Rewrite the message database VKontakte from scratch and survive
Our users write each other messages without knowing fatigue.

This is quite a lot. If you set out to read all the messages of all users, it would take more than 150 thousand years. Provided that you are pretty pumped reader and spend on each message no more than a second.
With this amount of data, it is critical that the storage and access logic is optimally constructed. Otherwise, in one not so beautiful moment, it may turn out that soon everything will go wrong.
For us, this moment came a year and a half ago. How we came to this and what happened in the end - we tell in order.
')
In the very first implementation of the message VKontakte worked on a bunch of PHP-backend and MySQL. This is quite a normal solution for a small student site. However, this site was growing uncontrollably and began to demand to optimize data structures for themselves.
At the end of 2009, the first text-engine storage was written, and in 2010 messages were transferred to it.
The text-engine messages were stored lists - a kind of "mailboxes". Each such list is determined by the uid, the user-owner of all these messages. A message has a set of attributes: interlocutor ID, text, attachments, and so on. The message identifier inside the “box” is local_id, it never changes and is assigned sequentially to new messages. The “boxes” are independent and with each other inside the engine are not synchronized in any way, the connection between them takes place already at the PHP level. Look at the data structure and capabilities of the text-engine from the inside here .
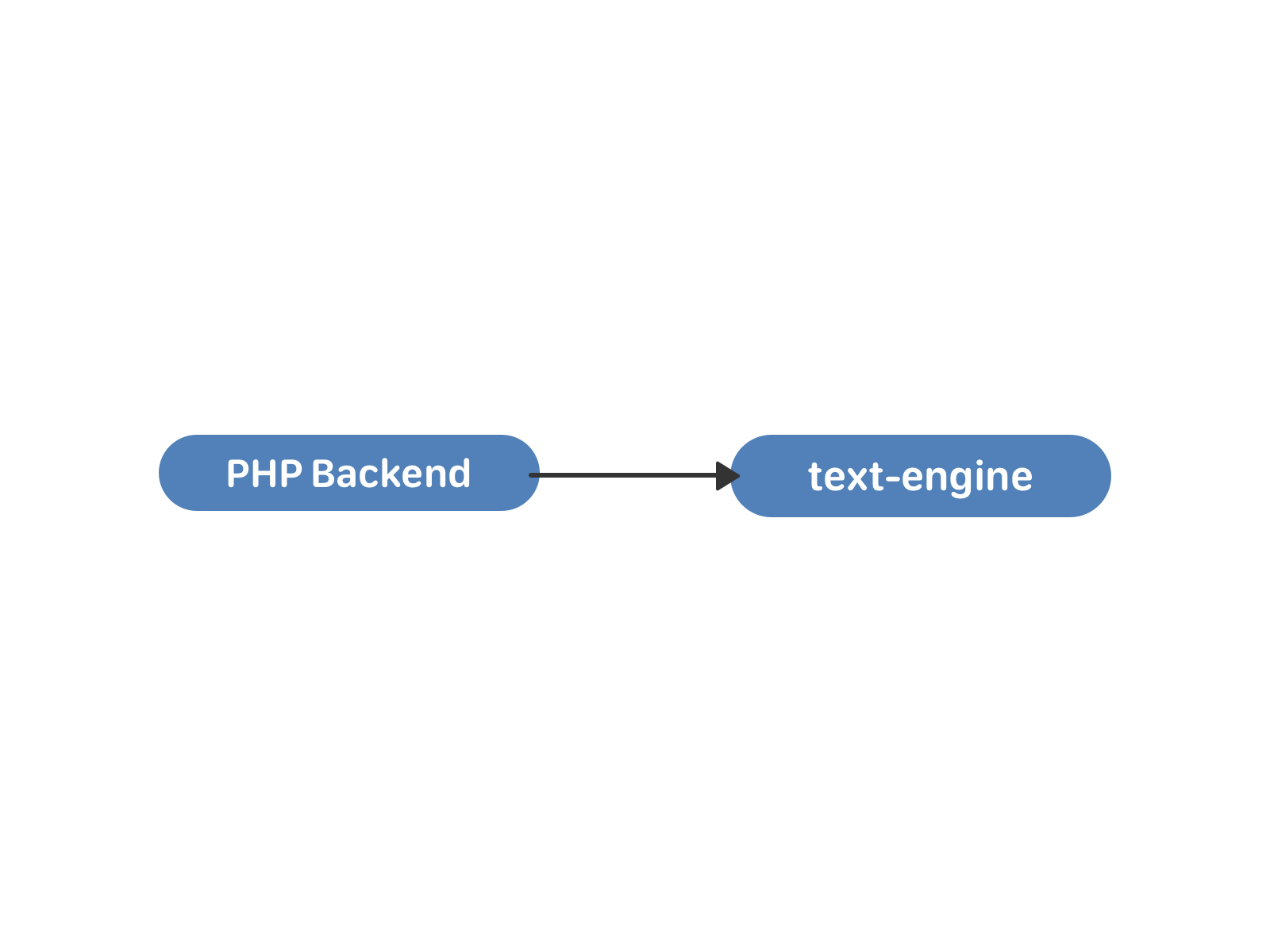
This was quite enough for the correspondence of two users. Guess what happened next?
