Regular expressions for the smallest
Hi, Habr.
My name is Vitaly Kotov and I know a little about regular expressions. Under the cut, I'll tell you the basics of working with them. Many theoretical articles have been written on this topic. In this article, I decided to focus on the number of examples. It seems to me that this is the best way to show the capabilities of this tool.
Some of them, for clarity, will be shown on the example of the programming languages PHP or JavaScript, but in general they work independently of PL.
')
From the title it is clear that the article is focused on the very initial level - those who have never used regular expressions in their programs or did it without proper understanding.
At the end of the article, I will briefly tell you which tasks cannot be solved by regular expressions and which tools should be used for this.
Go!

Regular expressions - the search language substring or substrings in the text. A pattern (pattern, mask) consisting of characters and metacharacters (characters that mean not themselves, but a set of characters) is used for the search.
This is quite a powerful tool that can be useful in many cases - search, check for correct string, etc. The spectrum of its capabilities is difficult to fit into one article.
In PHP, working with regular expressions consists of a set of functions, of which I most often use the following:
To work with them, you need a text in which we will search for or replace the substrings, as well as the regular expression that describes the search rule.
Match functions return the number of substrings found or false in case of errors. The replace function returns a modified string / array or null if an error occurs. The result can be brought to bool (false if no values were found and true if it was) and used together with if or assertTrue to handle the result of the work.
In JS, I most often have to use:
All further examples I suggest to look at https://regex101.com/ . This is a convenient and intuitive interface for working with regular expressions.
In PHP, a regular expression is a string that begins and ends with a delimiter character. Everything between delimiters is a regular expression.
Often used separators are slashes “/”, pound signs “#” and tildes “~”. The following are examples of templates with valid delimiters:
If you need to use a separator inside the template, you need to screen it with a backslash. If a separator is often used in a template, for readability purposes, it is better to choose another separator for this template.
In JavaScript, regular expressions are implemented by a separate RegExp object and integrated into string methods.
You can create a regular expression like this:
Or a shorter version:
An example of the simplest regular expression to find:
In this example, we are simply looking for all the characters “o”.
In PHP, the difference between preg_match and preg_match_all is that the first function will only find the first match and end the search, while the second function will return all entries.
Sample PHP code:
We try the same for the second function:
In the latter case, the function returned all entries that are in our text.
The same javascript example:
For regular expressions, there is a set of modifiers that change the search operation. They are denoted by a single letter of the Latin alphabet and are put at the end of a regular expression, after the closing “/”.
About the other modifiers used in PHP, you can read here .
In javascript - here .
You can read about modifiers in general here .
An example of a previous regular expression with a JavaScript modifier:
At first, the examples will be rather primitive, because we are familiar with the basics. The more we learn, the closer to reality there will be examples.
Most often, we do not know in advance what text we will have to parse. Only an approximate set of rules is known in advance. Be it a pincode in SMS, email in a letter, etc.
First example, we need to get all the numbers from the text:
To select any number, you need to collect all the numbers by specifying “[0123456789]”. In short, you can set it like this: “[0-9]”. For all digits there is a metacharacter “\ d”. It works identically.
But if we specify the regular expression “/ \ d /”, then only the first digit will return to us. Of course, we can use the “g” modifier, but in this case, each digit will return as a separate element of the array, since it will be considered a new entry.
In order to display a substring as a single occurrence, there are symbols plus “+” and an asterisk “*”. The first one indicates that a substring is suitable for us, where there is at least one suitable character for the set. The second is that this set of characters may or may not be, and this is normal. In addition, we can specify the exact value of the appropriate characters like this: “{N}”, where N is the desired number. Or set “from” and “to” by pointing like this: “{N, M}”.
Now there will be a couple of examples for it to fit in the head:
In a similar way, we work with letters, without forgetting that they have a register. This is how letters can be set:
With Cyrillic, the specified range works differently for different encodings. In Unicode, for example, the letter “e” is not included in this range. More on this here .
A couple of examples:
Such an expression will select all the words that are in the sentence and written in Cyrillic. We need the third word.
In addition to letters and numbers, we may also have important symbols, such as:
The previous example has become simpler:
If we know for sure that the search word is the last one, we put $ and the result will be only that character set, after which the end of the line follows.
