LizardFS - a brief overview of the cluster file system
Interesting cluster file system. On one not very big project we implemented it and it works better than the popular GlusterFS or NFS solutions. Uses FUSE when connecting on the client side. We thought that it would not work better than other cluster file systems, but in reality everything turned out to be very positive.
UPD:
')
After some time, we implemented LizardFS already on an average project, in fact, almost immediately after the publication of this article, we just had to look under the loads before writing the update article.
After 3 months and even there was a reboot of the master server, for reasons beyond the FS itself, I can say that it is the best cluster FS available and less complex. It doesn’t buggy at all, it keeps the average data volumes without problems (in our case from 1TB and small and large files), including it acts not only as a data storage for us, but almost every minute there is a constant updating of data, overwriting a large number of files.
Generally LizardFS or MooseFS (commercial) they are intended even for petabytes of information.
There is one nuance for those who will use it at home. This file system is not designed to write files line by line, that is, if you write a file from php directly to disk by unloading lines from the loop into it, it will try to constantly synchronize each change, and so the file system starts to slow down wildly for obvious reasons.
Therefore, to form a line-by-line record, simply mount the tmpfs folder somewhere, generate files into this folder line by line, then from there make the mv of the finished file into the cluster file system, or create an array of data in the RAM directly in the interceptor and merge it into the file at once. That is, it works well with atomic operations, copying a file, moving a file, reading a file, but most importantly a complete file, and then there will be no problems. Only with the help of for and any cycles it is not necessary to write files line by line into it.
Its ability to set the number of replicas in folders is fine.
I’ll add a simple monitoring script to the article, a master and shadow master servers, which can be installed in cron:
The scripts telegram.sh and msms.sh are already your scripts.
Initial article:
The advantages of LizardFS:
Very fast work in reading small files. Many who have used GlusterFS have encountered the problem of overly slow work if a clustered file system is used for the return of these sites.
The speed of reading large files is very good.
The speed of writing large files is not much different from the native file systems, especially if the bottom is SSD drives and between servers in a 1-10 Gbit cluster connection.
Operations chown / ls -la - slower than in the case of a native FS, but not so slow
as in the case of GlusterFS.
Recursive delete operations are very fast.
Very flexible connection options in the mfsmount utility.
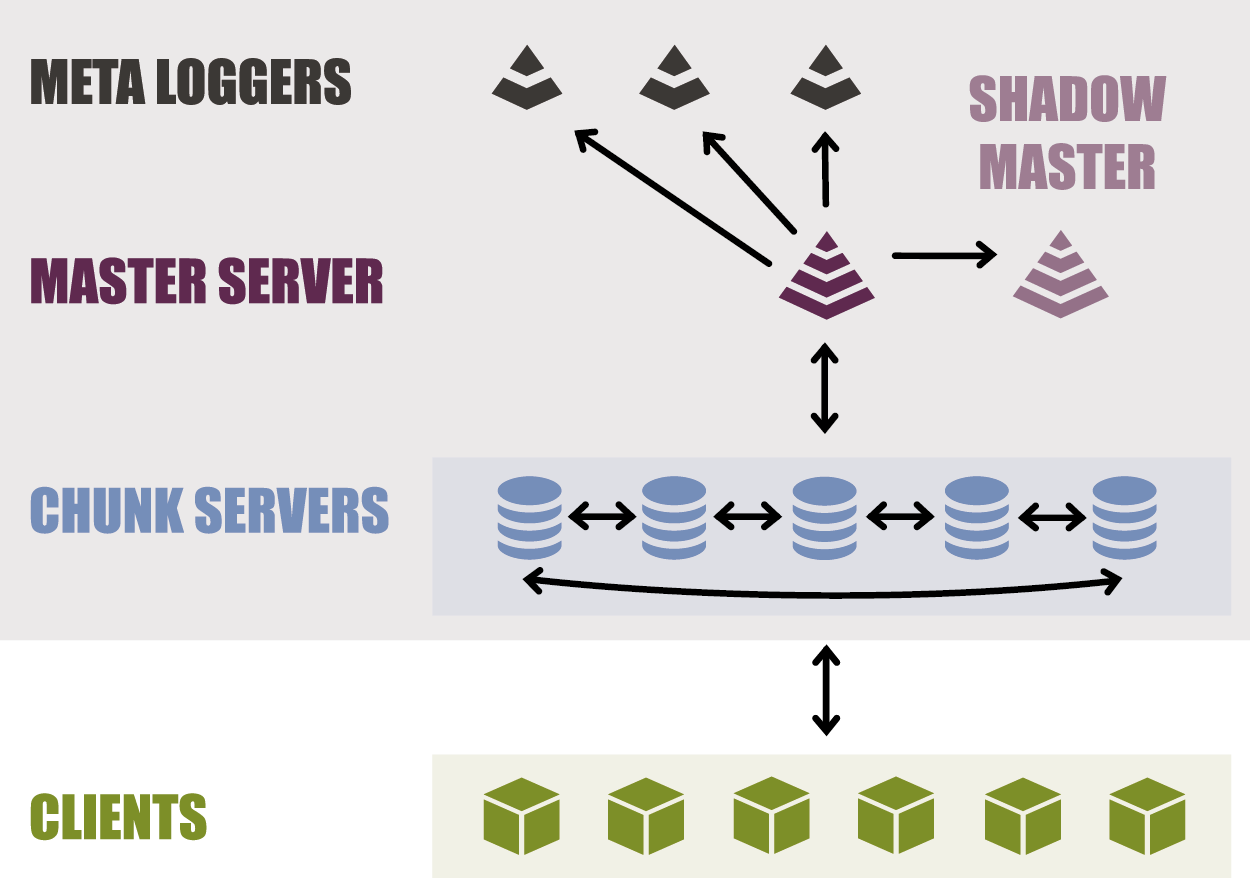
Duplication of metadata is easy and simple to set up; you can simultaneously have several safety shadow master servers and metalogger servers.
Meta data is stored in RAM.
