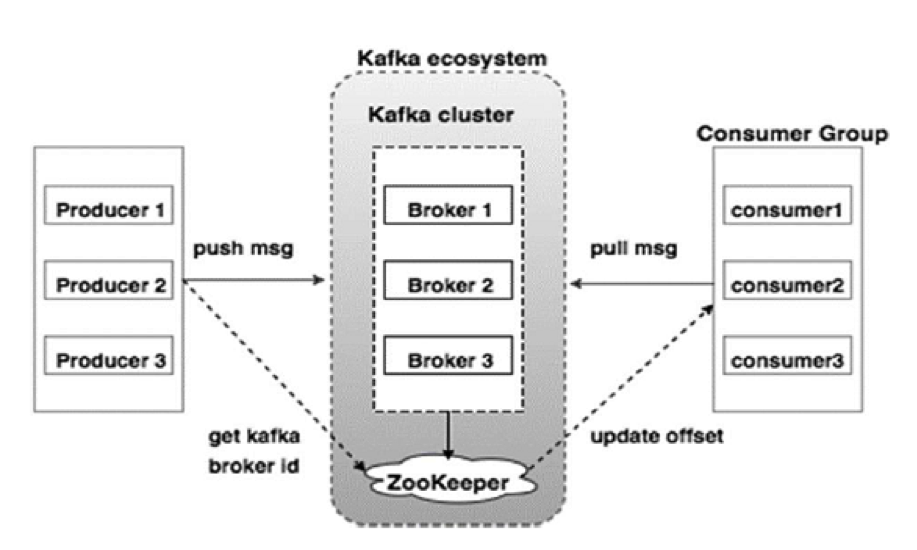
A separate topic is the interaction of MSA components with each other, as well as their integration with the existing IT ecosystem. Along with traditional approaches, such as MQ queues, we are actively introducing new interaction patterns based on weak connectivity and the Apache Kafka platform.
Now there are a lot of technologies that allow building high-load systems with a short response time. But their composition is constantly changing: something is constantly coming from the world of Open Source, new internal projects are being developed, some of which are also being transferred to the open source camp. However, we prefer proven solutions from well-known vendors. Our task is to increase the competence in the use of such systems.
It is hard to imagine a highly loaded system that does not use data caching. Although there is a large selection of tools on the market, we usually adhere to the proven “classics” - Memcached and Redis. But lately they have begun to glance in the direction of Apache Ignite, on some projects it has proven itself as a distributed cache.
As for the choice of programming languages, a lot depends on the task. As a rule, the choice falls on Java - here and a large number of frameworks that allow you to quickly and efficiently implement the necessary functionality, and a large number of settings of the JVM itself, allowing to achieve the required performance indicators.
When designing MSA, we also stick to the Java technology stack. In addition to unification, this allows us to easily integrate with applications already running in the bank through traditional integration mechanisms — MQ queues, web services, and numerous Java-based APIs. It also allows you to use the advanced development tools and microservice management tools available on this platform.
It is also important that there are already quite a few MSA application development specialists using the JVM-based technology stack on the Russian market.
With regard to data storage, the first question in the design arises: what kind of data model should the DBMS use - relational or some other? Further methods of increasing the efficiency of processing requests to the database depend on the choice, since high-load services should have a short response time a priori. If we are talking about relational DBMS, their use in high-loaded projects requires solving the problem of increasing the efficiency of queries. It all starts with an analysis of the query plan.
As a rule, according to its results, we change the queries themselves, we add indexes. You can apply partitioning to tables, reducing the amount of data in the samples by limiting them to one or more partitions. It is also often necessary to use data denormalization, introducing some redundancy - this is how you can increase the efficiency of queries.
And with non-relational DBMS, one has to use almost individual approaches depending on the specific product, on business scenarios. From the general approaches, it is possible to distinguish perhaps the delayed processing of laborious calculations.
Of course, it all depends on the specific task, but if there is a possibility, we use Oracle, because it takes less time for our engineers to write effective queries and set up. Also recently, we often look towards Apache Ignite.
As mentioned above, we cannot always predict what kind of load the system will create in six months or a year. And if you do not lay the possibility of scaling, the system will very quickly cease to cope with the growing load. Depending on the specific project, vertical or horizontal scaling is applied. Vertical - increase in the performance of individual components by adding resources within one component / node; horizontal - increasing the number of components / nodes in order to distribute the load on them.
Scaling a service or component is much easier if it uses the stateless paradigm, that is, it does not store the context between requests. In this case, we can easily deploy multiple copies of this component or service in the system, balancing the load between them. In the case of a stateful paradigm, care must be taken to ensure that balancing takes into account the presence of states in components / services.