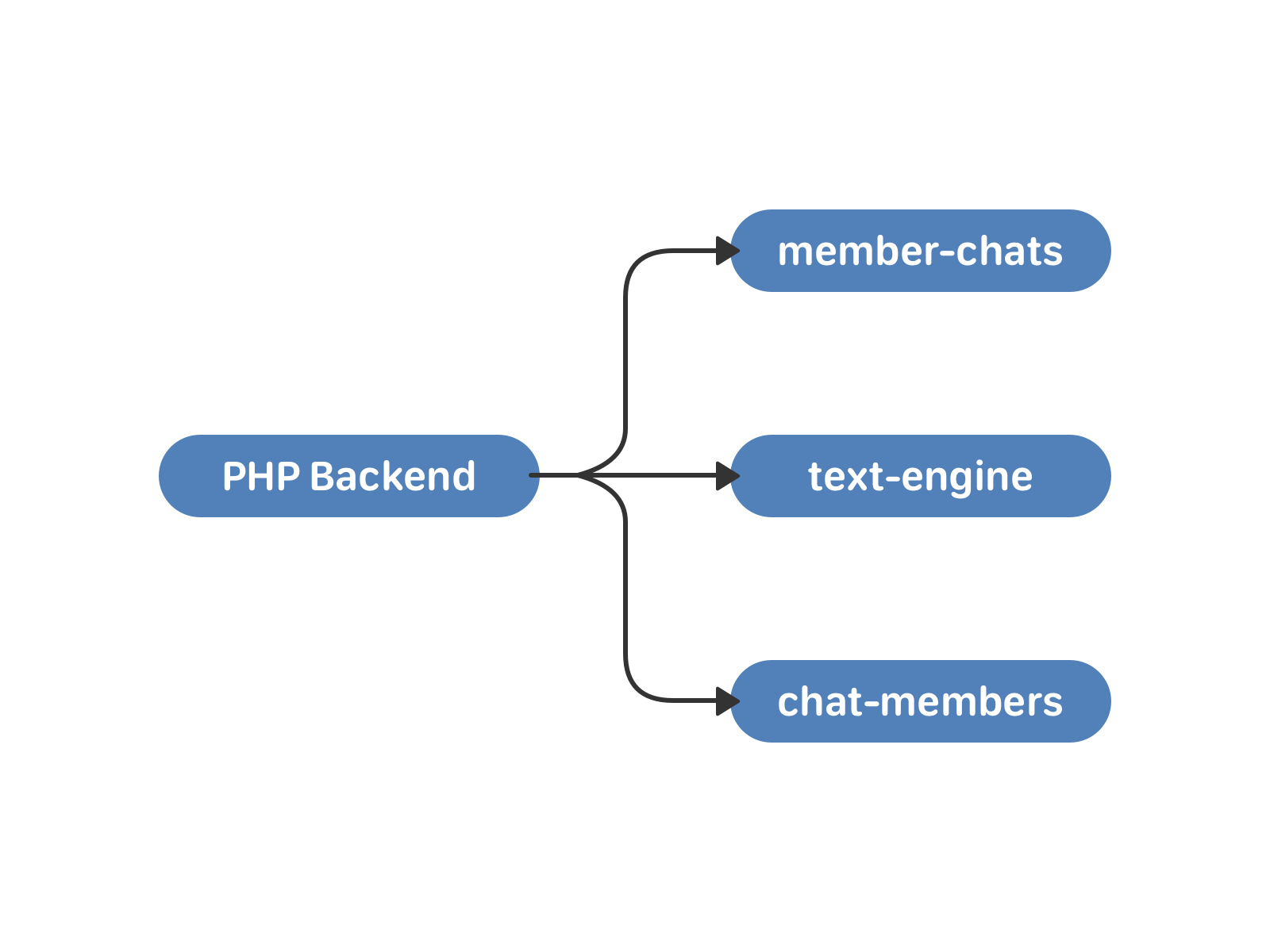
In May 2011, VKontakte appeared conversations with several participants - multi chat. To work with them, we raised two new clusters - member-chats and chat-members. The first one stores data about chats by users, the second one - data about users by chats. In addition to the lists themselves, this is, for example, the inviting user and the time of adding to the chat.
“PHP, let's send a message to the chat,” says the user.
“Come on, {username},” says PHP.
There are downsides to this scheme. Synchronization is still assigned to PHP. Big chats and users who simultaneously send messages to them is a dangerous story. Since the text-engine instance depends on the uid, the chat participants could receive the same message with a time difference. You could live with that if progress stood still. But do not happen this.
At the end of 2015, we launched community posts, and at the beginning of 2016, an API for them. With the advent of large chat bots in the communities, it was possible to forget about the even distribution of the load.
A good bot generates several million messages per day - even the most talkative users cannot boast of such. And this means that some text-engine instances, on which such bots lived, began to fall in full.
Message engines in 2016 are 100 instances of chat-members and member-chats, and 8000 text-engine. They were located on thousands of servers, each with 64 GB of memory. As a first emergency measure, we increased the memory by another 32 GB. Estimated predictions. Without fundamental changes, this would be enough for about a year. It is necessary either to get rich with iron, or to optimize the databases themselves.