It's great that LizardFS may prefer to take data from a local server. Using the example of 2 replicas to speed up reading, the LizardFS client will automatically take files from the local server, rather than pull over the network from the 2nd server.
The ability to install any goals on the subfolders (number of replicas), that is, you can specify LizardFS / var / lizardfs / important to make 3 replicas, and / var / lizardfs / not_important without any replicas and everything within one file system. It all depends on the number of chunk servers and the performance of the required tasks; you can even use several separate disks for each chunk server.
It supports various modes of data replication, including EC - Erasure Coding.
The read speed in this mode is not much less.
Everything works in LXC containers, except when the client mounts the file system itself. It is solved by mounting on the host machine and forwarding the mount point to the LXC container.
You can practice.
Automatic rebalance when adding new nodes.
Pretty simple removal of dropped or unnecessary nodes.
The disadvantages of LizardFS:
The recording speed of a large stream of small files is very low. Rsync shows it well.
In the case of the engines of sites that generate a large number of cache files on the file system,
The cache must be moved out of the cluster file system. For engines in which this is a problem, you can mount local folders in its subfolders over the mounted LizardFS, or use symbolic links.
Example:
The working master server meta data can work only 1 at a time, but at the same time a doubler or even a few in shadow mode can work. High Availability can be realized both with the help of the paid component LizardFS, and with the help of its own scripts + uCarp / keepalived / PaceMaker and similar software. In our case, we do not need this, rather manual control.
Unfortunately everything is automatically, as in GlusterFS out of the box, this is not there. The pros and flexibility outweigh the cons.
A little demanding of RAM. But for example on small projects where data is about 10-20GB and only 2 replicas are not critical:
On an average project I’ll check the RAM consumption later, haven’t implemented it yet, but we’re already preparing.
Setup:
I will provide a brief manual on how to quickly run LizardFS on Debian 9.
Suppose we have 4 servers with Debian 9 installed, the 8th by default does not contain any ready-made lizardfs packages.
Set limits:
In /etc/security/limits.conf you need to put down:
You can also register separately for root, mfs / lizardfs users. For whom, then, the limits have already been raised, this is not required. At a minimum, you need 10,000.
Distribute roles:
172.24.1.1 (master metadata / chunk) - master metadata / chunk repository
172.24.1.2 (shadow metadata / chunk) - shadow master metadata / chunk repository
172.24.1.3 (metalogger / chunk) - backup metadata / chunk storage
172.24.1.4 (metalogger / chunk) - backup metadata / chunk storage
Strictly speaking, a metalogger can work both on master and shadow in parallel, the more resources are cheap there. This is actually a delayed backup of meta data, exactly the same as on the master / shadow servers. And any metalogger, in case if the main servers have broken the meta data can be turned into a master server.
