As I wrote an application that in 15 minutes did the same thing as a regular expression in 5 days
From translator
Not so long ago I ran into the problem of finding a set of words in a large text. Of course, the main problem was performance. The search for ready-made solutions generated more questions than gave answers. Often I came across examples of using some kind of third-party boxes or online services. First of all, I needed a simple and easy solution that would later give me thoughts for the implementation of my own utility.
A few weeks ago there was a wonderful English-language article about the open-source FlashText python library. This library provided a fast working solution to finding and replacing keywords in text.
Since There are not so many materials on this subject in Russian, I decided to translate this article into Russian. Under the cat you will find a description of the problem, analysis of the principle of the library as well as examples of performance tests.
')
Start
The main task when working with text is to clean it. Usually this process is very simple. For example, we need to replace the phrase “Javascript” with “JavaScript”. But more often we just need to find all the references to the phrase "Javascript" in the text.
The task of data cleansing is a typical task for most projects working in the field of datalogy (data science) .
Data history starts with data clearing.
I recently solved just such a problem. I work as a researcher at Belong.co and natural language processing takes half of my time.
When I started using Word2Vec to analyze our text corpus , I realized that synonyms were analyzed as one value. For example, the term "Javascripting" was used instead of "Jacascript", etc.
To solve this problem I needed to clear the text. To do this, I wrote an application using a regular expression, which replaced all possible synonyms of the phrase "Javascript" with its original form. However, this only gave rise to new problems.
Some people, when confronted with a problem, think
“I know, I'll use regular expressions.” Now they have two problems.
This quote was the first time I met here and it was she who characterized my case. It turns out that a regular expression is executed relatively quickly, only if the number of keywords that need to be found and replaced in the source text does not exceed just a few hundred. But our text corpus consisted of more than 3 million documents and 20 thousand keywords.
When I estimated the time it would take to replace all the keywords using regular expressions, it turned out that we would need 5 days for one run of our text corpus.

The first solution to a similar problem suggested itself: a parallel start of several search and replace processes. However, this approach has ceased to be effective after the amount of data has increased. Now the text corpus consisted of tens of millions of documents and hundreds of thousands of keywords. But I was sure that there must be a better solution to this problem! And I started looking for him ...
I asked around for colleagues in my office, asked a few questions on Stack Overflow . As a result, I had a couple of good offers. Vinay Pandey, Suresh Lakshmanan
In the discussion they advised to try the Aho-Korasik algorithm and the prefix tree .
My attempts to find a ready-made solution were unsuccessful. I have not found any standing library. As a result, I decided to implement the proposed algorithms in the context of my task. This is how FlashText came into being.
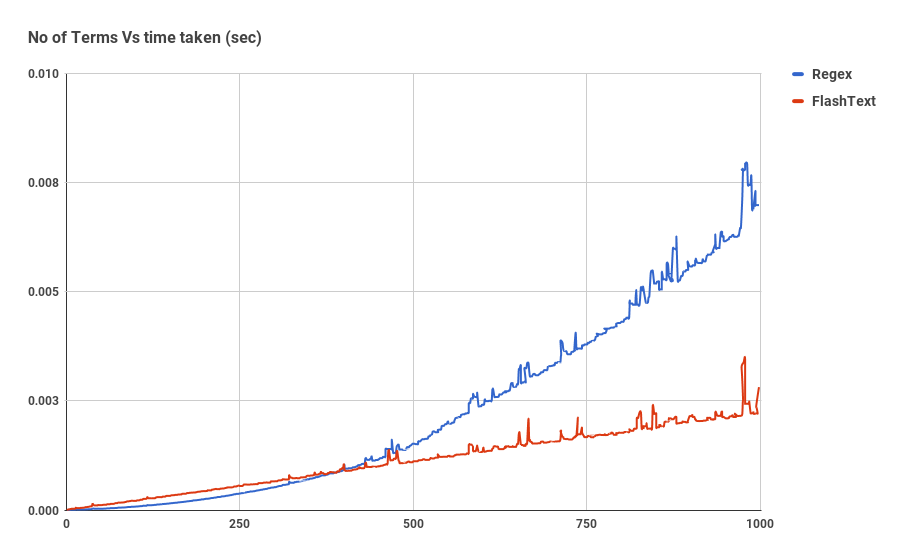
Before we get into the details of the implementation of FlashText, let's see how the search speed has increased.
