Black Friday IT, or The Tale of Data Loss

There is a beautiful saying "And the old woman is proruha". It can be made the motto of the industry: even a well-designed multi-level system to protect against data loss can fall victim to an unforeseen bug or human error. Alas, such stories are not uncommon, and today we want to tell about two cases from our practice, when everything went wrong. Shit happens, as the old Forrest Gump used to say.
Case one: bugs are omnipresent
One of our customers used a backup system designed to protect against a hardware failure. To ensure high availability of the operation of the levels of infra and applications, a cluster solution based on Veritas Cluster Server software was used. Data backup was achieved using synchronous replication using external disk arrays. Before updating the system or its individual components, a long test at the stand was always carried out in accordance with the recommendations of the software manufacturer.
The system is competent, distributed over several sites in case of loss of one data center entirely. It would seem that everything is fine, the reservation solution is excellent, the automation is set up, nothing terrible can happen. The system has been working for many years, and there were no problems - with failures, everything worked out properly.
But then that moment came when one of the servers fell. When switching to a backup site found that one of the largest file systems is not available. Long understood and found out that we have stepped on a software bug.
')
It turned out that shortly before these events a system software update was rolled in: the developer added new features to improve performance. But one of these features was buggy, and as a result, the data blocks of one of the database data files were damaged. He weighed only 3 GB, but the trouble is that he had to be restored from backup. And the last full backup of the system was ... almost a week ago.
To begin, the customer had to get the entire database from a week-old backup, and then apply all the archive logs for the week. It took a lot of time to get several terabytes of tapes, because the RMS actually depends on the current load, free drives and tape drives, which at the most necessary moment may be occupied by other restoration and recording of the next backup.
In our case, everything was even worse. The trouble does not come alone, yeah. Recovery from the full backup was fairly fast, because both the ribbons and the drives were allocated. But backups of archive logs were on the same tape, so it was not possible to start parallel recovery in several streams. We sat and waited until the system found the right position on the tape, read the data, rewound, looked for the right position again, and so on and around in a circle. And since the RMS was automated, a separate task was generated to restore each file, it fell into a common queue and waited for the release of the necessary resources.
In general, the poor 3 gigabyte we recovered 13 hours.
After this accident, the customer reviewed the reservation system and thought about the acceleration of the work of the IBS. We decided to abandon the tapes, considered the option of software storage and the use of various distributed file systems. The customer already had virtual libraries at that time, but their number was increased, they implemented deduplication software and local data storage systems to speed up access.
Case two: it is human to err
The second story is more prosaic. The approach to building distributed backup systems was standardized at a time when no one expected the presence of low-skilled personnel behind the server management console.
The monitoring system worked for the high utilization of the file system, the duty engineer decided to restore order and clean the file system on the server with the database. The engineer finds the database audit log - as he thinks! - and deletes its files. But the nuance is that the database itself was also called “AUDIT”. As a result, the customer’s engineer on duty confused the catalogs and famously deleted the database itself.
But the database at that moment worked, and the free space on the disk after deletion did not increase. The engineer began to look for other possibilities to reduce the file system size - he found them and calmed down, without telling anyone about the work done.
It took about 10 hours before the messages from users began to arrive that the database was slow and some operations did not go through at all. Our experts began to understand and found out that there are no files.
There was no point in switching to the backup site, because synchronous replication worked at the array level. All changes that were made on one side, instantly reflected on the other. That is, there was no data either on the main site or on the backup one.
An engineer from a suicide or a Lynch trial saved the experience of our employees. The fact is that the database files were located in the vxfs cross-platform file system. Due to the fact that no one had previously stopped the work of the database, the inode of the deleted files was not transferred to the freelist, they were not used by anyone yet. If you install an application and “release” these files, the file system will finish the “dirty business”, mark the blocks that were occupied by the data as free, and any application that requests additional space will be able to safely overwrite them.
To save the day, we broke replication on the go. This did not allow the file system on the remote node to synchronize the release of blocks. Then, using the file system debugger, we ran through the latest changes, found out which inodes corresponded to which files, reassociated them, made sure that the database files appeared again, and checked the database consistency.
Then they offered the customer to pick up an instance of the database in standby mode on the recovered files and thus synchronize the data on the backup site without losing the online data. When all this was done, we managed to switch to a backup site without loss.
According to all calculations, the primary recovery plan with the help of IBS could stretch up to a week. In this case, the cost of degradation of the service, and not its complete inaccessibility. A human error could result in financial and reputational losses, including loss of business.
