How not to put thousands of servers using centralized configuration management using the example of CFEngine
Hi, Habr! My name is Dmitry Samsonov, I work as a leading system administrator at Odnoklassniki. My main areas of expertise are Zabbix, CFEngine and Linux Optimization. We have more than 8 thousand servers and 200 applications, which in various configurations form 700 different clusters. The topic of this article is exhaustively described in the title.
Just want to make a reservation:
- I will be biased because I participated in the implementation of CFEngine in Odnoklassniki.
- I used CFEngine only versions 3.3-3.4.
- I have no illusions about CFEngine, this is a significant player, but not a market leader and not an outsider. The article will not compare CFEngine with other systems.
- From configuration systems, I have experience using only CFEngine and Ansible.
Classic Configuration Tools
First, let's talk about the classic systems that you are familiar with: ssh, scp, mstsc, winexe - all of them are good, but not suitable for configuring a large number of servers and managing them.
When we had more than a couple dozen servers in the project, we wrote our shell over the dssh-command + dscp + dwinexe-command utilities, which in the beginning have the letter d - distributed. They can do everything the same, but on a large number of servers at the same time.
Another tool in our arsenal is the image of the operating system. If we needed to change any config in the OS, we would use dssh to go through the entire production, and then change the operating system image so that the new servers could immediately get this config, and considered the work done.
First of all, I want to dwell on the dssh-command utility, because initially it contained absolutely no protection: what she was told to do was what she would do, no additional checks.
# cqn feeds-portlet-cdb | dssh-command -t 300 "date" Cqn is a CLI command that allows you to get a list of servers from the CMDB. We receive the list, give it to the standard input dssh-command and ask to execute the date command on these servers. The -t 300 operator is a timeout for which both the running command and all the commands generated by it are killed.
Why do you need it? There was an interesting incident, the server worked, worked, then - bang! - on it the application fell. They began to investigate: at this moment, none of the system administrators interacted with the server, but some time before the connection was made, the administrator launched the lsof command without any parameters, and in this case, it starts scanning absolutely all file descriptors, that is, connections , files and so on. Moreover, one of the running applications required a huge number of threads and opened many connections. As a result, one lsof team lsof lot of gigabytes of memory, after which OOM Killer was launched and killed everyone.
Then you need to confirm the input command. Most of these tools usually ask only “Yes / No”, and “Yes” is often the default choice. So, in essence, such protection does not save us from problems. But here, as a confirmation, you need to enter the correct result of a mathematical operation:
How much is 5 + 8 = We have a chance to think again whether we really want to do exactly what we wrote on the command line. Moreover, this calculator appears not once, but with each double increase in the volume of servers.
We entered the correct answer, the command starts to run.
Correct srvd1352:O:0:Fri Oct 14 13:17:52 MSK 2016 Executing: "date" But it is also not executed on all servers at once. First on one. The fact is that the team may simply be wrong. If it is an oneliner, then it is very easy to make a mistake, so we’ll make sure on one server that exactly what is needed is entered into the command line, and the expected result is obtained.
Further, the command will be executed on one data center. All production is located in several data centers, all of which are independent of each other. We can lose thousands of servers in one data center - and users will not notice.
Nevertheless, no one wants to lose the whole DC. To prevent this from happening, in addition to the mentioned protection mechanisms, the command will be executed simultaneously on a maximum of 50 servers.
Next, the user is asked if he wants to continue on the next DC, and so on until all servers are covered. At the end, you can see the execution log, standard output, standard error, exit status, and so on.
Do you want to execute the command on servers in DL? [Yes/No]: Yes srvd1353:O:0:Fri Oct 14 13:17:53 MSK 2016 Executing: "date" Do you want to execute the command on servers in M100? [Yes/No]: Yes srve1993:O:0:Fri Oct 14 13:17:54 MSK 2016 srve2765:O:0:Fri Oct 14 13:17:54 MSK 2016 ... Full output saved in /tmp/dsshFullOutput_29606_2016-10-14_13-17.log file. However, all this does not give any guarantee that our servers are configured correctly. The most trivial example: the server is currently turned off, because it just reboots - or administrators change the failed memory, disks. There are a million reasons why these changes may not reach the server. And so that this did not happen, configuration management systems were invented.
