How we played with neural networks
In 2016, Google Brain Group released the Magenta open access project. Magenta is positioned as a project that asks and answers the questions: “Can we use machine learning to create music and art worthy of attention? If so, how? If not, why not? ” The second goal of the project is to build a community of artists, musicians and researchers in the field of machine learning.
Why not, really. There was also a reason: to make a small performance at the opening of the TopConf conference.
Hi, my name is Alexander Tavgen. I am an architect at Playtech, and I still like to play constructor. True, the designer is a little more complicated.
')
I offered to try to connect the music and the car to Alexander Zhedelev aka Faershtein , a composer and music producer of the Russian Theater in Estonia. Rather, the project MODULSHTEIN (Alexander Zhedelev, Martin Altrov and Alexei Seminihin) . My thoughts for a long time have been implicitly trying to combine MIDI and char-based models. We are very well supported by the company Playtech, for which she thanks a lot. We had about two months to realize our attempt. And this is very little, considering that we live in different cities and work according to the main types of activity.
In this regard, the famous article by Andrej Karpathy is a great introduction to the principles behind recurrent neural networks, and there are excellent examples. That there is only one network, trained on the source code of Linux. Or a model trained on the speeches of Donald Trump , which I wrote about in the spring.
In general, recurrent neural networks show quite satisfactory results for temporal data with a certain structure.
Take the language. The structure of the language has several dimensions. One of them is semantic, to which machines are only matched. For example, Searle’s “Chinese Room” argument no longer looks so convincing in relation to Multimodal Training .
Another dimension, syntactic, is already quite capable. Recurrent neural networks take into account the previous context and can store a state. And it was fun to watch in practice, but more on that below. We can feed the model a large amount of text and ask to predict the probability of obtaining the following letters. For example, after the letters 'I lov', with a very high probability there will be 'e', but after the letters 'I love', it is no longer obvious - maybe 'y', 'h' or other.
Music, as a rule, has a certain structure. This is a rhythm, intervals, dynamics. If you simulate a music sequence as a set of certain characters, then recurrent neural networks are suitable for this purpose perfectly. MIDI file format is ideal for this. While I was thinking about how this can be done, and I have been looking at the MIDI libraries on Python, I came across the Magenta project.
