First HighLoad Cup: how we survived
Hello! Not so long ago ended HighLoad Cup . Many participants received a lot of questions about the organization of the champ from the inside. We, the team of development of championships and educational projects of Mail.Ru Group, in this article will tell about the device of a champ, about internal mechanics and a little about the history of the first HighLoad Cup!

First of all, on behalf of the developers, we thank all the participants of the championship. Yes, it was three weeks zhegova not only for you. Several nights were spent in the DC, a few weekends - in the office. The fire! Thanks you!
The idea of the championship came from life, from everyday life. Most of our (our) web-products - public "public" projects. Their life on the Internet is somewhat different from their life on the developer’s computer. That search engine, then visitors crowd.
When developing the server part of the application, one has to work out the speed of the application. It happens that something is overlooked, and the project is at the limit of server capacity (or outside). Throwing a badly written application with expensive equipment is how to treat a healthy, not the best solution. The right decision is to write the application correctly, correctly implement the architecture and backend.
We hold Russian Code Cup, MLBootCamp, Russian Ai Cup, Russian Design Cup and a number of other championships. Everything about them is good, except that the real life of a real backend developer is not enough. In the HighLoad Cup, we tried to bring this reality of development to the masses.
How does all this work?
The main question in the development of the championship was: where and how to turn the decision? We considered several options:
- The participant himself finds iron.
- We provide a virtual user with full access.
- We scroll git and ask to write a script that will launch the solution.
- Docker.
- Vagrant.
- Ejudge
- Member provides a KVM or VirtualBox image.
- Derivatives from versions 1-7 and their combinations.
When considering the implementation of the key were two points:
- Same conditions for all participants.
- Security.
It is impossible that the result is dependent on iron. In our case, it turns out, it was necessary to turn all the solutions on absolutely identical machines. Better on one, but it is enough for 48 decisions (participants) per day. Therefore, we need a fleet of identical cars.
Yes, they chose Docker. As a compromise between performance, simplicity and convenience, while ensuring safety. Variations without a docker got fewer votes at the developers' council. Either they did not meet the conditions, or they demanded great efforts for implementation, or they were excessively complex. Although the docker itself is not very transparent: the three options of the docker compose config are already worth something.
The architecture is as follows:
- Site. Web application. Gives you (visitors) a page.
- Storage. Based on docker-registry + special proxy server.
- Runner. Special washing machines include containers with Tank.
- Hub An application that implements all the mechanics. The site looks into the hub. The hub looks into the stack and runners. It starts what you need where it is necessary and gives the results to the site.
Least of all questions with the site. Registration, authorization, challenge, round. Everything is standard and typical.
Storage. The Docker-registry out of the box works well, but it does not implement the delimitation of access and limits on the amount of storage. Run it unlimited cool, but we can not afford it. The decisions of one participant should not be available to others. We have developed a proxy for storazhu to control access and the limit on storage volumes.
Hub Actually, this component steers everything that happens. Starting from the formation of a queue for "shelling" and ending with the processing of results. She knows about all the runners, calls on them to run the test and for the results. Gives them to the site at his request.
Runners. Here is the launch of everything together, the collection and processing of results, their temporary storage. Separate cars, the same up to the chassis vendor, cut off from the whole world and working in one direction. Yes, requests can only be to them and only from the hub. B - security. Single components run in duplicate with database replication and apload. O - fault tolerance. Runners in the initial configuration - two.
Now more.
On the development side, runners are a set of servers interacting with the “hub” via JSON and with the docker registry. According to hub commands, a set of servers forms a docker-compose and launches the required tank-solution pairs, processes and stores the result, provides it on demand. Our task is to provide the same conditions for all. Same and good enough for the highload. For this we:
- disable Intel TurboBoost;
- we fix the processor frequencies just below the nominal values;
- nailing processes (vcpupin) to the physical nuclei, separating the tank from the solution;
- we allocate a separate partition on the disk to expand the containers;
- tyunim sysctl, ulimit;
- To heighten fenshui, we fix processes to numanodes.
These measures together provide greater stability, greater productivity and less jitter in the shelling results.
Deploying and testing this complex, we decided to wrap it all in a KVM container. This gives the following profits:
A. Be on the safe side in case of kernel panic (virtualku reboot, but not host), attempts to flash bios, hardware, attempts to change something on the host, etc.
B. Limit the disk by read and write kbps. There are no two identical disks. They always work differently. To ensure consistency, you can use the iotune limits of virtual disks.
B. Quickly transfer, transfer or incline container.
D. Additionally, from above, limit the network on the host machine.
The benefits of such a decision are infrastructural. It does not give any additional advantages to the participants, and for operation it simplifies a number of questions. An overhead of kvm-virtualization for our case is not a loss: the main thing is that the conditions are the same.
In docker containers, they also made an un-privileged REMAP. You do not run a web server with root rights, right?
Time to develop slowly but surely ended. We didn’t know at all what interest in the championship there would be and whether it was necessary to spend more energy on it. Tasks, in addition to this championship, the car and a small truck. We decided to launch it. Launched the first trial. We will try quietly. MVP is ready. Works. Let's try, but we'll see. Maybe all this is in vain and uninteresting?
Go.
We prepare a simple task, some data. Data generator. Announce, do a couple of posts. We look at the empty rating. We are experiencing. We love to monitor everything. From voltages in sockets to smartctl parameters. That was the day of the announcement.

