Text captchas are easily recognized by deep learning neural networks.

Deep learning neural networks have achieved great success in pattern recognition. At the same time, text captchas are still used in some well-known free email services. I wonder if neural networks will be able to do deep learning to cope with the task of captcha recognition? If so, how?
What is text captcha?
Captcha (eng. “CAPTCHA”) is a test for “humanity”. That is, a task that is easily solved by a person, while for a machine, this task must be difficult. Often used text with stuck letters, the example in the picture below, the image is also subjected to optical distortion.

')
Captcha is usually used on the registration page to protect against spam bots.
Full-convolutional neural network
If the letters “stuck together”, then they are usually very difficult to separate by heuristic algorithms. Therefore, you need to look for each letter in each place of the picture. The full-convolutional neural network will cope with this task. Full-convolutional network - a convolutional network without a fully meshed layer. An image is fed to the input of such a network; at the output, it also gives an image or several images (center maps).

The number of center cards is equal to the length of the alphabet of symbols used in a particular captcha. The centers of the letters are marked with centers of letters. The large-scale transformation that occurs in the network due to the presence of pulling layers is taken into account. The following is an example of a character map for the “D” character.
In this case, convolutional layers with padding are used so that the size of the images at the output of the convolutional layer is equal to the size of the images on the input layer. The spot profile on the character map is given by a two-dimensional Gaussian function with widths of 1.3 and 2.6 pixels.
Initially, the full-convolution net was tested on the “R” symbol:
A small network with 2 pulling, natrenni on the CPU was used for testing. After making sure that the idea at least somehow works, I purchased a used Nvidia GTX 760, 2GB graphics card. This gave me the opportunity to train larger networks for all the characters of the alphabet, and also accelerated learning (about 10 times). For training the network, the Theano library was used, currently not supported anymore .
Training on the generator
It seemed a long and laborious task to mark up a large dataset manually, so it was decided to generate captcha with a special script. In this case, maps of the centers are generated automatically. I chose the font used in the captcha for the Hotmail service, the generated captcha was visually similar in style to the real captcha:

The final accuracy of training on generated captcha, as it turned out, is 2 times lower, compared to training on real captcha. Probably, such nuances as the degree of intersection of symbols, scale, thickness of lines of symbols, distortion parameters, etc., are important, and these nuances could not be reproduced in the generator. The network trained on generated captcha gave about 10% accuracy on real captcha, accuracy - what percentage of captcha was recognized correctly. A captcha is considered recognized if all the characters in it are recognized correctly. In any case, this experiment showed that the method is working, and it is required to increase the accuracy of recognition.
Training on a real dataset
For manual markup of real captcha datasets, a script was written on Matlab with a graphical interface:

Here you can arrange the circles and move the mouse. The circle marks the center of the symbol. Manual marking took 5-15 hours, however there are services where for a small fee they manually mark up datasets. However, as it turned out, the Amazon Mechanical Turk service does not work with Russian customers. Placed an order for markup dataset on the famous freelancing site. Unfortunately, the quality of the markup was not perfect, I corrected the markup myself. In addition, the search for the artist takes time (1 week) and it also seemed expensive: $ 30 for the 560 marked captcha. He refused this method, eventually came to use the manual recognition of captcha sites, where the lowest cost is 1 dollar for 2000 captchas. But the answer received there is a string. Thus, manual placement of the centers could not be avoided. Moreover, the performers in such services make mistakes or act in bad faith at all, typing an arbitrary string in the answer. As a result, it was necessary to check and correct errors.
Deeper network
Obviously the recognition accuracy was insufficient, so the question arose of the selection of architecture. I was interested in the question of whether one pixel “sees” on the output image the entire character on the input image:

Thus, we consider one pixel in the output image, and there is a question: what values of pixels on the input image affect the values of this pixel? I reasoned like this: if a pixel does not see the whole character, then not all the information about the character is used and the accuracy is worse. To determine the size of this scope (we will call it that way), I conducted the following experiment: I set all the weights of the convolutional layers to 0.01, and the offset to 0, an image is fed to the input of the network, in which the values of all pixels are 0 except the central one. As a result, the output of the network is a stain:

The shape of this spot is close to the shape of the Gaussian function. The shape of the resulting spot raises the question: why is the spot round, while the bundle cores are square in convolutional layers? (The network used 3x3 and 5x5 kernels). My explanation is this: it looks like the central limit theorem . In it, as here, there is a desire for a Gaussian distribution. The central limit theorem states that for random variables, even with different distributions, the distribution of their sum is equal to the convolution of the distributions . Thus, if we fold any signal with ourselves many times, then according to the central limit theorem, the result tends to a Gaussian function, and the width of the Gaussian function grows as the root of the number of convolutions (layers). If for the same network with constant weights to see where in the output image the pixel values are greater than zero, then it turns out to be a square area (see figure below), the size of this area is proportional to the sum of the sizes of convolutions in the convolutional layers of the network.

I used to think that because of the associative property of convolution, two consecutive 3x3 convolutions are equivalent to a 5x5 convolution and therefore, if you roll 2 2x 3x3 cores, you get one 5x5 core. However, then I came to the conclusion that this is not equivalent if only because two bundles have 3x3 9 * 2 = 18 parameters, and one has 5x5 25 parameters, thus, the 5x5 convolution has more degrees of freedom. As a result, the output of the network is a Gaussian function with a width less than the sum of the sizes of the bundles in the layers. Here I answered the question which pixels on the output are affected by one pixel on the input. Although initially the question was posed to reverse. But both questions are equivalent, which can be understood from the figure:

In the figure you can imagine that this is a view of images from the side or that our image height is 1. Each of the pixels A and B has its own zone of influence on the output image (marked in blue): for A this is DC, for B it is CE , the values of pixel C are affected by the values of pixels A and B and the values of all pixels between A and B. Distances are equal: AB = DC = CE (taking into account scaling: there are pulling layers in the network, therefore the input and output images have different resolutions). As a result, we get the following algorithm for finding the size of the scope:
- set constant weights in convolutional layers, weights set weights to 0
- input images with one non-zero pixel
- get the spot size at the output
- we multiply this size by a factor that takes into account the different resolutions of the input and output layers (for example, if we have 2 pooling in the network, then the output resolution is 4 times less than the input, then this size must be multiplied by 4).
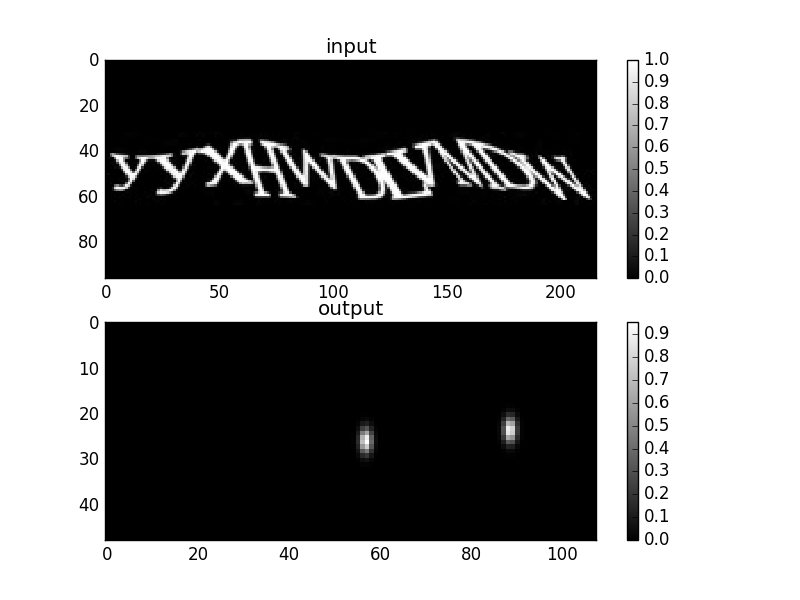
In order to see what signs the network uses, he conducted the following experiment: send a captcha image to the trained network, receive images with marked centers of characters at the output, select a detected character from them, leave only the map that corresponds to the considered one on the center image cards. character. This network output is memorized as
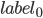 , then gradient descent minimizes the function:
, then gradient descent minimizes the function: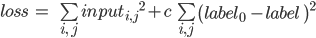
Here
 - input network image,
- input network image, 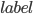 - output images of the network,
- output images of the network,  - some constant, which is chosen experimentally (
- some constant, which is chosen experimentally (  ). With such a minimization, the input and output of the network are considered variables, and the weights of the network are constants. Variable initial value This image of the captcha is the starting point for the optimization of the gradient descent algorithm. With this minimization, we reduce the pixel values at the image input, while keeping the pixel values at the output image, as a result of optimization, only those pixels that the network uses in character recognition remain on the input image.
). With such a minimization, the input and output of the network are considered variables, and the weights of the network are constants. Variable initial value This image of the captcha is the starting point for the optimization of the gradient descent algorithm. With this minimization, we reduce the pixel values at the image input, while keeping the pixel values at the output image, as a result of optimization, only those pixels that the network uses in character recognition remain on the input image.What happened:
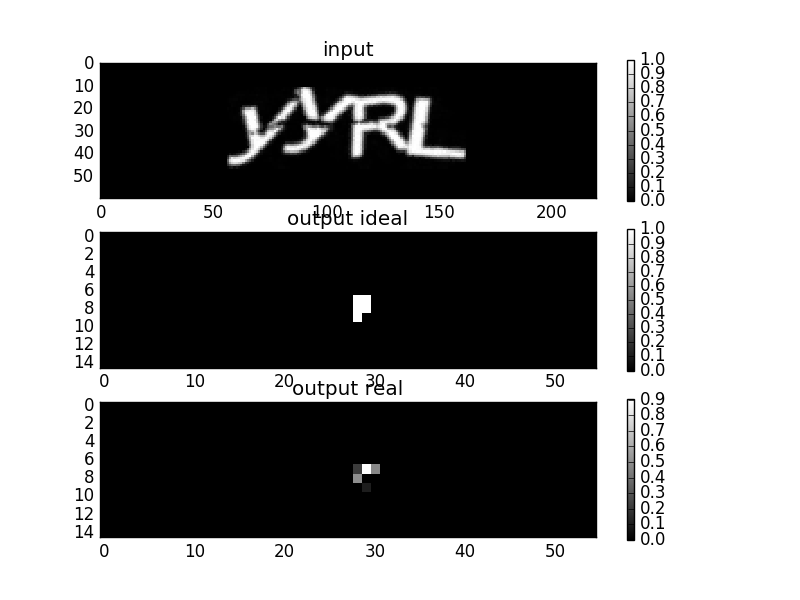
For the character “2”:

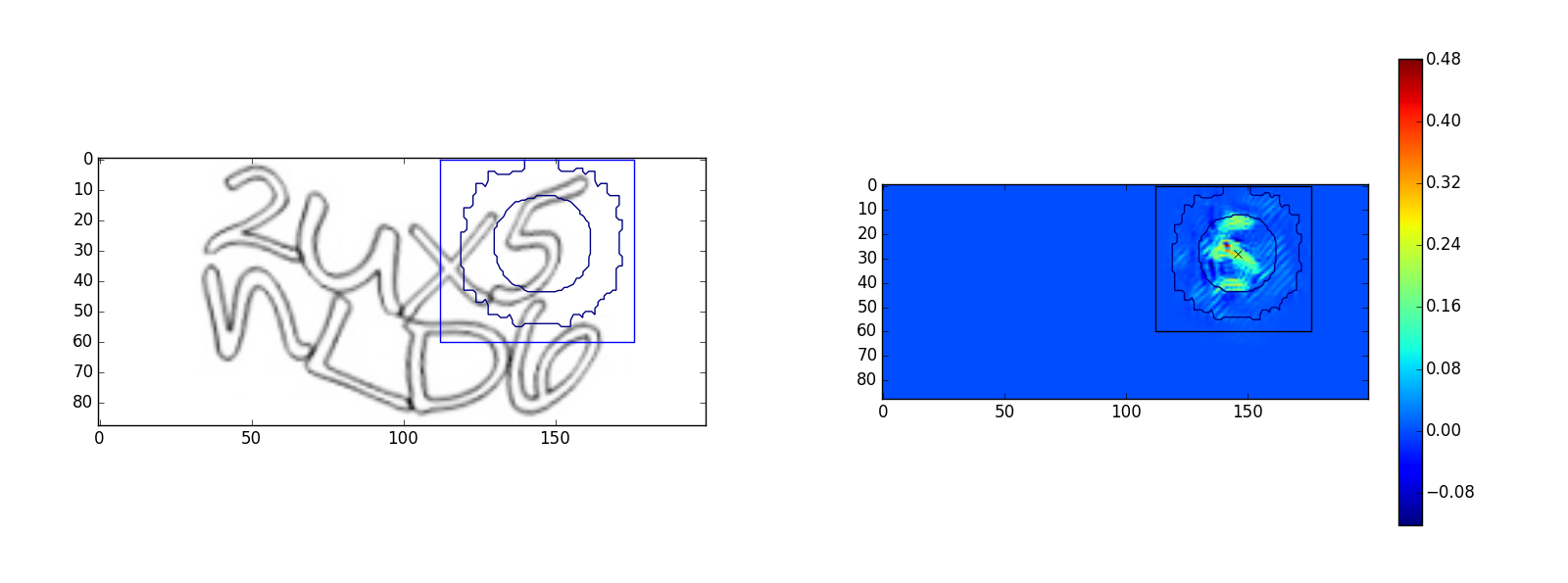
For the “5” symbol:
For the “L” symbol:

For the “u” character:
The images on the left are the original captch images, the images on the right are an optimized image
. The square on the images indicates the scope of output> 0, the circles in the figure are the lines of the level of the Gaussian function of the scope. Small circle - the level of 35% of the maximum value, a large circle - the level of 3%. Examples show what the network sees within its scope. However, the “u” symbol has a going beyond the scope, perhaps this is a partial false response to the “n” symbol.Many experiments with the network architecture have been carried out, the deeper and wider the network, the more complex captcha it can recognize, the most universal architecture is the following:
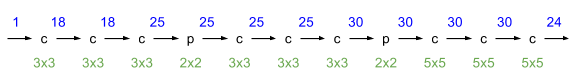
Blue color, over the arrows, shows the number of images (feature maps). c - convolutional layer, p - max-pooling layer, the green sizes at the bottom show the sizes of the cores. The convolutional layers use 3x3 and 5x5 kernels without strade, the pulling layer has a 2x2 patch. After each convolutional layer there is a ReLU layer (not shown in the figure). One image is fed to the input, the output is 24 (the number of characters in the alphabet). In convolutional layers, the padding is selected so that at the exit of the layer the image size is the same as at the entrance. Padding adds zeros, but this does not affect the network in any way, because the background pixel value of the captcha is 0, since a negative image is always taken (white letters on a black background). Padding only slightly slows down the network. Since the network has 2 pulling layers, the image resolution at the output is 4 times less than the image resolution at the input, thus each pulling reduces the resolution by 2 times, for example, if we have a captcha at the input of 216x96, then the output will have 24 images of 54x24 .
Improvements
The transition from the SGD solver to the ADAM solver gave a noticeable acceleration of learning, and the final quality became better. The ADAM solver imported from the lasagne module and used inside the theano-code, the learning rate parameter was set to 0.0005, the L2 regularization was added through the gradient. It was observed that from training to training the result is different. I explain it this way: the gradient descent algorithm is stuck in an insufficiently optimal local minimum. I partially overcame it in the following way: I ran the training several times and selected some of the best results, then I continued to train them for several more eras, after which I chose one best result and already this single best result I trained for a long time. Thus, it was possible to avoid getting stuck in insufficiently optimal local minima and the final value of the error function (loss) was obtained sufficiently small. The figure shows a graph - the evolution of the value of the error function:
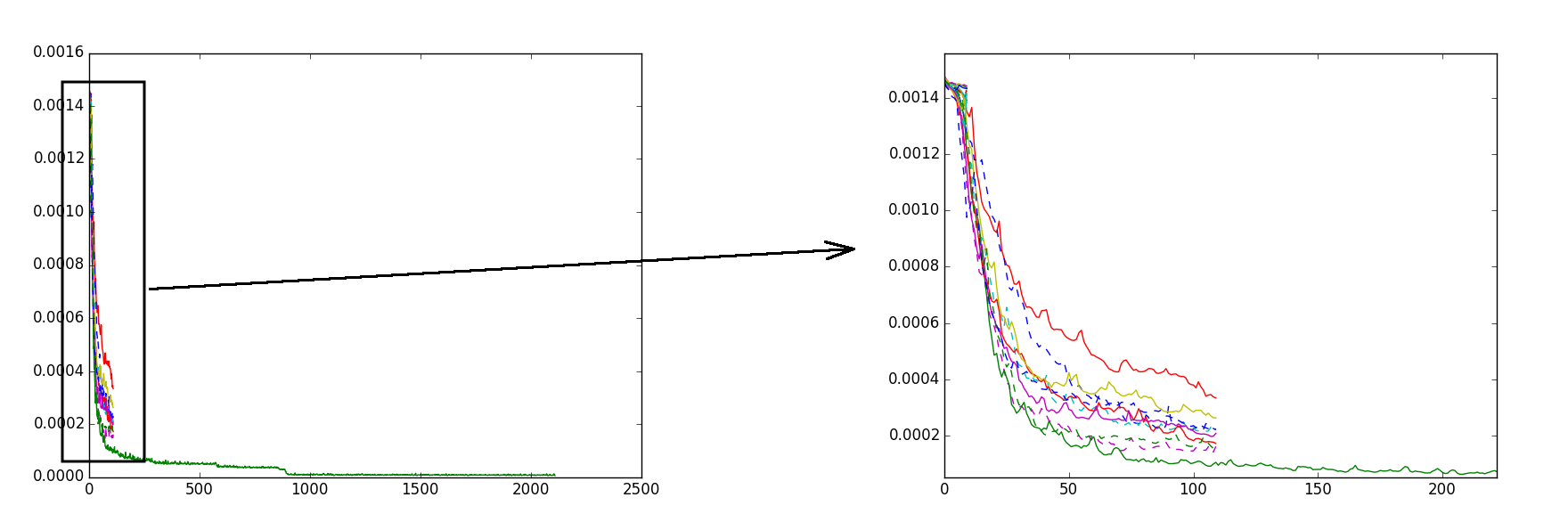
On the x axis, the number of epochs, on the y axis, the value of the error function. Different colors show different workouts. The order of training is like this:
1) run 20 workouts of 10 eras
2) choose the 10 best results (at the lowest loss value) and train them for another 100 eras
3) choose one best result and continue to train it for another 1500 epochs.
It takes about 12 hours. Of course, to save memory, these trainings were carried out sequentially, for example, in point 2) 10 trainings were carried out sequentially one after another, for this I carried out a modification of the ADAM solver from Lasagne to be able to save and load the state of the solver into variables.
Dividing the dataset into 3 parts made it possible to track network retraining:
Part 1: training dataset - the initial one, where the network is trained
Part 2: test dataset, on which the network is checked during training
3 part: deferred dataset, it checks the quality of training after training
Datasets 2 and 3 are small, in my case there were 160 captchas in each, and the optimal response threshold is determined from dataset 2, the threshold that is set on the output image. If the pixel value exceeds the threshold, then the corresponding symbol is found in this place. Typically, the optimal threshold value is in the range of 0.3 - 0.5. If the accuracy on the test dataset is significantly lower than the accuracy on the training dataset, this means that retraining has occurred and the training dataset needs to be increased. If these precisions are about the same, but not high, then the neural network architecture needs to be complicated, and the training data should be increased. Complicate the network architecture in two ways: to increase the depth or increase the width.
Pre-processing of images also increased recognition accuracy. Pre-processing example:
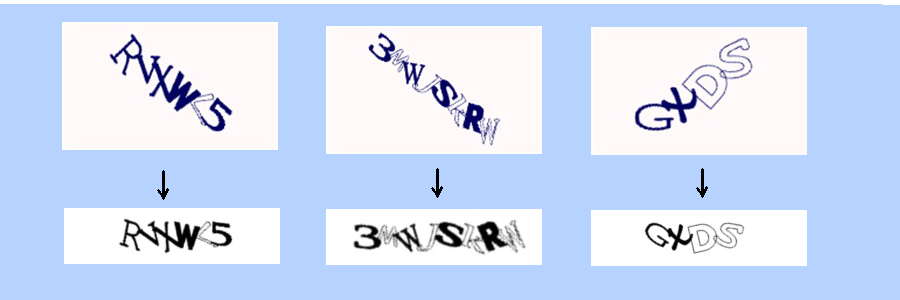
In this case, using the least squares method, the middle line of the rotated line was found, it is rotated and scaled, scaling is carried out along the average line height. Hotmail often makes a variety of distortions:



