Cutting hippo. Again about design and refactoring from Sandy Metz
Hi, Habr!
We’ve finished with an order for the second-hand book " Ruby. Object-Oriented Design " by Sandy Metz, which we hope to update next year. In the meantime, we have seen that Ms. Metz’s readers are much interested in her views on the PLO, and not only on the PLO in Ruby, therefore we offer a translation of her September article with a large number of pictures and a considerable number of interesting conclusions on the stated topic. Enjoy reading!
Hello!
It happens, I think about how applications develop, and what to do if we are not satisfied with the results. At the same time, I ponder three clearly diverse ideas. In this post I will outline all three and combine them. I hope that, having understood these interrelations, we will better understand our applications.
')
These thoughts are my personal opinion, based only on my own experience. Your opinion may differ, but I hope that I will give you some food for thought. Below - a lot of pictures. Imagine me drawing them directly on a whiteboard in front of you.
The first idea belongs to Martin Fowler and is called “ Design Stamina Hypothesis ” (architecture stability hypothesis).
Fowler illustrates this idea with the following pseudo-scheme.

Fig. one
On the vertical axis is accumulated functionality. The higher the line graph - the more we managed to do. The time spent on the horizontal axis is delayed. The farther to the right - the later.
In the coordinate grid drawn two different graphs. The orange line shows how much functionality we will produce to any point in time, if we begin to engage in design from the first day of work. The blue line shows what the result will be if we ignore the serious design. Please note: in the first stage, the blue line grows quite quickly, but in the end the orange line overtakes it.
According to the architecture sustainability hypothesis, at the early stage of the project we manage to do more, if we don’t bother too much about architecture. However, if you do not engage in architecture at all, then sooner or later during the project a moment will come when it will be necessary to take up architecture for further development.
The next idea is related to the differences between procedural and object-oriented code.
Here we compare procedural and object-oriented code in the context of how convenient it is to modify and understand the code of the first and second paradigms. The following diagram shows the trade-offs that the first and second options require.

Fig. 2
The convenience of modifying the code is delayed along the vertical axis. The code that is easiest to change is at the bottom. The more difficult it is to change it - the higher it is.
On the horizontal axis is the clarity of the code. The most obvious code is on the left, the most difficult to read is on the right.
A simple procedure is just a list of steps. Simple procedures are easily comprehended and easily changed; they are located in the lower left quarter of this diagram. This sector is the cheapest and most efficient.
To solve some problems, a simple procedural code without unnecessary conditions and without duplication is optimally suited. What could be more budget? We write the code and immediately run.
However, over time the situation may change. A request for a new feature (feature request) will appear, for the fulfillment of which you will need to add conditional logic or duplicate elements of the solution in several places, which will lead us to the situation with Figure. 3
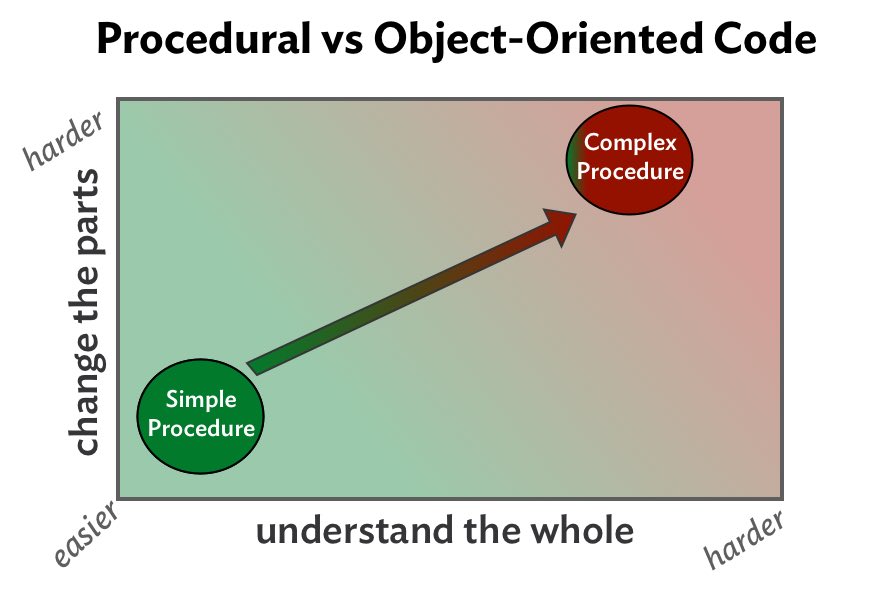
Fig. 3
The above shows how a cheap and effective procedure has become a complex, overgrown with conditions and doubles "quagmire"; Such code is difficult to understand and change.
