Apache Kafka and millions of messages per second

We in the company love and respect Apache Kafka, and to mark the release of its recent update, I decided to prepare an article about its performance. And also to tell a little about how to squeeze the maximum out of it.
Why do we need it?
The fact is that we are sometimes lucky to deal with high-loaded internal systems that automate the recruitment of our company. For example, one of them collects all the responses from most of the country's most well-known work sites, processes and sends it all to recruiters. And these are quite large data streams.
For everything to work, we need to exchange data between different applications. Moreover, the exchange should occur fairly quickly and without loss, because, ultimately, this translates into effective recruitment.
To solve this problem, we had to choose among several messages available on the broker market, and we settled on Apache Kafka. Why? Because it is fast and supports semantics of guaranteed only message delivery (exactly-once semantic). In our system, it is important that, in the event of a failure, messages are still delivered, and at the same time do not duplicate each other.
')
How things are arranged
Everything in Apache Kafka is built around the concept of logs. Not those logs that you put somewhere for reading by humans, but other, abstract logs. Logs, if you look wider, this is the simplest abstraction for storing information. This is a data queue that is sorted by time, and where data can only be added.
For Apache Kafka, all messages are logs. They are transmitted from the producers to the consumer via the Apache Kafka cluster. You can adapt the Apache Kafka cluster to your needs to improve performance. In addition to changing the settings of brokers (machines in a cluster), the settings can be changed from manufacturers and consumers. The article focuses on optimizing only manufacturers.
There are several important concepts that need to be understood in order to know what to tune and why:
No consumers - speed drops
If new messages are immediately taken away, they are saved to disk. And this is a very expensive operation. Therefore, if consumers suddenly shut down or “pledged”, the throughput rate will drop.The larger the message size, the higher the bandwidth.
The fact that it is much “easier” to write 1 file with a size of 100 bytes to a disk than 100 files with 1 byte. But Apache Kafka, if necessary, discards messages to disk. Interesting schedule from Linkedin: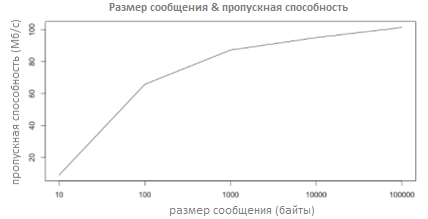
New producers / consumers almost linearly increase productivity
But do not forget about point number 1.Asynchronous replication can lose your data.
Unlike the synchronous replication mechanism, with asynchronous, the main node Apache Kafka does not wait for confirmation of receipt of the message from the child nodes. And if the master node fails, the data may be lost. So you have to decide - either speed or vitality.
About manufacturers parameters
Here are the basic configuration parameters of manufacturers that affect their work:
- Batch.size
The size of the message packet that is sent from the manufacturer to the broker. Manufacturers are able to collect these “packs“ in order not to send messages one by one, because they can be quite small. In general, the larger this parameter is, the:- (Plus) More compression, which means higher throughput.
