As "Dadata" looking for duplicates in the lists of outlets. Parse the algorithm

Our clients keep lists of thousands of companies, and usually there is primeval chaos.
Take a list of outlets through which the farmer sells goods throughout the country. Store names are written as they want, so a typical list looks like this:
')
- Eurasia.
- "SAKURA" Japanese cuisine.
- Dominant.
- Boutique shop "Eurasia".
- Milenium, LLC, a grocery store.
- Kiwi / LLC / Chelyabinsk.
- Supermarket eco-products "Dominant".
Points number 1 and number 4 - duplicates, number 3 and number 7 - also, but go figure it out.
And you need to figure it out: when there are 300 duplicates in a list of 1000 outlets, the manufacturer starts having problems.
- The sales plan fails. You think that you sell through 1000 stores, and in fact 300 of them are duplicates;
- sales representatives do not understand what. Trade representatives must drive points, clean up the shelves and re-order goods. If the database is duplicated, the staff gets strange routes and runs idle.
The first reaction is to clean the hands of live operators. Useless. People still make mistakes, because the names sometimes write quite exotic. Yes, and it is expensive.
We took up the problem with brute force solutions.
Ready tools do not fit
Good old Excel obviously will not cope with the task, because the duplication condition
"Dadatovsky" search for duplicate individuals , also did not fit. He compares people by name, address and additional fields like the phone. But the comparison algorithm of the full name is not suitable for the names, and you cannot find duplicates at the address alone: any shopping center with a bunch of boutique departments will break all the statistics.
There was still a chance: we have the Factor enterprise-engine, which brings the names to the type of the Unified State Register of Legal Entities - the state register of legal entities. But he did not help either: the name of a point often has nothing to do with the name of a legal entity. If LLC "Vector +" called the shop "Cosiness", the report will go "Cosiness". Incorporation will not help.
As a result, we took the search for duplicates on individuals and finalized. Addresses he already compared, it was necessary to teach him to compare the names.
Find the semantic basis of the name
To compare the names of companies, you must first clear them of the husk - to find the semantic basis. We do this with regular expressions.
Clear punctuation:
- add spaces after commas;
- change the strikethrough for spaces;
- remove everything from the name, except letters, numbers and spaces.
We delete everything that gets into typical patterns. Our analyst reviewed 10,000 records in the reports on the outlets. As a result, he made a database of patterns that litter the names. Dadata removes:
- types of outlets : “prod. shop ”,“ minimarket ”,“ supermarket ”,“ department store ”,“ eco-store ”,“ chain of stores ”, etc .;
- everything in brackets and after them : “Social Pharmacy 6 (104, Bataysk)” → “Social Pharmacy 6”;
- all except the first word, if three words are written in slash : “Bashmedservice / LLC / Chelyabinsk” → “Bashmedservice”. Probably, in this format, names are downloaded from accounting systems or registries, because the problem is very frequent;
- city from the beginning : "KRYMSK, LLC * BEREZKA *" → "LLC * BEREZKA *";
- address from the tail : “Nordex M LLC, Apatity, Murmansk region” → “Nordex M LLC”;
- tail after OPF : “Status LLC AGREEMENT NO” → “Status LLC”.
If you want to bypass the algorithm is simple: a bit of patterns. But problems with duplicates appear due to the lack of standards, and not malicious intent. In real life, the above is enough.
Remove the OPF : CJSC, OJSC, PJSC and decoding of the type “open”. acc. general. "
As a result, only meaningful parts of the names of the companies remain, which are compared by Dadat.
Compare the semantic foundations and addresses
In itself, coincidence of names is a very weak criterion. Therefore, in "Dadatu" they usually load the address, and sometimes - the phone.
The service finds the semantic basis of names and standardizes addresses. And deduplication itself begins: “Dadata” collects records from the input files into a heap and compares each with each.