Simple procedures are not burdensome, complex ones are expensive. The only compliment that can be weighed by a complex procedure (and it is really the only one) is to note that all this # $% @! the code is in the same place. However, compactness as such does not justify complexity. The code can be streamlined and more rational ways.
The following diagram takes into account the object-oriented code. Please note: An OO solution is a bit more expensive than a normal procedure, but it doesn’t compare in cost to a complex one.

Fig. four
In object-oriented solutions, small, interchangeable objects communicate with messages. Messages allow you to lay a kind of "seams", allowing you to replace existing objects with similar, performing the same role. Messaging makes it easier to modify behavior — to modify, you simply need to substitute new elements.
It is also important to note that messaging hides details of the result. From the point of view of the sender, the message merely describes the intention. The recipient of the message provides an implementation that is not known to the sender. Thus, with the help of messages, local replaceability is easily ensured, albeit by hiding the remote implementation from the sender.
With regard to complex procedures, the OO approach is clearer and more convenient with changes. In the case of simple procedures, the OO code is just as convenient to change, but on the whole, it may well be more difficult to understand it.
So, OO is not an indisputable and not a win-win option. It all depends on the complexity of your task and how durable your application should be.
Now, referring to the durability, consider the latest idea - code plowing (churn).
An overview of the idea of "plowing" is given in Michael Feathers' article, Getting Empirical about Refactoring . Plowing is a characteristic that allows you to assess how often a file changes.
The phenomenon of "plowing" is interesting in itself, but it is even more useful to consider it in the context of "complexity". The Fizers article has the following scheme, to which I added a green curve.
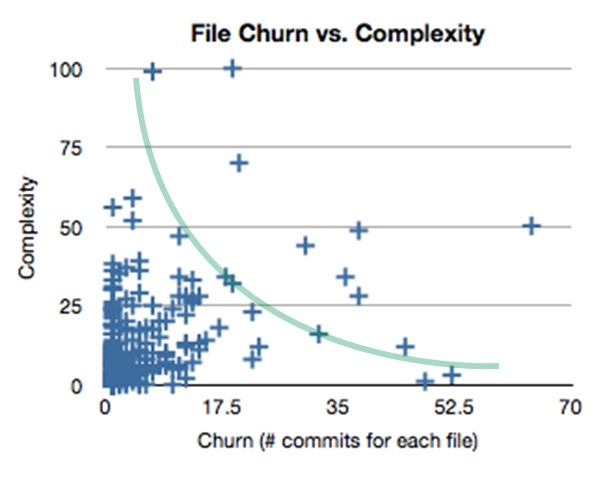
Fig. five
In this figure, the tillage rate is plotted horizontally, and the complexity of the code vertically.
Complex code, which is rarely changed, is localized in the upper left quarter of this scheme. Yes, the complexity of no one likes, but if the code does not change, then we do not cost anything to keep it complicated. Imagine that the code is a cabinet full of stacks of plastic dishes. It is enough to open the door - and everything will pour out. You can forget about the code from this segment until the revision is lit.
Simple code, which is changed very often, refers to the lower right quarter. If the code is straightforward (as, for example, the code in the configuration file), then changing it is easy. As long as the code remains simple, it can be changed as needed, as often as desired.
In the lower left quarter there is a code that is not too complicated and does not change so often - that is, it is already organized efficiently, and you can also ignore it.
The green curve starts from the left upper quarter, passes through the lower left and then to the lower right. It is desirable that the code in our applications should be concentrated along this curve. Please note: the curve does not go into the upper right quarter.
The upper right quarter is complex code that changes frequently. By definition, such a code will be difficult to understand and inconvenient to change. It is better that this quarter is empty, and if some code gets there, then it urgently needs refactoring.
Now that we have looked at these ideas in a general context, I will tell you, building on them, how the application can evolve in a vicious direction.