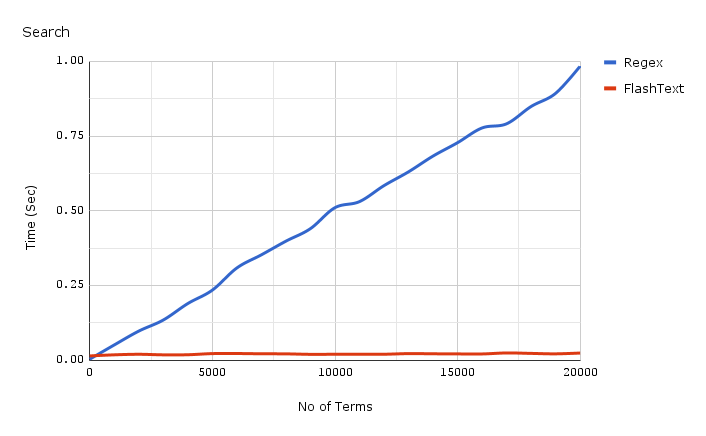
The graph shows the dependence of the time of work on the number of keywords, when performing a search operation for keywords in one document. As we can see, the time spent by an application using a regular expression depends linearly on the number of keywords. For FlashText, this dependence is not observed.
FlashText reduced the time for one run of our text corpus from 5 days to 15 minutes.

Below is a graph of time spent versus the number of keywords when performing a replace operation in one document.
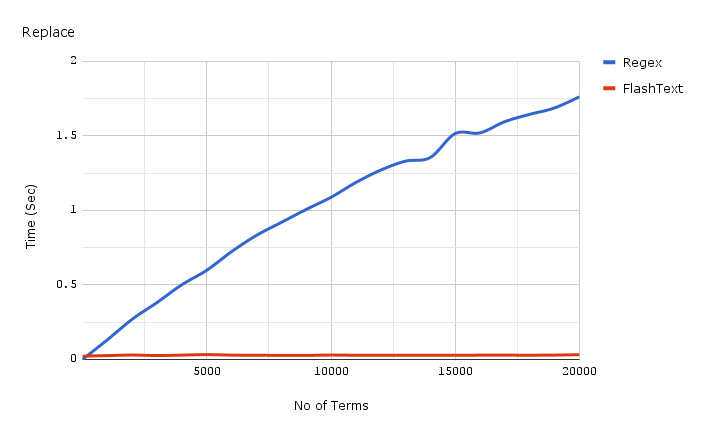
The code for getting the benchmarks used for the graphs presented above can be found here , and the benchmarks themselves here .
So what is FlashText?
FlashText is a small open-source Python library that is laid out on GitHub . It copes equally well with both the search task and the task of replacing keywords in a text document.
The first step in using FlashText is to build a corpus of keywords that the library will use to build the prefix tree. After that the text for which the search or replace procedure will be performed will be input to the library.
When replacing, FlashText will create a new line with replaced keywords. When searching, the library will return a list of keywords found in the input line. In both cases, the result will be obtained in one pass of the input line.
The first positive feedback from happy users has already appeared on twitter:
Why is FlashText so much faster?
Let's look at an example of work. Suppose we have a text consisting of three words:
I like Python and a body of keywords consisting of 4 words: { Python, Java, J2ee, Ruby } .If we check the presence of each keyword from the corpus in the source text, then we will have 4 search iterations:
is 'Python' in sentence? is 'Java' in sentence? ... From the pseudocode, we see that if the list of keywords consists of n elements, then we need n iterations.
But we can do the opposite: check the existence of each word from the source text in the body of keywords.
is 'I' in corpus? is 'like' in corpus? is 'python' in corpus? If the sentence consists of m words, then we will have m iterations. The total time of the operations will be directly proportional to the number of words in the text. It should be noted that the search for a word in the body of keywords will be performed faster than the search for a keyword in the text, since the body of keywords is a dictionary.
FlashText is based on a second approach. In its implementation, the Aho-Korasik algorithm and the prefix tree are also used.