In essence, Magenta provides a MIDI interface for TensorFlow models. Virtual MIDI ports are created for call-response, roughly speaking, input and output. You can run multiple parallel ports. For each pair of ports you can connect the model TensorFlow. The so-called bundle file is the checkpoint of the training and the metadata of the graph from TensorFlow. Briefly, the interaction process can be described as follows.
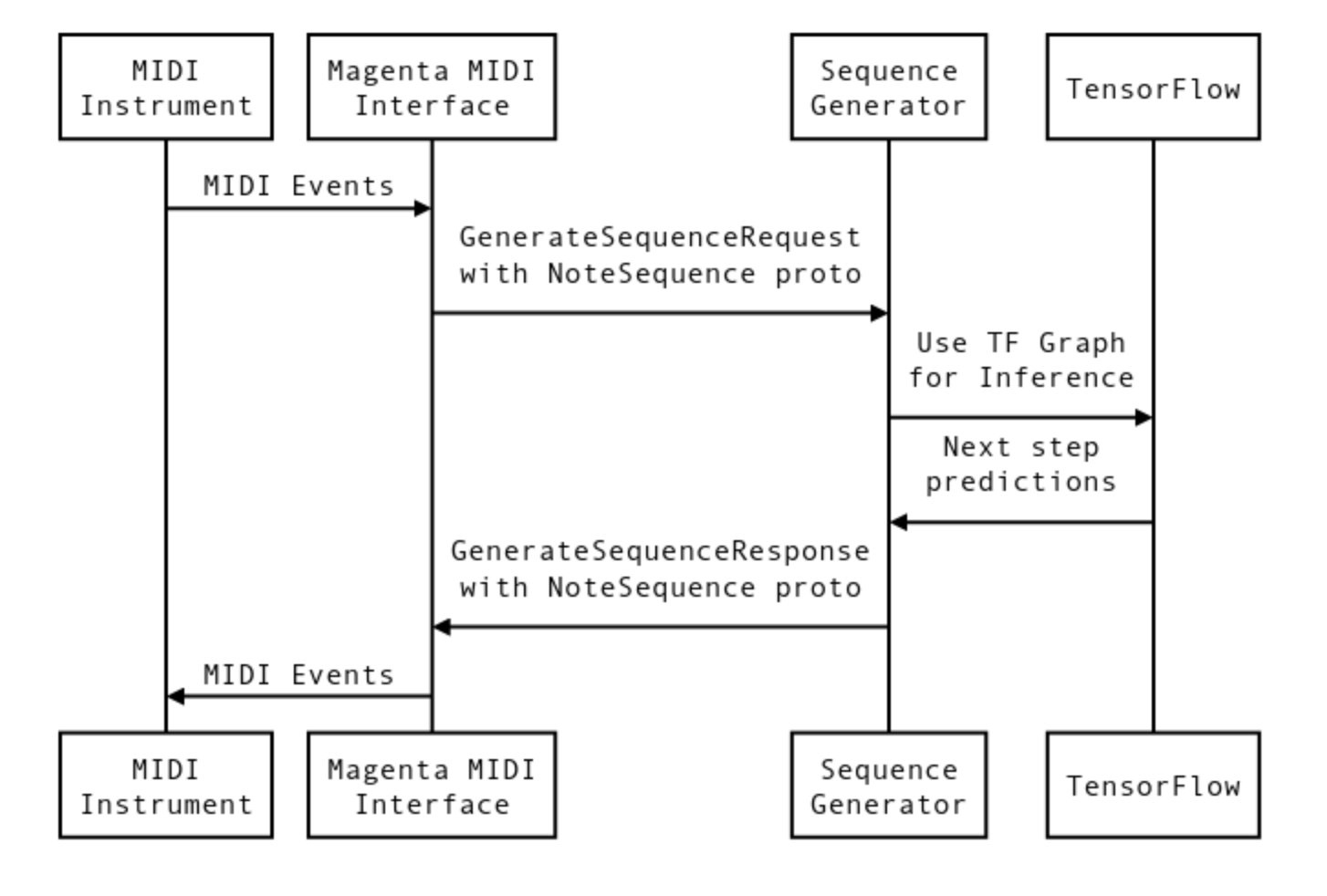
The signals pass through the MIDI interface, and are converted to the NoteSequence format. This is a protocol buffers format for exchanging data with models. Training data can be downloaded from here , or take a pretrained model, and continue learning from it.
At first, I thought of training from scratch, but first there were problems with the amount of data for the training, and secondly, when I tried to run Magenta on Amazon, for instance with the GPU, there were problems with hanging at different stages of the training. The problems were with the amount of data for training from scratch, and it does not make sense to train on the same dataset on which the models in the Magenta repository are trained. Therefore, I continued with their checkpointa. I pumped a bunch of music with broken rhythms. From Prodigy - Outer of Space and Goldie - Inner City Life to Massive Attack.
At Magenta Project Github, there are already tools for extracting different sections, such as drums and tunes from prepared note sequences. LSTM recurrent network was used, 2 layers of 128 elements, the last 2 bars were taken into account. Training time is about 4 days on a laptop. However, the gradient descended very slowly, and I cannot say whether it was a descent at the end, or an oscillation around a local minimum.
We now turn to how this all was connected further. Checkpoints were linked into a bundle file, and two models were loaded at the start, each with its own pair of virtual ports. Let's call them magenta_in / out 1 and 2. Now we need to connect all this with live musicians. Alexander Zhedelev used Ableton as a universal glue.
The Magenta project site has an example of how to link Ableton using MaxMSP, but this option was dropped, as MaxMSP crashed and crashed. If something can be thrown out of the system without interfering with work, then boldly throw it away.
Alexander Zhedelev conjured with Ableton. We had some minor problems with the overall synchronization of Magenta and Ableton via midi_clock. In the end, we got this configuration.
There were two models. The first one listens to the person and gives an answer, after which the second one starts to listen to the answer by the first one and gives out his part. There was a funny moment when we tied them in a loop (the first one listens to the second one and so on in a circle). We left for lunch, and returned about an hour later, and they were already in full rage with each other, so to speak. Semi-trance, semi-something, but sometimes interesting and fun.
