Hello Logify, or monitor errors on installed applications
As you know, there are no programs without errors, and there are a lot of tools and approaches designed to improve the quality of the produced applications, from unit tests to code analyzers. However, even if you use all of them simultaneously, no one will guarantee that your applications are free from any errors. And if the problems arising during development and testing are visible to us immediately, or almost immediately, and we have the opportunity to get detailed information about what happened and quickly fix it, then the errors after the release occurring on the user side are more insidious.
The most important thing is that, most likely, they will not tell you about them. How often did you send errors to Microsoft when you were asked to do this? :) Users, as a rule, either just restart the application,swear and continue to use further, or delete it completely. If you are lucky, and they will tell you about the fall, it often looks like this:

')
and this brings absolutely no clarity to the understanding of the problem. As a result, users form a negative experience from using your program, and you have no way to do something about it.
Well, since there is no hope for users, you will have to take matters into your own hands. For a start, we know that we can handle all the exceptional situations in our programs. For example, in .NET we can hang the global handler of all the exceptions. The simplest thing you can do next is to write to the log all the exceptions that arrive in this handler. This is at least something.
However, it’s just that the log does not send itself, and we have to wait for a message from the user to find out about the problem and ask him to send this log, which is a waste of time, and indeed, the user may not write at all. As an option, we can send our log by e-mail, but it’s scary to imagine what our mailbox will turn into if we receive a sufficiently large number of alerts. And this is quite realistic on large projects. And in general, to disassemble what is written there in a text log file for 100,500 lines is not an entirely pleasant exercise.
As a result, we come to the fact that the most adequate solution is a service that will spin in the cloud and receive information about errors that have occurred, process it, structure it and show it to us via the web interface in a convenient form. Well, why don't we write such a service for ourselves?
Initially, we made a simple crash collector in our demos to get data about these crashes, and on their basis, fix problems in our components, thereby improving their quality. It was just the count stack and the module name of the demo, however, we quickly realized that this data was not enough and began to expand it. As a result, at the moment we collect very detailed information about the environment where the error occurred, starting with the list of loaded libraries and the version of the studio and framework, and ending with the version of the OS and the current culture. In this case, if we need, we can always add any additional information through the mechanism CustomData. For an example, you can look at the test report .
When there was enough information for finding problem areas, we were faced with the fact that sometimes there are a lot of reports. After all, if the problem is trivial enough, then it is likely that many users will come across it. And in this situation, we get a report from each of them. As a result, we have a bunch of reports that, if not identical, are extremely similar:
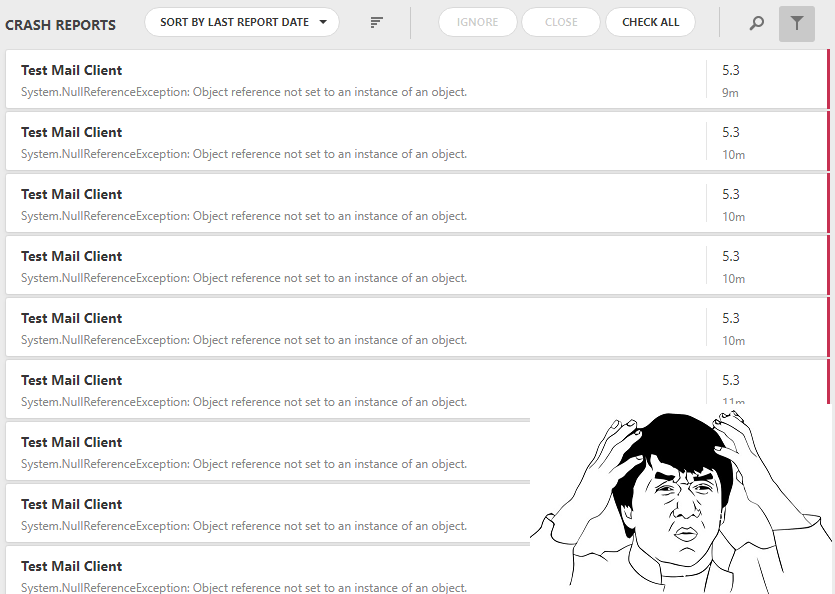
It is clear that to work with all this, to put it mildly, is difficult, plus, among all these identical reports, unique issues that alert to other problems may be lost. To get rid of this, we implemented a duplicate search for a specific set of key fields and collapse them into one report:
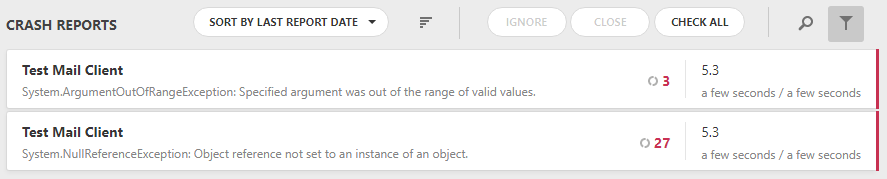
Yes, this is much better.