Due to the nature of the architecture, it only makes sense to build up iron. That is, at least double the number of cars - obviously, this is quite an expensive way. We will optimize.
The central essence of the new approach is chat. The chat has a list of messages that relate to it. User has a chat list.
The required minimum is two new databases:

New clusters communicate with each other using TCP - this ensures that the order of the requests does not change. The requests and confirmations for them are written to the hard drive - so we can restore the queue status at any time after a failure or restart of the engine. Since the user-engine and chat-engine are 4,000 shards each, the queue of requests between the clusters will be evenly distributed (but in reality it is not at all - and it works very quickly).
Working with the disk in our databases in most cases is based on a combination of a binary change log (binlog), static images and a partial image in memory. Changes during the day are written in binlog, periodically a snapshot of the current state is created. A snapshot is a set of data structures optimized for our purposes. It consists of a header (meta-index snapshot) and a set of metafiles. The header is permanently stored in RAM and indicates where to look for data from the snapshot. Each metafile includes data that is likely to be needed at close moments in time — for example, pertaining to a single user. When requesting a database, the necessary metafile is read using a snapshot header, and then the changes in the binlog that have taken place after the snapshot creation are taken into account. Read more about the benefits of this approach here .
At the same time, the data on the hard disk itself is changed only once a day - late at night in Moscow, when the load is minimal. Thanks to this (knowing that the structure on the disk is constant over the course of a day) we can afford to replace the vectors with arrays of a fixed size - and thereby win in memory.
Sending a message in the new scheme looks like this:
But in addition to actually sending messages, you need to implement a few more important things:
All sublists are rapidly changing structures. To work with them, we use Splay-trees . This choice is explained by the fact that at the top of the tree we sometimes have a whole segment of messages from the snapshot - for example, after a night re-indexing, the tree consists of one vertex, in which all messages of the sublist lie. A splay tree makes it easy to perform an insert operation in the middle of such a vertex, without thinking about balancing. In addition, Splay does not store unnecessary data, and it saves us memory.
Messages involve a large amount of information, mainly text, which is useful to be able to compress. At the same time it is important that we can unarchive even one single message accurately. To compress messages, we use the Huffman algorithm with our own heuristics — for example, we know that in messages, words alternate with “not words” —spaces, punctuation, and we also remember some peculiarities of using symbols for the Russian language.
Since there are far fewer users than chat rooms, in order to save random-access disk requests in the chat-engine, we cache messages in the user-engine.
Search by message is implemented as a diagonal request from the user-engine to all chat-engine instances that contain the chats of this user. The results are already combined in the user-engine itself.
Well, all the details have been taken into account, it remains to switch to a new scheme - and preferably so that users do not notice.
So, we have a text-engine, which stores messages by users, and two clusters of chat-members and member-chats, which store data about multichats and users in them. How to move from this to the new user-engine and chat-engine?
The member-chats in the old scheme was used primarily for optimization. We quickly transferred the necessary data from it to chat-members, and then he did not participate in the migration process anymore.
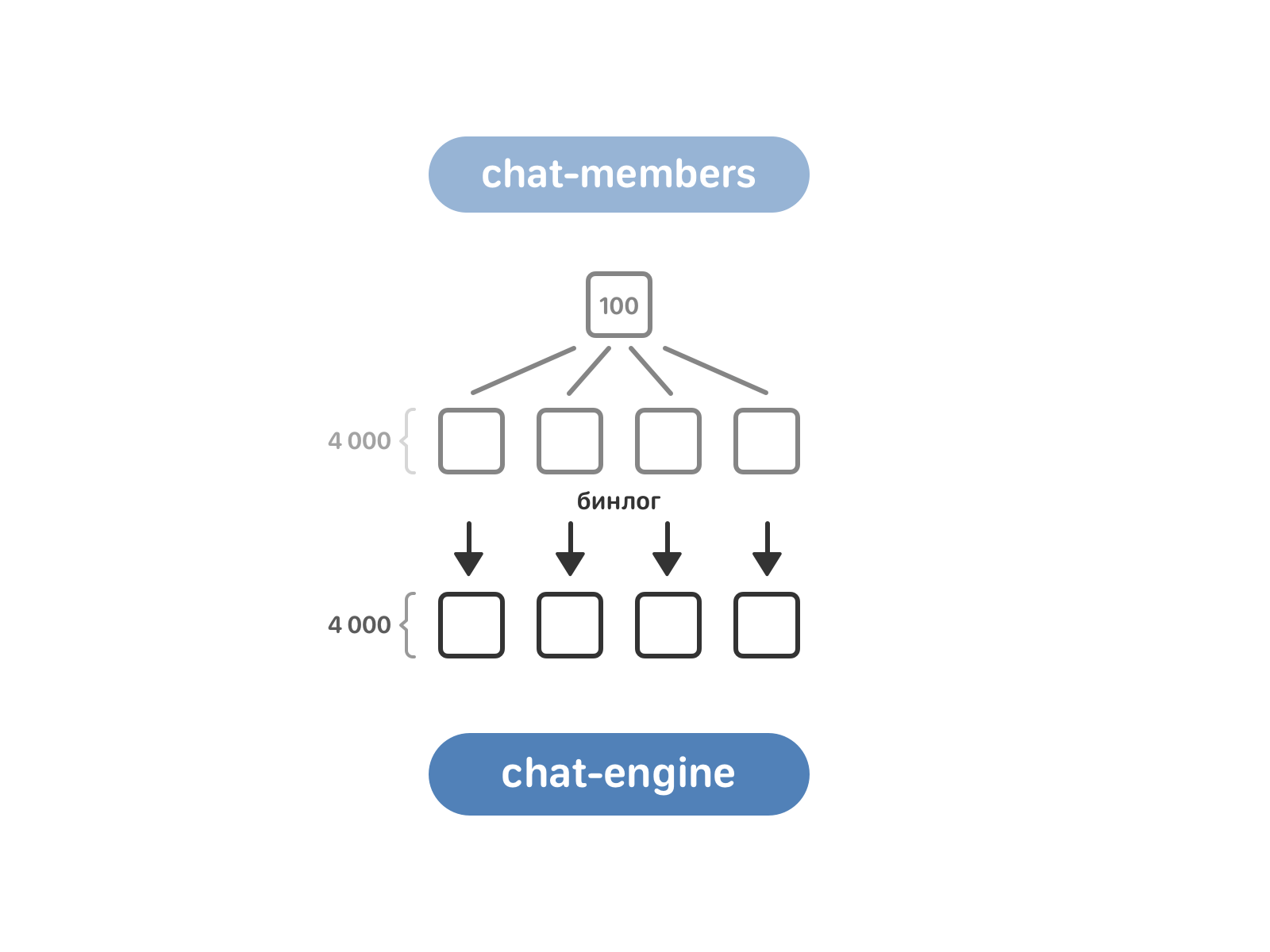