A person plays on an drum-pad (Ableton Push2) an example of a rhythm, a model, all the while receiving MIDI signals at the input and then, after the end of the example, after a while gives an answer. And we noticed that the longer you play and set the length of the listened sections, the more meaningful the answer is. Apparently this is due to the very internal state. I can not yet fully explain to myself, too, why at the beginning the network gives options with log-likelihood -70, but over time this value drops to -150, -400, even -750. The lower this value, the higher the maximum likelihood of the result. That is, minimizing log-likelihood is the same as maximizing the maximum likelihood function. At the hearing it is expressed that the model, as if played, and enters into a rage. That is, it is clear that the model has an internal state that depends on the previous context, but over time it converges to the best generated sequences.
In the process.

The beginning looked like this.
These are the very first steps and testing of various options for linking models.
But the first real rehearsal with real people was at the moment when we decided to capture everything on video. Playtech provided us with office space for this, and there was something in it. Outside the window - an airport with airplanes taking off, 10th floor, evening, empty office, the sound of bass making its way to the bone. Many thanks to Nikolai Alkhazov for his help and work, this video would not have happened without him. The difficulty was that since it was an improvisation on the part of the models, each take was not similar to the previous ones, and this added intrigue. And yes, good cocoa saved a life.

The rhythm section is issued by neural networks. At different moments, Alexander plays the starter rhythms, and then the chain of improvisations unfolds.
Since for Alexander it was important what happens in the models at any given moment, the Magenta web interface, which allows you to see and change the network settings through the browser, was very useful. In the video, he runs from the side, like Tetris.
Each time the results get better and better. If you take video controlled by MIDI signals, you can theoretically connect networks with video and music, and synchronize them with each other. The space for further searches is quite large, as are the use cases. You can link models with each other, create loops, and get unexpected and sometimes interesting options.
And, here, today's interview on local television.
It was a very interesting and unusual experience. And there are thoughts for further direction.
I would like to thank all the people who participated in the project.
Why not, really. There was also a reason: to make a small performance at the opening of the TopConf conference.
Hi, my name is Alexander Tavgen. I am an architect at Playtech, and I still like to play constructor. True, the designer is a little more complicated.
')
I offered to try to connect the music and the car to Alexander Zhedelev aka Faershtein , a composer and music producer of the Russian Theater in Estonia. Rather, the project MODULSHTEIN (Alexander Zhedelev, Martin Altrov and Alexei Seminihin) . My thoughts for a long time have been implicitly trying to combine MIDI and char-based models. We are very well supported by the company Playtech, for which she thanks a lot. We had about two months to realize our attempt. And this is very little, considering that we live in different cities and work according to the main types of activity.
In this regard, the famous article by Andrej Karpathy is a great introduction to the principles behind recurrent neural networks, and there are excellent examples. That there is only one network, trained on the source code of Linux. Or a model trained on the speeches of Donald Trump , which I wrote about in the spring.
In general, recurrent neural networks show quite satisfactory results for temporal data with a certain structure.
Take the language. The structure of the language has several dimensions. One of them is semantic, to which machines are only matched. For example, Searle’s “Chinese Room” argument no longer looks so convincing in relation to Multimodal Training .
Another dimension, syntactic, is already quite capable. Recurrent neural networks take into account the previous context and can store a state. And it was fun to watch in practice, but more on that below. We can feed the model a large amount of text and ask to predict the probability of obtaining the following letters. For example, after the letters 'I lov', with a very high probability there will be 'e', but after the letters 'I love', it is no longer obvious - maybe 'y', 'h' or other.
Music, as a rule, has a certain structure. This is a rhythm, intervals, dynamics. If you simulate a music sequence as a set of certain characters, then recurrent neural networks are suitable for this purpose perfectly. MIDI file format is ideal for this. While I was thinking about how this can be done, and I have been looking at the MIDI libraries on Python, I came across the Magenta project.
In essence, Magenta provides a MIDI interface for TensorFlow models. Virtual MIDI ports are created for call-response, roughly speaking, input and output. You can run multiple parallel ports. For each pair of ports you can connect the model TensorFlow. The so-called bundle file is the checkpoint of the training and the metadata of the graph from TensorFlow. Briefly, the interaction process can be described as follows.