Running a high-load system is unthinkable without load testing. Under load testing is the verification of the achievement of certain KPIs at the entrance. From our experience, a long query processing time is most often associated with the inefficiency of the algorithm. Also, performance caching is facilitated by a large number of queries of the same type.
Tests reveal bottlenecks that we might have overlooked when designing. A web service implemented in one of the projects, under load testing, worked with poor performance, despite its simplicity. Profiling showed that serialization-deserialization of data took most of the time, that is, we basically distilled the data structures into a bit representation and back. The solution was found quickly enough - the nature of the data was such that they changed extremely rarely. We were able to implement the pre-serialization of data (by preparing a serialized representation in advance), and greatly reduced the response time.
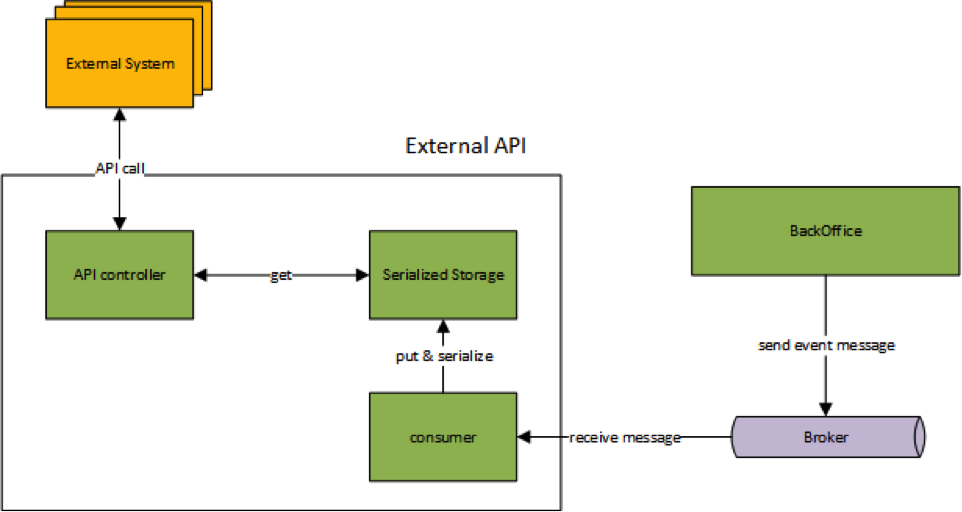
Serialization optimization for external API (pre-serialization)
Along with load testing, in which we test the system for compliance with the requirements, we also carry out load tests. The purpose of such tests is to find out the maximum possible load that the system can withstand.
Metrics play the role of sensors, they are heavily strewn with any serious system, especially highly loaded. Without metrics, any program turns into a black box with inputs and outputs, it is unclear how it works inside. When designing in architecture laid the meters that generate information for the monitoring system.
In some projects, ELK (Elastick Search Kibana) was used to visualize system activity and monitor it. This framework has a flexible interface that allows you to easily and quickly set up the necessary reporting form.
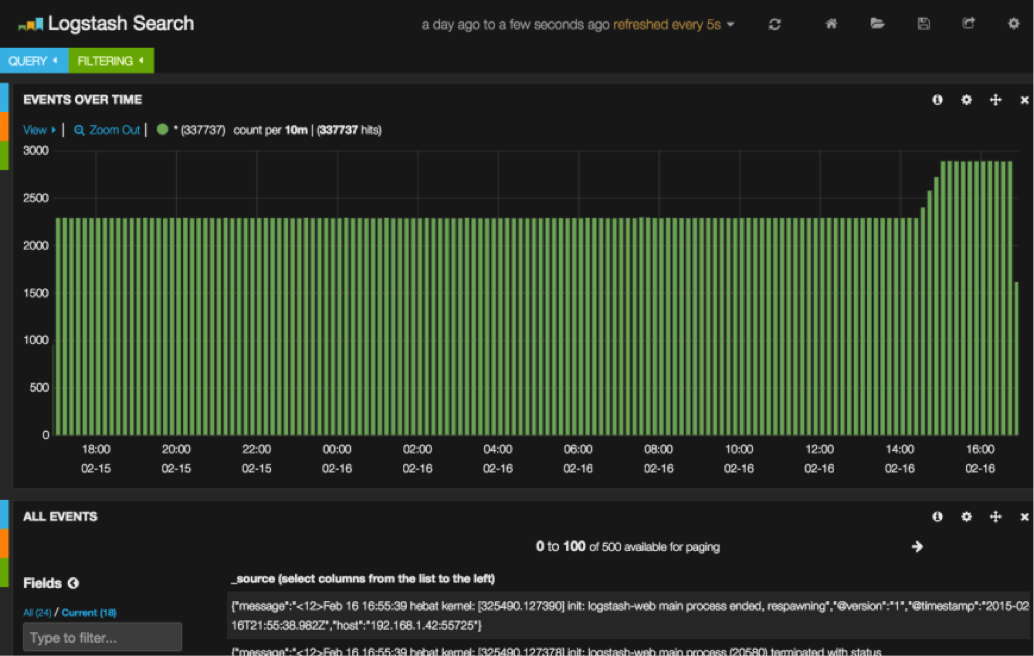
Kibana Monitoring
When building fault-tolerant high-load systems, there is no silver bullet. We can cope with loads not at the expense of technology, but at the expense of a properly chosen system architecture. It is always a search for some compromises. In some cases, we can take existing approaches and patterns, and in some we have to design and implement our architectural solutions.