Yielding to doubts that “something has broken,” we push our decision, we see it in the top and we are afraid that it will win. We are experiencing again. The first participants appear. Rejoice! But our solution is still in the top. Still experiencing.
We didn’t have long to worry about “not take off”. Since the technologies are relatively non-standard for the IT-championship, the participants began to actively try test runs. Ratings are limited to one per day and take half an hour, and test ones are not limited in any way. It is somehow unfair to limit them.
A queue of test runs formed. Two runners began to be missed. Already in the morning of the next day we were looking for equipment to deploy more runners, in the evening of the next day we sat in the DC and set up two new cars, trying not to miss anything from the fine settings of each. Four cars in service. While we set up the above two, it became clear that no less than eight of them needed exactly.
The place in the storehouse ends. 200 GB should have been enough for 40 planned participants in the estimated conditions. Participants in the first five days came ten times more. But everything is worse, almost before the launch, the conditions changed: the number of requests to the solution and the amount of data were increased. We understand that we need a couple of terabytes, we order. In the meantime, the storage space for the results flowed. We are dumping a bit out of stock, but this is not enough for long.

Modest virtualka site begins to smoke, throws non-stop on the process. In the meantime, we get discs under stand. For a hot change at all. Not provided. No slots. We are preparing a new car, asking for half an hour downtime and pouring.
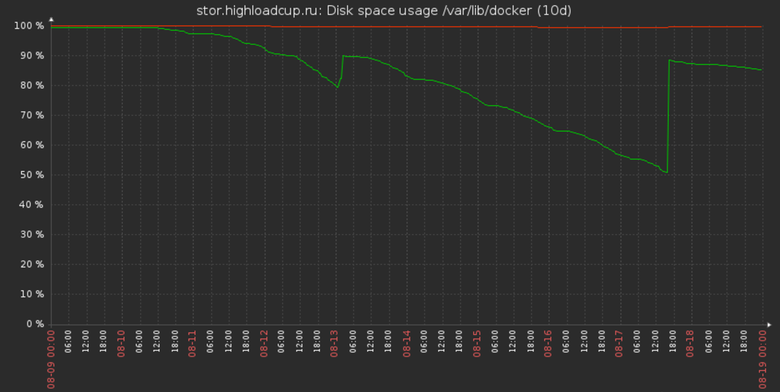
Participants are asking for more data. Like, yes. There is only 20 MB. Well this is about anything. Need 1 GB. It sounds easy. In fact, this is a hundredfold increase in both the resources required for processing and the space for storing the results.
We understand that eight runners are not enough. We are looking for more. We remove four cars from another project in exactly the same configuration and we coax them. Twelve runners. Everything. There are no more such cars.
Several times we find ourselves on the brink of a foul. Several times we are saved on the go. And the participants more and more.
Peaks
It seems that this is the most frequent word in the championship chat. It would be possible not to attach importance to them. This may well be due to the application implementation curve. That GC, for example. Meanwhile, the RPSs have reached 10K values, and at such speeds any sneeze in the system can lead to microbursts in the operation of applications. Peaks were almost all.
At this stage, we remembered (in fact, participants suggested to us) about the architectural omission: the tank writes to the disk. He writes a lot. Disk operations performed by the tank itself are likely to cause the very sneezes in the system. What were the options to solve this? Move to RAM disk:
a) the entire runner disk;
b) the section where the tank writes.
First of all, on the test machine, we carried the entire runner disk into RAM. This ensured no disk operations, but most of the solutions in this configuration fell from OOM. We did not manage to find out the reasons. Memory was with a reserve. Probably, the decisions somehow referred to the total available memory on the machine, which became four times as large when the limit on the solution did not change. This could lead to erroneous consumption of memory by the solution and its subsequent OOM Kill.
In parallel, we conducted an experiment with the removal of the section with the tank in the RAM disk. He managed, the top 50 worked consistently. This was the solution. Such a move did not solve all the problems with peaks. They have become smaller, they have become less significant, but their presence is still being studied.
Meanwhile, the deadlines expire. In the top C / C ++ bicycles, phoned the eyes of PHP in the top 25, the final in a day, and we have not slept for three weeks.
The final
Initially, the final was planned as a regular round, launching each solution one by one and identifying the best. This did not guarantee justice: the same solution in different launches showed a run with a decent result. In order to honestly and fairly reveal the best solution, the method proposed by the participants themselves to hold the final: to get rid of all decisions many times (in waves). For the result we take the best (minimum) time. Thus we equalize the chances of each. Writing day, testing night. We start. It was the longest final among our championships. The decisions of the finalists were tested for a day and a half.
Summing up, we note:
- A number of mistakes in planning computational (iron) resources made our life more fun. We have become a little more experienced.
- Peaks are inevitable on large RPS. It is necessary, of course, to level them.
- The original invented task was too simple. We think.
But, actually, that's all. Through the eyes of the development team it was three weeks of fierce hardcore. On behalf of the developers, I want to thank the participants! Without you, we would not get that much drive. We participated in the championship on the other side of the screen with you! Thanks you! For you tried Maxim xammi-1 Kislenko, Boris bkolganov Kolganov, Egor geoolekom Komarov, Ilya liofz Lebedev, Ilya sat2707 Stytsenko.

')
Source: https://habr.com/ru/post/343032/
All Articles