System selection
In 2012, we decided that it was time to implement some of these systems, and first wrote a list of criteria:
- CMDB integration;
- package installation;
- work with files (copy / edit / attributes);
- file control (content / attributes);
- management of processes and services;
- manual launch of policies / recipes / manifestos;
- version control, change logging, reports;
- scaling, backup;
- Linux and Windows support;
- checking for servers without a working CM.
But as a result, we chose only three main criteria.
The first is performance . Here is a graph of the load on the CFEngine-hub, which serves 3000 servers:
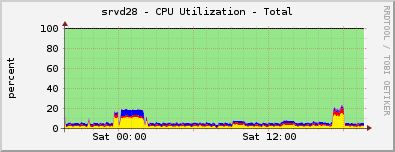
There is still a lot of free CPU time, one server can safely serve tens of thousands of clients. Memory is the same.
The next criterion is maturity . This is the scale of the emergence of modern configuration management tools.
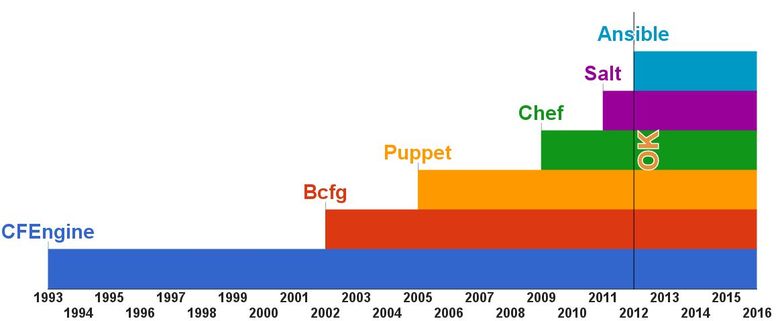
As you can see, CFEngine is at least 10 years older than all existing systems today, and this gives some confidence in its capabilities and reliability. By the way, two other popular products, Puppet and Chef, appeared like this: Puppet developer used CFEngine, but he didn’t like it, so he did Puppet; then another developer didn’t like Puppet, and he did Chef.
The last criterion is popularity . CFEngine is not at all common in Russia, but outside of its borders it was used by such large companies as NASA, IBM, LinkedIn. Let's look at the historical data in Google Trends.
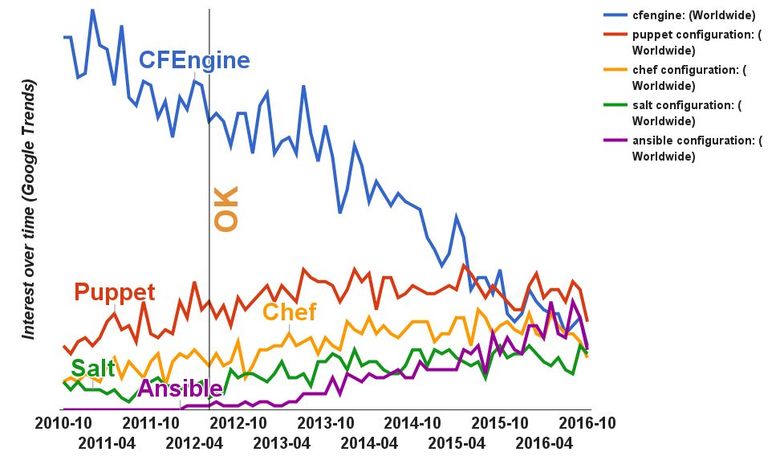
CFEngine was incredibly popular, remained a market leader for a long time, when other configuration management systems were still not very common. In 2012, CFEngine best met all our requirements. Many demonize this tool because of the specificity of its capabilities, logic and organization of the language. But you can bring it into a state where it will be enough just to use it.
CFEngine in Odnoklassniki
Here is an example of a typical application configuration policy in production.