The same with the beginning of the line:
Before getting acquainted with the meta characters further, you need to discuss the “^” symbol separately, because it goes to two works at once (this is to make it more interesting). In some cases, it denotes the beginning of a line, but in some - negation.
This is necessary for those cases where it is easier to specify characters that do not suit us than those that suit us.
Suppose we have collected a set of characters that suit us: “[a-z0-9]” (we are satisfied with any small Latin letter or digit). Now suppose that we are satisfied with any character except this one. This will be indicated like this: “[^ a-z0-9]”.
Example:
We select all "not spaces".
So, here is a list of basic metacharacters:
As described above, it was possible to guess that [] is used to group several characters together. So we say that we are satisfied with any character from the set.
Example:
Here we gathered in the group (between the characters []) all Latin letters and a space. With the help of {} indicated that we are interested in occurrences, where at least 2 characters, to exclude occurrences from empty spaces.
Similarly, we could get all the Russian words by inverting: “[^ A-Za-z \ s] {2,}”.
Unlike [], characters () collect marked expressions. They are sometimes called “capture”.
They are needed in order to transfer the selected piece (which may consist of several occurrences of [] in the output result).
Example:
There are many solutions. The example below is an approximate version that simply shows the possibilities of regular expressions. Actually there is an RFC that determines the correctness of an email. And there are "regulars" for RFC - here are examples .
We choose everything that is not a space (because the first part of the email can contain any character set), then there should be an @ symbol, then anything except a dot and a space, then a dot, then any Latin character in lower case ...
So, let's go:
It turned out not so difficult. Now we have email assembled in parts. Consider the example of the result of the work in PHP preg_match:
Happened! But what if now we need to separately get the domain and name by email? And somehow use further in the code? This is where the “capture” will help us. We simply choose what we need and wrap them with signs (), as in the example:
It was:
It became:
We try:
In the match array, the zero element is always a full occurrence of a regular expression. And then take turns “captures”.
In PHP, you can call it “captures” using the following syntax:
Then the array of the match will become associative:
This immediately +100 to readability and code, and regular.
There is a letter with HTML-code, you need to pull out of it a new password. The text can be either in English or in Russian:
First, we say that the text before the password can be of two options, using the “or”.
You can list as many options as you like:
Next we have a colon and one space:
Next sign b tag:
And then we are interested in everything that is not a “<” symbol, since it will indicate that the b tag is closed:
We wrap it in a grip, because we need him.
Next, we write the closing tag b, escaping the “/” symbol, as this is a special character:
It's pretty simple.
In PHP, there is a cool function that helps to work with the URL, breaking it down into its component parts:
Let's do the same, just regular? :)
Any url begins with the scheme. For us, this is the http / https protocol. One could make a logical “or”:
But you can cheat and do this:
In this case, the symbol “?” Means that “s” can eat, maybe not ...
Next we have “: //”, but we have to escape the “/” symbol (see above):
Next we have the domain before the “/” sign or the end of the line. It may consist of numbers, letters, underscores, dashes and periods:
Here we have put together the metacharacter “\ w”, the dot ”\.” And the dash ”-”.
Next comes the URI. Everything is simple, we take everything up to the question mark or the end of the line:
Now a question mark, which may or may not be:
Then everything is up to the end of the line or the beginning of the anchor (the # character) —do not forget that this part may also not be:
Further, it may be #, or it may not be:
Then everything is up to the end of the line, if there is:
All the beauty in the end looks like this (unfortunately, I didn’t figure out how to insert this part so that Habr would not consider part of the line as a comment):
The main thing is not to blink! :)
It turned out about the same thing, only with their own hands.
At first glance, it seems that regular text can describe and parse any text. But, unfortunately, it is not.
Regular expressions are a subspecies of formal languages, which in Chomsky’s hierarchy belong to the 3rd type, the simplest. About this here .
With the help of this language, we cannot, for example, parse the syntax of programming languages with a nested grammar. Or HTML code.
We have a span, within which there are many other span and we do not know how much. You have to choose everything inside this span:
Of course, if we parse HTML, where there is not only this span. :)
The bottom line is that we cannot start at some point “counting” the symbols span and / span, meaning that there should be an equal number of opening and closing symbols. And to “understand” that the closing symbol, for which there was previously no pair, is the same closing symbol, which separates the block.
Same with the code and {} characters.
For example:
In such a structure, we cannot, using only a regular expression, distinguish the closing brace inside the code from the one that completes the initial function (if the code consists not only of this function).