The algorithm checks pairs by scenarios, there are ten of them. Examples:
| Scenario | Probability of double |
|---|---|
| Names are the same, other fields are empty | 100% |
| Names are similar, addresses match | 95% |
| The names are the same, the address is different extension of the house number (letter, letter, etc.) | 95% |
| The names are similar, the phones are the same. | 70% |
- if the basics end in number, and the numbers are different, Dadata considers the names different. Otherwise, for example, “Social Pharmacy Dr. Zhivago 12” and “Social Pharmacy Dr. Zhivago 13” will fall under the filter;
- address matches have more weight than name matches. If the names match by 60%, and the addresses by 100%, then the probability of a double is 95%;
- among the scenarios that fit a pair of records, Dadata chooses the one that gives the highest percentage of similarity.
When the service has found the probability of duplicates, it makes a verdict:
- > 85% similarity - guaranteed double. You can automatically merge entries into one;
- <85% - possibly double. The system marks entries with the tag “similar” and ID. By ID in the final file, the user selects groups of similar entries;
- if no script came up, then the notes are different.
Our algorithm will not find all duplicates as 100%. He will simply mark similar points for the operator to disassemble them with his hands. There is room for improvement, we will finish it.
Let the robots work
Meanwhile, we reduced prices for duplicates by 10 times. Now "Dadata" is looking for the same people and companies for just 1 kopek per post processed.
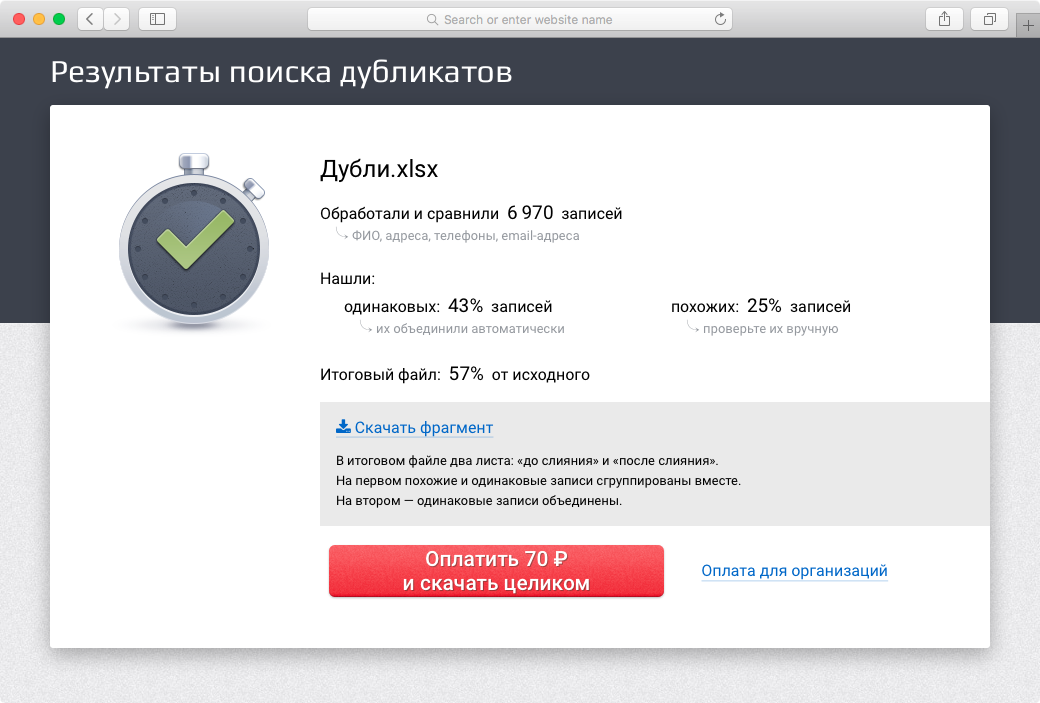
“Dadata” will first receive the files and show the number of duplicates, and only then will ask if you want to pay
Register , upload files - and you can clean from duplicate lists of outlets, contractors, customers, anyone.
Source: https://habr.com/ru/post/343150/
All Articles