The code develops predictably, turning into a jumble
There is a characteristic “code-hash” that comes across to me again and again. I propose several schemes from the Code Climate website, illustrating, with examples of several projects, the characteristic symptoms of code turning into just such a jumble (as of September 7, 2017).

Fig. 6

Fig. 7

Fig. eight
The above schemes are "Plowing vs. Quality ”compiled on the Code Climate website based on the Fiecher’s idea“ Revision of file vs. complexity". Pay attention: on all schemes the points are concentrated along curves resembling the green curve from fig. 6. This is good. I praise the developers - in most of these applications, complex code almost does not change, most changes are made to simple code.
However, in all these schemes there is also an undesirable "periphery" - a code located in the upper right quarter. I did not see the source code of these applications, but on the basis of these schemes alone I can assume something about the classes that are on this periphery. I think they are:
If you want - you can see for yourself. If you click on each of the above schemes, the corresponding application page on the Code Climate opens. Once there, click on the peripheral point - and a link to the corresponding code opens. As I have already said, in essence, I do not know these applications, but ... I am sure that, based on their size, complexity and rates of plowing, in this case I can’t be wrong. If the scheme changes by the time you read this article, just skip this example;) and believe that the principle works.
Such a structure can be traced in many applications. Most of the code in the application is understandable, and changing such a code is easy. But in the application there will definitely be several large, complex and constantly plowed classes - it is in these classes that the extremely important ideas of the subject area are expressed.
The work on these peripheral classes is hated by everyone. Touch - immediately break. Tests do not guarantee safety. No action helps. In spite of all the efforts, the classes will thump in the eyes and become more complex. It was bad - it gets worse.
How does this happen?
You can explain the problem by using the three ideas above. And if the problem is clear - then there is hope to prevent it.
I affirm:
This is how applications turn out, in which a multitude of small effective classes coexist with an expensive and cumbersome hippopotamus, stuffed with conventional structures. A series of small and innocuous corrections in the most important code of your application make this code into such a complex class that no one can fix this problem. The problem is clearly manifested in paragraph 15 of the above list, but rooted in paragraph 8, when the complexity gradually increases until all the logic passes the point of no return.
To cling to a procedural code for a long time is just as harmful as it is too early to start design. If important classes in your subject area change frequently, while constantly increasing and overgrowing with conditional constructions, then immediately stop such development. Implement changes in the form of small, well-designed classes that interact with an existing object.
The 5,000 line class is so overwhelming that it becomes difficult to imagine how, in this case, to write a set of ten-line auxiliary classes that would satisfy the new requirements. In any case, write new classes. In order for the peripheral classes to pull themselves up to the green line again, do not be tempted to shove even more code into objects that are already huge. Create small objects, and over time large ones will disappear.
We’ve finished with an order for the second-hand book " Ruby. Object-Oriented Design " by Sandy Metz, which we hope to update next year. In the meantime, we have seen that Ms. Metz’s readers are much interested in her views on the PLO, and not only on the PLO in Ruby, therefore we offer a translation of her September article with a large number of pictures and a considerable number of interesting conclusions on the stated topic. Enjoy reading!
Hello!
It happens, I think about how applications develop, and what to do if we are not satisfied with the results. At the same time, I ponder three clearly diverse ideas. In this post I will outline all three and combine them. I hope that, having understood these interrelations, we will better understand our applications.
')
These thoughts are my personal opinion, based only on my own experience. Your opinion may differ, but I hope that I will give you some food for thought. Below - a lot of pictures. Imagine me drawing them directly on a whiteboard in front of you.
The first idea belongs to Martin Fowler and is called “ Design Stamina Hypothesis ” (architecture stability hypothesis).
# 1: Architectural Sustainability Hypothesis
Fowler illustrates this idea with the following pseudo-scheme.
Fig. one
On the vertical axis is accumulated functionality. The higher the line graph - the more we managed to do. The time spent on the horizontal axis is delayed. The farther to the right - the later.
In the coordinate grid drawn two different graphs. The orange line shows how much functionality we will produce to any point in time, if we begin to engage in design from the first day of work. The blue line shows what the result will be if we ignore the serious design. Please note: in the first stage, the blue line grows quite quickly, but in the end the orange line overtakes it.