However, in addition to duplicates, there were quite a lot of reports in the inboxes that we are simply not interested in, for example, there may be reports on issues that have already been fixed. This pushed us to the task of implementing the automatic ignoring of incoming reports for any conditions, and they gave us a lot of conditions: so that the version can be ignored, and so that the keywords in the wrench, and so that certain lines of the warsaw, and that error without our We did not receive components in the copske, etc., etc. As a result, we identified 4 basic types of rules ignored, and this covered all our tasks. In general, this topic deserves a separate article, so here I will provide a link to the documentation, so that you can make a general impression about this mechanism: Ignoring Filters
In the process of working with the service, we found him another unusual application: he can perfectly help the support department. Often, users write that they have some kind of problem, but it is reproduced only on their user's machine, and there is no opportunity to podobazhit or get some detailed information about the error itself. Or, for example, errors occur on programs that are restricted in their rights and cannot record a log file. In all these situations, Logify helps us successfully, because collecting data on crashes on deployed applications is its main task.
As a result, Logify has been implemented in many of our products, and now brings tangible benefits. In the development process, Logify has clearly ceased to be just a project for internal use, and we decided to release it as a separate service. He was combed and presented to the public with a converted UI, first in the form of beta testing, and at the moment he is fully launched in production. So who are interested, I invite you to try: Logify . Clients are available on github .
The most important thing is that, most likely, they will not tell you about them. How often did you send errors to Microsoft when you were asked to do this? :) Users, as a rule, either just restart the application,
')
and this brings absolutely no clarity to the understanding of the problem. As a result, users form a negative experience from using your program, and you have no way to do something about it.
Well, since there is no hope for users, you will have to take matters into your own hands. For a start, we know that we can handle all the exceptional situations in our programs. For example, in .NET we can hang the global handler of all the exceptions. The simplest thing you can do next is to write to the log all the exceptions that arrive in this handler. This is at least something.
However, it’s just that the log does not send itself, and we have to wait for a message from the user to find out about the problem and ask him to send this log, which is a waste of time, and indeed, the user may not write at all. As an option, we can send our log by e-mail, but it’s scary to imagine what our mailbox will turn into if we receive a sufficiently large number of alerts. And this is quite realistic on large projects. And in general, to disassemble what is written there in a text log file for 100,500 lines is not an entirely pleasant exercise.
As a result, we come to the fact that the most adequate solution is a service that will spin in the cloud and receive information about errors that have occurred, process it, structure it and show it to us via the web interface in a convenient form. Well, why don't we write such a service for ourselves?
Initially, we made a simple crash collector in our demos to get data about these crashes, and on their basis, fix problems in our components, thereby improving their quality. It was just the count stack and the module name of the demo, however, we quickly realized that this data was not enough and began to expand it. As a result, at the moment we collect very detailed information about the environment where the error occurred, starting with the list of loaded libraries and the version of the studio and framework, and ending with the version of the OS and the current culture. In this case, if we need, we can always add any additional information through the mechanism CustomData. For an example, you can look at the test report .
When there was enough information for finding problem areas, we were faced with the fact that sometimes there are a lot of reports. After all, if the problem is trivial enough, then it is likely that many users will come across it. And in this situation, we get a report from each of them. As a result, we have a bunch of reports that, if not identical, are extremely similar:
It is clear that to work with all this, to put it mildly, is difficult, plus, among all these identical reports, unique issues that alert to other problems may be lost. To get rid of this, we implemented a duplicate search for a specific set of key fields and collapse them into one report:
Yes, this is much better.
However, in addition to duplicates, there were quite a lot of reports in the inboxes that we are simply not interested in, for example, there may be reports on issues that have already been fixed. This pushed us to the task of implementing the automatic ignoring of incoming reports for any conditions, and they gave us a lot of conditions: so that the version can be ignored, and so that the keywords in the wrench, and so that certain lines of the warsaw, and that error without our We did not receive components in the copske, etc., etc. As a result, we identified 4 basic types of rules ignored, and this covered all our tasks. In general, this topic deserves a separate article, so here I will provide a link to the documentation, so that you can make a general impression about this mechanism: Ignoring Filters
In the process of working with the service, we found him another unusual application: he can perfectly help the support department. Often, users write that they have some kind of problem, but it is reproduced only on their user's machine, and there is no opportunity to podobazhit or get some detailed information about the error itself. Or, for example, errors occur on programs that are restricted in their rights and cannot record a log file. In all these situations, Logify helps us successfully, because collecting data on crashes on deployed applications is its main task.
As a result, Logify has been implemented in many of our products, and now brings tangible benefits. In the development process, Logify has clearly ceased to be just a project for internal use, and we decided to release it as a separate service. He was combed and presented to the public with a converted UI, first in the form of beta testing, and at the moment he is fully launched in production. So who are interested, I invite you to try: Logify . Clients are available on github .
Source: https://habr.com/ru/post/342620/
All Articles