"app_ok_feed" or => {"cmdb_group_feeds_proxy", “cmdb_group_feeds_cache}; ... bundle agent app_ok_feed { vars: "application" string => "ok-feed"; methods: "app_ok" usebundle => app_ok("$(application)"); } The name of the policy is app_ok_feed , it is applied to two groups of servers — feeds_proxy and feeds_cache , it contains the name of the application and the app_ok method being app_ok . Even if you do not know the syntax of CFEngine, difficulties with understanding will not arise.
Let's move on to the next level of abstraction - directly the app_ok method app_ok .
bundle agent app_ok(application) { vars: "file[/ok/bin/$(application)][policy]" string => "copy"; "file[/ok/bin/$(application)][mode]" string => "0755"; "file[/ok/conf/$(application).conf][policy]" string => "copy"; "file[/root/ok/ok.properties][policy]" string => "edit"; "file[/root/ok/ok.properties][suffix]" string => "$(application)"; "file[/root/ok/ok.properties][type]" string => "file"; methods: "files" usebundle => files_manage("$(this.bundle).file"); } Here we take the name of the application, copy some configs, expose them the necessary permissions and proceed to the next level of abstraction: call the files_manage method. That is, CFEngine makes it easy to create levels of abstraction.
A few more very short examples:
- Add user:
"user[git][policy]" string => "add"; - Start the service:
"service[mysql][policy]" string => "start"; - Add cron:
"cron[do_well][cron]" string => "* * * * * do_well"; - Install package:
"package[rsyslog][policy]" string => "add";
Distribution by type of our policies:
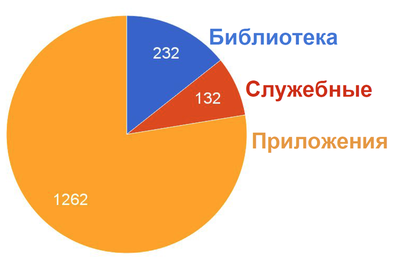
There are about 1500 of them in total, the largest policy is 27 Kb - oddly enough, this is the Zabbix server configuration policy. It describes absolutely all aspects, you can take a bare server and run the policy, as a result, the database and the front-end with all the necessary patches will be configured.
A few more examples of specific things that configuration systems often do not configure:
- IP routes;
- cache records HW RAID;
- SELinux;
- IPMI SOL;
- kernel modules;
- RSS / RPS / RFS.
We have it all automated with CFEngine. Suffice to say which mode you want and on which server, and the system will do the rest.
disadvantages
However, CFEngine has drawbacks. First of all, it is a high threshold of entry . The biggest pain for new employees and those who train them is the explanation of all internal logic. Of course, there are high levels of abstraction. Nevertheless, the system administrator who wants to work with it is important to understand how the tool works under the hood.
The next problem - CFEngine lags far behind competitors . I have no illusions, I know the capabilities of modern systems, and CFEngine is far from them.
CFEngine does not have the ability to extend functionality . It is written in C. Other popular systems basically have plugins that are written in simpler languages like Python.
Bad templates . They are weak in capabilities, specific things cannot be done in them, you have to create several different files.
April, 4
What is remarkable April 4? This is the day of the web developer. But not only. In 2013, on April 4, the project Odnoklassniki became unavailable for all users, and we tried to fix it for three days. The problem was complex, all servers were inaccessible to users and system administrators, and the reboot did not help. This case entered the world history of downtime. You can read more in the post “ Three days that shook us in 2013 ”.
Could this have been avoided? Naturally, we worked remedies:
- syntax checking;
- test environments;
- review;
- monitoring.
Nevertheless, the devil is in the details. The same review though existed, but was optional. As for the commit that broke everything, he went through the review, at least two administrators watched it - and that did not save. In the commit, several symbols were added to the config, and a tragic coincidence happened: the bug of one system superimposed on the bug of another, and everything collapsed.