To solve such problems using higher level languages.
I tried to tell in some detail about the basics of the world of regular expressions. Of course it is impossible to fit everything into one article. Further work with them is a matter of experience and ability to google.
Thanks for attention.
My name is Vitaly Kotov and I know a little about regular expressions. Under the cut, I'll tell you the basics of working with them. Many theoretical articles have been written on this topic. In this article, I decided to focus on the number of examples. It seems to me that this is the best way to show the capabilities of this tool.
Some of them, for clarity, will be shown on the example of the programming languages PHP or JavaScript, but in general they work independently of PL.
')
From the title it is clear that the article is focused on the very initial level - those who have never used regular expressions in their programs or did it without proper understanding.
At the end of the article, I will briefly tell you which tasks cannot be solved by regular expressions and which tools should be used for this.
Go!
Introduction
Regular expressions - the search language substring or substrings in the text. A pattern (pattern, mask) consisting of characters and metacharacters (characters that mean not themselves, but a set of characters) is used for the search.
This is quite a powerful tool that can be useful in many cases - search, check for correct string, etc. The spectrum of its capabilities is difficult to fit into one article.
In PHP, working with regular expressions consists of a set of functions, of which I most often use the following:
- preg_match ( http://php.net/manual/en/function.preg-match.php )
- preg_match_all ( http://php.net/manual/en/function.preg-match-all.php )
- preg_replace ( http://php.net/manual/en/function.preg-replace.php )
To work with them, you need a text in which we will search for or replace the substrings, as well as the regular expression that describes the search rule.
Match functions return the number of substrings found or false in case of errors. The replace function returns a modified string / array or null if an error occurs. The result can be brought to bool (false if no values were found and true if it was) and used together with if or assertTrue to handle the result of the work.
In JS, I most often have to use:
- match ( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match )
- test ( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/test )
- replace ( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/replace )
All further examples I suggest to look at https://regex101.com/ . This is a convenient and intuitive interface for working with regular expressions.
An example of using functions
In PHP, a regular expression is a string that begins and ends with a delimiter character. Everything between delimiters is a regular expression.
Often used separators are slashes “/”, pound signs “#” and tildes “~”. The following are examples of templates with valid delimiters:
- / foo bar /
- # ^ [^ 0-9] $ #
- % [a-zA-Z0-9 _-]%
If you need to use a separator inside the template, you need to screen it with a backslash. If a separator is often used in a template, for readability purposes, it is better to choose another separator for this template.
- / http: \ / \ //
- #http: // #
In JavaScript, regular expressions are implemented by a separate RegExp object and integrated into string methods.
You can create a regular expression like this:
let regexp = new RegExp("", ""); Or a shorter version:
let regexp = //; // let regexp = //gmi; // gmi ( ) An example of the simplest regular expression to find:
RegExp: /o/ Text: hello world In this example, we are simply looking for all the characters “o”.
In PHP, the difference between preg_match and preg_match_all is that the first function will only find the first match and end the search, while the second function will return all entries.
Sample PHP code:
<?php $text = 'hello world'; $regexp = '/o/'; $result = preg_match($regexp, $text, $match); var_dump( $result, $match ); int(1) // , .. array(1) { [0]=> string(1) "o" // , , } We try the same for the second function:
<?php $text = 'hello world'; $regexp = '/o/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match ); int(2) array(1) { [0]=> array(2) { [0]=> string(1) "o" [1]=> string(1) "o" } } In the latter case, the function returned all entries that are in our text.
The same javascript example:
let str = 'Hello world'; let result = str.match(/o/); console.log(result); ["o", index: 4, input: "Hello world"] Template Modifiers
For regular expressions, there is a set of modifiers that change the search operation. They are denoted by a single letter of the Latin alphabet and are put at the end of a regular expression, after the closing “/”.
- i - the characters in the pattern correspond to the characters of both upper and lower case.
- m - by default, the text is processed as a single-line character string. The metacharacter of the beginning of the string '^' matches only the beginning of the text being processed, while the metacharacter of the end of the string '$' corresponds to the end of the text. If this modifier is used, the metacharacters “beginning of line” and “end of line” also correspond to positions before an arbitrary translation character and line and, respectively, after, as at the very beginning, and at the very end of the line.
About the other modifiers used in PHP, you can read here .