That is, for example, this option is used by me too:
172.24.1.1 (master metadata / metalogger / chunk)
172.24.1.2 (shadow metadata / metalogger / chunk)
We continue further in the article in the version of 4 servers.
Items 1-3 are performed on all 4 servers.
1. Install on all servers a full set of all services except the client if you have LXC containers. We put all the services, because they are still disabled in Debian at startup in / etc / default / ... And if you suddenly have to turn the metalogger into a master, everything will already be installed in advance.
Or, since the option above is given in Debian in native packages, if you install from source or build your packages, the directory will be different:
Including the names of the utilities, depending on the packages, can also change - mfs * / lizardfs <action> and so on.
In some cases, if you do not install the master package of the server, but only put metalogger and chunkserver, then by default the rights of the user and the group mfs / lizardfs on the folder / var / lib / mfs or / var / lib / lizardfs are not set.
2. Add to / etc / hosts the default entry for LizardFS.
3. Choose a folder or a separate section for data storage, or even 2 sections or more. Consider just 1 folder in the current filesystem on each server: / data / lizardfs-chunk
Or
Sharing the root - meaning the entire space of the LizardFS itself, and not the root of the native FS system.
Sharing points - meaning that it was possible to connect the file system with meta-data. This will be required to clean up the deleted files. Reviewed below.
4. Specify who will be the master, and who is the shadow
On 172.24.1.1 we specify PERSONALITY = master in the config mfsmaster.cfg
At 172.24.1.2 we indicate PERSONALITY = shadow in the config mfsmaster.cfg
5. We include the necessary services:
Next, we mount the client, there are different options, there are a lot of options:
FS on chunkserver `s:
If you have a native XFS file system, add -o mfssugidclearmode = XFS
If you have collected on BSD, you must add -o mfssugidclearmode = BSD
If you have collected on MAC OSX :), you need to add -o mfssugidclearmode = OSX
It is clear that it is not recommended to mix different FS under chunkserver `s within the cluster, and if you want, you need to use -o mfssugidclearmode = ALWAYS
The default is EXT for btrfs, ext2, ext3, ext4, hfs [+], jfs, ntfs and reiserfs.
I don’t think that someone would use ntfs under Linux for chunkserver.
The supported options depend on the version of LizardFS, in the second version the reading speed is much higher. mfsmount by default takes the IP master from / etc / hosts, but connects to all chunk servers in parallel. The big_writes option is considered obsolete in new FUSE clients and is turned on by default, preferably for older systems.
Available replica options are written in mfsgoals.cfg
Then we indicate how many replicas of the data we need:
Well, then we start using in / var / www
Supplement about cleaning the basket LizardFS. Deleted files can be restored by default, but they also take up space.
We do it on any machine, you can do it at all.
The time the files stay in the default basket is 24 hours after deletion:
You can change it for immediate deletion as follows:
Final deletion of files:
Recover all deleted files:
By default, after deleting files from the recycle bin, real files are deleted from chunk servers rather slowly. How to speed it up is not very clear.
Accordingly, it is possible to do basket management on the subdirectory separately, which gives good flexibility. For example, for cache directories, you can put 0, for other directories from accidental deletion, you can put more than 24 hours.
Once again, I emphasize the flexibility in replicating specific directories or files with an example:
That is, you can specify on the directories directly how many replicas of directories and their subdirectories
do. Rebalancing is done automatically. The type of replicas available for the mfssetgoal utility is indicated in mfsgoals.cfg
For those who need parallel recording more than, for example, 1 gigabyte per second, we simply do not need this, but this file system can even google it, then we need to configure the goal to use erasure coding in mfsgoals.cfg and assign this type of replication using mfssetgoal to the desired folder. In this mode, the client writes data in parallel, provided that the client has a network of 10 gigabits at a minimum. At servers it is supposed that too not less.
→ More about replication modes
Important: do not do killall -9 mfsmaster without the need.
By doing so, you can at least lose some of the data that is still in RAM and, as a maximum, beat the metadata file and have to either repair it with the mfsfilerepair utility or even replace it with the old one, the data will naturally be lost. Partly depends on the wizard settings.
I did not write this down to the minuses, since the cluster file system should be done not on the servers from the dump site. Moreover, it is desirable that the servers had an emergency power supply.