The signals pass through the MIDI interface, and are converted to the NoteSequence format. This is a protocol buffers format for exchanging data with models. Training data can be downloaded from here , or take a pretrained model, and continue learning from it.
At first, I thought of training from scratch, but first there were problems with the amount of data for the training, and secondly, when I tried to run Magenta on Amazon, for instance with the GPU, there were problems with hanging at different stages of the training. The problems were with the amount of data for training from scratch, and it does not make sense to train on the same dataset on which the models in the Magenta repository are trained. Therefore, I continued with their checkpointa. I pumped a bunch of music with broken rhythms. From Prodigy - Outer of Space and Goldie - Inner City Life to Massive Attack.
At Magenta Project Github, there are already tools for extracting different sections, such as drums and tunes from prepared note sequences. LSTM recurrent network was used, 2 layers of 128 elements, the last 2 bars were taken into account. Training time is about 4 days on a laptop. However, the gradient descended very slowly, and I cannot say whether it was a descent at the end, or an oscillation around a local minimum.
We now turn to how this all was connected further. Checkpoints were linked into a bundle file, and two models were loaded at the start, each with its own pair of virtual ports. Let's call them magenta_in / out 1 and 2. Now we need to connect all this with live musicians. Alexander Zhedelev used Ableton as a universal glue.
The Magenta project site has an example of how to link Ableton using MaxMSP, but this option was dropped, as MaxMSP crashed and crashed. If something can be thrown out of the system without interfering with work, then boldly throw it away.
Alexander Zhedelev conjured with Ableton. We had some minor problems with the overall synchronization of Magenta and Ableton via midi_clock. In the end, we got this configuration.
There were two models. The first one listens to the person and gives an answer, after which the second one starts to listen to the answer by the first one and gives out his part. There was a funny moment when we tied them in a loop (the first one listens to the second one and so on in a circle). We left for lunch, and returned about an hour later, and they were already in full rage with each other, so to speak. Semi-trance, semi-something, but sometimes interesting and fun.
A person plays on an drum-pad (Ableton Push2) an example of a rhythm, a model, all the while receiving MIDI signals at the input and then, after the end of the example, after a while gives an answer. And we noticed that the longer you play and set the length of the listened sections, the more meaningful the answer is. Apparently this is due to the very internal state. I can not yet fully explain to myself, too, why at the beginning the network gives options with log-likelihood -70, but over time this value drops to -150, -400, even -750. The lower this value, the higher the maximum likelihood of the result. That is, minimizing log-likelihood is the same as maximizing the maximum likelihood function. At the hearing it is expressed that the model, as if played, and enters into a rage. That is, it is clear that the model has an internal state that depends on the previous context, but over time it converges to the best generated sequences.
In the process.
The beginning looked like this.
These are the very first steps and testing of various options for linking models.
But the first real rehearsal with real people was at the moment when we decided to capture everything on video. Playtech provided us with office space for this, and there was something in it. Outside the window - an airport with airplanes taking off, 10th floor, evening, empty office, the sound of bass making its way to the bone. Many thanks to Nikolai Alkhazov for his help and work, this video would not have happened without him. The difficulty was that since it was an improvisation on the part of the models, each take was not similar to the previous ones, and this added intrigue. And yes, good cocoa saved a life.
The rhythm section is issued by neural networks. At different moments, Alexander plays the starter rhythms, and then the chain of improvisations unfolds.
Since for Alexander it was important what happens in the models at any given moment, the Magenta web interface, which allows you to see and change the network settings through the browser, was very useful. In the video, he runs from the side, like Tetris.
Each time the results get better and better. If you take video controlled by MIDI signals, you can theoretically connect networks with video and music, and synchronize them with each other. The space for further searches is quite large, as are the use cases. You can link models with each other, create loops, and get unexpected and sometimes interesting options.
And, here, today's interview on local television.
It was a very interesting and unusual experience. And there are thoughts for further direction.
I would like to thank all the people who participated in the project.
- Aleksandr Zedeljov aka Faershtein
- Marten Altrov - MODULSHTEIN
- Aleksej Semenihhin - MODULSHTEIN
- Nikolay Alhazov , for making this videos real
- Katrin Kvade , sound engineering
- Playtech company
- Help and support for Marianne Võime and Ergo Jõepere
Source: https://habr.com/ru/post/342306/
All Articles