- (Minus) Longer delay in general.
- Linger.ms
The default is 0. Usually, the producer starts collecting the next batch of messages immediately after the previous one is sent. The linger.ms parameter tells the producer how long to wait, starting with the previous package sending and until the next moment when the new package (batch) is packaged. - Compression.type
Algorithm for compressing messages (lzip, gzip, etc). This parameter has a profound effect on latency. - Max.in.flight.requests.per.connection
If this parameter is greater than 1, then we are in the so-called “pipeline” mode. This is what this generally leads to.- (Plus) Better bandwidth.
- (Minus) The possibility of violation of the order of messages in case of failure.
- Acks
Affects the "vitality" of messages in the event of a failure of something. It can take four parameters: -1, 0, 1, all (the same as -1). The table below details how and what it affects: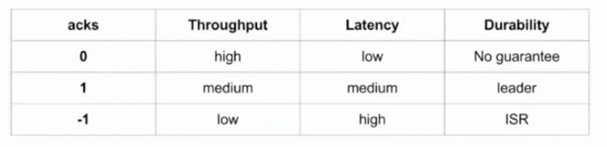
How to make the most
So, you want to tweak the parameters of the manufacturer and thereby speed up the system. Acceleration is understood as an increase in throughput and a decrease in delay. At the same time, “vitality” and the order of messages in case of failure should remain
Take for granted that you have already determined the type of messages that you send from the manufacturer to the consumer. So, its size is approximately known. We take as an example messages in the size of 100 bytes.
You can understand what “plug-in” is using the file bin \ windows \ kafka-producer-perf-test.bat. This is quite a flexible tool for profiling Apache Kafka, and I used it to build graphs. And if you patch it (git pull github.com/becketqin/kafka KAFKA-3554), you can set two additional parameters in it: --num-threads (number of producer threads) and --value-bound (random number range for compressor load).
There are two options for what can be changed in manufacturers to speed things up:
- Find the optimal batch size (batch.size).
- Increase the number of manufacturers and the number of sections in the topic (partitions).
We reproduced it all in our house. And that's what happened:
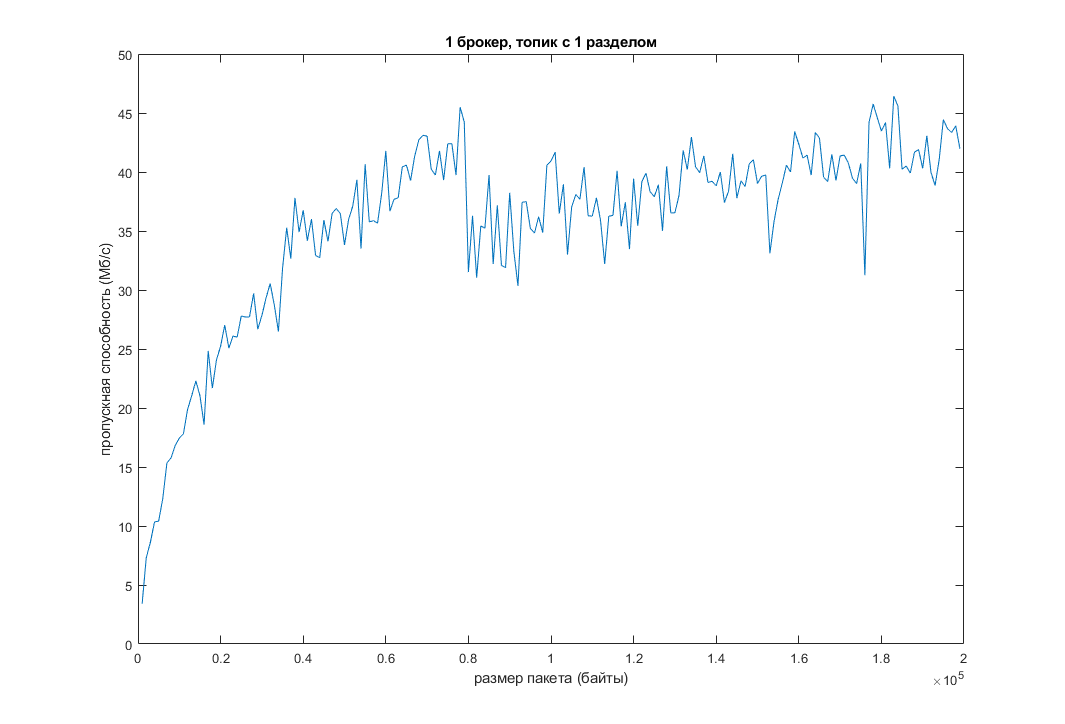

As you can see, with an increase in the default packet size, the throughput increases and the latency decreases. But there is a limit to everything. In my case, when the packet size exceeded 200 KB, the function almost went down:


Another option is to increase the number of sections in the topic while increasing the number of threads. Let's carry out the same tests, but with already 16 sections in the topic and 3 different values –num-threads (theoretically, this should increase efficiency):


The bandwidth is slightly raised, and the delay is slightly reduced. It can be seen that with a further increase in the number of threads, performance drops due to the costs of the context switching time between threads. On another machine, the schedule, of course, will be slightly different, but the overall picture most likely will not change.
Conclusion
This article examined the basic settings of manufacturers, by changing which you can achieve an increase in productivity. It was also demonstrated how changing these parameters affects throughput and latency. I hope my little research in this matter will help you and thank you for your attention.
References
Source: https://habr.com/ru/post/342892/
All Articles