Then our engineers came up with a solution. In 90% of customer systems, Oracle databases are running. We proposed to leave the old reservation system, but supplement it with a reservation system at the application level. That is, to synchronous replication by means of arrays, they also added software - by means of Oracle Data Guard. Its only drawback is that after failover, a number of activities need to be done, automating which is problematic. To avoid them, we implemented switching instances between sites using cluster software with the replacement of database configs.
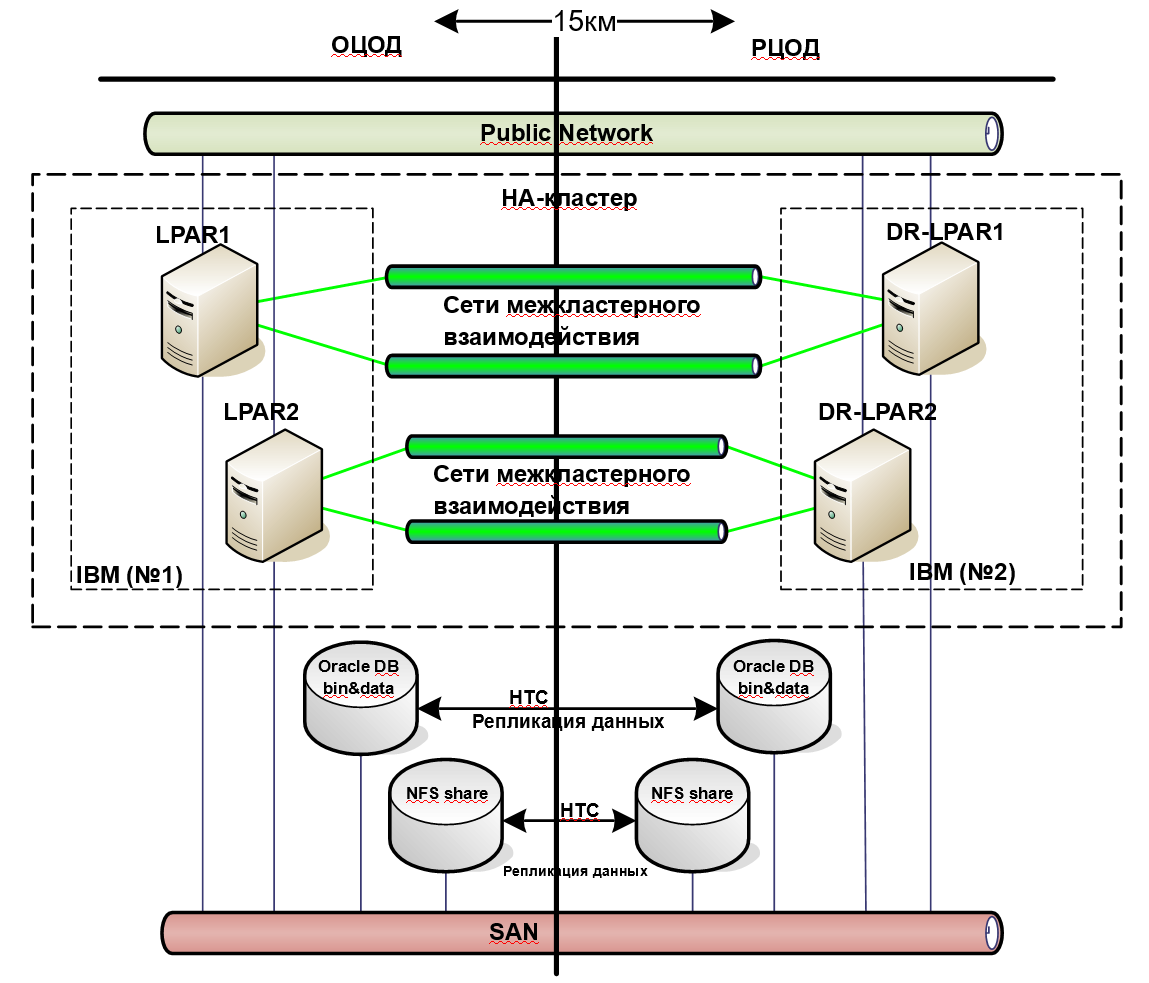
The result is an additional level of data protection. In addition, the new backup system helped reduce the requirements for arrays, so the customer saved money by switching from Hi-End-level arrays to mid-level data storage systems.
Here is such a happy end.
Enterprise Support Team, Jet Infosystems
Source: https://habr.com/ru/post/343112/
All Articles