When several thousand servers stopped working due to CFEngine, we stopped it first. We had to sit down and very seriously think about how to continue to exist, whether system administrators will use some kind of configuration system, and if so, how. In addition, it was necessary to eliminate the human factor as much as possible, physically limiting the possibility of a repetition of the disaster.
First of all, I would like to note that in the end we left CFEngine. Moreover, it still runs once every five minutes on each server . This is important because configuration management systems primarily ensure that the server is configured exactly the way you want it. And this is true for all of our servers. They have the configs that we want, everything is done absolutely exactly, I don’t need to check it - CFEngine or any other configuration management system does it for me.
I want to note that CFEngine does not participate in the deployment of Java applications at all. We use it more likely to prepare for deployment, which our separate self-written system makes. We roll out the server, CFEngine brings it to the ready state, and another system can easily install the main Java application.
What measures have we taken to prevent this situation from happening again?
The first level of protection is git . There are hooks, and all CFEngine-politician source codes are in git. In git-hooks, the syntax is checked and the style is corrected automatically, the autocomplete and the commit message is checked. The latter is not entirely related to security, but in case of any problems, you can quickly find all the commits that belong to them by the task number or the name of the data center. When creating a commit, the admin writes the ticket number and the comment itself at the beginning, and the hook analyzes which files have changed and adds the affected environments to the message. As a result, a typical commit message looks like a “Task number: [list of environments] comment”. For example:
ADMODKL-54581: [D,E,G,K,P] add some cloud-minion-ec to stable The next defense step is to check in the test environment . The test environment consists of several parts. The first part is unstable, these are virtual machines that anyone can use, can break them in any way he can, we absolutely do not feel sorry for them. They are updated every five minutes. Next comes the testing environment - testing on physical servers (some policies on physical servers run differently). And unlike virtuallok, we have physical servers in CMDB, there, too, policies can be applied differently. Nevertheless, this layer can also be completely lost, it is updated every five minutes.
The next protection is checking for parts of production servers with automated load control . These are real working servers, databases, frontends, etc., where real users sit. We take one server from each new cluster that we install in production if it is fault tolerant and add it to the stable environment. Thus, there are absolutely all types of hardware (RAID controllers, motherboards, network cards, etc.), all types of applications, their various configurations. Everything that is possible in our production.
Since only one server from the cluster gets into stable and only if this server can be lost without an effect for the user, even a fatal error in the stable environment policies does not lead to an effect for users, they will continue to use the portal without any interruptions.
In stable, all system administrators can commit and they can break it, but here the policies are updated not in five minutes, but in an hour. Still, no one wants to once again repair hundreds of servers, so we smoothly update them within an hour.
Also for production-servers the load is automatically controlled. Naturally, we have monitoring of everything, but specifically for these servers, we additionally monitor for at least two hours that they do not appear anomalies. There may be a banal memory leak. If this is immediately given to production, then the consequences could be the worst. With major changes, policies are kept in a stable day.
The next defense mechanism is a review . We check the style (something that was not automatically corrected by the git-hook), the use of the latest versions of the methods, the “adequacy” of the code.

But before the politicians go to production, the reviewer must make sure that they do not cause any errors on all previous environments, that there are no load anomalies and that at least two hours have passed. Only after this the reviewer sends a commit to production.
Naturally, there are problems that need to be quickly resolved, and for this you can bypass the protection mechanisms. This we also provided. If, say, on five servers you need to quickly commit, then you can go to five servers and update by hand. But on all servers you will not do that. To work with a large number of servers, there are special tools with their own protection mechanisms.
At first, only 3 administrators were involved in the review, who implemented CFEngine, understood it best and had the most experience.
Then we introduced a two-level review. Zarejuvit could any admin. This greatly accelerated the work, it was not necessary to wait for several people. It was possible to go to his neighbor, he was revising, but the post-inspection was already carried out by the senior system administrator.
Now all admins have gained a sufficient level of competence, and we have canceled a re-review for everyone who has worked in the company for a long time.
And the last level of protection is protection against distribution of production policies . This is the so-called "darts".