According to the architecture sustainability hypothesis, at the early stage of the project we manage to do more, if we don’t bother too much about architecture. However, if you do not engage in architecture at all, then sooner or later during the project a moment will come when it will be necessary to take up architecture for further development.
The next idea is related to the differences between procedural and object-oriented code.
# 2: Comparison of procedural and object-oriented code
Here we compare procedural and object-oriented code in the context of how convenient it is to modify and understand the code of the first and second paradigms. The following diagram shows the trade-offs that the first and second options require.
Fig. 2
The convenience of modifying the code is delayed along the vertical axis. The code that is easiest to change is at the bottom. The more difficult it is to change it - the higher it is.
On the horizontal axis is the clarity of the code. The most obvious code is on the left, the most difficult to read is on the right.
A simple procedure is just a list of steps. Simple procedures are easily comprehended and easily changed; they are located in the lower left quarter of this diagram. This sector is the cheapest and most efficient.
To solve some problems, a simple procedural code without unnecessary conditions and without duplication is optimally suited. What could be more budget? We write the code and immediately run.
However, over time the situation may change. A request for a new feature (feature request) will appear, for the fulfillment of which you will need to add conditional logic or duplicate elements of the solution in several places, which will lead us to the situation with Figure. 3
Fig. 3
The above shows how a cheap and effective procedure has become a complex, overgrown with conditions and doubles "quagmire"; Such code is difficult to understand and change.
Simple procedures are not burdensome, complex ones are expensive. The only compliment that can be weighed by a complex procedure (and it is really the only one) is to note that all this # $% @! the code is in the same place. However, compactness as such does not justify complexity. The code can be streamlined and more rational ways.
The following diagram takes into account the object-oriented code. Please note: An OO solution is a bit more expensive than a normal procedure, but it doesn’t compare in cost to a complex one.
Fig. four
In object-oriented solutions, small, interchangeable objects communicate with messages. Messages allow you to lay a kind of "seams", allowing you to replace existing objects with similar, performing the same role. Messaging makes it easier to modify behavior — to modify, you simply need to substitute new elements.
It is also important to note that messaging hides details of the result. From the point of view of the sender, the message merely describes the intention. The recipient of the message provides an implementation that is not known to the sender. Thus, with the help of messages, local replaceability is easily ensured, albeit by hiding the remote implementation from the sender.
With regard to complex procedures, the OO approach is clearer and more convenient with changes. In the case of simple procedures, the OO code is just as convenient to change, but on the whole, it may well be more difficult to understand it.
So, OO is not an indisputable and not a win-win option. It all depends on the complexity of your task and how durable your application should be.
Now, referring to the durability, consider the latest idea - code plowing (churn).
# 3: Code Breaking and Difficulty
An overview of the idea of "plowing" is given in Michael Feathers' article, Getting Empirical about Refactoring . Plowing is a characteristic that allows you to assess how often a file changes.
The phenomenon of "plowing" is interesting in itself, but it is even more useful to consider it in the context of "complexity". The Fizers article has the following scheme, to which I added a green curve.
Fig. five
In this figure, the tillage rate is plotted horizontally, and the complexity of the code vertically.
Complex code, which is rarely changed, is localized in the upper left quarter of this scheme. Yes, the complexity of no one likes, but if the code does not change, then we do not cost anything to keep it complicated. Imagine that the code is a cabinet full of stacks of plastic dishes. It is enough to open the door - and everything will pour out. You can forget about the code from this segment until the revision is lit.
Simple code, which is changed very often, refers to the lower right quarter. If the code is straightforward (as, for example, the code in the configuration file), then changing it is easy. As long as the code remains simple, it can be changed as needed, as often as desired.
In the lower left quarter there is a code that is not too complicated and does not change so often - that is, it is already organized efficiently, and you can also ignore it.
The green curve starts from the left upper quarter, passes through the lower left and then to the lower right. It is desirable that the code in our applications should be concentrated along this curve. Please note: the curve does not go into the upper right quarter.
The upper right quarter is complex code that changes frequently. By definition, such a code will be difficult to understand and inconvenient to change. It is better that this quarter is empty, and if some code gets there, then it urgently needs refactoring.
Now that we have looked at these ideas in a general context, I will tell you, building on them, how the application can evolve in a vicious direction.