For large systems, it may be important to enable configuration:
For quick work in the mode of connecting several clients in parallel and parallel writing and reading, do not forget about the following default parameters:
And about the options in mfsmount:
In general, it took me one full day to deal with this clustered FS. Yes, it is a bit more complicated than GlusterFS, but the pluses outweigh. Quickly reading a bunch of small files is great.
→ Documentation
UPD:
')
After some time, we implemented LizardFS already on an average project, in fact, almost immediately after the publication of this article, we just had to look under the loads before writing the update article.
After 3 months and even there was a reboot of the master server, for reasons beyond the FS itself, I can say that it is the best cluster FS available and less complex. It doesn’t buggy at all, it keeps the average data volumes without problems (in our case from 1TB and small and large files), including it acts not only as a data storage for us, but almost every minute there is a constant updating of data, overwriting a large number of files.
Generally LizardFS or MooseFS (commercial) they are intended even for petabytes of information.
There is one nuance for those who will use it at home. This file system is not designed to write files line by line, that is, if you write a file from php directly to disk by unloading lines from the loop into it, it will try to constantly synchronize each change, and so the file system starts to slow down wildly for obvious reasons.
Therefore, to form a line-by-line record, simply mount the tmpfs folder somewhere, generate files into this folder line by line, then from there make the mv of the finished file into the cluster file system, or create an array of data in the RAM directly in the interceptor and merge it into the file at once. That is, it works well with atomic operations, copying a file, moving a file, reading a file, but most importantly a complete file, and then there will be no problems. Only with the help of for and any cycles it is not necessary to write files line by line into it.
Its ability to set the number of replicas in folders is fine.
I’ll add a simple monitoring script to the article, a master and shadow master servers, which can be installed in cron:
#!/bin/bash #Variables SRV="172.24.1.1" #Every 15 minutes repeat alert if have troubles test -f /tmp/$SRV.lizardfs && find /tmp/$SRV.lizardfs -mmin +15 -delete #Check if no have previous alert flag file if [ ! -e /tmp/$SRV.lizardfs ]; then #Check command CHECK_LIZ=`lizardfs-probe metadataserver-status $SRV 9421 | grep "running\|connected" | awk '{print $3}' | sed '/^$/d' | tr -d ' '` #Send Alert if have troubles if [[ "$CHECK_LIZ" != "running" && "$CHECK_LIZ" != "connected" ]] ; then echo "$CHECK_LIZ" > /tmp/$SRV.lizardfs #Send Alert /home/scripts/telegram/telegram.sh --service "$SRV LizardFS" --event "Status: $CHECK_LIZ" ; /home/scripts/sms/msms.sh --service "$SRV LizardFS" --event "Status: $CHECK_LIZ" ; fi fi The scripts telegram.sh and msms.sh are already your scripts.
Initial article:
The advantages of LizardFS:
Very fast work in reading small files. Many who have used GlusterFS have encountered the problem of overly slow work if a clustered file system is used for the return of these sites.
The speed of reading large files is very good.
The speed of writing large files is not much different from the native file systems, especially if the bottom is SSD drives and between servers in a 1-10 Gbit cluster connection.
Operations chown / ls -la - slower than in the case of a native FS, but not so slow
as in the case of GlusterFS.
Recursive delete operations are very fast.
Very flexible connection options in the mfsmount utility.
Duplication of metadata is easy and simple to set up; you can simultaneously have several safety shadow master servers and metalogger servers.
Meta data is stored in RAM.
It's great that LizardFS may prefer to take data from a local server. Using the example of 2 replicas to speed up reading, the LizardFS client will automatically take files from the local server, rather than pull over the network from the 2nd server.
The ability to install any goals on the subfolders (number of replicas), that is, you can specify LizardFS / var / lizardfs / important to make 3 replicas, and / var / lizardfs / not_important without any replicas and everything within one file system. It all depends on the number of chunk servers and the performance of the required tasks; you can even use several separate disks for each chunk server.
It supports various modes of data replication, including EC - Erasure Coding.
The read speed in this mode is not much less.
Everything works in LXC containers, except when the client mounts the file system itself. It is solved by mounting on the host machine and forwarding the mount point to the LXC container.
You can practice.
Automatic rebalance when adding new nodes.
Pretty simple removal of dropped or unnecessary nodes.
The disadvantages of LizardFS:
The recording speed of a large stream of small files is very low. Rsync shows it well.