Queue for chat-members. It includes 100 copies, while the chat-engine - 4 thousand. For the transfer of data, you need to bring them in line - for this, chat-members were broken into the same 4,000 instances, and after they turned on the reading of the binlog chat-members into the chat-engine.
Now the chat-engine knows about chat-members multi-chat, but so far he doesn’t know anything about conversations with two interlocutors. Such dialogs lie in the text-engine with reference to users. Here we took the data "in the forehead": each instance of the chat-engine asked all instances of the text-engine if they had the dialogue it needed.
Great - the chat engine knows what multi chat is and knows what dialogue there are.
It is necessary to combine messages in multicat - so that in the end for each chat to get a list of messages in it. First, the chat-engine retrieves from the text-engine all user messages from this chat. In some cases, there are quite a few of them (up to hundreds of millions), but with very few exceptions, the chat is completely placed in the RAM. We have unordered messages, each in several copies - after all, they are all pulled out of different text-engine instances corresponding to the users. The task is to sort the messages and get rid of copies that take up extra space.
Each message has a timestamp containing the dispatch time and text. We use time for sorting - we place pointers to the oldest messages of the participants of the multi chat and compare the hashes from the text of the intended copies, moving in the direction of increasing the timestamp. It is logical that the copies will have the same hash and timestamp, but in practice this is not always the case. As you remember, the synchronization in the old scheme was carried out by PHP - and in rare cases, the time to send the same message was different for different users. In these cases, we allowed ourselves to edit the timestamp - usually within a second. The second problem is the different order of messages for different recipients. In such cases, we allowed the creation of an extra copy, with different versions of the order for different users.
After this, the data on messages in multi-chat is sent to the user-engine. And here comes the unpleasant feature of the imported messages. In normal operation, messages that arrive in the engine are ordered strictly in ascending order by user_local_id. The messages imported from the old engine in the user-engine lost this useful property. At the same time for the convenience of testing, you need to be able to quickly contact them, look for something in them and add new ones.
To store the imported messages, we use a special data structure.
It is a size vector. where everything is - are different and ordered in descending order, with a special order of elements. In each segment with indices items are sorted. The search for an element in such a structure is performed in time. through binary searches. Adding item is depreciated for .
So, we figured out how to transfer data from old engines to new ones. But this process takes several days - and it’s unlikely for these days our users will give up the habit of writing to each other. In order not to lose messages during this time, we switch to the work scheme, which involves both old and new clusters.
Data recording goes to chat-members and user-engine (and not to the text-engine, as during normal operation according to the old scheme). The user-engine proxies the request to the chat-engine - and here the behavior depends on whether this chat is already or not. If the chat is not yet confused, the chat-engine does not write a message to itself, and it is processed only in the text-engine. If the chat is already chatted in the chat-engine, it returns chat_local_id to the user-engine and sends the message to all recipients. The user-engine proxies all the data in the text-engine - so that in case of anything, we can always roll back, having all the actual data in the old engine. The text-engine returns a user_local_id, which the user-engine keeps and returns to the backend.