The code develops predictably, turning into a jumble
There is a characteristic “code-hash” that comes across to me again and again. I propose several schemes from the Code Climate website, illustrating, with examples of several projects, the characteristic symptoms of code turning into just such a jumble (as of September 7, 2017).
Fig. 6
Fig. 7
Fig. eight
The above schemes are "Plowing vs. Quality ”compiled on the Code Climate website based on the Fiecher’s idea“ Revision of file vs. complexity". Pay attention: on all schemes the points are concentrated along curves resembling the green curve from fig. 6. This is good. I praise the developers - in most of these applications, complex code almost does not change, most changes are made to simple code.
However, in all these schemes there is also an undesirable "periphery" - a code located in the upper right quarter. I did not see the source code of these applications, but on the basis of these schemes alone I can assume something about the classes that are on this periphery. I think they are:
- Larger than most other classes
- Loaded with conditional constructions and
- Describe the basic concepts of the domain
If you want - you can see for yourself. If you click on each of the above schemes, the corresponding application page on the Code Climate opens. Once there, click on the peripheral point - and a link to the corresponding code opens. As I have already said, in essence, I do not know these applications, but ... I am sure that, based on their size, complexity and rates of plowing, in this case I can’t be wrong. If the scheme changes by the time you read this article, just skip this example;) and believe that the principle works.
Such a structure can be traced in many applications. Most of the code in the application is understandable, and changing such a code is easy. But in the application there will definitely be several large, complex and constantly plowed classes - it is in these classes that the extremely important ideas of the subject area are expressed.
The work on these peripheral classes is hated by everyone. Touch - immediately break. Tests do not guarantee safety. No action helps. In spite of all the efforts, the classes will thump in the eyes and become more complex. It was bad - it gets worse.
How does this happen?
You can explain the problem by using the three ideas above. And if the problem is clear - then there is hope to prevent it.
I affirm:
- Premature design work is a waste.
(Fig. 1 - orange line in the early stages) - If you do not do design at all, the code will turn into a terrible mess.
(Fig. 1 - blue line in the later stages) - At a certain stage you will need to invest in the design, it will save you money
(Fig. 1 - the point of intersection of two lines) - Simple procedures almost do not require design, they are easy to maintain.
(Fig. 2, Fig. 1: the beginning of the blue line) - The procedures become more complicated with time and it becomes more expensive to maintain them.
(Fig. 3, Fig. 1: the blue line in the later stages) - From an economic point of view, an object-oriented code is more profitable than a complex procedural code.
(Fig. 4) - Those procedures that are most important for your subject area change more often than non-specific procedures.
- Those procedures that are most important for your subject area are complicated more quickly than the rest of the code.
- It's hard to catch the moment when your application crosses the line of “design expediency”
(Fig. 1) - 10. You will understand that this line is behind when the pace of development slows down and problems begin to grow.
(Fig. 1 - part of the blue line, located under the line of design expediency) - By the time you understand this, the most important code will already be in the most neglected form.
- Moderately complex procedures are easy to convert to OO.
- Exceptionally complex procedures are the most difficult to translate into OO.
- Attempts to convert moderately complex procedures to OO are usually successful.
- Attempts to convert extremely complex procedures in OO often fail.
This is how applications turn out, in which a multitude of small effective classes coexist with an expensive and cumbersome hippopotamus, stuffed with conventional structures. A series of small and innocuous corrections in the most important code of your application make this code into such a complex class that no one can fix this problem. The problem is clearly manifested in paragraph 15 of the above list, but rooted in paragraph 8, when the complexity gradually increases until all the logic passes the point of no return.
To cling to a procedural code for a long time is just as harmful as it is too early to start design. If important classes in your subject area change frequently, while constantly increasing and overgrowing with conditional constructions, then immediately stop such development. Implement changes in the form of small, well-designed classes that interact with an existing object.
The 5,000 line class is so overwhelming that it becomes difficult to imagine how, in this case, to write a set of ten-line auxiliary classes that would satisfy the new requirements. In any case, write new classes. In order for the peripheral classes to pull themselves up to the green line again, do not be tempted to shove even more code into objects that are already huge. Create small objects, and over time large ones will disappear.
Source: https://habr.com/ru/post/342810/
All Articles