In the case of the engines of sites that generate a large number of cache files on the file system,
The cache must be moved out of the cluster file system. For engines in which this is a problem, you can mount local folders in its subfolders over the mounted LizardFS, or use symbolic links.
Example:
mount --bind /data/nativefs/cache /var/lizardfs/cache The working master server meta data can work only 1 at a time, but at the same time a doubler or even a few in shadow mode can work. High Availability can be realized both with the help of the paid component LizardFS, and with the help of its own scripts + uCarp / keepalived / PaceMaker and similar software. In our case, we do not need this, rather manual control.
Unfortunately everything is automatically, as in GlusterFS out of the box, this is not there. The pros and flexibility outweigh the cons.
A little demanding of RAM. But for example on small projects where data is about 10-20GB and only 2 replicas are not critical:
root@172.24.1.1:/# df -h |grep "mfs\|Size" Filesystem Size Used Avail Use% Mounted on mfs#mfsmaster:9421 1.8T 41G 1.8T 3% /var/www ( 2- ) root@172.24.1.1:/# find /var/www -type f -print0 | wc -l --files0-from=- |grep total 185818 total ( ) root@172.24.1.1:/# smem -u -t -k |grep "mfs\|RSS" User Count Swap USS PSS RSS mfs 3 0 170.0M 170.9M 180.9M (3 - master/metalogger/chunkserver) On an average project I’ll check the RAM consumption later, haven’t implemented it yet, but we’re already preparing.
Setup:
I will provide a brief manual on how to quickly run LizardFS on Debian 9.
Suppose we have 4 servers with Debian 9 installed, the 8th by default does not contain any ready-made lizardfs packages.
Set limits:
In /etc/security/limits.conf you need to put down:
* hard nofile 20000 * soft nofile 20000 You can also register separately for root, mfs / lizardfs users. For whom, then, the limits have already been raised, this is not required. At a minimum, you need 10,000.
Distribute roles:
172.24.1.1 (master metadata / chunk) - master metadata / chunk repository
172.24.1.2 (shadow metadata / chunk) - shadow master metadata / chunk repository
172.24.1.3 (metalogger / chunk) - backup metadata / chunk storage
172.24.1.4 (metalogger / chunk) - backup metadata / chunk storage
Strictly speaking, a metalogger can work both on master and shadow in parallel, the more resources are cheap there. This is actually a delayed backup of meta data, exactly the same as on the master / shadow servers. And any metalogger, in case if the main servers have broken the meta data can be turned into a master server.
That is, for example, this option is used by me too:
172.24.1.1 (master metadata / metalogger / chunk)
172.24.1.2 (shadow metadata / metalogger / chunk)
We continue further in the article in the version of 4 servers.
Items 1-3 are performed on all 4 servers.
1. Install on all servers a full set of all services except the client if you have LXC containers. We put all the services, because they are still disabled in Debian at startup in / etc / default / ... And if you suddenly have to turn the metalogger into a master, everything will already be installed in advance.
apt-get -y install lizardfs-common lizardfs-master lizardfs-chunkserver lizardfs-metalogger lizardfs-client cp /etc/lizardfs/mfsmaster.cfg.dist /etc/lizardfs/mfsmaster.cfg cp /etc/lizardfs/mfsmetalogger.cfg.dist /etc/lizardfs/mfsmetalogger.cfg cp /etc/lizardfs/mfsgoals.cfg.dist /etc/lizardfs/mfsgoals.cfg cp /etc/lizardfs/mfschunkserver.cfg.dist /etc/lizardfs/mfschunkserver.cfg cp /etc/lizardfs/mfshdd.cfg.dist /etc/lizardfs/mfshdd.cfg Or, since the option above is given in Debian in native packages, if you install from source or build your packages, the directory will be different:
cp /etc/mfs/mfsmaster.cfg.dist /etc/mfs/mfsmaster.cfg cp /etc/mfs/mfsmetalogger.cfg.dist /etc/mfs/mfsmetalogger.cfg cp /etc/mfs/mfsgoals.cfg.dist /etc/mfs/mfsgoals.cfg cp /etc/mfs/mfschunkserver.cfg.dist /etc/mfs/mfschunkserver.cfg cp /etc/mfs/mfshdd.cfg.dist /etc/mfs/mfshdd.cfg Including the names of the utilities, depending on the packages, can also change - mfs * / lizardfs <action> and so on.