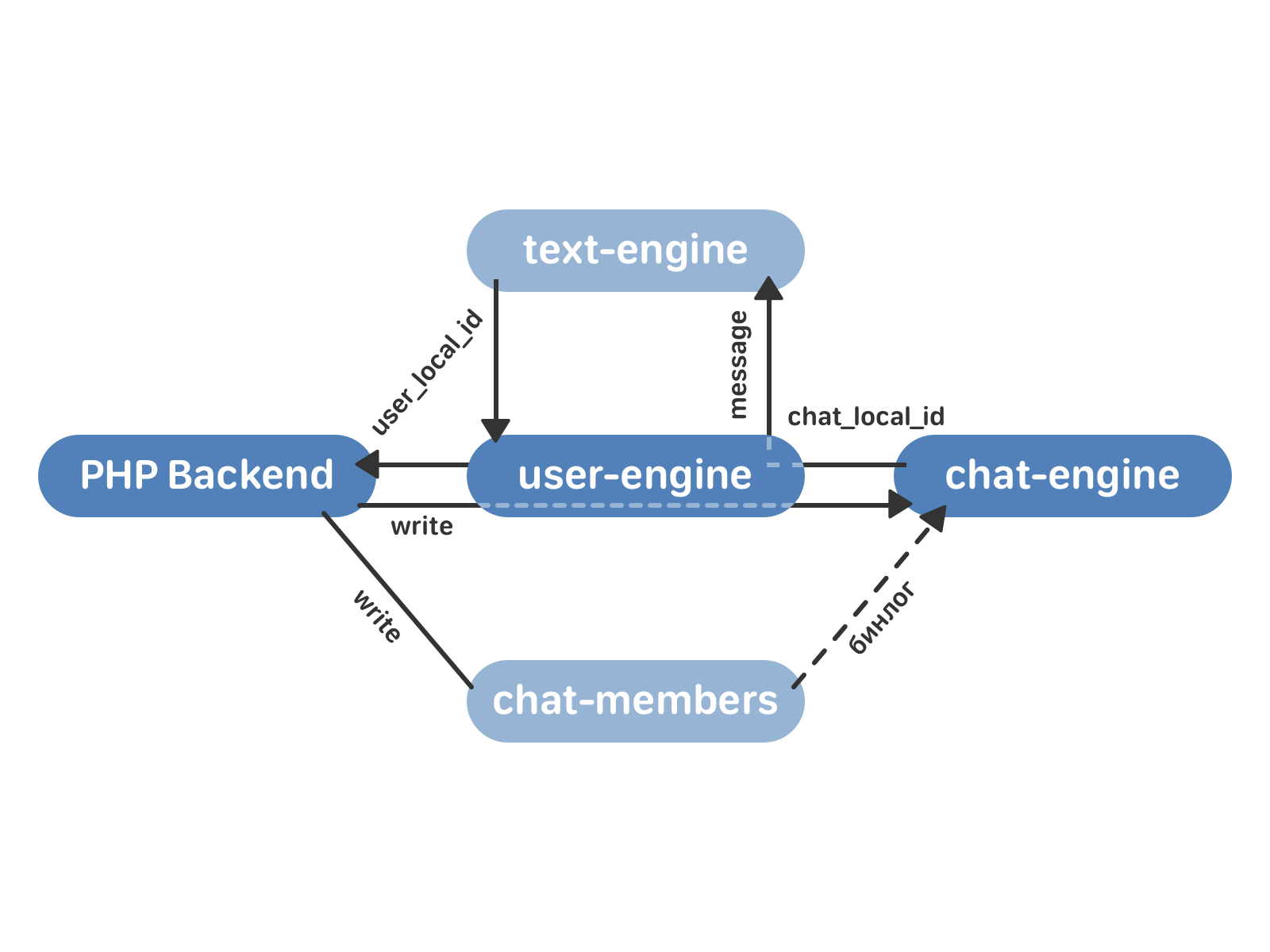
As a result, the transition process looks like this: we connect empty user-engine clusters and chat-engine. chat-engine reads all chat-members binlogs, then proxies are started according to the scheme described above. Pouring old data, we get two synchronized clusters (old and new). It remains only to switch the reading from the text-engine to the user-engine and disable proxying.
Thanks to the new approach, all metrics of engine performance have improved, problems with data consistency have been resolved. Now we can more quickly implement new features in messages (and have already begun to do this - increased the maximum number of chat participants, implemented a search on forwarded messages, launched pinned messages, and raised the limit on the total number of messages from one user).
The changes in logic are really grand. And I want to note that this does not always mean whole years of development by a huge team and a myriad lines of code. chat-engine and user-engine, along with all the additional stories like Huffman for compressing messages, Splay-trees and the structure for imported messages, are less than 20 thousand lines of code. And they were written by 3 developers in just 10 months (however, it should be borne in mind that all three developers are world champions in sports programming ).
Moreover, instead of doubling the number of servers, we came to reduce their number by half - now the user-engine and chat-engine live on 500 physical machines, while the new scheme has a large margin on load. We saved a lot of money on equipment - about $ 5 million + $ 750 thousand per year due to operating expenses.
We strive to find the best solutions for the most complex and large-scale tasks. We have plenty of them - and therefore we are looking for talented developers in the database department. If you like and are able to solve such problems, well know the algorithms and data structures, we invite you to join the team. Contact our HR to find out more.