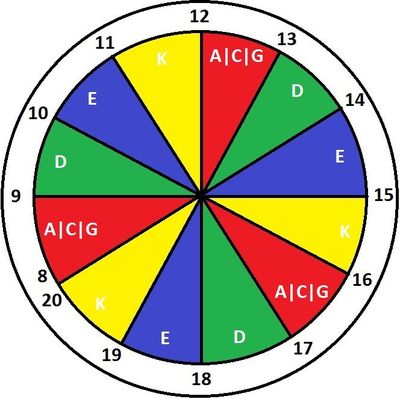
Letters - abbreviations of our DC. Datacenter Data Line with the letter D, it is updated three times a day: from 9 to 10, from 13 to 14 and from 17 to 18. Data centers are independent, thanks to this scheme we have time to notice problems. If the policies are updated on DC and DC begins to fall, then we will see it in time, and the rest DC will remain unaffected. And even if we did not have time to notice for a whole hour, that is, at least another three hours before the fall of the entire production.
If we say that the “green” Data Line starts updating at 9 am, this does not mean that 100% of its servers have immediately been pumped out by new policies. This is done gradually. We don’t want to lose the whole DC at one time, so the policies will be updated at once on a limited number of servers, this is the standard CFEngine functionality - the splay class. Do not need to do anything with your hands, everything is automated.
Additional protection is that the policies are updated only from 8 to 20. No one wants surprises at night, and working time is enough for all things.
If the error rolls over the entire Data Line, then the procedure depends on how serious the problem is. If you need to fix it here and now, then we can still interfere with our hands through the already familiar dssh or the usual ssh. Whatever happens if there is a conflict with CFEngine, we have mechanisms to temporarily disable CFEngine for individual policies or even for individual files. Forget about these temporary changes also fail, because after the timeout expires (3 days), all changes that are not in CFEngine will be rolled back.
If the problem occurs on a large number of servers, then here you can act differently, depending on the severity of the situation. In general, we try to do nothing in manual mode. If the problem can wait, then we will act according to the standard procedure: commit, then stable, review - and within four hours the fix will crawl to these servers. If everything is bad and there are noticeable problems in the service, then we quickly roll back the commit.
So, we have five levels of protection when politicians prepare and go to production. But we decided that this is not enough. What to do if bad politics still broke into production?

We have a plan B. This is another git-repository, which also has policies, but they are very simple, there are very few of them, and we rarely make changes there. If everything is broken, CFEngine switches to an alternative set of policies, and this allows you to first of all keep the CFEngine itself as our main tool. And after switching, we can use it to repair something more serious.
 But even that seemed to us a little, so we wrote a small script that allows, very quickly, to stop CFEngine in all production in tens of seconds. Since 2013, we have never used this tool! But periodically check its performance
But even that seemed to us a little, so we wrote a small script that allows, very quickly, to stop CFEngine in all production in tens of seconds. Since 2013, we have never used this tool! But periodically check its performance
Why there is no automatic rollback of changes? Because in CFEngine there are no transactions and logs. Naturally, configs can be backed up, and we do it. But we cannot know the entire scope of work that led to this problem. Maybe it was a config. Maybe a package upgrade. Maybe a restart of the service. Maybe a combination of actions or their sequence. And to roll them back, you need to know what exactly was done. This can be viewed on the log, but it is not an automatic operation.
, , , . , , , : , , , , .
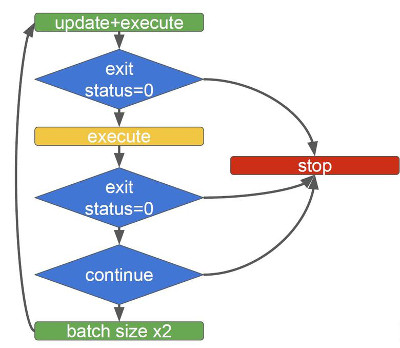
, . , , : 50, 100, 200, 400 . .
Brief summary
— , . :
- ,
- - ,
. production, , production . — , , .
')
Source: https://habr.com/ru/post/342300/
All Articles