In some cases, if you do not install the master package of the server, but only put metalogger and chunkserver, then by default the rights of the user and the group mfs / lizardfs on the folder / var / lib / mfs or / var / lib / lizardfs are not set.
2. Add to / etc / hosts the default entry for LizardFS.
echo "172.24.1.1 mfsmaster" >> /etc/hosts 3. Choose a folder or a separate section for data storage, or even 2 sections or more. Consider just 1 folder in the current filesystem on each server: / data / lizardfs-chunk
mkdir -p /var/www ( ) mkdir -p /data/lizardfs-chunk ( LizardFS ) echo "/data/lizardfs-chunk" > /etc/lizardfs/mfshdd.cfg echo "172.24.1.0/24 / rw,alldirs,maproot=0" > /etc/lizardfs/mfsexports.cfg Or
echo "/data/lizardfs-chunk" > /etc/mfs/mfshdd.cfg echo "172.24.1.0/24 . rw,alldirs,maproot=0" > /etc/mfs/mfsexports.cfg echo "172.24.1.0/24 / rw,alldirs,maproot=0" > /etc/mfs/mfsexports.cfg Sharing the root - meaning the entire space of the LizardFS itself, and not the root of the native FS system.
Sharing points - meaning that it was possible to connect the file system with meta-data. This will be required to clean up the deleted files. Reviewed below.
4. Specify who will be the master, and who is the shadow
On 172.24.1.1 we specify PERSONALITY = master in the config mfsmaster.cfg
At 172.24.1.2 we indicate PERSONALITY = shadow in the config mfsmaster.cfg
5. We include the necessary services:
172.24.1.1: echo "LIZARDFSMASTER_ENABLE=true" > /etc/default/lizardfs-master echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver systemctl start lizardfs-master systemctl start lizardfs-chunkserver 172.24.1.2: echo "LIZARDFSMASTER_ENABLE=true" > /etc/default/lizardfs-master echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver systemctl start lizardfs-master systemctl start lizardfs-chunkserver 172.24.1.3: echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver echo "LIZARDFSMETALOGGER_ENABLE=true" > /etc/default/lizardfs-metalogger systemctl start lizardfs-metalogger systemctl start lizardfs-chunkserver 172.24.1.4: echo "LIZARDFSCHUNKSERVER_ENABLE=true" > /etc/default/lizardfs-chunkserver echo "LIZARDFSMETALOGGER_ENABLE=true" > /etc/default/lizardfs-metalogger systemctl start lizardfs-metalogger systemctl start lizardfs-chunkserver Next, we mount the client, there are different options, there are a lot of options:
FS on chunkserver `s:
If you have a native XFS file system, add -o mfssugidclearmode = XFS
If you have collected on BSD, you must add -o mfssugidclearmode = BSD
If you have collected on MAC OSX :), you need to add -o mfssugidclearmode = OSX
It is clear that it is not recommended to mix different FS under chunkserver `s within the cluster, and if you want, you need to use -o mfssugidclearmode = ALWAYS
The default is EXT for btrfs, ext2, ext3, ext4, hfs [+], jfs, ntfs and reiserfs.
I don’t think that someone would use ntfs under Linux for chunkserver.
mfsmount -o big_writes,nosuid,nodev,noatime,allow_other /var/www mfsmount -o big_writes,nosuid,nodev,noatime,allow_other -o cacheexpirationtime=500 -o readaheadmaxwindowsize=4096 /var/www The supported options depend on the version of LizardFS, in the second version the reading speed is much higher. mfsmount by default takes the IP master from / etc / hosts, but connects to all chunk servers in parallel. The big_writes option is considered obsolete in new FUSE clients and is turned on by default, preferably for older systems.
Available replica options are written in mfsgoals.cfg
Then we indicate how many replicas of the data we need:
mfssetgoal -r 2 /var/www mfsgetgoal /var/www Well, then we start using in / var / www
Supplement about cleaning the basket LizardFS. Deleted files can be restored by default, but they also take up space.