Immediately make a reservation that we will focus on custom development. As common sense bequeathed to us, we start designing with the setting of business tasks. And including we define, whether the system will be high-loaded. It is clear that over time it will change (for example, the load profile will change), therefore, when describing business logic, we lay down the likely paths of development where it is possible. Let's say if this is some kind of customer service, then you can predict a change in the size of the audience. Sometimes it is immediately clear how the system will change over time, and some control points are difficult to predict.
At the initial stage, we can calculate the data volumes that we need for storage, calculate the initial load on our abstract service and its growth rate. You can also classify data by type of work with them: storage, writing or reading, and depending on this to optimize processes.
')
We have a KPI for the system, on the basis of which the permissible degree of its degradation is determined. For most systems, response time is critical. In some cases, it can reach a few seconds, while in others it takes a millisecond. Also at this stage is determined by the degree of accessibility of the system. As a rule, we develop high-availability systems or systems of continuous operation: with availability from 99.9% to 99.999%.
Having decided on the business logic, permissible data volumes and system behavior, we begin to build data movement diagrams. This is necessary in order to understand which design pattern is best to choose. And after constructing the diagrams, we proceed to the design itself.
Microservices - the buzzword of our time
Recently, when creating high-loaded systems, we prefer a service-oriented architecture. In particular, microservice so fashionable in recent years: we take the functionality of the system and divide it into small pieces - services, each of which performs some small task. There can be a lot of services, hundreds or thousands. Such an architecture facilitates system support, and changes made to individual services have a much smaller effect on the system as a whole.
Another important feature of microservice architecture is also good scalability.
But besides the weighty advantages, microservice architecture has a significant drawback: it is not always possible to divide business logic into fairly small functional pieces.
This task is complex, and, as a rule, is solved at the design stage. The downside of the medal is interservice interaction. You must ensure that the messaging overhead is not too large. This is achieved mainly by choosing effective methods for serializing / deserializing data (more on this below), moving interacting services “closer” to each other, or combining them into one microservice. But if it is possible to successfully divide the logic into small tasks, then all the advantages of microservice architecture will be at your service.
Microservice architecture allows you to place services on a large number of nodes and lay the necessary redundancy in case of failure of some nodes (pah-pah-pah). The redundancy scheme largely depends on the initial tasks. Somewhere it is impossible to allow pauses and instant service restoration is required - in this case the Active / Active scheme is used when the balancer instantly disconnects the failed node. In other cases, let us assume a small idle time at the time of service restoration, and then the Active / Standby scheme is used, when the backup node is not immediately available, but after a short period of time, until the service is automatically transferred to the backup node.
Obvious examples of the need to use options for Active / Active schemes can serve as remote banking services - Internet and mobile banking.
Traditionally, VTB Bank has a fairly large amount of customized software development. Until recently, the technologies .NET and Java Enterprise were mainly used for these purposes. Now these funds are already considered by us as legacy. For new projects, we started to use approaches based on microservice architecture (MSA - Microservice Architecture).
More specifically, the new systems in the bank are designed as a set of microservices on the Spring Boot platform. The main reasons for choosing the Spring Framework were its prevalence in the IT services market, as well as the relative ease of its use in the development of services and microservices.
As a rule, a web interface developed using React or Angular, interacting with server components via the Rest API, is used for user interaction.
A separate topic is the interaction of MSA components with each other, as well as their integration with the existing IT ecosystem. Along with traditional approaches, such as MQ queues, we are actively introducing new interaction patterns based on weak connectivity and the Apache Kafka platform.