In javascript - here .
You can read about modifiers in general here .
An example of a previous regular expression with a JavaScript modifier:
let str = "hello world \ How is it going?" let result = str.match(/o/g); console.log(result); ["o", "o", "o", "o"] Regex metacharacters
At first, the examples will be rather primitive, because we are familiar with the basics. The more we learn, the closer to reality there will be examples.
Most often, we do not know in advance what text we will have to parse. Only an approximate set of rules is known in advance. Be it a pincode in SMS, email in a letter, etc.
First example, we need to get all the numbers from the text:
: “, 1528. .” To select any number, you need to collect all the numbers by specifying “[0123456789]”. In short, you can set it like this: “[0-9]”. For all digits there is a metacharacter “\ d”. It works identically.
But if we specify the regular expression “/ \ d /”, then only the first digit will return to us. Of course, we can use the “g” modifier, but in this case, each digit will return as a separate element of the array, since it will be considered a new entry.
In order to display a substring as a single occurrence, there are symbols plus “+” and an asterisk “*”. The first one indicates that a substring is suitable for us, where there is at least one suitable character for the set. The second is that this set of characters may or may not be, and this is normal. In addition, we can specify the exact value of the appropriate characters like this: “{N}”, where N is the desired number. Or set “from” and “to” by pointing like this: “{N, M}”.
Now there will be a couple of examples for it to fit in the head:
: “ 2 .” . RegExp: “/\d/” : “ : 24356” “ .” , . RegExp: “/\d*/” : “ 89091534357” 11 , FALSE, . RegExp: “/\d{11}/” In a similar way, we work with letters, without forgetting that they have a register. This is how letters can be set:
- [az]
- [a-zA-Z]
- [aaaa-za]
With Cyrillic, the specified range works differently for different encodings. In Unicode, for example, the letter “e” is not included in this range. More on this here .
A couple of examples:
: “ ” “ ” “”, “”. RegExp: “/[--]+/” Such an expression will select all the words that are in the sentence and written in Cyrillic. We need the third word.
In addition to letters and numbers, we may also have important symbols, such as:
- \ s - space
- ^ - beginning of line
- $ - end of line
- | - "or"
The previous example has become simpler:
: “ ” “ ” “”, “”. RegExp: “/[--]+$/” If we know for sure that the search word is the last one, we put $ and the result will be only that character set, after which the end of the line follows.
The same with the beginning of the line:
: “ ” “ ” “”, “”. RegExp: “/^[--]+/” Before getting acquainted with the meta characters further, you need to discuss the “^” symbol separately, because it goes to two works at once (this is to make it more interesting). In some cases, it denotes the beginning of a line, but in some - negation.
This is necessary for those cases where it is easier to specify characters that do not suit us than those that suit us.
Suppose we have collected a set of characters that suit us: “[a-z0-9]” (we are satisfied with any small Latin letter or digit). Now suppose that we are satisfied with any character except this one. This will be indicated like this: “[^ a-z0-9]”.
Example:
: “ ” . RegExp: “[^\s]+” We select all "not spaces".
So, here is a list of basic metacharacters:
- \ d - matches any digit; equivalent [0-9]
- \ D - matches any non-numeric character; equivalent [^ 0-9]
- \ s - matches any whitespace character; equivalent to [\ t \ n \ r \ f \ v]
- \ S - matches any non-whitespace character; equivalent [^ \ t \ n \ r \ f \ v]
- \ w - matches any letter or number; equivalent of [a-zA-Z0-9_]
- \ W - vice versa; equivalent [^ a-zA-Z0-9_]
- . - (just a dot) any character except the translation of the “carriage”
Operators [] and ()
As described above, it was possible to guess that [] is used to group several characters together. So we say that we are satisfied with any character from the set.
Example:
: “ I dont know, !” . RegExp: “/[A-Za-z\s]{2,}/” Here we gathered in the group (between the characters []) all Latin letters and a space. With the help of {} indicated that we are interested in occurrences, where at least 2 characters, to exclude occurrences from empty spaces.
Similarly, we could get all the Russian words by inverting: “[^ A-Za-z \ s] {2,}”.
Unlike [], characters () collect marked expressions. They are sometimes called “capture”.
They are needed in order to transfer the selected piece (which may consist of several occurrences of [] in the output result).