Even if this story is not about you, please note that we appreciate the recommendations. Tell a friend about the developer ’s job , and if he successfully passes the probationary period, you will receive a bonus of 100 thousand rubles.
This is quite a lot. If you set out to read all the messages of all users, it would take more than 150 thousand years. Provided that you are pretty pumped reader and spend on each message no more than a second.
With this amount of data, it is critical that the storage and access logic is optimally constructed. Otherwise, in one not so beautiful moment, it may turn out that soon everything will go wrong.
For us, this moment came a year and a half ago. How we came to this and what happened in the end - we tell in order.
')
Background
In the very first implementation of the message VKontakte worked on a bunch of PHP-backend and MySQL. This is quite a normal solution for a small student site. However, this site was growing uncontrollably and began to demand to optimize data structures for themselves.
At the end of 2009, the first text-engine storage was written, and in 2010 messages were transferred to it.
The text-engine messages were stored lists - a kind of "mailboxes". Each such list is determined by the uid, the user-owner of all these messages. A message has a set of attributes: interlocutor ID, text, attachments, and so on. The message identifier inside the “box” is local_id, it never changes and is assigned sequentially to new messages. The “boxes” are independent and with each other inside the engine are not synchronized in any way, the connection between them takes place already at the PHP level. Look at the data structure and capabilities of the text-engine from the inside here .
This was quite enough for the correspondence of two users. Guess what happened next?
In May 2011, VKontakte appeared conversations with several participants - multi chat. To work with them, we raised two new clusters - member-chats and chat-members. The first one stores data about chats by users, the second one - data about users by chats. In addition to the lists themselves, this is, for example, the inviting user and the time of adding to the chat.
“PHP, let's send a message to the chat,” says the user.
“Come on, {username},” says PHP.
There are downsides to this scheme. Synchronization is still assigned to PHP. Big chats and users who simultaneously send messages to them is a dangerous story. Since the text-engine instance depends on the uid, the chat participants could receive the same message with a time difference. You could live with that if progress stood still. But do not happen this.
At the end of 2015, we launched community posts, and at the beginning of 2016, an API for them. With the advent of large chat bots in the communities, it was possible to forget about the even distribution of the load.
A good bot generates several million messages per day - even the most talkative users cannot boast of such. And this means that some text-engine instances, on which such bots lived, began to fall in full.
Message engines in 2016 are 100 instances of chat-members and member-chats, and 8000 text-engine. They were located on thousands of servers, each with 64 GB of memory. As a first emergency measure, we increased the memory by another 32 GB. Estimated predictions. Without fundamental changes, this would be enough for about a year. It is necessary either to get rich with iron, or to optimize the databases themselves.
Due to the nature of the architecture, it only makes sense to build up iron. That is, at least double the number of cars - obviously, this is quite an expensive way. We will optimize.
New concept
The central essence of the new approach is chat. The chat has a list of messages that relate to it. User has a chat list.
The required minimum is two new databases:
- chat-engine. This is a repository of chat vectors. Each chat has a vector of messages that relate to it. Each message has a text and a unique message identifier within the chat - chat_local_id.
- user-engine This is a repository of users - user links. Each user has a peer_id vector (interlocutors - other users, multi-chat or communities) and a message vector. Each peer_id has a vector of messages that apply to it. Each message has a chat_local_id and the unique message identifier for this user is user_local_id.
New clusters communicate with each other using TCP - this ensures that the order of the requests does not change. The requests and confirmations for them are written to the hard drive - so we can restore the queue status at any time after a failure or restart of the engine. Since the user-engine and chat-engine are 4,000 shards each, the queue of requests between the clusters will be evenly distributed (but in reality it is not at all - and it works very quickly).
Working with the disk in our databases in most cases is based on a combination of a binary change log (binlog), static images and a partial image in memory. Changes during the day are written in binlog, periodically a snapshot of the current state is created. A snapshot is a set of data structures optimized for our purposes. It consists of a header (meta-index snapshot) and a set of metafiles. The header is permanently stored in RAM and indicates where to look for data from the snapshot. Each metafile includes data that is likely to be needed at close moments in time — for example, pertaining to a single user. When requesting a database, the necessary metafile is read using a snapshot header, and then the changes in the binlog that have taken place after the snapshot creation are taken into account. Read more about the benefits of this approach here .
At the same time, the data on the hard disk itself is changed only once a day - late at night in Moscow, when the load is minimal. Thanks to this (knowing that the structure on the disk is constant over the course of a day) we can afford to replace the vectors with arrays of a fixed size - and thereby win in memory.