The algorithm works as follows:
First, a prefix tree is created for the body of keywords. It will look like this:
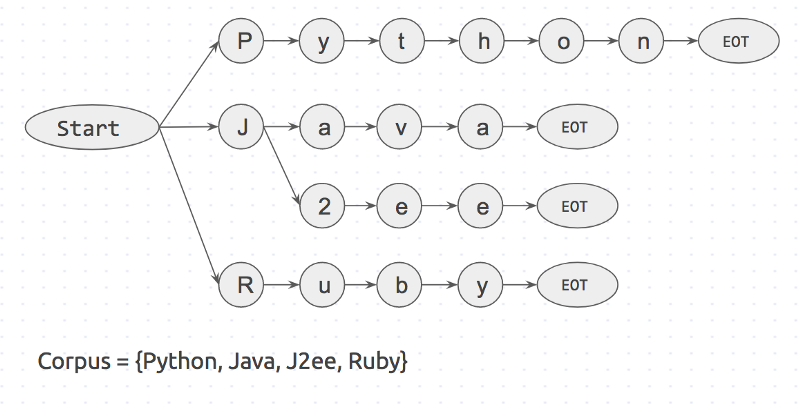
"Start" and "EOT" are the boundaries of the words: space, new line, etc. The keyword will match the input value, only if the word has border characters on both sides. This approach will eliminate erroneous coincidences, such as "apple" and "pineapple".
Next, consider an example. Take the string
I like Python and begin to search for keywords in the element by element. Step 1: is <start>I<EOT> in dictionary? No Step 2: is <start>like<EOT> in dictionary? No Step 3: is <start>Python<EOT> in dictionary? Yes Below is the prefix tree for step 3.
is <start>Python<EOT> in dictionary? Yes 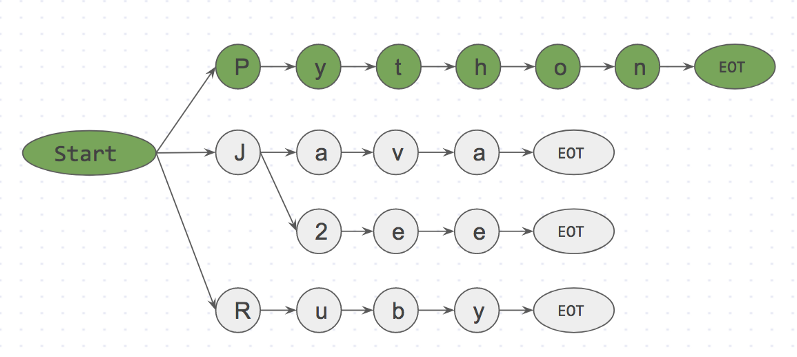
Thanks to this approach, we can already reject like <EOT /> on the first character, because the symbol
i not located next to start . Thus, we can almost instantly discard words that are not part of the body and not waste time on them.The FlashText algorithm will parse the characters of the input string
I like Python , while the body of the keywords can be of any size. The size of the body of the body of keywords will not affect the speed of the algorithm. This is the main secret of the FlashText algorithm.When do you need to use FlashText?
It's very simple: as soon as the size of the body of keywords becomes more than 500, then this graph appears.
However, it is worth noting that Regex, unlike FlashText, can search in the source string for special characters such as
^,$,*,\d,, which are not supported by the FlashText algorithm. That is, it is not necessary to include the word\dvec element in the body of keywords, but with the word2vec element everything will work fine.How to run FlashText to search for keywords
# pip install flashtext from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword('Big Apple', 'New York') keyword_processor.add_keyword('Bay Area') keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.') keywords_found # ['New York', 'Bay Area'] Same on github
How to run FlashText to replace keywords
In general, this was the main task for which FlashText was developed. We use this to clear data before processing.
from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword('Big Apple', 'New York') keyword_processor.add_keyword('New Delhi', 'NCR region') new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.') new_sentence # 'I love New York and NCR region.' Same on github
If you have colleagues who work with the analysis of test data, recognition of references to entities , processing of natural language or Word2vec , then please share this article with them.
This library has been very useful for us and I am sure that it will be useful to someone else.
It turned out long. Thank you for reading.
Source: https://habr.com/ru/post/343116/
All Articles