Example:
: 'Email you sent was ololo@example.com Is it correct?' email. There are many solutions. The example below is an approximate version that simply shows the possibilities of regular expressions. Actually there is an RFC that determines the correctness of an email. And there are "regulars" for RFC - here are examples .
We choose everything that is not a space (because the first part of the email can contain any character set), then there should be an @ symbol, then anything except a dot and a space, then a dot, then any Latin character in lower case ...
So, let's go:
- we select everything that is not a space: “[^ \ s] +”
- we select the @ sign: “@”
- we choose anything except a period and a space: “[^ \ s \.] +”
- we select the point: “\.” (the backslash is needed for the escape of the metacharacter, since the dot character describes any character - see above)
- we select any lowercase Latin character: “[az] +”
It turned out not so difficult. Now we have email assembled in parts. Consider the example of the result of the work in PHP preg_match:
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/[^\s]+@[^\s\.]+\.[az]+/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match ); int(1) array(1) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } } Happened! But what if now we need to separately get the domain and name by email? And somehow use further in the code? This is where the “capture” will help us. We simply choose what we need and wrap them with signs (), as in the example:
It was:
/[^\s]+@[^\s\.]+\.[az]+/ It became:
/([^\s]+)@([^\s\.]+\.[az]+)/ We try:
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/([^\s]+)@([^\s\.]+\.[az]+)/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match ); int(1) array(3) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } [1]=> array(1) { [0]=> string(5) "ololo" } [2]=> array(1) { [0]=> string(7) "example.com" } } In the match array, the zero element is always a full occurrence of a regular expression. And then take turns “captures”.
In PHP, you can call it “captures” using the following syntax:
/(?<mail>[^\s]+)@(?<domain>[^\s\.]+\.[az]+)/ Then the array of the match will become associative:
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/(?<mail>[^\s]+)@(?<domain>[^\s\.]+\.[az]+)/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match ); int(1) array(5) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } ["mail"]=> array(1) { [0]=> string(5) "ololo" } ["domain"]=> array(1) { [0]=> string(7) "example.com" } } This immediately +100 to readability and code, and regular.
Real life examples
Parsim a letter searching for a new password:
There is a letter with HTML-code, you need to pull out of it a new password. The text can be either in English or in Russian:
: “: <b>f23f43tgt4</b>” “password: <b>wh4k38f4</b>” RegExp: “(password|):\s<b>([^<]+)<\/b>” First, we say that the text before the password can be of two options, using the “or”.
You can list as many options as you like:
(password|) Next we have a colon and one space:
:\s Next sign b tag:
<b> And then we are interested in everything that is not a “<” symbol, since it will indicate that the b tag is closed:
([^<]+) We wrap it in a grip, because we need him.
Next, we write the closing tag b, escaping the “/” symbol, as this is a special character:
<\/b> It's pretty simple.
Parsim URL:
In PHP, there is a cool function that helps to work with the URL, breaking it down into its component parts:
<?php $URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor"; $parsed = parse_url($URL); var_dump($parsed); array(5) { ["scheme"]=> string(5) "https" ["host"]=> string(14) "hello.world.ru" ["path"]=> string(16) "/uri/starts/here" ["query"]=> string(15) "get_params=here" ["fragment"]=> string(6) "anchor" } Let's do the same, just regular? :)
Any url begins with the scheme. For us, this is the http / https protocol. One could make a logical “or”:
(http|https) But you can cheat and do this:
http[s]? In this case, the symbol “?” Means that “s” can eat, maybe not ...
Next we have “: //”, but we have to escape the “/” symbol (see above):
“:\/\/” Next we have the domain before the “/” sign or the end of the line. It may consist of numbers, letters, underscores, dashes and periods:
[\w\.-]+ Here we have put together the metacharacter “\ w”, the dot ”\.” And the dash ”-”.