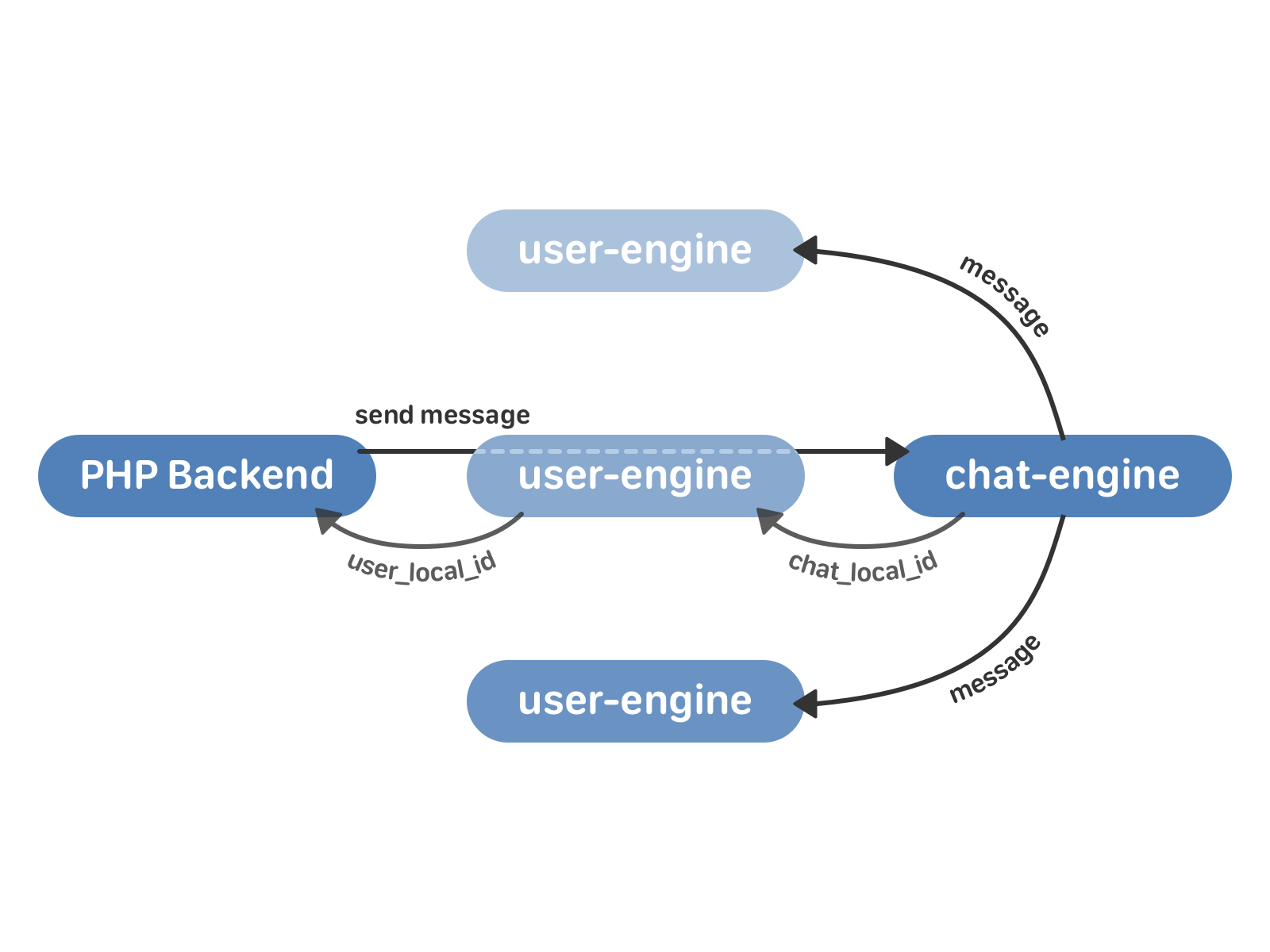
Sending a message in the new scheme looks like this:
- PHP backend calls the user-engine with a request to send a message.
- The user-engine proxies the request to the required chat-engine instance, which returns the chat_local_id, the unique identifier of the new message within this chat, to the user-engine. Then chat_engine sends the message to all recipients in the chat.
- The user-engine accepts chat_local_id from the chat-engine and returns to PHP user_local_id - the unique message identifier for this user. This identifier is then used, for example, to work with messages through the API.
But in addition to actually sending messages, you need to implement a few more important things:
- Sublists are, for example, the most recent messages that you see when opening the list of conversations. Unread messages, messages with labels (“Important”, “Spam”, etc.).
- Compress messages in chat-engine
- User-engine message caching
- Search (for all conversations and within the specific).
- Real time update (Longpolling).
- Storing history for implementing caching on mobile clients.
All sublists are rapidly changing structures. To work with them, we use Splay-trees . This choice is explained by the fact that at the top of the tree we sometimes have a whole segment of messages from the snapshot - for example, after a night re-indexing, the tree consists of one vertex, in which all messages of the sublist lie. A splay tree makes it easy to perform an insert operation in the middle of such a vertex, without thinking about balancing. In addition, Splay does not store unnecessary data, and it saves us memory.
Messages involve a large amount of information, mainly text, which is useful to be able to compress. At the same time it is important that we can unarchive even one single message accurately. To compress messages, we use the Huffman algorithm with our own heuristics — for example, we know that in messages, words alternate with “not words” —spaces, punctuation, and we also remember some peculiarities of using symbols for the Russian language.
Since there are far fewer users than chat rooms, in order to save random-access disk requests in the chat-engine, we cache messages in the user-engine.
Search by message is implemented as a diagonal request from the user-engine to all chat-engine instances that contain the chats of this user. The results are already combined in the user-engine itself.