We do it on any machine, you can do it at all.
mkdir /mnt/lizardfs-meta mfsmount /mnt/lizardfs-meta -o mfsmeta cd /mnt/lizardfs-meta/trash root@172.24.1.1:/mnt/lizardfs-meta/trash# root@172.24.1.1:/mnt/lizardfs-meta/trash# ls -la total 0 drwx------ 3 root root 0 Dec 2 09:36 . dr-xr-xr-x 4 root root 0 Dec 2 09:36 .. -rw-r--r-- 0 root root 0 Dec 2 09:38 00016C88|test.txt dw------- 2 root root 0 Dec 2 09:36 undel The time the files stay in the default basket is 24 hours after deletion:
root@172.24.1.1:/mnt/lizardfs-meta/trash# lizardfs rgettrashtime /var/www/ /var/www/: files with trashtime 86400 : 44220 directories with trashtime 86400 : 2266 You can change it for immediate deletion as follows:
root@172.24.1.1:/mnt/lizardfs-meta/trash# lizardfs rsettrashtime 0 /var/www/ /var/www/: inodes with trashtime changed: 46486 inodes with trashtime not changed: 0 inodes with permission denied: 0 Final deletion of files:
root@172.24.1.1:/mnt/lizardfs-meta/trash# find /mnt/lizardfs-meta/trash/ -type f -delete Recover all deleted files:
root@172.24.1.1:/mnt/lizardfs-meta/trash# find /mnt/lizardfs-meta/trash/ -type f -exec mv {} /mnt/lizardfs-meta/trash/undel/ \; By default, after deleting files from the recycle bin, real files are deleted from chunk servers rather slowly. How to speed it up is not very clear.
Accordingly, it is possible to do basket management on the subdirectory separately, which gives good flexibility. For example, for cache directories, you can put 0, for other directories from accidental deletion, you can put more than 24 hours.
Once again, I emphasize the flexibility in replicating specific directories or files with an example:
root@172.24.1.1:/# mfssetgoal -r 1 /var/www/test/ /var/www/test/: inodes with goal changed: 1 inodes with goal not changed: 0 inodes with permission denied: 0 root@172.24.1.1:/# mfsgetgoal /var/www /var/www: 2 root@172.24.1.1:/# mfsgetgoal /var/www/test /var/www/test: 1 That is, you can specify on the directories directly how many replicas of directories and their subdirectories
do. Rebalancing is done automatically. The type of replicas available for the mfssetgoal utility is indicated in mfsgoals.cfg
For those who need parallel recording more than, for example, 1 gigabyte per second, we simply do not need this, but this file system can even google it, then we need to configure the goal to use erasure coding in mfsgoals.cfg and assign this type of replication using mfssetgoal to the desired folder. In this mode, the client writes data in parallel, provided that the client has a network of 10 gigabits at a minimum. At servers it is supposed that too not less.
→ More about replication modes
Important: do not do killall -9 mfsmaster without the need.
By doing so, you can at least lose some of the data that is still in RAM and, as a maximum, beat the metadata file and have to either repair it with the mfsfilerepair utility or even replace it with the old one, the data will naturally be lost. Partly depends on the wizard settings.
I did not write this down to the minuses, since the cluster file system should be done not on the servers from the dump site. Moreover, it is desirable that the servers had an emergency power supply.
For large systems, it may be important to enable configuration:
root@172.24.1.1:/# cat /etc/mfs/mfschunkserver.cfg |grep -B3 FACTOR ## If enabled, chunkserver will send periodical reports of its I/O load to master, ## which will be taken into consideration when picking chunkservers for I/O operations. ## (Default : 0) # ENABLE_LOAD_FACTOR = 0 For quick work in the mode of connecting several clients in parallel and parallel writing and reading, do not forget about the following default parameters:
root@172.24.1.1:/# cat /etc/mfs/mfschunkserver.cfg |grep WORKERS # NR_OF_NETWORK_WORKERS = 1 # NR_OF_HDD_WORKERS_PER_NETWORK_WORKER = 2 # NR_OF_NETWORK_WORKERS = 1 # NR_OF_HDD_WORKERS_PER_NETWORK_WORKER = 20 And about the options in mfsmount:
-o mfswritecachesize=<N> specify write cache size in MiB (in range: 16..2048 - default: 128) -o mfswriteworkers='N' define number of write workers (default: 10) -o mfswritewindowsize='N' define write window size (in blocks) for each chunk (default: 15) In general, it took me one full day to deal with this clustered FS. Yes, it is a bit more complicated than GlusterFS, but the pluses outweigh. Quickly reading a bunch of small files is great.
→ Documentation
Source: https://habr.com/ru/post/343326/
All Articles