Next comes the URI. Everything is simple, we take everything up to the question mark or the end of the line:
[^?$]+ Now a question mark, which may or may not be:
[?]? Then everything is up to the end of the line or the beginning of the anchor (the # character) —do not forget that this part may also not be:
[^#$]+ Further, it may be #, or it may not be:
[#]? Then everything is up to the end of the line, if there is:
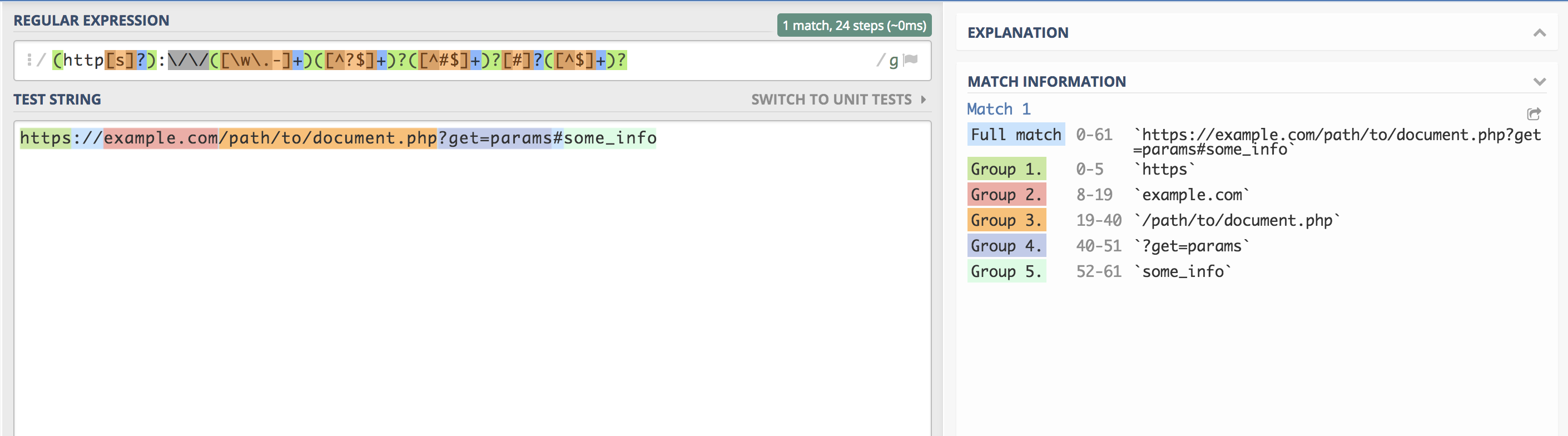
[^$]+ All the beauty in the end looks like this (unfortunately, I didn’t figure out how to insert this part so that Habr would not consider part of the line as a comment):
/(?<scheme>http[s]?):\/\/(?<domain>[\w\.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/ The main thing is not to blink! :)
<?php $URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor"; $regexp = “/(?<scheme>http[s]?):\/\/(?<domain>[\w\.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/”; $result = preg_match($regexp, $URL, $match); var_dump( $result, $match ); array(11) { [0]=> string(61) "https://hello.world.ru/uri/starts/here?get_params=here#anchor" ["scheme"]=> string(5) "https" ["domain"]=> string(14) "hello.world.ru" ["URI"]=> string(16) "/uri/starts/here" ["params"]=> string(15) "get_params=here" ["anchor"]=> string(6) "anchor" } It turned out about the same thing, only with their own hands.
What tasks are not solved by regular expressions
At first glance, it seems that regular text can describe and parse any text. But, unfortunately, it is not.
Regular expressions are a subspecies of formal languages, which in Chomsky’s hierarchy belong to the 3rd type, the simplest. About this here .
With the help of this language, we cannot, for example, parse the syntax of programming languages with a nested grammar. Or HTML code.
Examples of tasks:
We have a span, within which there are many other span and we do not know how much. You have to choose everything inside this span:
<span> <span>ololo1</span> <span>ololo2</span> <span>ololo3</span> <span>ololo4</span> <span>ololo5</span> <...> </span> Of course, if we parse HTML, where there is not only this span. :)
The bottom line is that we cannot start at some point “counting” the symbols span and / span, meaning that there should be an equal number of opening and closing symbols. And to “understand” that the closing symbol, for which there was previously no pair, is the same closing symbol, which separates the block.
Same with the code and {} characters.
For example:
function methodA() { function() {<...>} if () { if () {<...>} } } In such a structure, we cannot, using only a regular expression, distinguish the closing brace inside the code from the one that completes the initial function (if the code consists not only of this function).
To solve such problems using higher level languages.
Conclusion
I tried to tell in some detail about the basics of the world of regular expressions. Of course it is impossible to fit everything into one article. Further work with them is a matter of experience and ability to google.
Thanks for attention.
Source: https://habr.com/ru/post/343310/
All Articles