Well, all the details have been taken into account, it remains to switch to a new scheme - and preferably so that users do not notice.
Data migration
So, we have a text-engine, which stores messages by users, and two clusters of chat-members and member-chats, which store data about multichats and users in them. How to move from this to the new user-engine and chat-engine?
The member-chats in the old scheme was used primarily for optimization. We quickly transferred the necessary data from it to chat-members, and then he did not participate in the migration process anymore.
Queue for chat-members. It includes 100 copies, while the chat-engine - 4 thousand. For the transfer of data, you need to bring them in line - for this, chat-members were broken into the same 4,000 instances, and after they turned on the reading of the binlog chat-members into the chat-engine.
Now the chat-engine knows about chat-members multi-chat, but so far he doesn’t know anything about conversations with two interlocutors. Such dialogs lie in the text-engine with reference to users. Here we took the data "in the forehead": each instance of the chat-engine asked all instances of the text-engine if they had the dialogue it needed.
Great - the chat engine knows what multi chat is and knows what dialogue there are.
It is necessary to combine messages in multicat - so that in the end for each chat to get a list of messages in it. First, the chat-engine retrieves from the text-engine all user messages from this chat. In some cases, there are quite a few of them (up to hundreds of millions), but with very few exceptions, the chat is completely placed in the RAM. We have unordered messages, each in several copies - after all, they are all pulled out of different text-engine instances corresponding to the users. The task is to sort the messages and get rid of copies that take up extra space.
Each message has a timestamp containing the dispatch time and text. We use time for sorting - we place pointers to the oldest messages of the participants of the multi chat and compare the hashes from the text of the intended copies, moving in the direction of increasing the timestamp. It is logical that the copies will have the same hash and timestamp, but in practice this is not always the case. As you remember, the synchronization in the old scheme was carried out by PHP - and in rare cases, the time to send the same message was different for different users. In these cases, we allowed ourselves to edit the timestamp - usually within a second. The second problem is the different order of messages for different recipients. In such cases, we allowed the creation of an extra copy, with different versions of the order for different users.
After this, the data on messages in multi-chat is sent to the user-engine. And here comes the unpleasant feature of the imported messages. In normal operation, messages that arrive in the engine are ordered strictly in ascending order by user_local_id. The messages imported from the old engine in the user-engine lost this useful property. At the same time for the convenience of testing, you need to be able to quickly contact them, look for something in them and add new ones.
To store the imported messages, we use a special data structure.
It is a size vector. where everything is - are different and ordered in descending order, with a special order of elements. In each segment with indices items are sorted. The search for an element in such a structure is performed in time. through binary searches. Adding item is depreciated for .
So, we figured out how to transfer data from old engines to new ones. But this process takes several days - and it’s unlikely for these days our users will give up the habit of writing to each other. In order not to lose messages during this time, we switch to the work scheme, which involves both old and new clusters.
Data recording goes to chat-members and user-engine (and not to the text-engine, as during normal operation according to the old scheme). The user-engine proxies the request to the chat-engine - and here the behavior depends on whether this chat is already or not. If the chat is not yet confused, the chat-engine does not write a message to itself, and it is processed only in the text-engine. If the chat is already chatted in the chat-engine, it returns chat_local_id to the user-engine and sends the message to all recipients. The user-engine proxies all the data in the text-engine - so that in case of anything, we can always roll back, having all the actual data in the old engine. The text-engine returns a user_local_id, which the user-engine keeps and returns to the backend.
As a result, the transition process looks like this: we connect empty user-engine clusters and chat-engine. chat-engine reads all chat-members binlogs, then proxies are started according to the scheme described above. Pouring old data, we get two synchronized clusters (old and new). It remains only to switch the reading from the text-engine to the user-engine and disable proxying.
results
Thanks to the new approach, all metrics of engine performance have improved, problems with data consistency have been resolved. Now we can more quickly implement new features in messages (and have already begun to do this - increased the maximum number of chat participants, implemented a search on forwarded messages, launched pinned messages, and raised the limit on the total number of messages from one user).
The changes in logic are really grand. And I want to note that this does not always mean whole years of development by a huge team and a myriad lines of code. chat-engine and user-engine, along with all the additional stories like Huffman for compressing messages, Splay-trees and the structure for imported messages, are less than 20 thousand lines of code. And they were written by 3 developers in just 10 months (however, it should be borne in mind that all three developers are world champions in sports programming ).
Moreover, instead of doubling the number of servers, we came to reduce their number by half - now the user-engine and chat-engine live on 500 physical machines, while the new scheme has a large margin on load. We saved a lot of money on equipment - about $ 5 million + $ 750 thousand per year due to operating expenses.
We strive to find the best solutions for the most complex and large-scale tasks. We have plenty of them - and therefore we are looking for talented developers in the database department. If you like and are able to solve such problems, well know the algorithms and data structures, we invite you to join the team. Contact our HR to find out more.
Even if this story is not about you, please note that we appreciate the recommendations. Tell a friend about the developer ’s job , and if he successfully passes the probationary period, you will receive a bonus of 100 thousand rubles.
Source: https://habr.com/ru/post/342570/
All Articles