These distortions need to be compensated.
Bad ideas
It is always interesting to read about other people's failures, I will describe them here.
There was a problem with a small dataset: for quality recognition, a large dataset was needed, which was required to be manually marked out (1000 caps). I have made various attempts to somehow train the network qualitatively in a small dataset. I tried to train the network on the results of recognition of another network. at the same time I chose only those captchas and those places of images in which the network was confident. Confidence was determined by the pixel value on the output image. Thus it is possible to increase. However, the idea did not work, after several iterations of learning, the quality of recognition deteriorated greatly: the network did not recognize some characters, confused them, that is, recognition errors accumulated.
Another attempt to learn in a small dataset is to use Siamese networks, the Siamese network at the entrance requires a couple of captchas, if we dataset from N captchas, then the pair will be N 2 , we get much more teaching examples. The network converts captcha to a vector map. As the metric of similarity of vectors chose the scalar product. It was assumed that the Siamese network will work as follows. The network compares a part of the image on a captcha with a certain reference image of a symbol, if the network sees that the symbol is the same, taking into account the distortion, then it is considered that there is a corresponding symbol in this place of kachi. The Siamese network practiced with difficulty, often getting stuck in a non-optimal local minimum, the accuracy was noticeably lower than the accuracy of a conventional network. Perhaps the problem was in the wrong choice of the vector similarity metrics.
There was also an idea to use autoencoder for preliminary training of the lower part of the network (the one that is closer to the entrance) in order to speed up learning. The autoencoder is a network that learns to produce the same image as the input on the output image, while organizing a narrow section in the architecture of the autoencoder. Training avtoenkodera have training without a teacher.
An example of autoecoder operation:
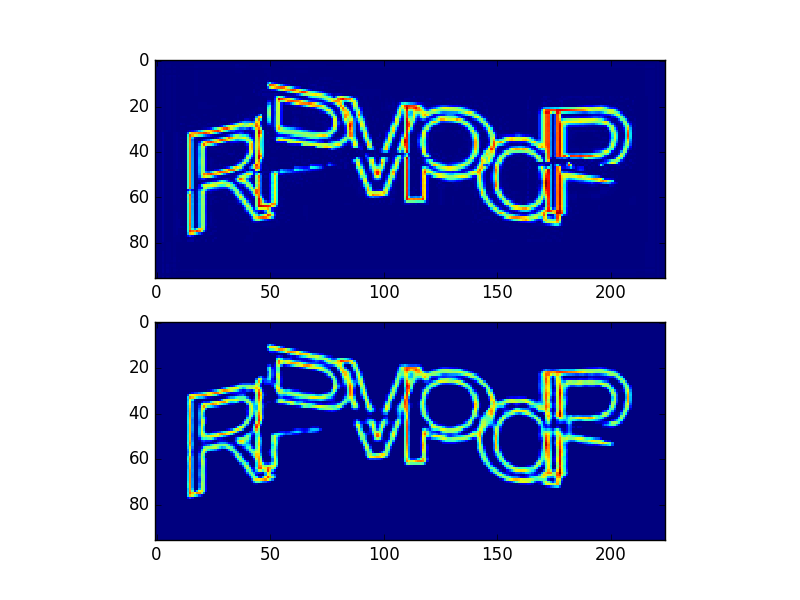
The first image is the input, the second is the output.
A trained avtoenkoder take the lower part of the network, add new untrained layers, all this is tested for the desired task. In my case, the use of an avtoenkoder did not accelerate the training of the network.
There was also an example of a captcha that used color:


On this captcha, the described method with a full-convolutional neural network did not give a result, it did not appear even after various image preprocessing enhancing the contrast. I suppose that full-convolutional nets do not cope well with low-contrast images. However, this captcha was recognized by a conventional convolutional network with a fully connected layer, an accuracy of about 50% was obtained, and the coordinates of the symbols were determined using a special heuristic algorithm.
Result
| Examples | Accuracy | Commentary |
|---|---|---|
  | 42% | Captcha Microsoft jpg |
 | 61% | |
 | 63% | |
 | 93% | captcha mail.ru , 500x200, jpg |
 | 87% | captcha mail.ru , 300x100, jpg |
 | 65% | Captcha Yandex , Russian words, gif |
 | 70% | Captcha Steam , png |
 | 82% | captcha World Of Tanks , numbers, png |
What else could be improved
It would be possible to make an automatic marking of the centers of symbols. The manual recognition services for captcha give out only recognized lines, so automatic marking of the centers would help to fully automate the marking of the training dataset. The idea is this: to choose only those captchas in which each symbol occurs once, for each symbol to train a separate ordinary convolutional network, such a network will only answer the question: is there a symbol in this captcha or not? Then, see which attributes the network uses using the minimization method of the pixel values of the input image (described above). The obtained signs will allow to localize the symbol, then we train the full-convolution net on the received centers of symbols.
findings
Text captchas are recognized by a full-convolutional neural network in most cases. Probably, the time has come to abandon the text captchas. Google has not used text captcha for a long time; instead of text, images with various objects are suggested that need to be recognized by a person:
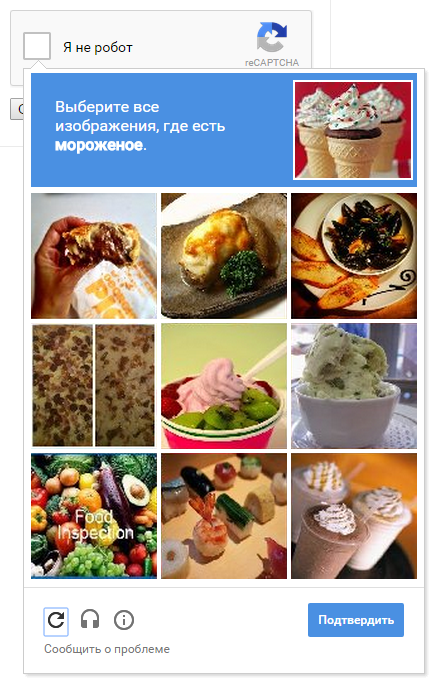
However, this problem seems to be solved for the convolutional network. It can be assumed that in the future there will be people’s registration centers, for example, a person is interviewed by a live person on Skype, checks passport scans and the like, then a person is given a digital signature with which he can automatically register on any site.
© Maxim Vedenev
Source: https://habr.com/ru/post/343222/
All Articles