Languages and frameworks
Now there are a lot of technologies that allow building high-load systems with a short response time. But their composition is constantly changing: something is constantly coming from the world of Open Source, new internal projects are being developed, some of which are also being transferred to the open source camp. However, we prefer proven solutions from well-known vendors. Our task is to increase the competence in the use of such systems.
It is hard to imagine a highly loaded system that does not use data caching. Although there is a large selection of tools on the market, we usually adhere to the proven “classics” - Memcached and Redis. But lately they have begun to glance in the direction of Apache Ignite, on some projects it has proven itself as a distributed cache.
As for the choice of programming languages, a lot depends on the task. As a rule, the choice falls on Java - here and a large number of frameworks that allow you to quickly and efficiently implement the necessary functionality, and a large number of settings of the JVM itself, allowing to achieve the required performance indicators.
When designing MSA, we also stick to the Java technology stack. In addition to unification, this allows us to easily integrate with applications already running in the bank through traditional integration mechanisms — MQ queues, web services, and numerous Java-based APIs. It also allows you to use the advanced development tools and microservice management tools available on this platform.
It is also important that there are already quite a few MSA application development specialists using the JVM-based technology stack on the Russian market.
Data storage
With regard to data storage, the first question in the design arises: what kind of data model should the DBMS use - relational or some other? Further methods of increasing the efficiency of processing requests to the database depend on the choice, since high-load services should have a short response time a priori. If we are talking about relational DBMS, their use in high-loaded projects requires solving the problem of increasing the efficiency of queries. It all starts with an analysis of the query plan.
As a rule, according to its results, we change the queries themselves, we add indexes. You can apply partitioning to tables, reducing the amount of data in the samples by limiting them to one or more partitions. It is also often necessary to use data denormalization, introducing some redundancy - this is how you can increase the efficiency of queries.
And with non-relational DBMS, one has to use almost individual approaches depending on the specific product, on business scenarios. From the general approaches, it is possible to distinguish perhaps the delayed processing of laborious calculations.
Of course, it all depends on the specific task, but if there is a possibility, we use Oracle, because it takes less time for our engineers to write effective queries and set up. Also recently, we often look towards Apache Ignite.
Scaling
As mentioned above, we cannot always predict what kind of load the system will create in six months or a year. And if you do not lay the possibility of scaling, the system will very quickly cease to cope with the growing load. Depending on the specific project, vertical or horizontal scaling is applied. Vertical - increase in the performance of individual components by adding resources within one component / node; horizontal - increasing the number of components / nodes in order to distribute the load on them.
Scaling a service or component is much easier if it uses the stateless paradigm, that is, it does not store the context between requests. In this case, we can easily deploy multiple copies of this component or service in the system, balancing the load between them. In the case of a stateful paradigm, care must be taken to ensure that balancing takes into account the presence of states in components / services.
Physical world
Tests, tests, and again tests
Running a high-load system is unthinkable without load testing. Under load testing is the verification of the achievement of certain KPIs at the entrance. From our experience, a long query processing time is most often associated with the inefficiency of the algorithm. Also, performance caching is facilitated by a large number of queries of the same type.
Tests reveal bottlenecks that we might have overlooked when designing. A web service implemented in one of the projects, under load testing, worked with poor performance, despite its simplicity. Profiling showed that serialization-deserialization of data took most of the time, that is, we basically distilled the data structures into a bit representation and back. The solution was found quickly enough - the nature of the data was such that they changed extremely rarely. We were able to implement the pre-serialization of data (by preparing a serialized representation in advance), and greatly reduced the response time.
Serialization optimization for external API (pre-serialization)
Along with load testing, in which we test the system for compliance with the requirements, we also carry out load tests. The purpose of such tests is to find out the maximum possible load that the system can withstand.
Monitoring
Metrics play the role of sensors, they are heavily strewn with any serious system, especially highly loaded. Without metrics, any program turns into a black box with inputs and outputs, it is unclear how it works inside. When designing in architecture laid the meters that generate information for the monitoring system.
In some projects, ELK (Elastick Search Kibana) was used to visualize system activity and monitor it. This framework has a flexible interface that allows you to easily and quickly set up the necessary reporting form.
Kibana Monitoring
Conclusion
When building fault-tolerant high-load systems, there is no silver bullet. We can cope with loads not at the expense of technology, but at the expense of a properly chosen system architecture. It is always a search for some compromises. In some cases, we can take existing approaches and patterns, and in some we have to design and implement our architectural solutions.
Source: https://habr.com/ru/post/343506/
All Articles